您现在的位置是:首页 >学无止境 >如何评估现代处理器的性能——以ARM Cortex-A53为例网站首页学无止境
如何评估现代处理器的性能——以ARM Cortex-A53为例
如何评估现代处理器的性能——以ARM Cortex-A53为例
1 有哪些通用评价指标?
现代处理器内核的性能可以从以下几个方面进行评估:
时钟速度(Clock Speed):它是CPU内部时钟发生器的频率,以赫兹(Hz)为单位。时钟速度越高,每秒钟内执行的指令数就越多,因此性能也会更好。
指令级并行性(ILP):现代处理器采用了一些技术来提高指令级并行性,如超标量、超线程等。这些技术可以同时执行多条指令。
流水线(Pipeline):现代处理器还采用了流水线技术来提高性能。流水线将指令分成多个阶段,并且同时执行多个指令,从而使得处理器每个时钟周期可以完成更多的工作。
缓存(Cache):缓存是一种快速的存储设备,用于暂时存储处理器需要使用的数据和指令。现代处理器内置了多级缓存系统,从而可以大大降低访问内存的延迟,提高处理器的性能。
向量化(Vectorization):向量化是一种并行计算技术,可以同时处理一组数据。现代处理器内置了向量化指令集,如SSE、AVX等,可以在单个时钟周期内执行多个操作。
芯片工艺(Process Technology):芯片工艺是指用于制造处理器的制造工艺。随着芯片工艺的不断进步,处理器的晶体管数量和频率都有了大幅度提升。
2 为什么不再使用MIPS指标?
MIPS代表每秒钟可以执行的百万条指令数。具体来说,MIPS值等于 CPU执行的指令总数除以执行这些指令所花费的时间(单位为秒),再除以一百万。
在过去,MIPS评价处理器内核性能被广泛使用是因为它是衡量计算机性能的一种简单而直观的方式。然而,在现代计算机中,MIPS已经不再被广泛使用来评估处理器的性能,原因如下:
处理器架构复杂:现代处理器的架构非常复杂,包括多级缓存、预取和超标量执行等功能,这些都使得MIPS评价成为不够准确的性能指标。
指令集变化:随着处理器指令集的变化,MIPS评价可能会失去其原有的意义。例如,现代处理器引入了向量指令,可以实现并行计算,但这不会反映在MIPS评价中。
单纯指令计数难以反映性能提升: 现代处理器通常会使用更短的指令序列来完成相同的操作,从而提高性能,这些性能提升很难通过简单的指令计数进行比较。
不同应用场景需要不同指标: 不同的应用场景需要不同的性能指标,例如,数据库系统需要高并发、低延迟的I/O操作,而图像处理则需要高吞吐量的向量计算。在这些应用场景中,MIPS评价可能无法提供有用的信息。
因此,现代计算机中常用的处理器性能指标包括时钟频率、IPC(每时钟周期指令数)、功耗和浮点运算性能等。这些指标可以更准确地衡量处理器性能,并且可以根据不同的应用场景进行定制化的性能评估。
3 主推何种评价指标?
现代计算机中常用的处理器性能指标包括时钟频率、IPC(每时钟周期指令数)、功耗和浮点运算性能等。这些指标可以更准确地衡量处理器性能,并且可以根据不同的应用场景进行定制化的性能评估。
《计算机体系结构量化研究方法》的作者约翰• L.亨尼西(John L. Hennessy) 和大卫•A.帕特森(David A. Patterson)认为时钟周期时间、CPI(1/IPC,执行每条指令需要的时钟周期数)和指令数量这三个评价指标能够综合反映某个计算机系统的性能。

4 为什么选择这些指标?
究其原因,就是上一节那张图里的约束条件了。
emmm首先我们要意识到,仅仅关注指令数量和主频是不够的。可执行文件中的指令数是受到指令集体系结构和编译器技术制约的。对于同样的测试程序/负载,我们使用不同的编译器编译产生的指令数量可能不同。即使是同样的编译器和程序,在目标架构不同时,输出文件的指令数也可能有差异。
GCC的编译过程分为四个阶段:预处理、编译、汇编和链接。在预处理阶段,预处理器将源代码转换为一个更大的、包含了所有头文件和宏替换的单一文件。在编译阶段,编译器将这个单一文件翻译成汇编代码。在汇编阶段,汇编器将汇编代码转换成二进制目标文件。最后,在链接阶段,链接器将多个目标文件组合成一个可执行文件。
LLVM的编译过程分为三个主要阶段:前端、优化和后端。在前端阶段,源代码被翻译成一个中间表示(IR),这种表达方式非常接近于高级语言的语法。在优化阶段,LLVM将IR进行各种优化操作以提高程序性能。在后端阶段,IR会被翻译成目标平台的机器码。这种模块化的设计使得LLVM更易于扩展和定制,因为用户可以用自己的前端或后端替换默认实现。而且,LLVM还可以生成可重定向的对象文件,这些对象文件可以在链接时进行优化。
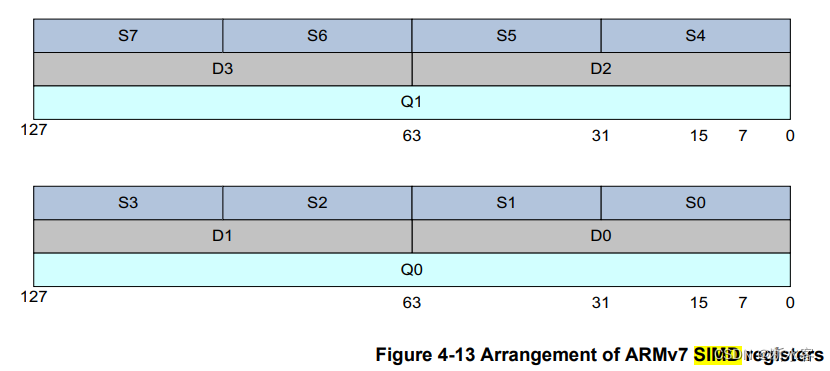
其次就是组成与指令集体系结构会影响CPI,比如总线宽度、主存速率,都会拖处理核的后腿。对于支持向量运算的处理核,即使每条指令需要的周期数比不支持向量指令的处理核多3倍,它也可能比后者更快地完成同一个运算任务。比如下图所示,armv7支持Dn/Qn寄存器,分别可以存64bits/128bits的数据,这样每次可以运算2/4个32位浮点数,自然就能更快地做完一批运算。
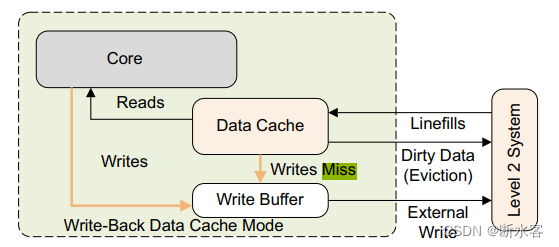
最后咱也不能迷信主频,和CPI一样,处理核周围的设备的速率也可能会制约处理核发挥真正的实力。即时处理核能跑4GHz,cache却总是miss(cache太小),或者总线总是处于忙碌状态(位宽不够),这样系统的吞吐量也是上不去的。
5 ARM Cortex-A53的性能
我找到有人对A53的IPC和FOP两个参数做了测试,结果贴在这里用作参考。
每周期指令数(IPC)
32bit浮点类型数乘/加运算任务,每周期可执行两个标量/SIMD 2(64bits)操作指令,每周期执行1个SIMD 4(128bits) 操作指令。
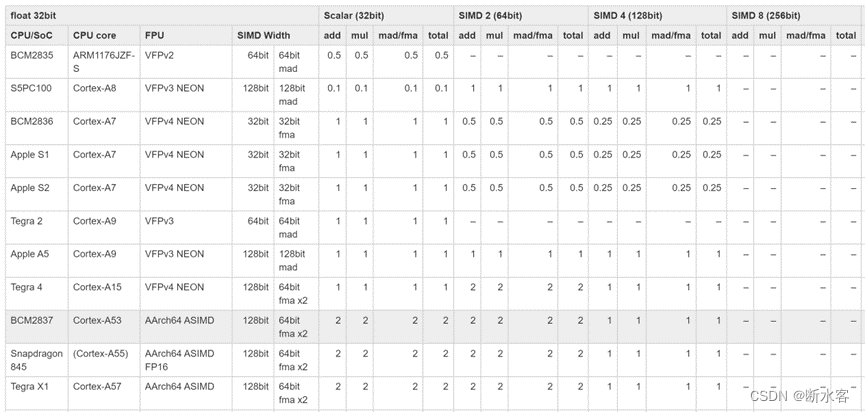
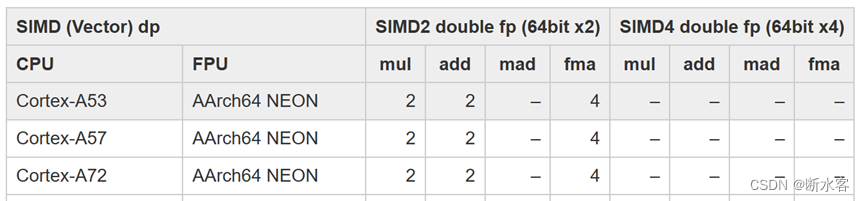
64bits浮点类型数乘/加运算任务,每周期可执行两个标量操作指令,每周期执行1个SIMD 2(128bits) 操作指令。

每周期浮点运算次数(FOP)
每周期可执行两次标量单/双精度浮点运算。
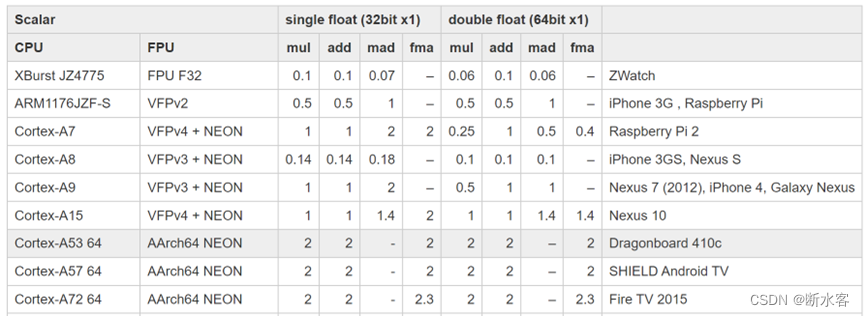
使用SIMD情况下,每周期可执行4次单精度浮点运算,8次乘积累加运算(FMA)。
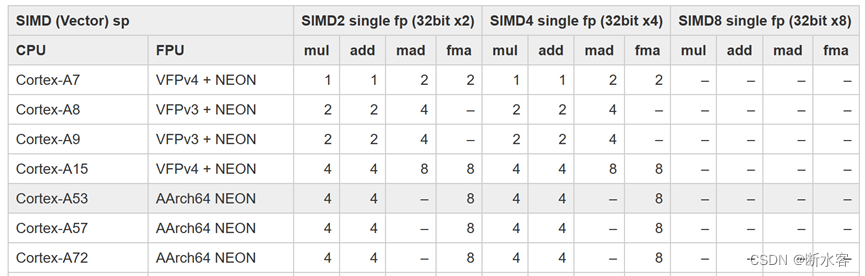
使用SIMD情况下,每周期可执行2条双精度浮点运算,4次乘积累加运算(FMA)。
参考






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结