您现在的位置是:首页 >学无止境 >【Mybatis源码分析】动态标签的底层原理,DynamicSqlSource源码分析网站首页学无止境
【Mybatis源码分析】动态标签的底层原理,DynamicSqlSource源码分析
DynamicSqlSource 源码分析
一、DynamicSqlSource 源码分析
DynamicSqlSource 的层次结构图,实现 SqlSource 接口,实现 getBoundSql 方法,获取绑定好的 SQL 对象。
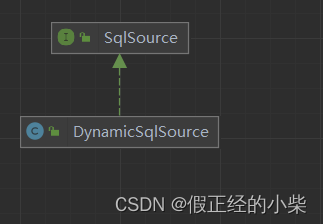
下面是getBoundSql方法实现源码
@Override
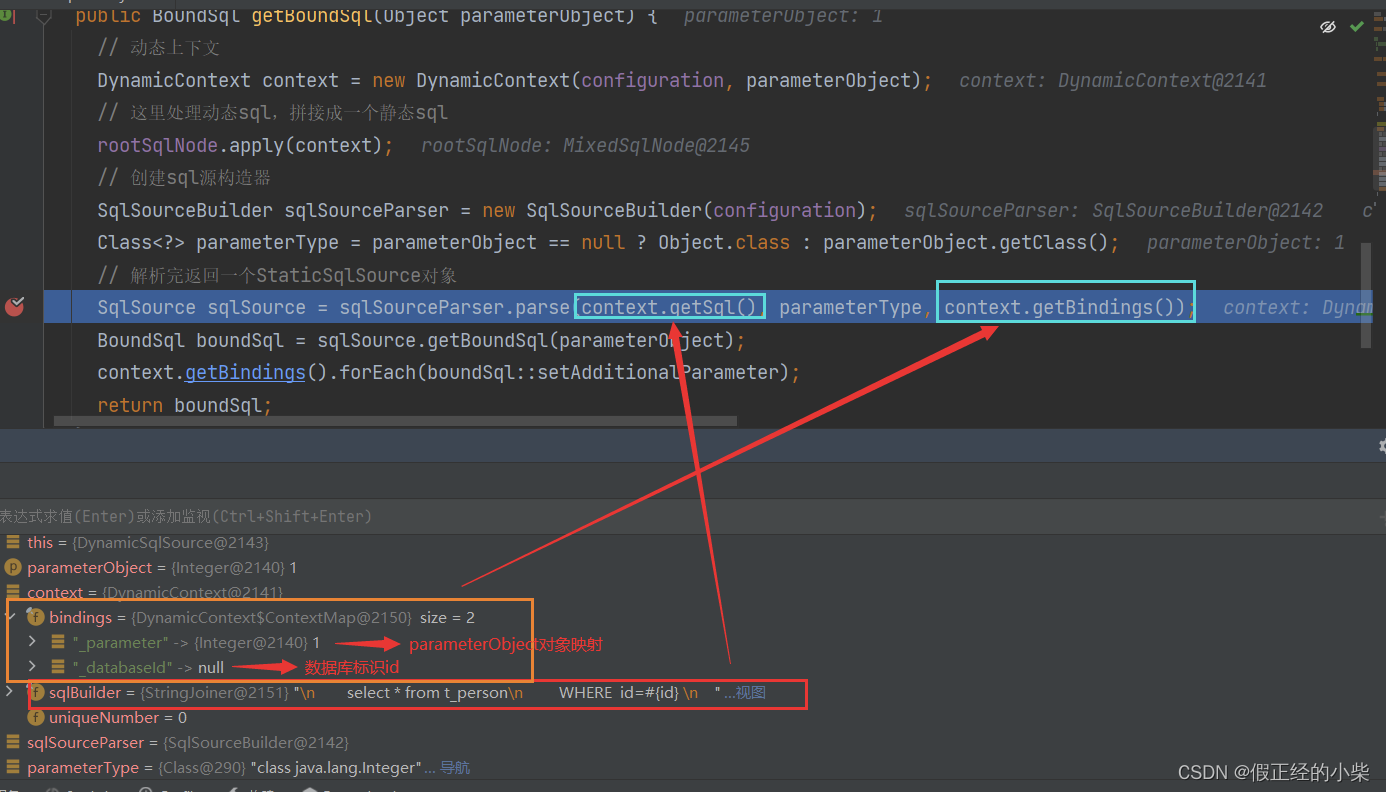
public BoundSql getBoundSql(Object parameterObject) {
// 动态上下文
DynamicContext context = new DynamicContext(configuration, parameterObject);
// 这里处理动态sql,拼接成一个静态sql
rootSqlNode.apply(context);
SqlSourceBuilder sqlSourceParser = new SqlSourceBuilder(configuration);
Class<?> parameterType = parameterObject == null ? Object.class : parameterObject.getClass();
// 解析完返回一个StaticSqlSource对象
SqlSource sqlSource = sqlSourceParser.parse(context.getSql(), parameterType, context.getBindings());
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
context.getBindings().forEach(boundSql::setAdditionalParameter);
return boundSql;
}
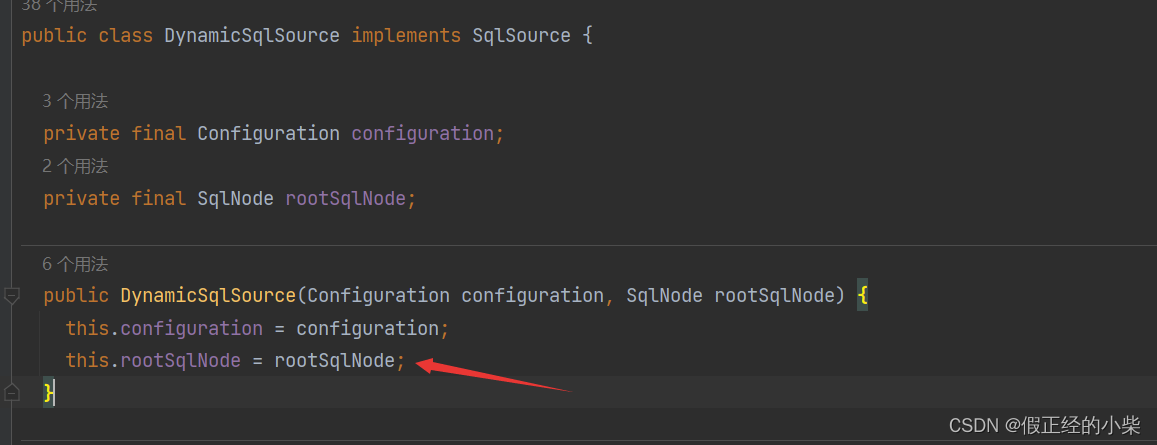
DynamicSqlSource中的属性和构造
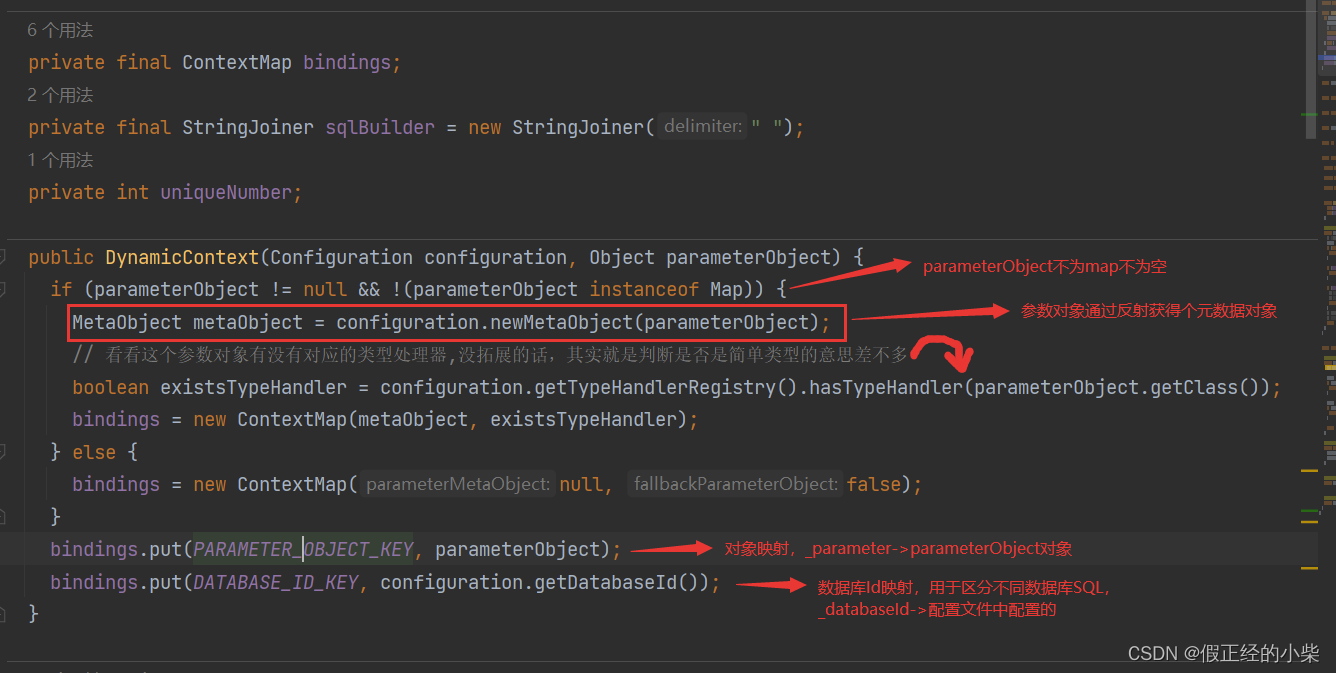
😯DynamicContext源码分析
DynamicContext 中的静态代码块,开启ognl的属性访问器,使用自己写的上下文访问器ContextAccessor。
static {
OgnlRuntime.setPropertyAccessor(ContextMap.class, new ContextAccessor());
}
DynamicContext 中有俩重要属性
// ContextMap是 DynamicContext中的一个内部类,继承了HashMap
private final ContextMap bindings;
// StringJoiner对象," "是分割符,它用来sql字符串凭借,把动态sql解析结果加入到这里,然后以空格分隔。
private final StringJoiner sqlBuilder = new StringJoiner(" ");
构造解析
ContextMap 源码解析
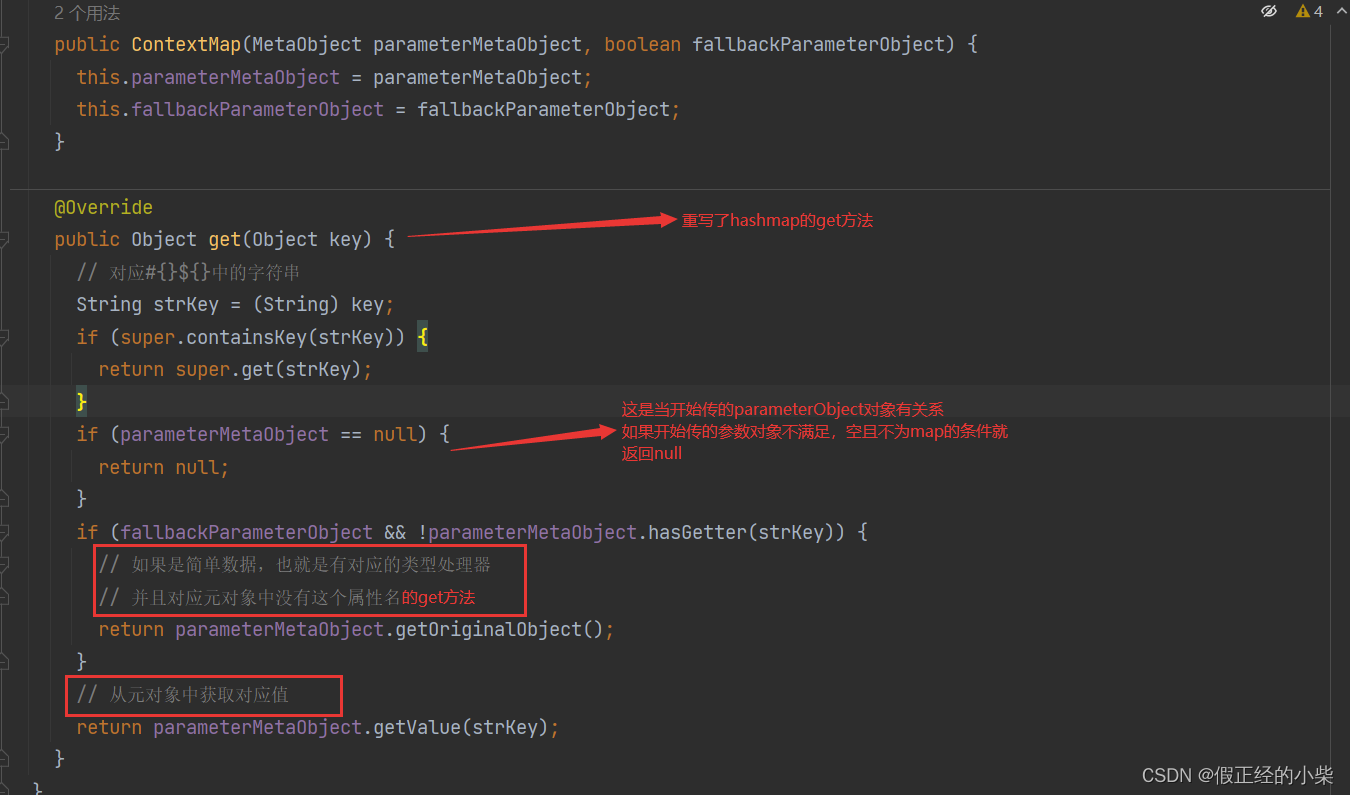
DynamicContext 这个类是用来收集动态 SQL 片段和参数的上下文对象,用来到时候处理完动态SQL的时候进行字符串凭借,从而得到一个非动态的SQL,然后再去处理参数。总的来说它就是一个动态SQL片段的凭借工具+参数对象封装的工具。
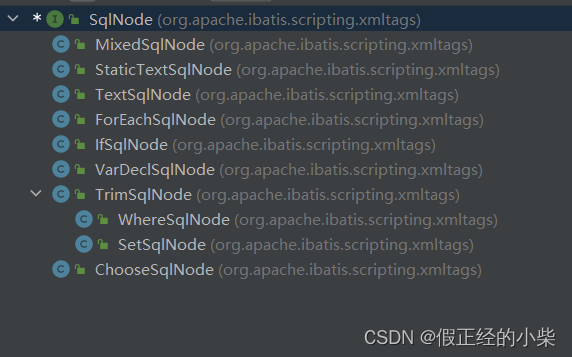
🙄SqlNode源码分析(动态SQL标签)
Mybatis 动态SQL标签
IfSqlNode:通过OGNL来判断test是否为真(经常用来判断参数是否为空或者字符串是否为空字符串),然后进行SQL拼接。WhereSqlNode:会将最后拼接出来的SQL最前面如果有多出来的AND或者OR会给去除掉,一般是与IfSqlNode连用。(内部会将SQL转大写进行比对,所以写的时候正常写就行。)SetSqlNode:会将最后拼接出来的SQL最后面如果多出来了,会给去除掉,一般是与IfSqlNode连用,进行更新操作。TrimSqlNode:是前俩的父类,可以设置前缀、后缀、前缀要最后覆盖的字符串、后缀要最后覆盖的字符串。这个的话看你怎么灵活应用吧。ForEachSqlNode:如果穿过来的参数是数组、实现 Iterable 的对象、Map对象,如果是Map的话那index对应的就是key,item对应的就是value。主要用于构建in语句,批量删除、批量插入语句等。ChooseSqlNode:小编日常用的不多,相当于switch语句。
举例、调试
<select id="selectOne" resultType="person">
select * from t_person
<where>
<if test="id!=null">and id=#{id}</if>
</where>
</select>
以上的动态SQL对应着以下的SqlNode对象。
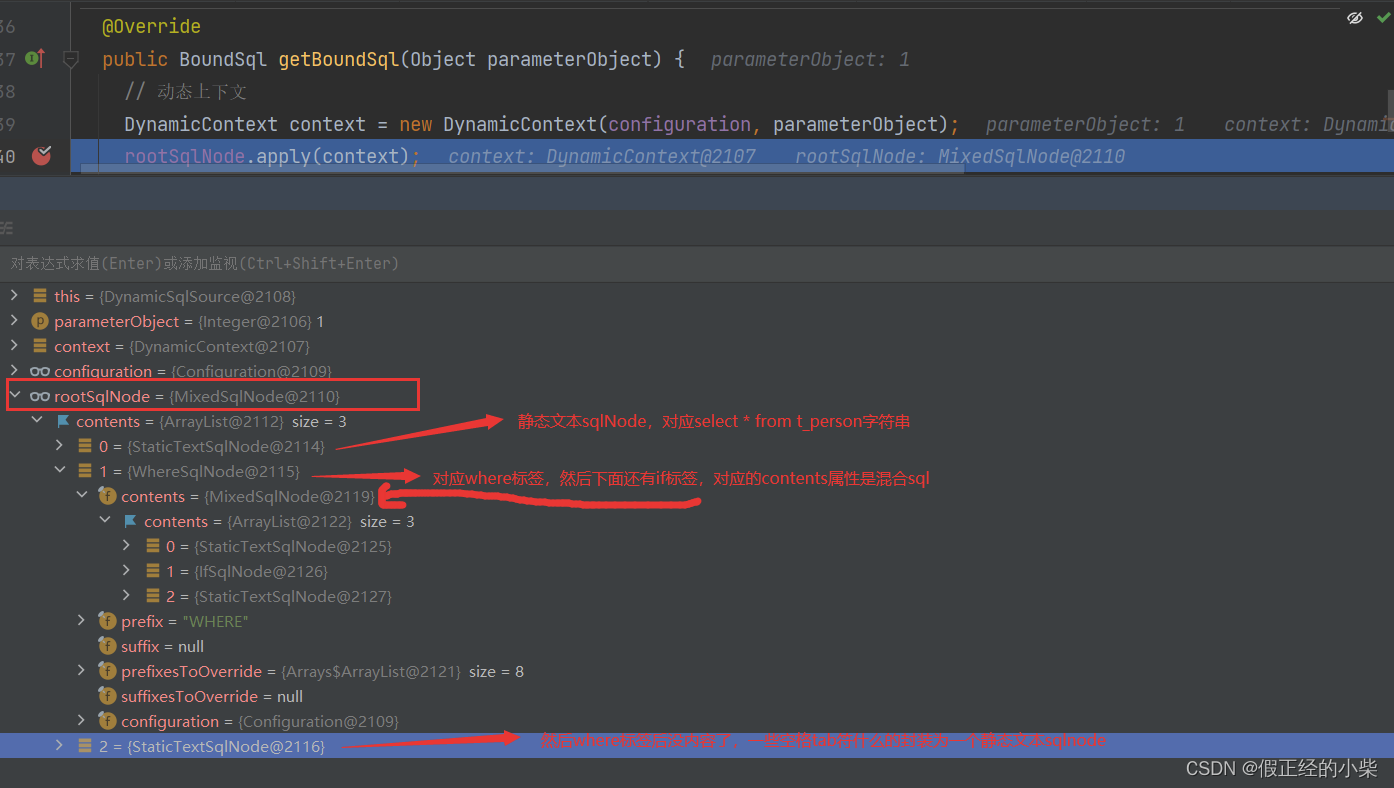
SqlNode源码分析
SqlNode 接口就一个方法,返回值类型是布尔类型,它的返回值取决于是否要进行动态SQL拼接。对那个上面DynamicContext中的sqlBuilder属性对象进行拼接。
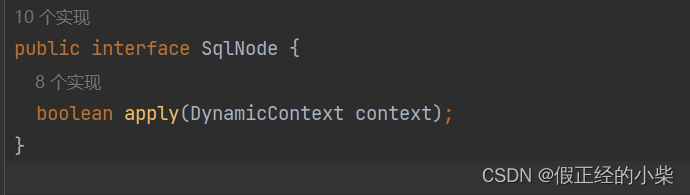
下面是 SqlNode 接口的实现类
 通过解析 XML 查看是否有动态SQL,有的话创建SqlNode对象,在构造DynamicSqlSource对象的时候初始化其
通过解析 XML 查看是否有动态SQL,有的话创建SqlNode对象,在构造DynamicSqlSource对象的时候初始化其rootSqlNode属性。然后调用SqlNode的apply方法进行动态解析。
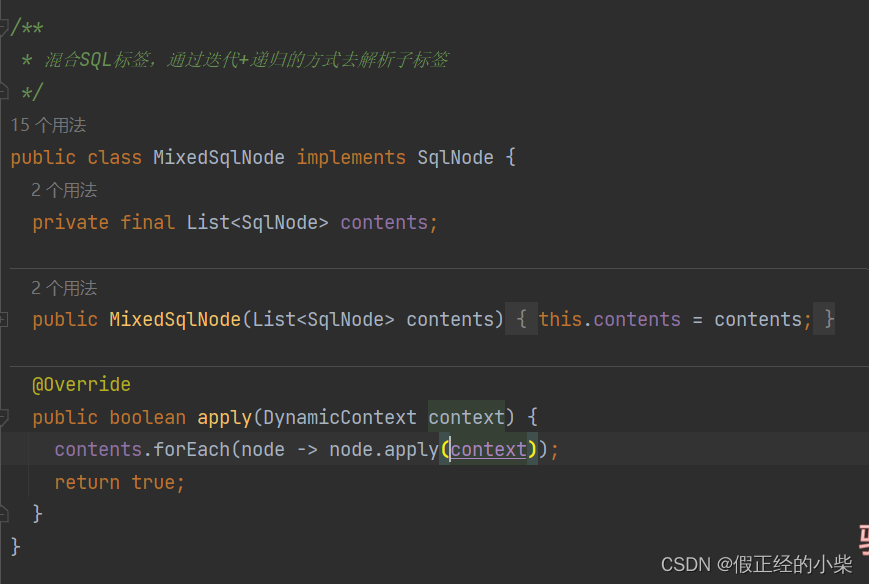
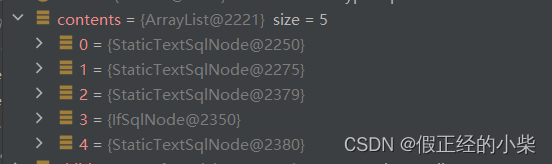
MixedSqlNode
它是一个混合SqlNode标签,内部初始化是一个SqlNode集合。
通过遍历这个集合去处理解析出来的标签,通过递归去实现解析标签下的子标签。
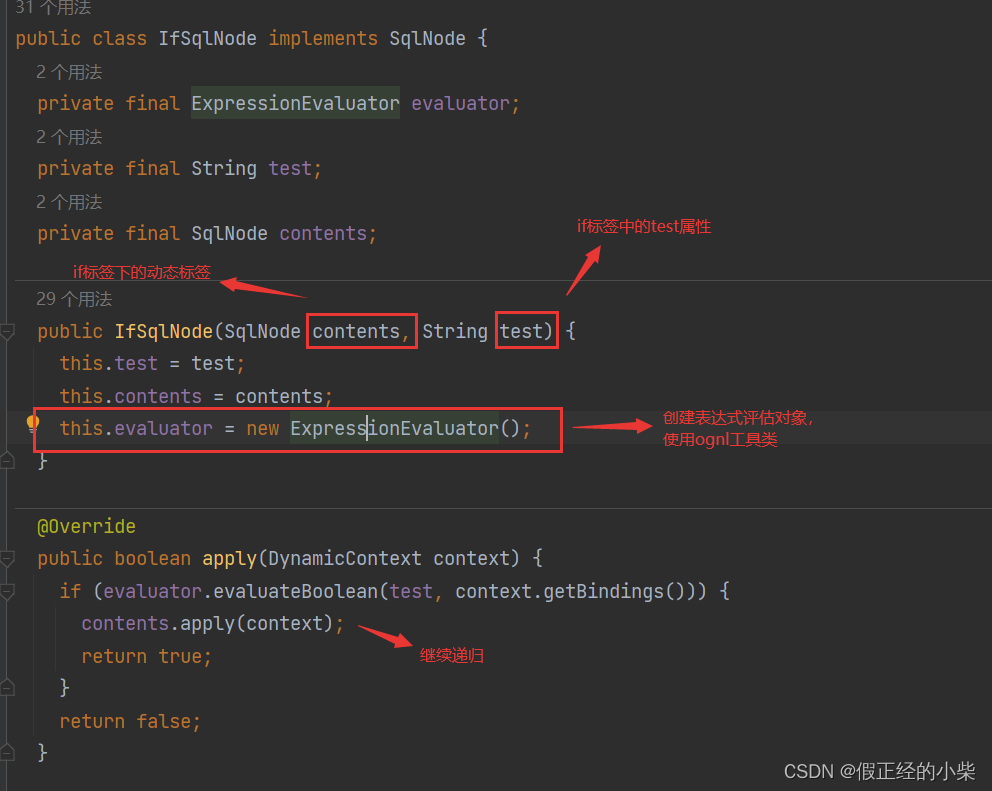
IfSqlNode
在解释IfSqlNode之前, 得先了解一下ExpressionEvaluator类。它是一个 ognl 工具类,处理表达式用的。就俩方法:
public boolean evaluateBoolean(String expression, Object parameterObject):这个主要用来if标签下的test属性,看看是否满足条件。public Iterable<?> evaluateIterable(String expression, Object parameterObject):这个主要用于forEach标签,用于后续item、index迭代。
ifSqlNode的源码还是比较简单的,代码如下
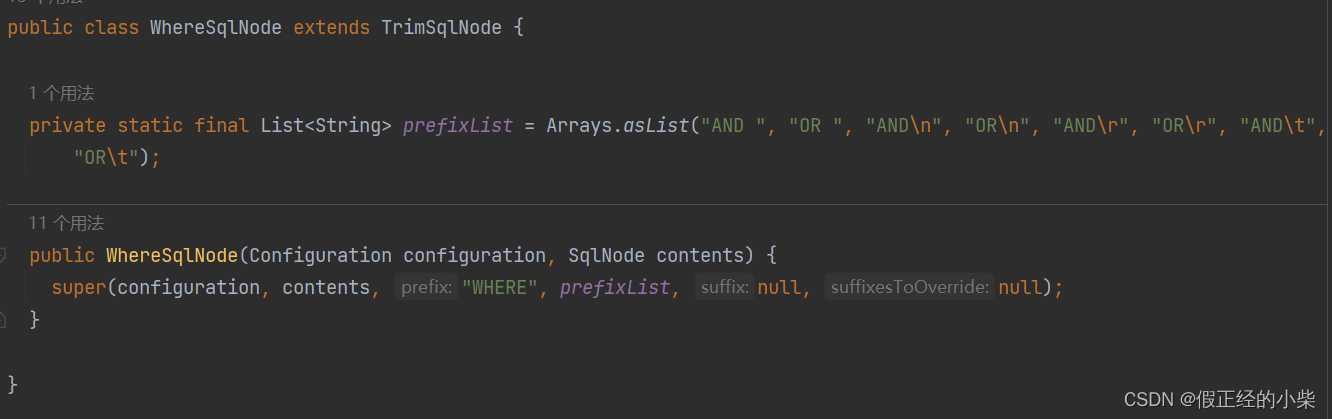
WhereSqlNode、SetSqlNode、TrimSqlNode
WhereSqlNode是继承于TrimSqlNode类的,apply方法也没有进行重写,仍然是TrimSqlNode中实现的apply方法。WhereSqlNode主要就是给父类属性进行初始化。
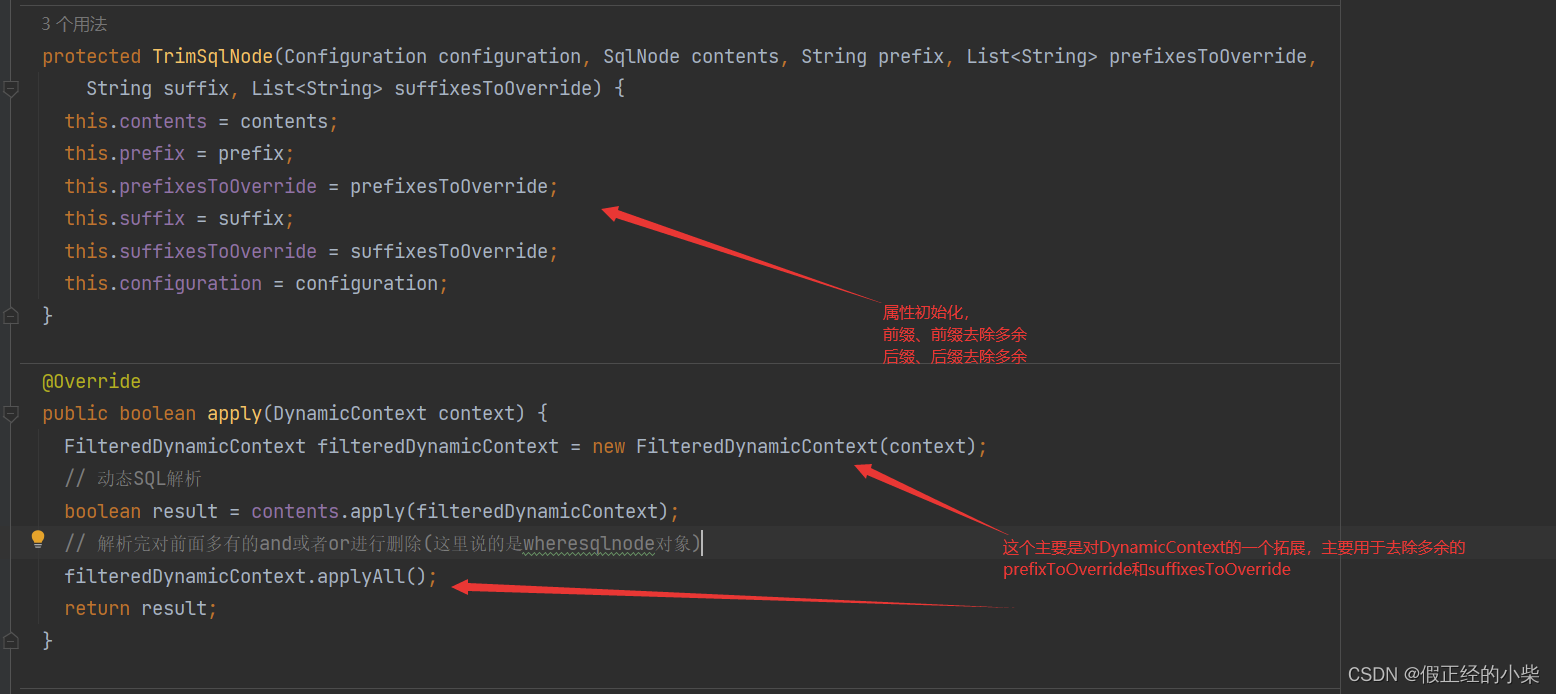
先主要看看TrimSqlNode的源码
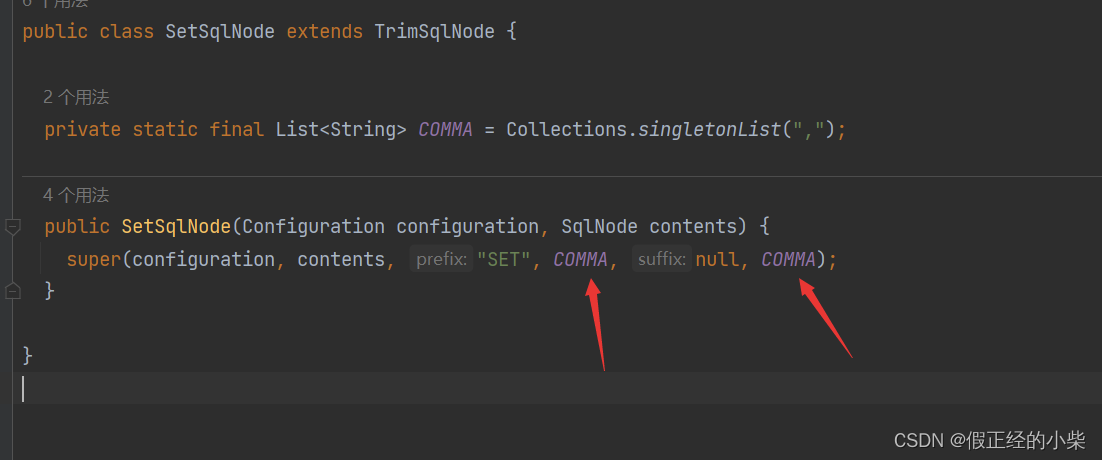
SetSqlNode 没啥说的,和where只是一个前后缀的区别,但是它是前后缀多余的点都算在内,where不是,where是前面多余的and或者or给你去掉。
trim标签单独使用得注意下面的细节了。
在单独使用trim标签的时候,自己通过属性配置prefixesToOverride和suffixesToOverride得注意了,它会对你对你配置的字符串进行解析,通过parseOverrides 方法。首先要知道 prefixesToOverride 和 suffixesToOverride 是一个 list 集合对象,内部元素是字符串类型的。

下面是parseOverrides的源代码,只要就是将xml配置的字符串通过或运算符 | 进行分割,然后封装到集合中进行返回。
private static List<String> parseOverrides(String overrides) {
if (overrides != null) {
// 创建一个字符串分割对象,用来对字符串进行分割,可以看见是通过或运算符 | 进行分割
final StringTokenizer parser = new StringTokenizer(overrides, "|", false);
// 这里执行控制容量,防止add过头了,进行扩容浪费了空间
final List<String> list = new ArrayList<>(parser.countTokens());
// 这里就往集合中添加你配置的字符串咯
while (parser.hasMoreTokens()) {
list.add(parser.nextToken().toUpperCase(Locale.ENGLISH));
}
return list;
}
return Collections.emptyList();
}
也就是说使用 trim 标签的时候要配置prefixesToOverride和suffixesToOverride的话,记得用或运算符|进行分割。
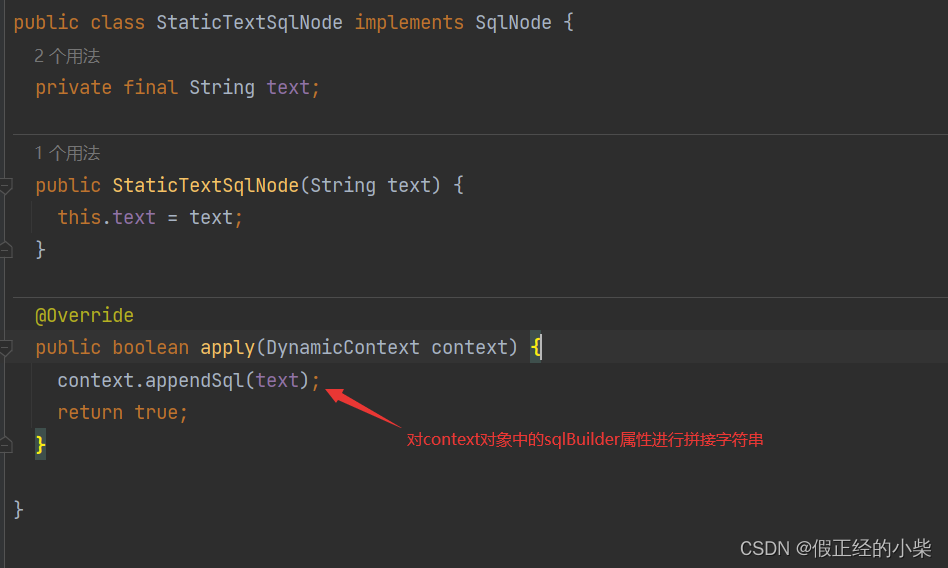
StaticTextSqlNode
这个在上面举例中出现过,就是将解析动态SQL标签前后的sql片段进行拼接。其源代码如下
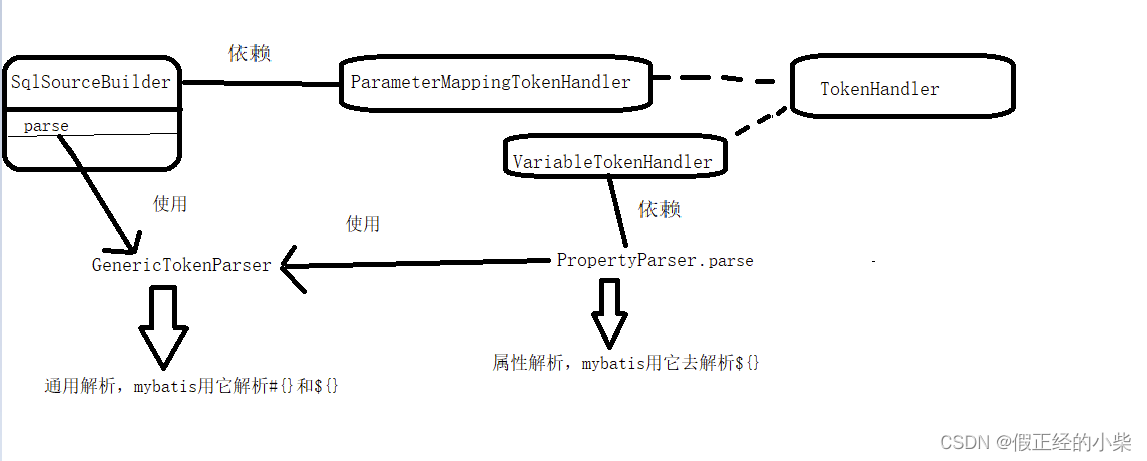
😴SqlSourceBuilder中parse方法源码分析
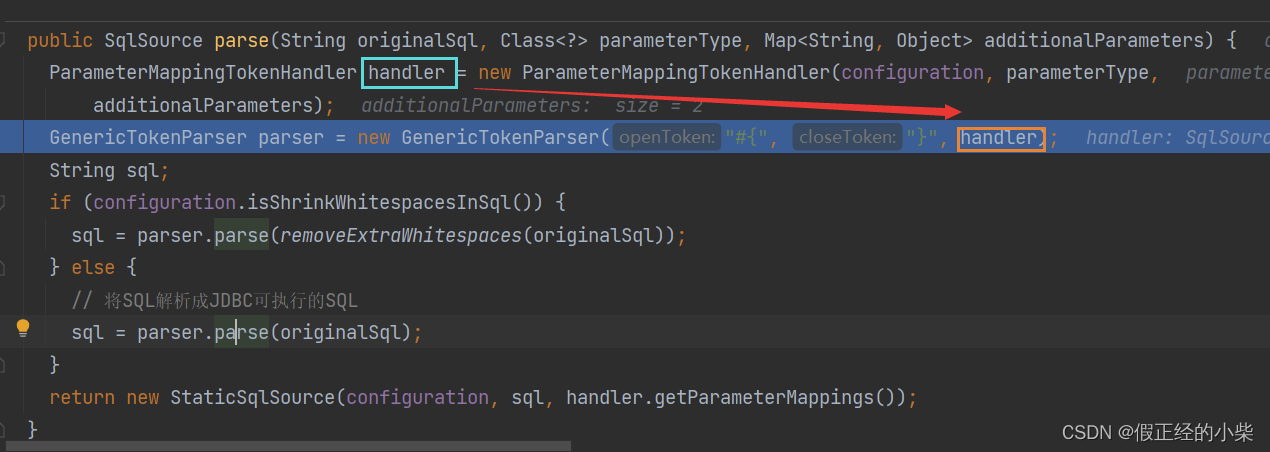
解析完动态SQL,然后拼接成的sql字符串片段,基本已经成型了。现在需要对参数进行处理,也就是对#{}进行处理,把这里要注入的数据封装好,然后用?代替,形成一个预处理的SQL,对应着JDBC中的Prepared Statement预处理语句对象,后期执行。
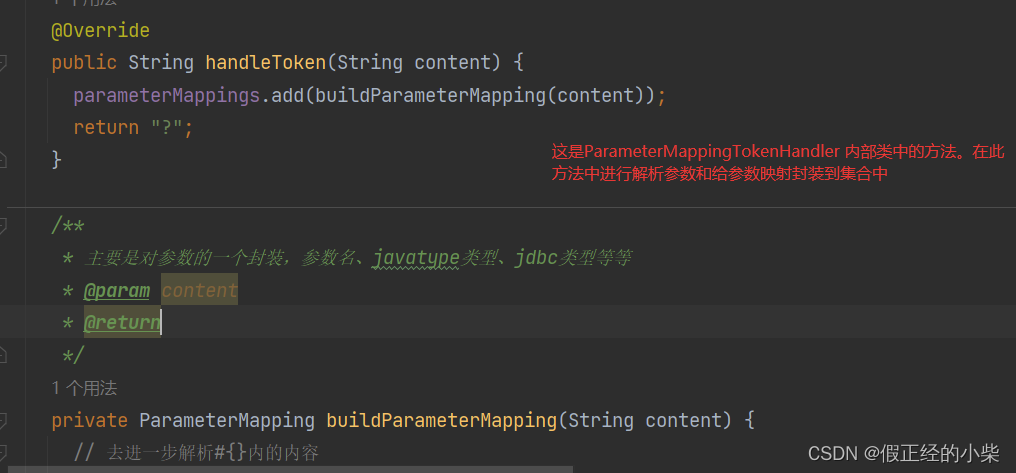
SqlSourceBuilder 类中有个私有内部类 ParameterMappingTokenHandler ,内部有个List<ParameterMapping> parameterMappings集合对象属性,就是封装那个#{}中的参数后期注入。同时这也解析了xml中配置的参数的配置信息(#{参数(javatype=??,jdbctype=??,mode=??})。有下面圈到的这些:
 parse 方法源代码
parse 方法源代码
注意:ParameterMappingTokenHandler 对象在构造 GenericTokenParser 通用解析器对象的时候传入了。这里在下面的解析源sql(动态sql片段拼接后的sql)有被用到。
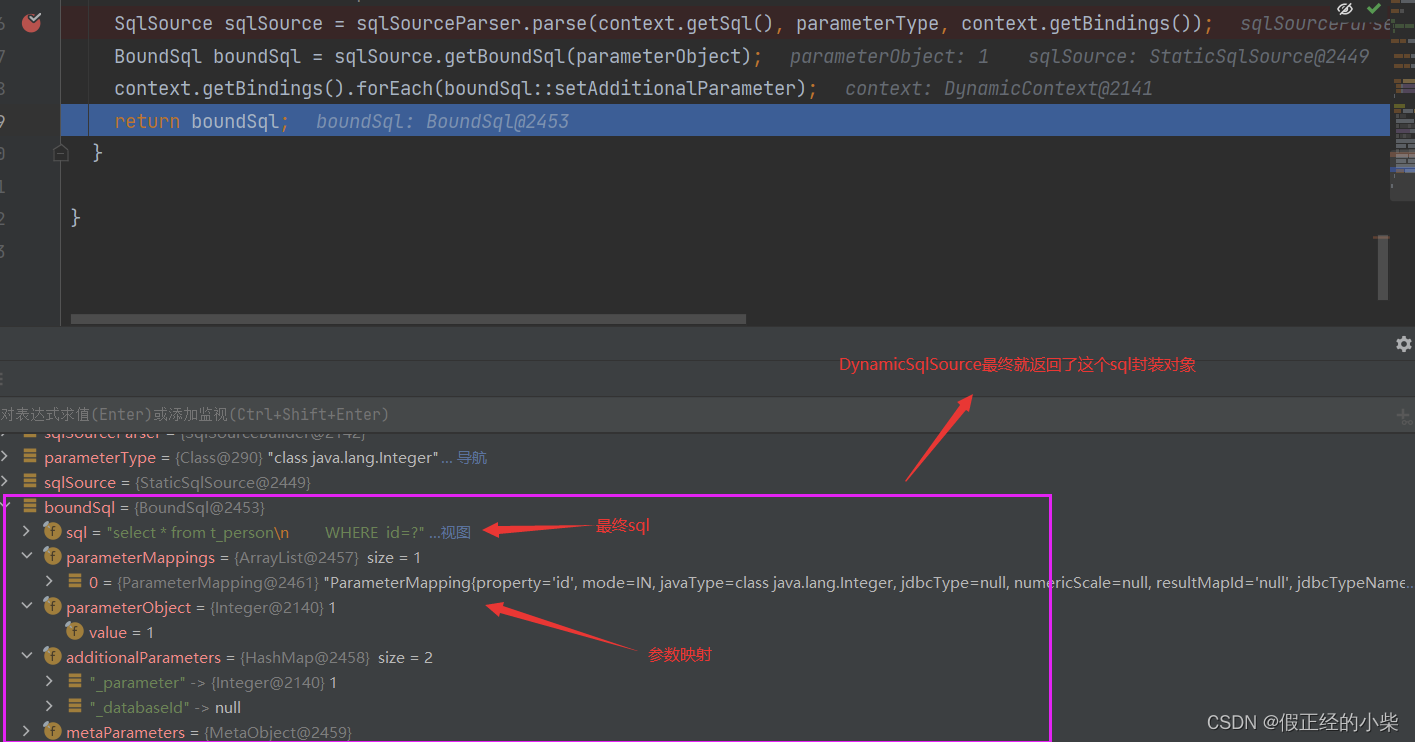
 通过那个 GenericTokenParser 对象的 parse 方法后,就解析成如下sql
通过那个 GenericTokenParser 对象的 parse 方法后,就解析成如下sql
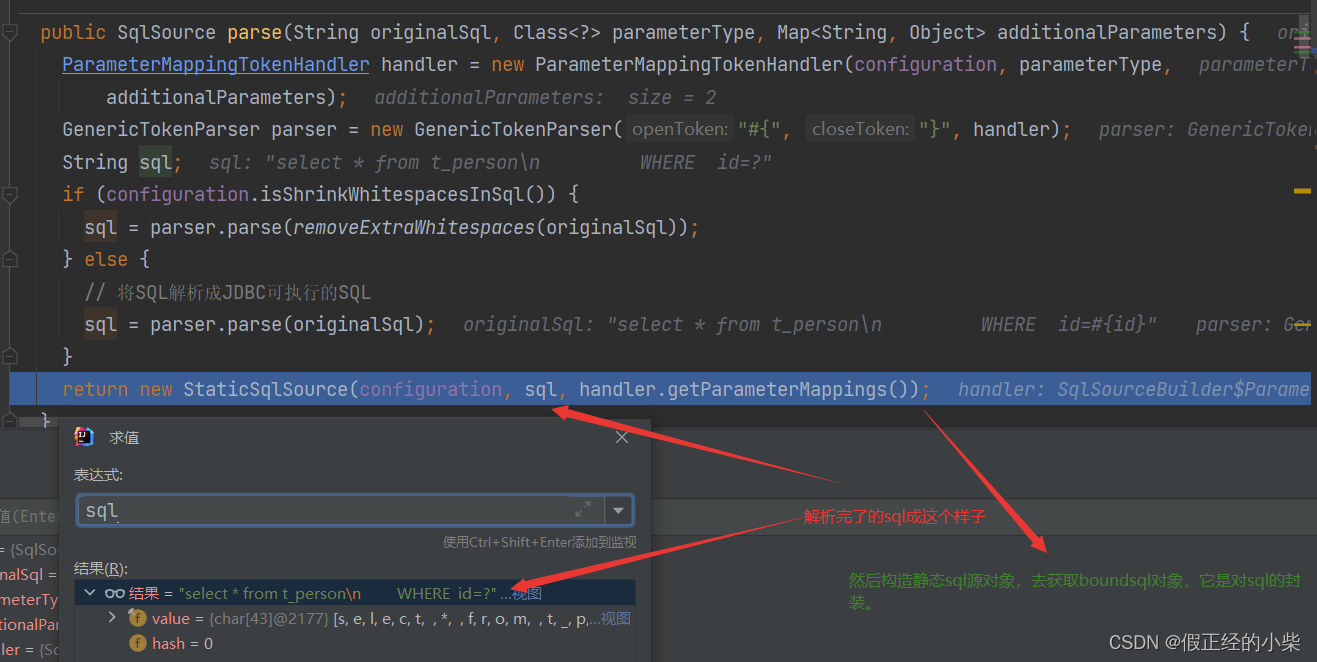
(在上解析sql的时候,途中调用了这个函数,它对参数进行了封装,也对参数的描述进行了解析。)
DynamicSqlSource 最后返回结果
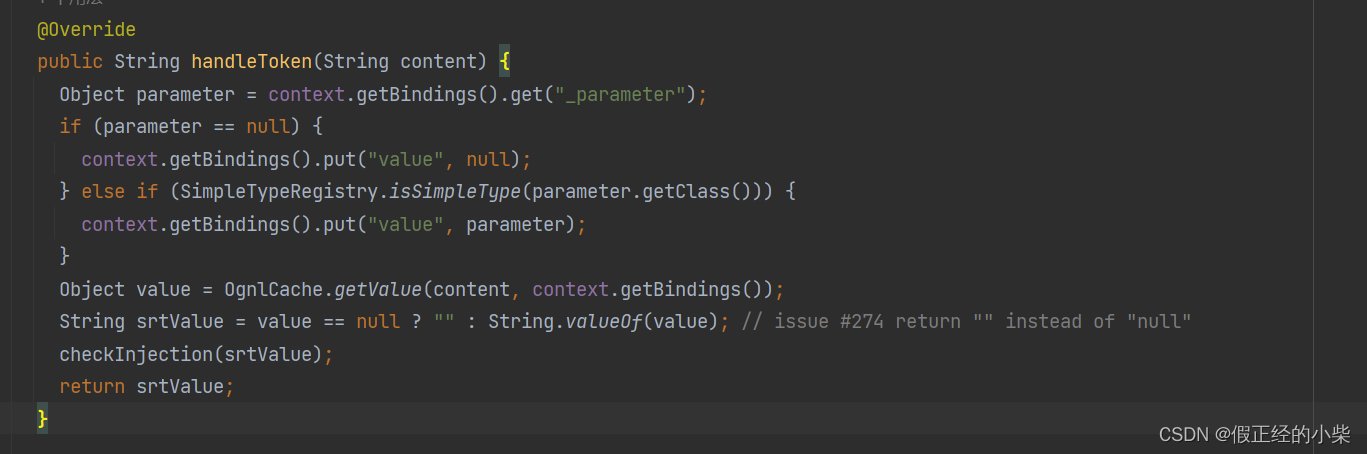
TextSqlNode 内部也有俩个内部类对 TokenHandler 去进行实现,也是对 ${} 的一个解析,它是通过 GenericTokenParser 去实现的这个解析.(没有画)
下面是 TextSqlNode 中关键重写的 handleToken 方法(如果是简单类型,${}里面随便写都能解析出来,否则用 OGNL 去匹配)
XMLLanguageDriver
不管是去解析注解中的带有的动态标签(script标签下的),还是去解析xml的,都是通过XMLLanguageDriver 这个类中的方法去获取 SqlSource,进而获得SQL的封装,BoundSql对象。
解析来看这个类对下面这段 xml 做了啥。
<select id="selectTest" resultType="person">
select * from t_person
where <![CDATA[age>20]]>
<if test="name!=null and name!=''">and name like '%${name}%'</if>
</select>
其实本质上这里就包含Node的子孩子有,文本Node-》CDATANode-》ElementNode(If)
当然回车、空格一些符号它也会计算进去。
首先解析前需要知道它需要传入的参数:configuration对象、对应标签的XNode对象、传进来的参数类型。
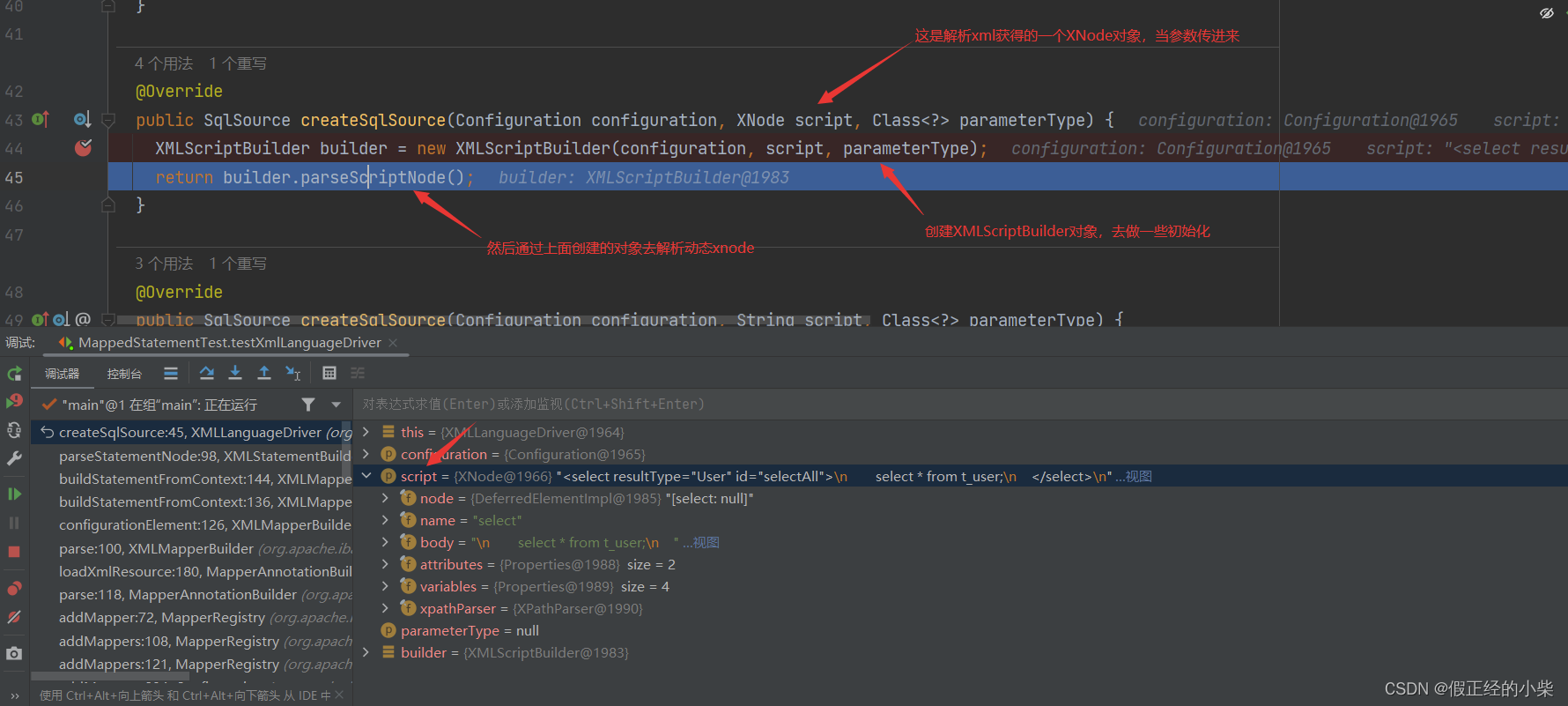 进一步去解析XNode对象,然后得到一个
进一步去解析XNode对象,然后得到一个MixedSqlNode当作rootSqlNode对象。
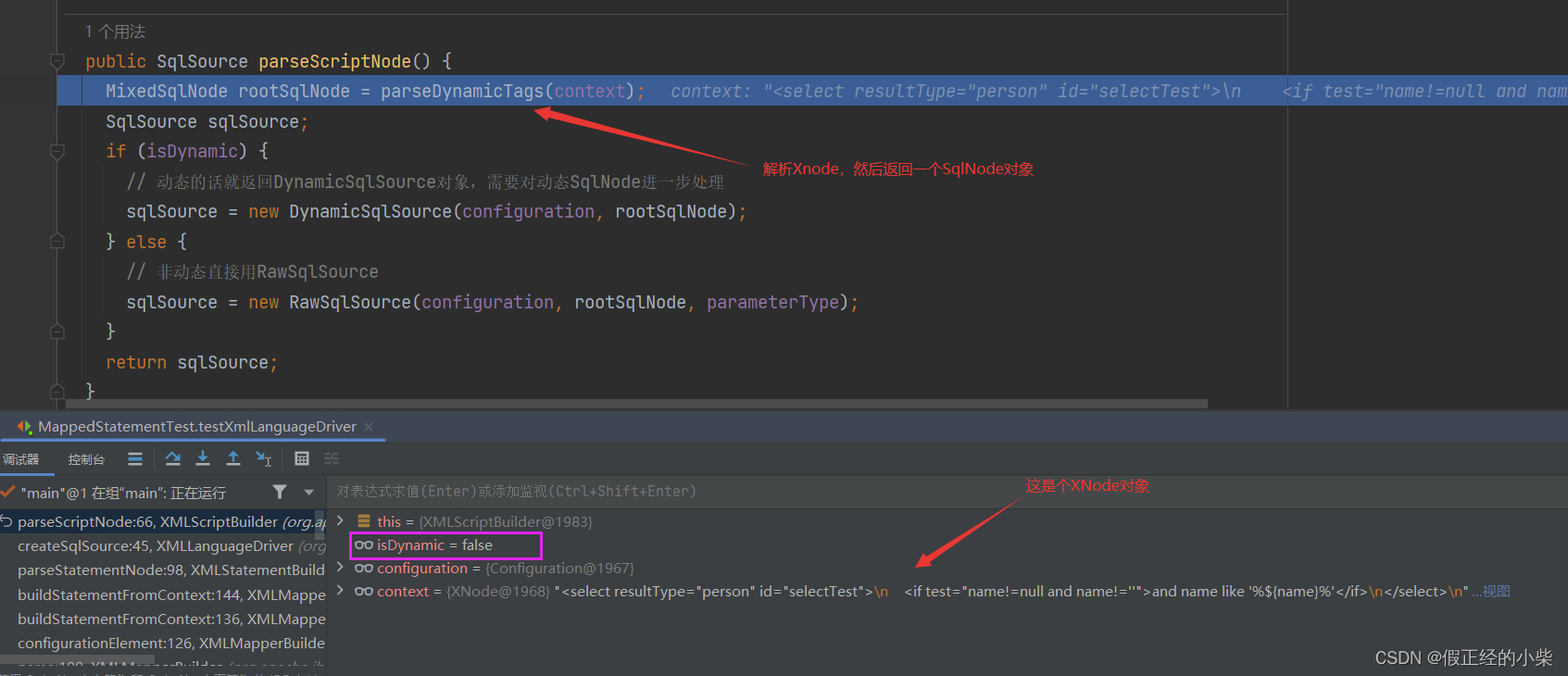 下面是解析过程,过程不难。就是需要注意一个点,
下面是解析过程,过程不难。就是需要注意一个点,node.getNode().getChildNodes()包含了文本节点,对应着Node.TEXT_NODE(3),也可以看得见这里有对<![CDATA []]>的解析
protected MixedSqlNode parseDynamicTags(XNode node) {
List<SqlNode> contents = new ArrayList<>();
NodeList children = node.getNode().getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
XNode child = node.newXNode(children.item(i));
// 判断改节点是纯文本还是<![CDATA []]>
if (child.getNode().getNodeType() == Node.CDATA_SECTION_NODE || child.getNode().getNodeType() == Node.TEXT_NODE) {
String data = child.getStringBody("");
TextSqlNode textSqlNode = new TextSqlNode(data);
// 这是判断有没有${},有的话添加textSqlNode,没有的话直接添加StaticTextSqlNode
if (textSqlNode.isDynamic()) {
contents.add(textSqlNode);
isDynamic = true;
} else {
contents.add(new StaticTextSqlNode(data));
}
} else if (child.getNode().getNodeType() == Node.ELEMENT_NODE) { // issue #628
String nodeName = child.getNode().getNodeName();
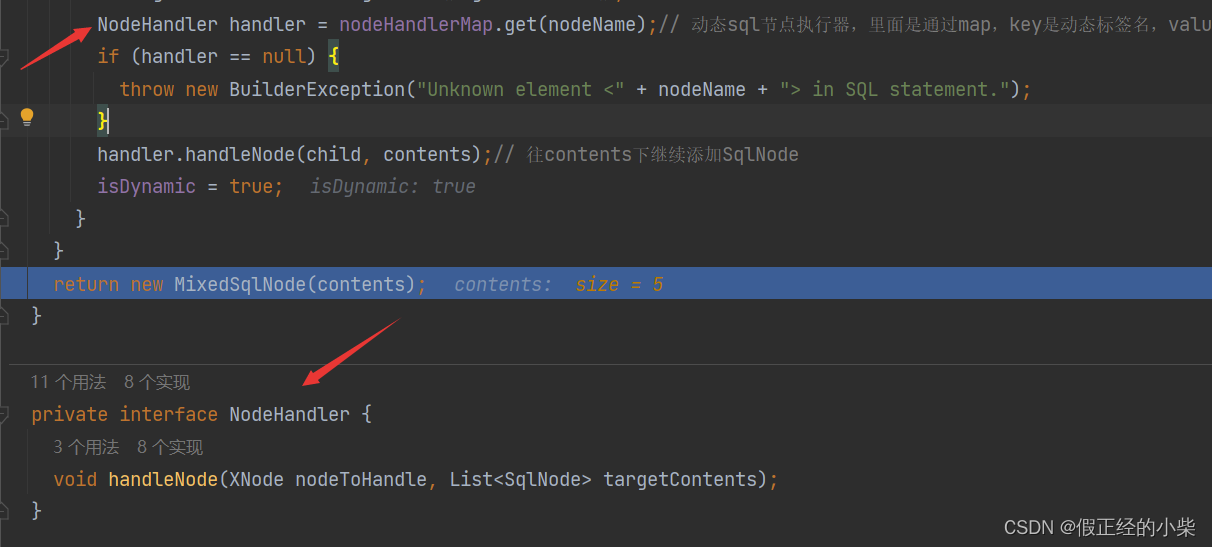
NodeHandler handler = nodeHandlerMap.get(nodeName);// 动态sql节点执行器,里面是通过map,key是动态标签名,value是对应执行器
if (handler == null) {
throw new BuilderException("Unknown element <" + nodeName + "> in SQL statement.");
}
handler.handleNode(child, contents);// 往contents下继续添加SqlNode
isDynamic = true;
}
}
return new MixedSqlNode(contents);
}
解析出来的SqlNode集合
这里还得说一下 NodeHandler,它是一个内置的接口,每个动态标签都有对应着一个NodeHandler实现类,去重写 handlerNode 然后是实现递归解析。
以 IfHandler 为例进行源码分析,其他标签也类似。
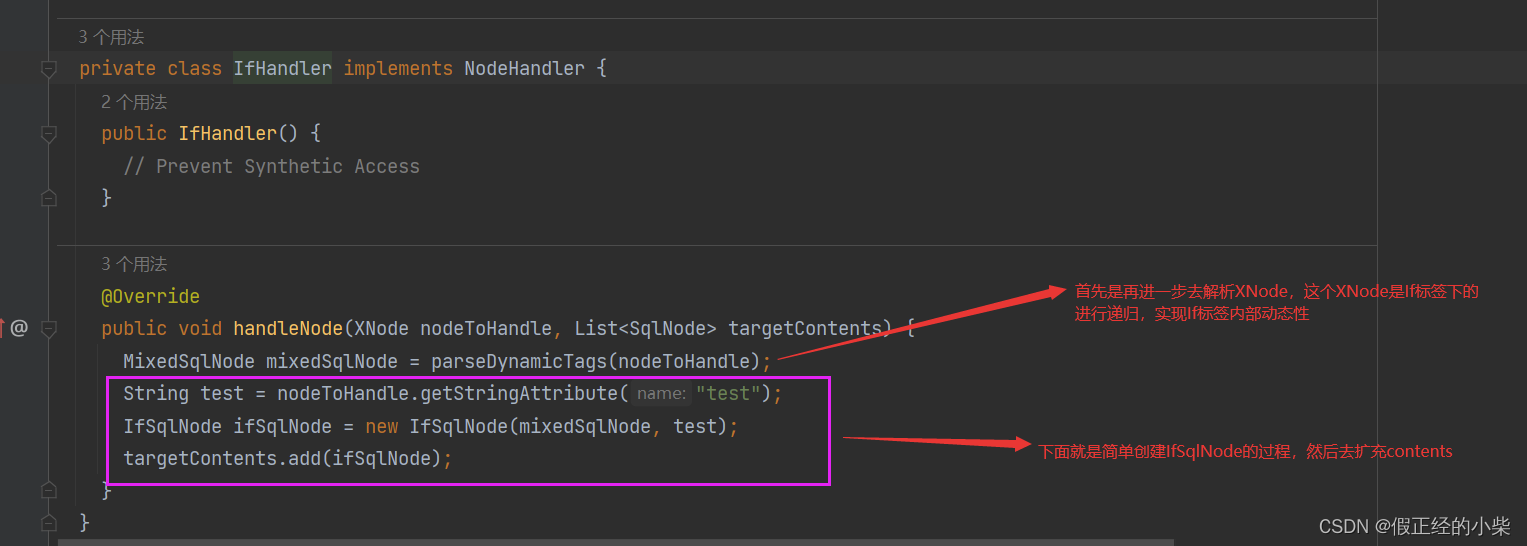
总结
- DynamicSqlSource 是用 DynamicContext 对象中的 sqlBuilder 对象进行动态Sql片段拼接的,它是一个
StringJoiner对象,以空格分隔开片段。 - 解析映射xml中的动态sql标签是封装在
SqlNode对象中,其中是通过MixedSqlNode混合 SqlNode 进行遍历,然后通过递归的一种形式进行处理的。 - SqlSourceBuilder.parse 进行了sql 最后的处理,处理了
#{},并对参数进行了封装。 - 本质就是 DynamicSqlSource 最后还是通过前者解析后获得的 StaticSqlSource 对象,然后调用
getBoundSql将sql封装对象BoundSql进行返回。 - 通过
XMLLanguageDriver去获取相应的SqlSource对象,它的作用就是去看有哪些动态标签,去解析<![CDATA []]>,然后通过 SqlSource 就可以去获取 BoundSql 对象了。 - Raw翻译为未加工的。那RawSqlSource和DynamicSqlSource的差异其实就少了去处理动态的标签,比如If、where、set这些需要进一步处理的它没有。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结