您现在的位置是:首页 >技术交流 >unity 性能优化之GPU和资源优化网站首页技术交流
unity 性能优化之GPU和资源优化
Shader相关优化
众所周知,我们在unity里编写Shader使用的HLSL/CG都是高级语言,这是为了可以书写一套Shader兼容多个平台,在unity打包的时候,它会编译成对应平台可以运行的指令,而变体则是,根据宏生成的,而打包运行时,GPU会根据你设置的宏切换这些打包出来的代码,而不是我们书写那种只生成的一个Shader,这也是为了提高运行速度。
如果你要查看实际运行的代码,可以使用RenderDoc等工具截帧查看实际运行的代码。
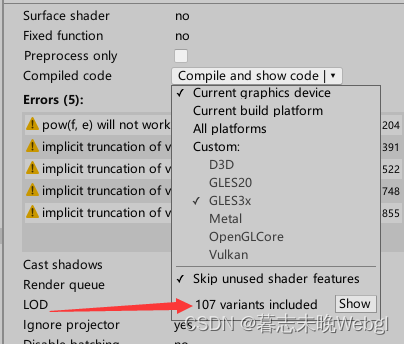
可以在Shader上面查看当前生成的变体数量。
优化Shader最主要的是优化Shader的算法,整理代码结构,减少冗余。使用最精简,运行效率最高的代码来实现我们的功能。
函数性能优化
我们可以在微软的网站查看,根据指令槽进行排序,查看性能消耗顺序。里面展示了在片元里面的占用:
- 纹理采样尽量减少采样次数,消耗排序:texCubelod > texCube > tex2Dlod > tex2D
- 减少复杂的数学函数调用,它们无法直接编译简单指令:pow,exp,sign,cos,sin,tan
- 能复用的,尽量减少重复计算:normalize,dot
- saturate,abs,max,min 推荐使用,效率高
注意事项
- 避免使用除法,使用rcp代替,a/b 可以改成 a*rcp(b)这种提高性能
- 避免使用if,loop这种逻辑和循环
- 计算精度问题:世界空间位置以及精度要求高的纹理坐标用float,其它都用half就行(纹理坐标,向量,颜色(HDR)等)
- 减少寄存器的数量
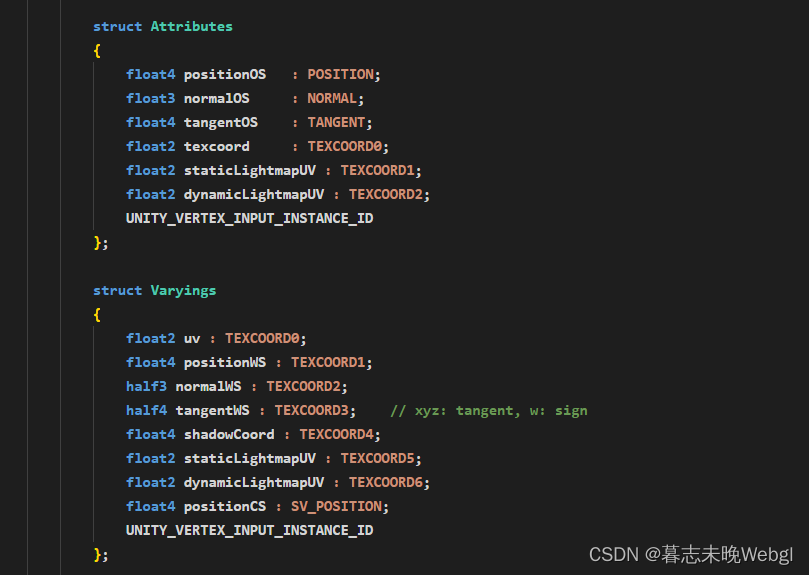
一般是在Varyings减少,Attributes是从Mesh上面获取,如果Shader上没有使用到也可以去掉。 - 能在顶点计算的,尽量在顶点着色器计算,一些线性的数据,比如Fog SH
- 慎重使用AlphaTest,会导致Early-z的失效,最好使用脚本,设置宏,开启时自动修改队列到2450
- Color Mask问题,一些平台上移动端可能会占用资源。
渲染优化
函数优化的再多也节省不了多少,都不如少渲染几次节省的多,所以,我们要从减少渲染量上面入手。
- 减少Overdraw 尽量避免AlphaTest和AlphaBlend物体,尤其是AlphaTest要放到2450,不要和不透明物体混合。减少整个屏幕的特效。
- 减少后处理,每一次全屏后处理增加计算量太大了,计算时最好能降低分辨率计算,比如bloom计算时都采用了一种降采样的做法。
- 抗锯齿,移动端尽量不要开,性能推荐:MSAA < TAA < FXAA&SMAA
inline内联函数
我们在Unity的内置CGInclude文件中可以发现不少函数都有inline关键字,有inline修饰的函数为内联函数,可以解决一些频繁调用的小函数大量消耗栈空间(栈内存)的问题,但inline 的使用是有所限制的,inline 只适合函数体内代码简单的函数且会被频繁调用时使用,不能包含复杂的结构控制语句例如 while、switch,并且内联函数本身不能是直接递归函数(即,自己内部还调用自己的函数)。
美术资源的优化
美术资源主要是包含:纹理,网格以及Shader的变体,其中最主要的是纹理。
纹理
纹理大小会影响资源加载时间,gpu渲染时间,内存的使用,包体大小以及画面质量。
有些同学一直认为要极致压缩在unity里面的大小,这种方式是不对的,那只是导入到unity中的图片存储格式,不代表在打包后的占用,unity在打包时,会将格式转换成其它格式进行存储。
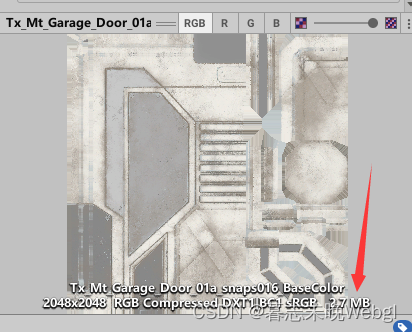
上图展示了图片打包后的占用,前面则表面了当前的图片使用了何种压缩。
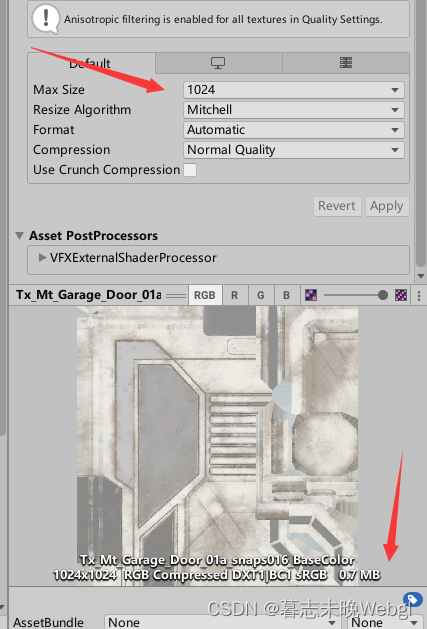
所以,不要在乎图片导入时的大小和尺寸,要在图片上进行设置,比如设置其最大1024。
压缩格式
首先,科普一下bpp,比如4 bpp,意思为每个像素占用4bit 应为 4bit per pixel。
- 移动端常用格式 有损压缩
PVRTC: RGBA 4 bpp 尺寸要求正方向
ETC2:RGBA 8 bpp 尺寸要求为4的倍数
ASTC 4x4 :RGBA 8 bpp 尺寸要求4的倍数(还有6x6 8x8 要求符合相应的倍数),它支持HDR
默认则为RGBA 32bit 占用比其它大至少四倍 - PC常用格式
DXT:RGB 4 bpp 尺寸要求为2的幂次方 不透明纹理常用
BC7:RGBA 8bpp 尺寸要求为2的幂次方 支持透明通道
BC6H:RGBA(HDR)8 bpp 支持HDR
unity官方纹理压缩文档
3. 开启minmap可以有效降低带宽,但是会增加内存 33%
4. 各向异性过滤,建议不开启或者只单独处理
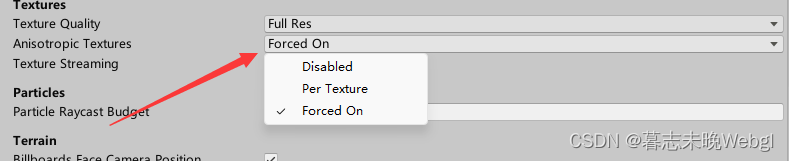
它是默认开启的,一般设置Per Texture,然后需要在图片上开启。
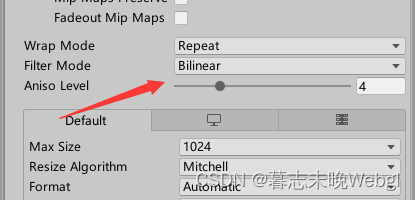
开启以后会增加采样,会降低纹理mipmap过渡时的锯齿。
5. 如果ui图片的尺寸不符合标准,会采用无损压缩,会造成浪费。
Mesh
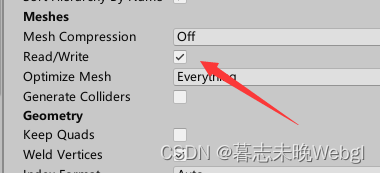
- 注意写入的开启,开启状态内存占用会翻倍
- 骨骼模型要着重注意面数,比较影响性能,因为它的动画需要每帧计算顶点位置
资源相关检查工具
-
纹理和Mesh的检查工具,可以一键查看相关占用
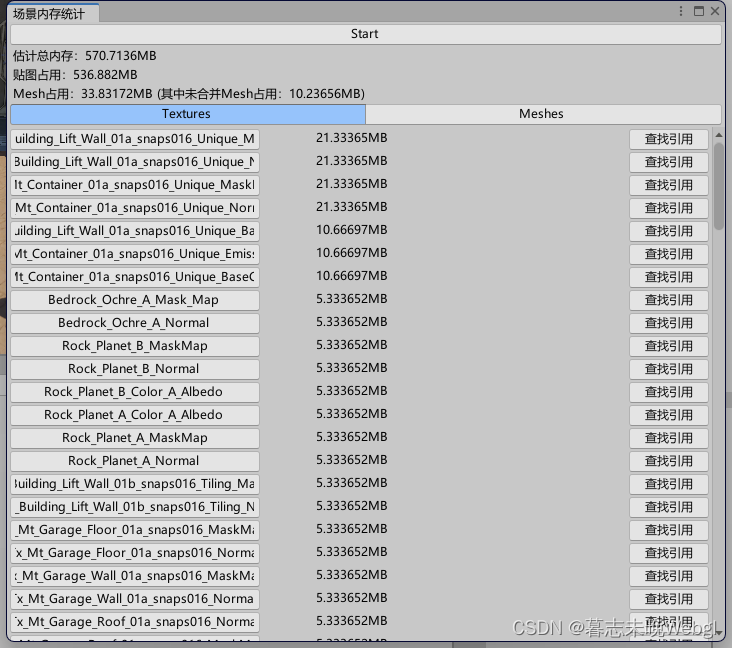
可以一键检查出对应的大文件。
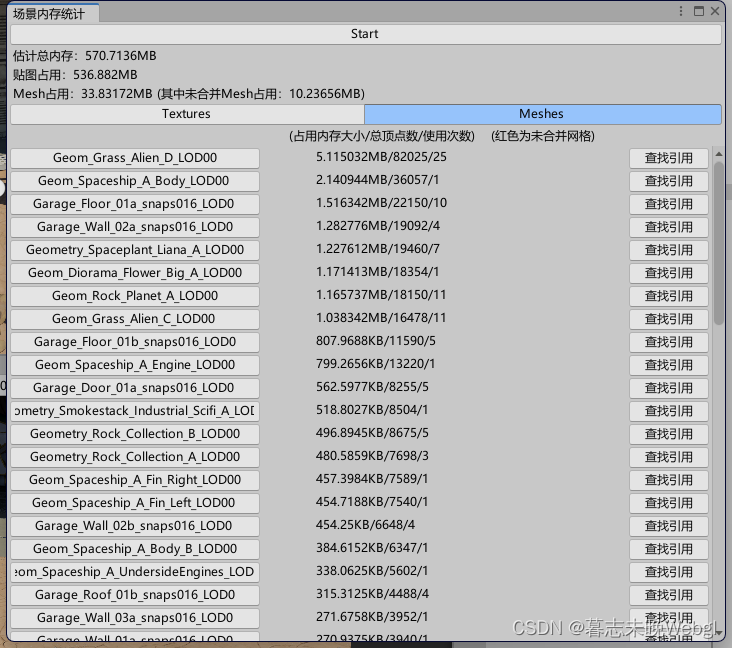
Mesh统计了使用次数的总占用,可以清晰的查看当前Mesh在场景的总占用。红色为未合并网格。 -
贴图相关检测
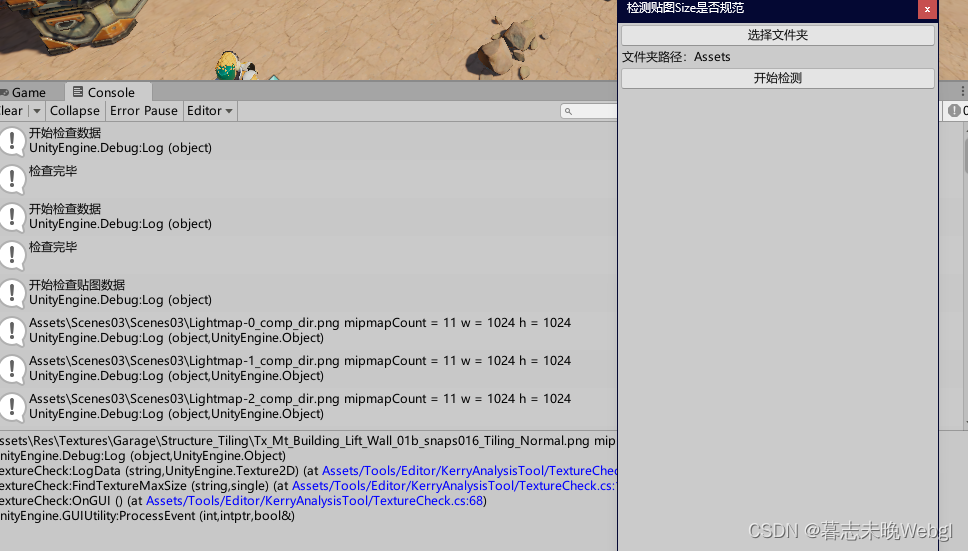
可以检测贴图的尺寸是否规范
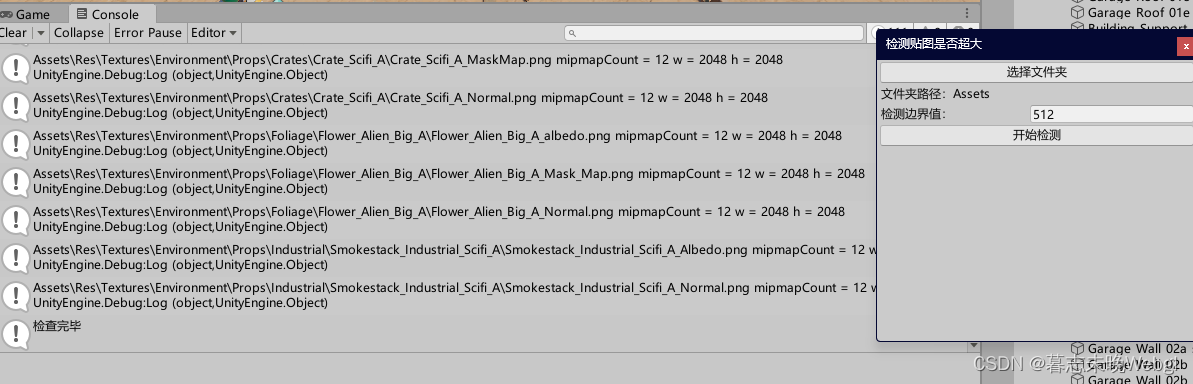
可以检测贴图尺寸是否过大
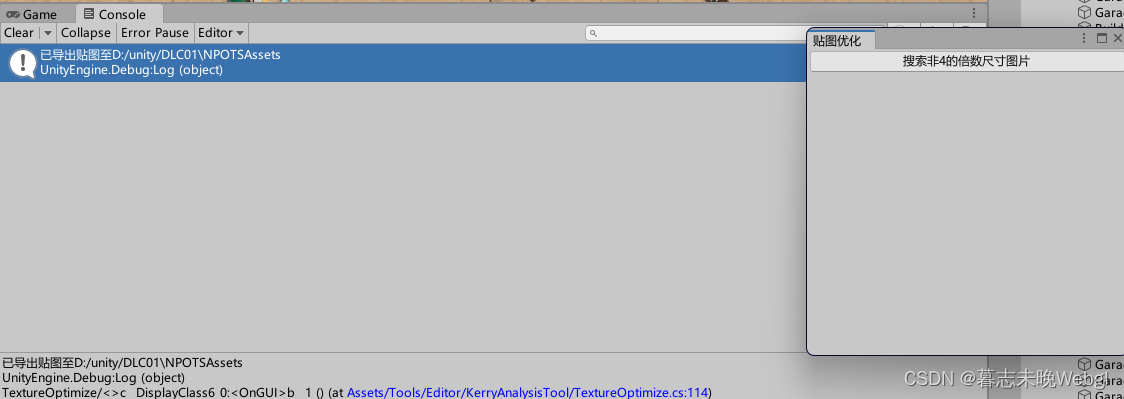
会将非4的倍数的图片导出到相应文件夹,然后美术同学可以修改完成图片后,对资源进行替换。 -
shader相关检查
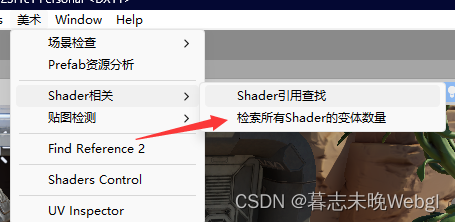
可以查看所有shader变体数量
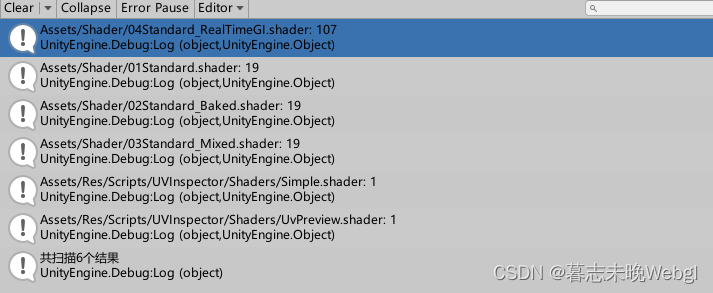
可以打印出项目中shader的所有变体数量。
变体减少的办法就是减少宏的使用,如果没办法,就少用multi_compile,使用shader_feature
变体的相关使用 点击此处看官网 -
资源引用查找
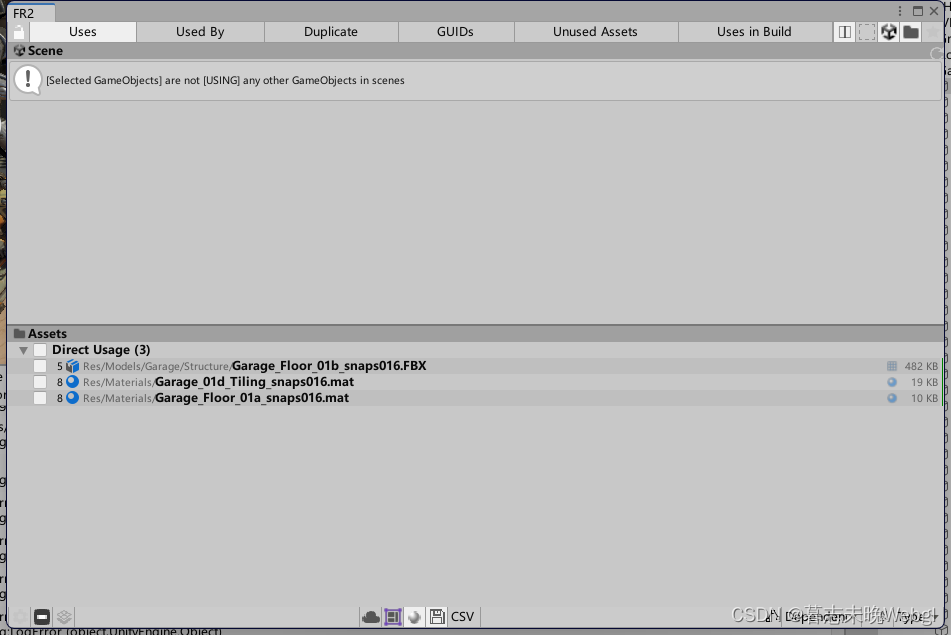
可以查看资源之间的互相引用,Uses可查看使用的资源,Used By可以查看被引用,Unused Assets查看没有被使用的资源
可以选中物体进行查看相关引用,或者向上查找 -
Prebe资源分析
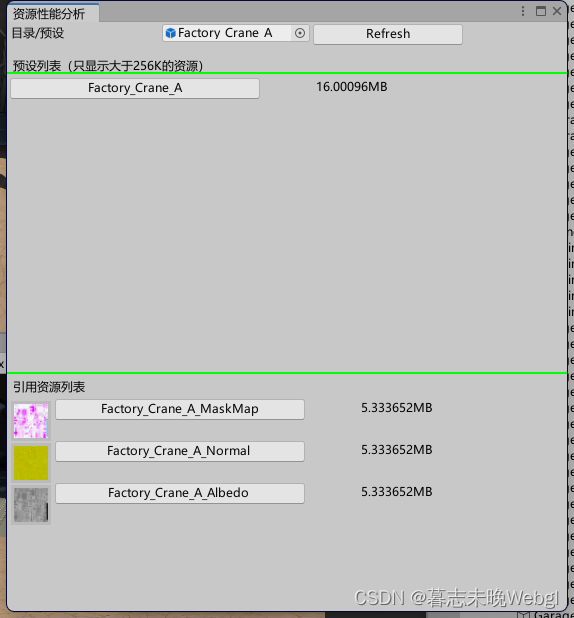
查找一个Prefab的资源引用分析,以及占用。
蒙皮动画
蒙皮动画也在游戏运行时占用比较大的性能,一般都会有一些方式解决,这里我推荐之前项目中使用的,使用GPU Skining + LOD,近处的模型使用默认蒙皮动画,保证效果,远处的角色模型,则使用低模+顶点动画烘焙动画贴图,根据颜色像素转换反向和距离,重新生成顶点位置绘制,这种方式还支持合批甚至GPU Instancing提高性能。
资源的加载
资源加载有时也会出现卡顿的情况 查看官方文档,这个一般需要程序同学协助完成。
Shader的加载
默认情况下,Shader会在首次渲染几何体是进行加载,这也是我们减少变体的原因之一。如果使用了相同的变体和Shader,渲染新的几何体时,将不会在重新加载Shader。
有时会运行卡顿,我们可以使用预加载的形式进行Shader加载。

UI的优化
优化unity UI,这是先备份一下,需要时再看。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结