您现在的位置是:首页 >技术杂谈 >飞桨paddlespeech语音唤醒推理C实现网站首页技术杂谈
飞桨paddlespeech语音唤醒推理C实现
上篇(飞桨paddlespeech 语音唤醒初探)初探了paddlespeech下的语音唤醒方案,通过调试也搞清楚了里面的细节。因为是python 下的,不能直接部署,要想在嵌入式上部署需要有C下的推理实现,于是我就在C下把这个方案的部署实现了。需要说明的是目前完成的是浮点实现,真正部署时要用的是定点实现,后面要做的是从浮点到定点的转换。浮点实现也做了两个版本。一是跟python下的实现完全一致的版本,做这个版本的目的是方便与python版本的结果比较,确保每个模块的实现完全正确。二是将模型中的卷积层和对应的batchNormal(BN)层合并为一个卷积层的版本,将卷积层和对应的BN层合并为一个卷积层一是可以减少参数的个数,二是可以减少运算量(BN里有求方差等运算)。做定点化时也是要基于这个版本来做的。下面就讲讲我是怎么做C下的实现的。
语音唤醒的推理过程如下图所示:

从上图可以看出主要分两步,一是做特征提取,二是做模型推理。将提取出来的特征值作为模型的输入,推理后得到模型的输出,从而给出是否是关键词的结果。
1, 特征提取
特征提取的步骤如下图所示:

做这一步时主要基于两份开源的代码: FFT 和 MFCC。Fbank是MFCC的一部分,因此需要对代码进行裁剪。做时从分帧开始到得到特征值,每一步处理都要跟python下的保持完全一致,如分帧时用的是什么窗,用的是能量谱还是对数谱等。调试时基于一个具体的WAV文件来调。每一步执行后python下有一个输出,在C下也有一个输出,要确保这两个输出在误差允许范围内保持一致,否则就是C的实现有问题。经过调试后特征提取部分就完成了,python下的结果和C下的结果保持小数点后面前四位相同,误差还是非常小的。
2, 模型推理
模型推理可以分为如下几个步骤:在Python下获取模型参数并保存进文件给C实现用,跟python完全一致的浮点实现,将卷积层和对应的BN层合并为一个卷积层的浮点实现。
2.1 模型参数获取
在paddlespeech下先用API获取每层的参数,代码大致如下:

然后将每层的参数按事先规定的格式保存在一个文件里,供C实现去解析参数。我用的参数保存格式如下:

即参数一层一层的放。在每一层里,先是层名,然后是weight参数的个数和bias参数的个数,最后是weight和bias具体的参数值。在C中就根据这个规则去解析从而得到每一层的参数。
2.2 跟python推理完全一致的浮点实现
模型的框图如下:
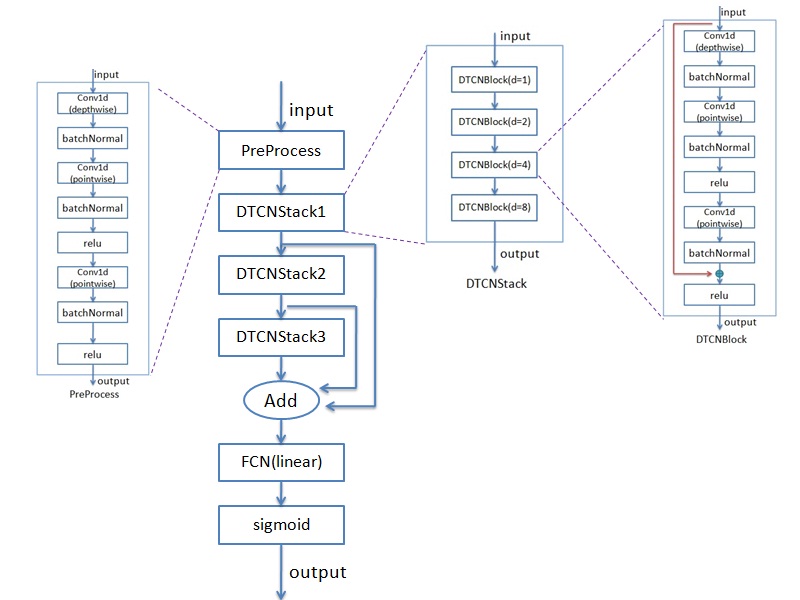
主要有PreProcess/DTCNStack等模块。先实现模型用到的神经网络里的基本单元,有depthwise_conv1d/pointwise_conv1d/relu/batch_normal/sigmoid等。再将这些基本单元组成pre_process模块来调试。依旧是用调试特征提取时的方法来调,确保每一步的输出跟python下的在误差允许范围内保持一致。PreProcess模块调好后再来调DTCNStack等模块,最终形成一个完整的推理实现。下图给出了我调试时用的wav的最终每帧的在python下和C下的后验概率(有多个值,限于长度,这里只截取了部分),可以看出python下和C下的结果是保持一致的。

2.3将卷积层和对应的BN层合并为一个卷积层的浮点实现
为了减少参数个数和运算量,可以将将卷积层和对应的BN层合并为一个卷积层。具体原理如下:
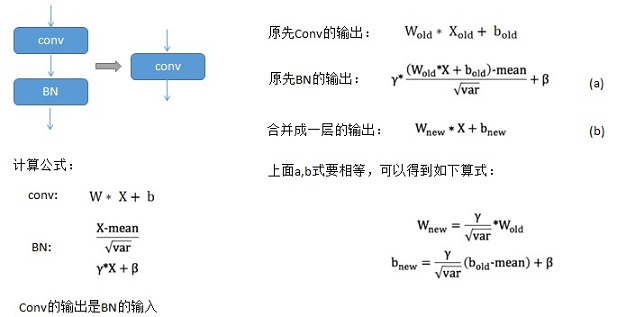
对于C实现来说,只要把banch_normal()函数去掉就可以了。但是在保存参数时卷积层的参数要根据上面的公式做个换算,同时把BN层的去掉。下图是做最后linear以及后验概率运算时有没有BN层的结果(有多个值,限于长度,这里只截取了部分)。
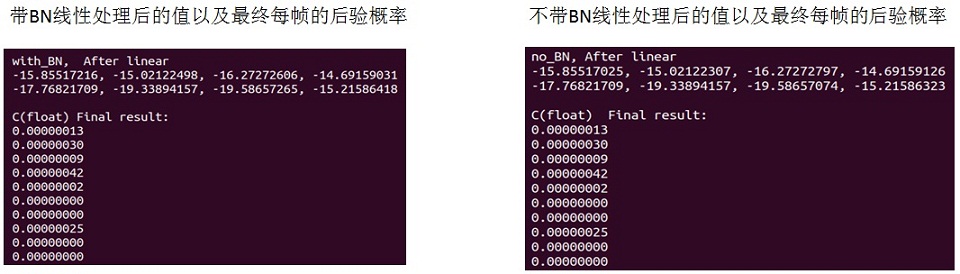
从上两图看出将卷积层和BN层合并为一层对最终结果的影响是非常小的,但是省掉了2.5K的参数以及原先BN层要做的运算量。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结