您现在的位置是:首页 >学无止境 >【数据生成】——Semantic Image Synthesis via Diffusion Models语义分割数据集生成论文浅读网站首页学无止境
【数据生成】——Semantic Image Synthesis via Diffusion Models语义分割数据集生成论文浅读
语义分割,数据生成

摘要
Denoising Diffusion Probabilistic Models (DDPMs) 在各种图像生成任务中取得了显著的成功,相比之下,生成对抗网络 (GANs) 的表现不尽如人意。最近的语义图像合成工作主要遵循事实上的基于 GAN 的方法,这可能导致生成图像的质量或多样性不尽如人意。在本文中,我们提出了一种基于 DDPM 的语义图像合成的新框架。与以前的条件扩散模型直接将语义布局和噪声图像作为输入到 U-Net 结构不同,我们的框架对语义布局和噪声图像进行了不同的处理。它将噪声图像输入到 U-Net 结构的编码器中,而将语义布局通过多层空间自适应归一化算子输入到解码器中。为了进一步提高语义图像合成中的生成质量和语义可解释性,我们引入了无分类器引导采样策略,该策略承认无条件模型的得分用于采样过程。
1. 简介
直接将条件信息与噪声图像作为去噪网络的输入是不充分利用输入语义掩码中的信息的,这会导致生成的图像质量低且与语义相关性差。为此,我们设计了一个条件去噪网络,它独立处理语义布局和噪声图像。噪声图像被输入到去噪网络的编码器中,而语义布局通过多层空间自适应归一化算子嵌入到去噪网络的解码器中。这大大提高了生成图像的质量和语义相关性。
此外,扩散模型本身具有生成多样结果的能力。采样策略在平衡生成结果的质量和多样性方面起着重要作用。简单的采样过程可以生成具有高多样性但缺乏真实感和与语义标签图强相关性的图像。受[13]启发,我们采用无分类器引导策略来提高图像保真度和语义相关性。具体来说,我们通过随机删除语义掩码输入来微调预训练的扩散模型。然后,采样策略基于扩散模型在有和没有语义掩码时的预测进行处理。通过插值这两种情况下的得分,采样结果达到更高的保真度和与语义掩码输入更强的相关性。
2. 相关工作
略
3. 方法
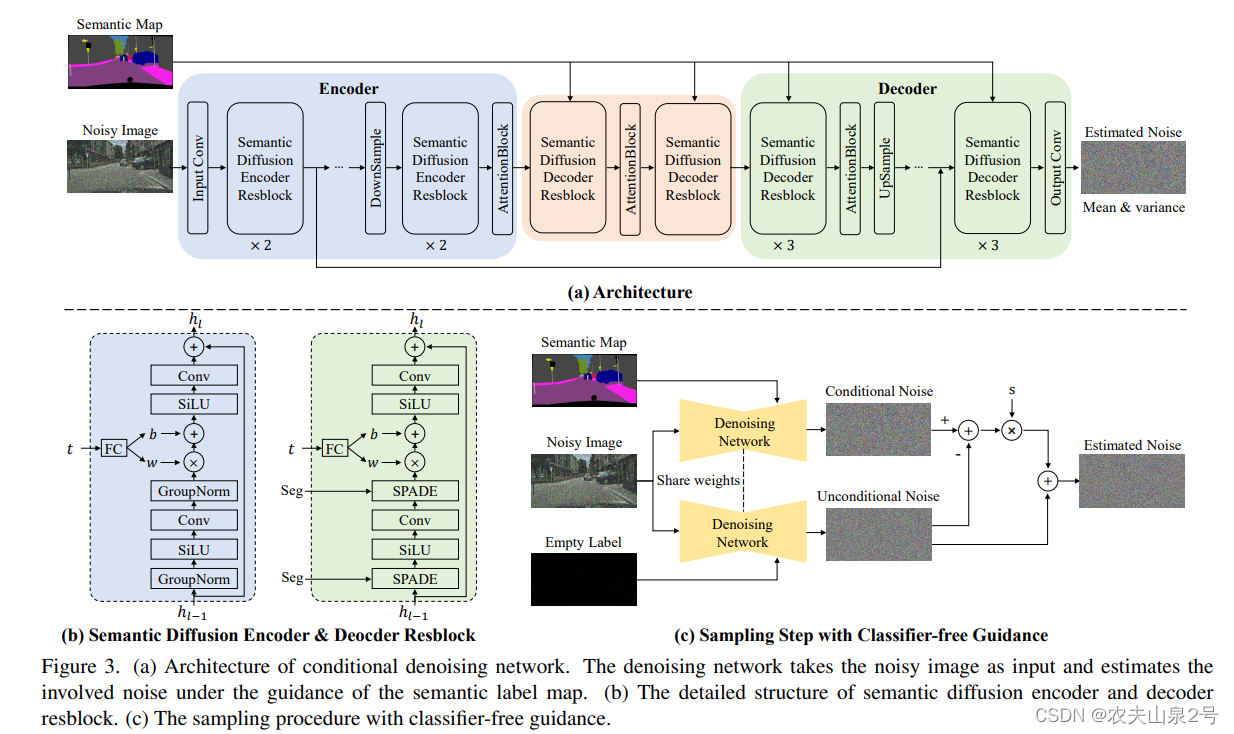
整体架构
SDM 的条件去噪网络是一个基于 U-Net 的网络,用于估计输入噪声图像中的噪声。与先前的条件扩散模型不同,我们的去噪网络独立处理语义标签图和噪声图像。噪声图像被馈入去噪网络的编码器部分。为了充分利用语义信息,语义标签图通过多层空间自适应归一化算子注入到去噪网络的解码器中。
图像编码部分
编码器。我们使用堆叠的语义扩散编码器残差块(SDEResblocks)和注意力块对噪声图像的特征进行编码。我们在图 3(b)中展示了 SDEResblocks 的详细结构,它由卷积、SiLU 和组归一化组成。SiLU [33] 是一个激活函数,简单地说就是 f(x) = x · sigmoid(x),它在更深层次的模型上比 ReLU [28] 更好。为了使网络在不同的时间步长 t 估计噪声,SDEResblock 通过学习权重 w(t) ∈ R1×1×C 和偏置 b(t) ∈ R1×1×C 来缩放和移动中间激活值,并将 t 纳入其中。
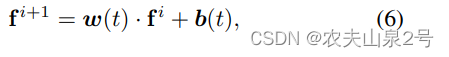
编码器部分的attention 模块是 self attention
语义解码部分
我们将语义标签图注入到去噪网络的解码器中,以指导去噪过程。重新审视先前的条件扩散模型[35,36],它们直接将条件信息与噪声图像作为输入连接起来,我们发现这种方法并没有充分利用语义信息,导致生成的图像质量低且语义相关性弱。为了解决这个问题,我们设计了语义扩散解码器残差块(SDDResblock)(见图 3(b)),以多层空间自适应方式将语义标签图嵌入到去噪网络的解码器中。与 SDEResblock 不同,我们引入了空间自适应归一化(SPADE)[31]来代替组归一化。SPADE 通过调节特征中的空间自适应、可学习转换来将语义标签图注入到去噪流中
SPADE 通过调节特征中的空间自适应、可学习转换来将语义标签图注入到去噪流中。具体来说,它的公式如下:f_i+1 = γ_i(x) · Norm(f_i) + β_i(x),其中 f_i 和 f_i+1 分别是 SPADE 的输入和输出特征。Norm(·) 指的是无参数的组归一化。γ_i(x) 和 β_i(x) 分别是从语义布局中学习的空间自适应权重和偏置。值得一提的是,我们的框架与 SPADE [31] 不同,因为我们的 SDM 是专门为扩散过程设计的,具有注意力块、跳跃连接和时间步长嵌入模块,而 SPADE 则没有。
损失函数
- 输出噪声估计
- 遵循改进的去噪扩散模型[30],我们进一步训练网络来预测方差Σθ(y, x, t e ),以提高生成图像的对数似然。条件扩散模型还额外输出每个维度的插值系数 v,并将输出转换为方差,
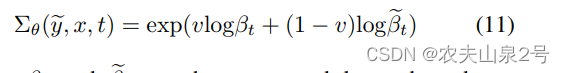
无分类器引导策略
图3.c 中的策略,其核心思想是将在语义标签图指导下估计的噪声 θ(yt|x) 与无条件情况 θ(yt|∅) 分离。相当于减去无条件的噪声
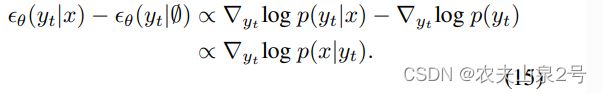
sample 的每一步会减掉无语义标签的噪声
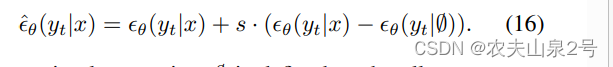
4. 实验
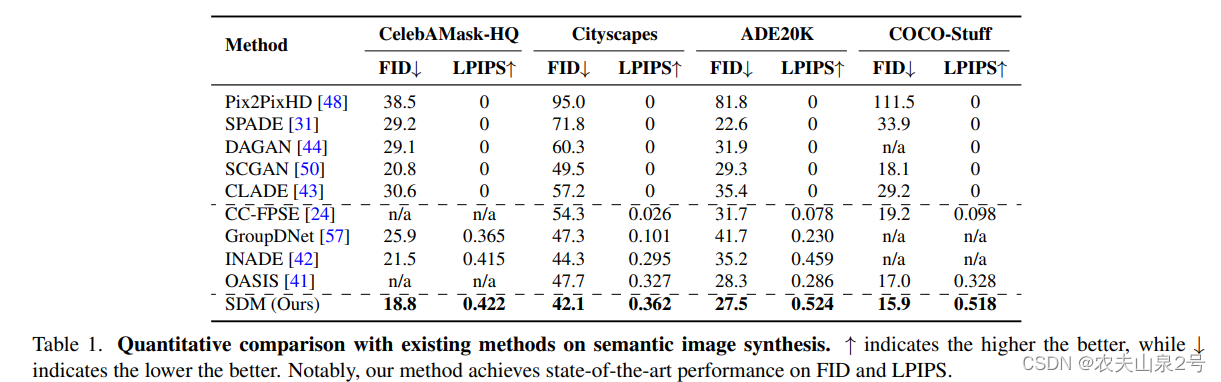
- 采用FID, FPIPS作为评价指标
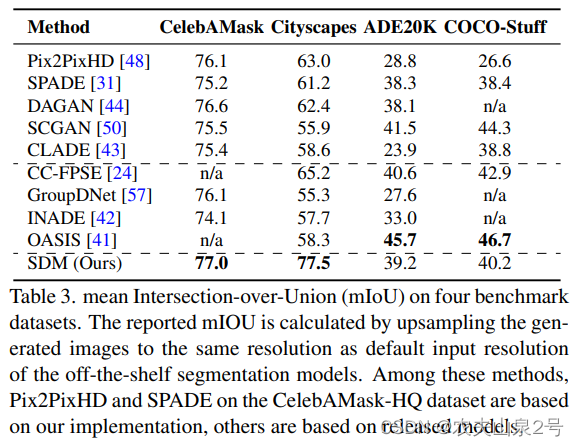
- 为了评估学习到的对应关系,我们使用现成的网络来评估生成结果的“语义可解释性”。我们使用 DRN-D-105 [52] 用于 Cityscapes,UperNet101 [51] 用于 ADE20K,Unet [20, 34] 用于 CelebAMask-HQ 和 DeepLabV2 [4] 用于 COCO-Stuff。使用现成的网络,基于生成的图像和语义布局计算平均交集并集(mIoU)
MIOU
语义编码和无分类器采样策略的影响
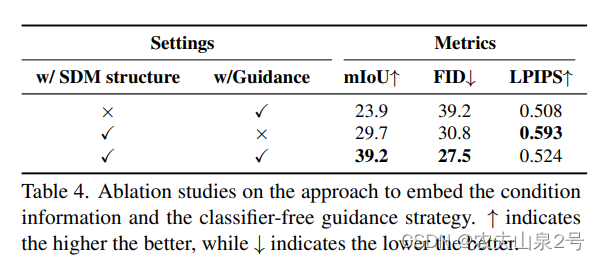
为了评估独立于噪声图像嵌入条件信息的重要性,我们设计了一个基线变体作为比较。作为替代方案,我们直接应用条件 DDPM [35,36],它直接将语义标签图与噪声图像作为输入连接起来。从上表,观察到我们的语义扩散模型在所有指标上都高度优于先前的条件 DDPM。此外,我们分析了这两个变体之间的视觉结果。在图 9 中,可以看到,通过以多层空间自适应方式嵌入语义标签图,生成的图像在保真度和与语义标签图的对应关系上展示出更优异的视觉质量。
分类器无引导的重要性。此外,我们研究了分类器无引导策略的有效性。我们将没有分类器无引导的变体作为比较。从表 4 中可以看出,分类器无引导大大提高了 mIoU 和 FID 指标,而 LPIPS 损失很小。在图 9 中,我们展示了分类器无引导策略的定性结果。使用分类器无引导生成的图像更好地展示了语义信息并生成了更多结构化内容。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结