您现在的位置是:首页 >技术教程 >机器学习 -- 过拟合与欠拟合以及应对过拟合的方法 神经网络中的超参数如何选择网站首页技术教程
机器学习 -- 过拟合与欠拟合以及应对过拟合的方法 神经网络中的超参数如何选择
前言
在学习机器学习的过程中,训练模型时常遇到的问题就是模型的过拟合和欠拟合,下文我将解释过拟合和欠拟合的概念,并且学习应对过拟合以及神经网络中的超参数如何选择的方法。
过拟合和与欠拟合
过拟合:是指学习时选择的模型包含的参数过多,以至于出现这一模型对已知的数据预测的很好,但对未知的数据预测的很差的情况。这种情况下的模型可能知识记住的训练数据,而不是学习到了数据特质。
欠拟合:模型描述能力太弱,以至于不能更好的学习数据中的规律,产生欠拟合的原因常常是模型过于简单。
学习过程中的过拟合
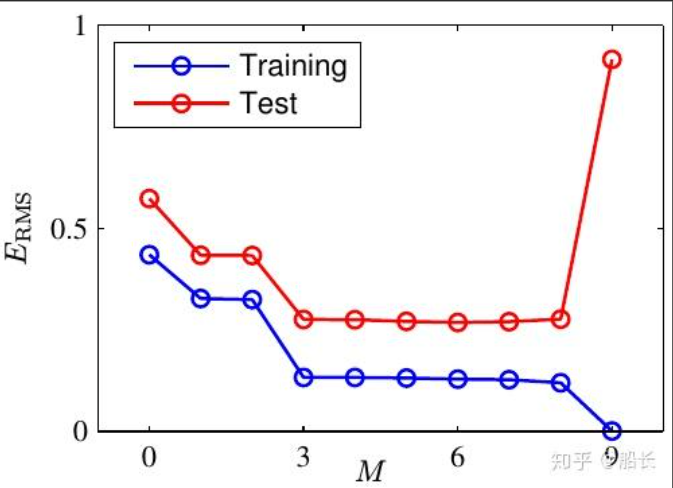
- 机器学习的根本问题是优化的泛化的问题
- 优化:是指调节模型以在训练数据上得到最佳性能
- 泛化:是指训练好的模型在前所未见的数据上的性能好坏
训练初期:优化和泛化是相关的,训练集上的误差越小,验证集上的误差也越小,模型的泛化能力逐渐增强。
训练后期:模型在验证集上的错误率不再降低,转而变高,模型出现过拟合,开始学习仅和训练集有关的模式。
如何应对过拟合
最优方案:获取更多的训练数据
如果模型能够记住世界上所有的数据,那么就不用担心过拟合的问题。
次优方案:调节模型允许储存的信息量或者 对模型允许储存的信息加以约束,这类方法也称为正则化
- 调节模型大小
- 约束模型权重,即权重正则化(常见的有L1、L2正则化)
- 随机失活

L2正则损失对于大数值的权重向量进行严厉惩罚,鼓励更加分散的权重向量,使模型倾向于使用所有输入特征做决策,此时的模型泛化性能好。
随即失活
- 随即失活:让隐层的神经元以一定的概率不被激活
- 实现方式:训练过程中,对某一层使用随机失活,就是随机将该层的一些输出舍弃(输出变为0),这些被舍弃的神经元就好像被网络删除了一样。
- 随机失活比率:是被设为0的特征所占的比例通常在0.2-0.5的比例中。
随机失活为什么能够防止过拟合?
- 解释1:随机失活是的每次更新梯度时参与计算的网络参数减少了 ,降低了模型容量,所以能够防止过拟合。
- 解释2:随机失活鼓励权重分散,从这个角度来看随机失活也能起到正则化的作用,进而防止过拟合。
- 解释3:Dropout可以看作模型集成
神经网络中的超参数
- 网格结构–隐层神经元个数,网格层数,非线性单元等。
- 优化相关–学习率、dropout比率、正则项强度等。
超参数的重要性:如果学习率设置过大,训练过程中损失函数就无法收敛,如果学习率偏大,损失函数会在最小值附件震荡,达不到最优,学习率太小,收敛时间较长,学习率适中,收敛快、结果好。所以超参数在训练过程中的设置是非常重要的,一个好的超参数也会决定模型的好坏。
超参数优化方法
网格搜索法:
- 1、每个超参数分别取几个值,组合这些超参数值,形成多组超参数
- 2、在验证集上评估每组超参数的模型性能
- 3、选择性能最优的模型所采用的那组值作为最终的 超参数的值。
随机搜索法:
- 1、参数空间内随机取点,每个点对于一组超参数
- 2、在验证集上评估每组超参数的模型性能
- 3、选择性能最优的模型所采用的那组值作为最终的超参数的值。
超参数搜索策略
- 粗搜索:利用随机法在较大范围里采样超参数,训练一个周期,依据验证集正确率缩小超参数范围。
- 精搜索:利用随机法在前述缩小的 范围内采样超参数,允许模型五到十个周期,选择验证集上精度最高的那组超参数。
建议:对于学习率、正则项强度这类超参数,在对数空间上进行随机采样更合适。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结