您现在的位置是:首页 >技术杂谈 >【读论文】(个人对DETR的理解)End-to-End Object Detection with Transformers网站首页技术杂谈
【读论文】(个人对DETR的理解)End-to-End Object Detection with Transformers
论文讲解:https://www.bilibili.com/video/BV1GB4y1X72R/?spm_id_from=333.337.search-card.all.click&vd_source=7e5eb1b53aea4e859474207d5132cffa
论文翻译:https://zhuanlan.zhihu.com/p/362945932
注:该文记录自己在学习DETR、以及看论文过程中对该模型的理解。由于已经有很多大佬翻译了该论文,且沐神和bryanyzhu大佬对该论文已进行详细的讲解,因此该文其实是对这些公开学习资料的总结以及个人见解。参考链接上面给出
目录
End-to-End Object Detection with Transformers论文理解
以前的目标检测模型很少有端到端的方法,都需要一个后处理操作比如NMS操作,用来去除冗余的框。
这里提出的DETR不需要proposal,也不需要Anchor,直接利用Transformer这种能够全局建模的能力,把目标检测看成集合预测。这样就没有那么多Anchor,没有那么多框(每个检测目标只出一个框),也就不需要NMS,因此就没有那么多的超参数要去调了。
DETR步骤:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CdUd9TEL-1682949558522)(TyporaFiles/images/image-20230501210227984.png)]](https://img-blog.csdnimg.cn/cf9d4e8c2f8a43f4a408a0ae11b8e54f.png)
Fig. 1: DETR通过将普通CNN与transformer架构相结合,直接(并行)预测最后的检测结果集合。在训练过程中,二部匹配框唯一地将真实框(ground truth boxes)分配给预测结果。没有匹配的预测结果应该产生一个no object(∅)类的预测。
第一步:卷积神经网络(CNN)抽特征
第二步:用Transformer encoder学习全局特征
使用了Transformer encoder,那每一个点,或者说每一个特征,就跟这个图片里其他的特征有交互了,这样网络就大概知道哪块是哪个物体,哪块又是另一个物体了,就能实现对同一个物体只出一个框了,这种全局处理,可以很好的去除冗余的框。
第三步:就是用Transformer decoder生成预测框,上图中没有体现object query
decoder的输入为encoder输出的编码矩阵、位置编码以及可学习的object queries矩阵。它仍然遵循transformer的标准结构,使用multi-head self-attention模块处理维度为(N,256)维的张量object queries得到N个预测值。但与原始的transformer使用自回归模型一次预测一个元素最终得到预测序列不同的是,DETR并行的解码object queries得到output embedding,维度为(N,256),它们通过FFN独立地预测出box prediction和class label。
3.1 object queries编码矩阵
object queries是可学习的位置编码,被添加到decoder中每个自注意力层的输入中。该矩阵可以看成有N个不同的人从N个角度向模型提问当前位置是否有目标。在网络中的作用类似于给网络划重点,让网络着重关注这几个部分。图4是20个prediction slots(out of N=100 prediction slots)对coco数据集每张图片预测到的目标框中心点的可视化。
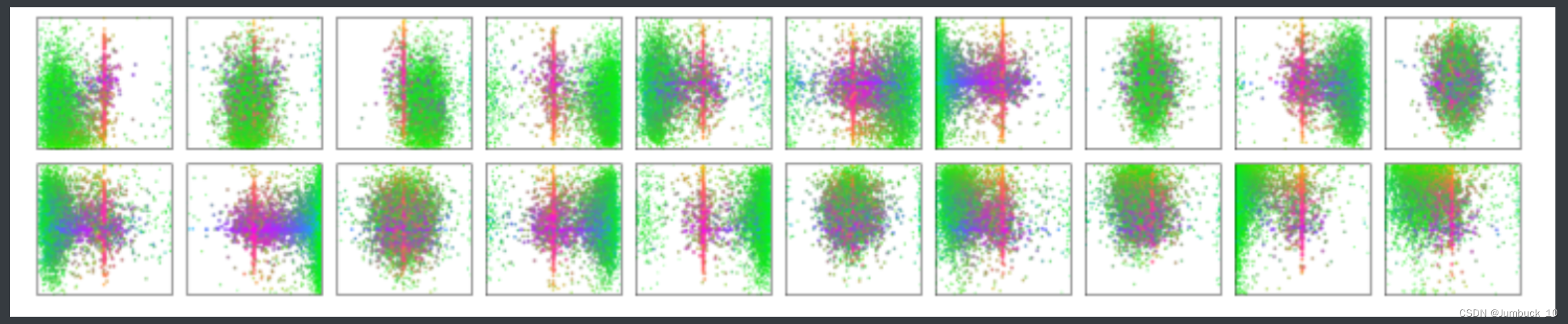
图4 图中绿色的点对应小目标的框的中心点,红色对应大目标水平方框的中心点,蓝色对应大目标垂直方框的中心点。
由图4可以发现,每个object queries上的slot都学会了在某些区域以及box尺寸上专门的operating mode。而几乎所有的slot都有一种预测大型目标的operating mode,因为大目标在coco数据集中是很常见的。
第四步:把生成的预测框和ground Truth的框做一个匹配
4.1 FNN
最终预测是由三层的FFN计算得到的,FFN使用ReLU激活函数。FFN根据decoder的output emdedding得到归一化的预测bounding-box(包括中心坐标、高度和宽度),然后使用softmax函数预测类标签。
推理的时候没有第四步,直接卡一个置信度即可
此外,DETR可以直接在后边加一个分割的检测头,前边的主干网络都不用动即可实现分割任务。
but
DETR小物体检测不怎么样,而且训练还特别慢,需要500个epoch,但是作者很巧妙的引入了别的优点比如多任务、遍地开花。
二分图匹配??(使用匈牙利算法)
DeformableDETR通过多尺度特征解决了小物体检测的问题,还解决了训练慢的问题






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结