您现在的位置是:首页 >技术杂谈 >GLM:ChatGLM的基座模型网站首页技术杂谈
GLM:ChatGLM的基座模型
介绍
ChatGLM-6B:https://github.com/THUDM/ChatGLM-6B ,主要是能够让我们基于单卡自己部署。ChatGLM的基座是GLM: General Language Model Pretraining with Autoregressive Blank Infilling论文中提出的模型。
动机
预训练语言吗模型大体可以分为三种:自回归(GPT系列)、自编码(BERT系列)、编码-解码(T5、BART),它们每一个都在各自的领域上表现不俗,但是,目前没有一个预训练模型能够很好地完成所有任务。GLM是一个通用的预训练语言模型,它在NLU(自然语言理解)、conditional(条件文本生成) and unconditional generation(非条件文本生成)上都有着不错的表现。
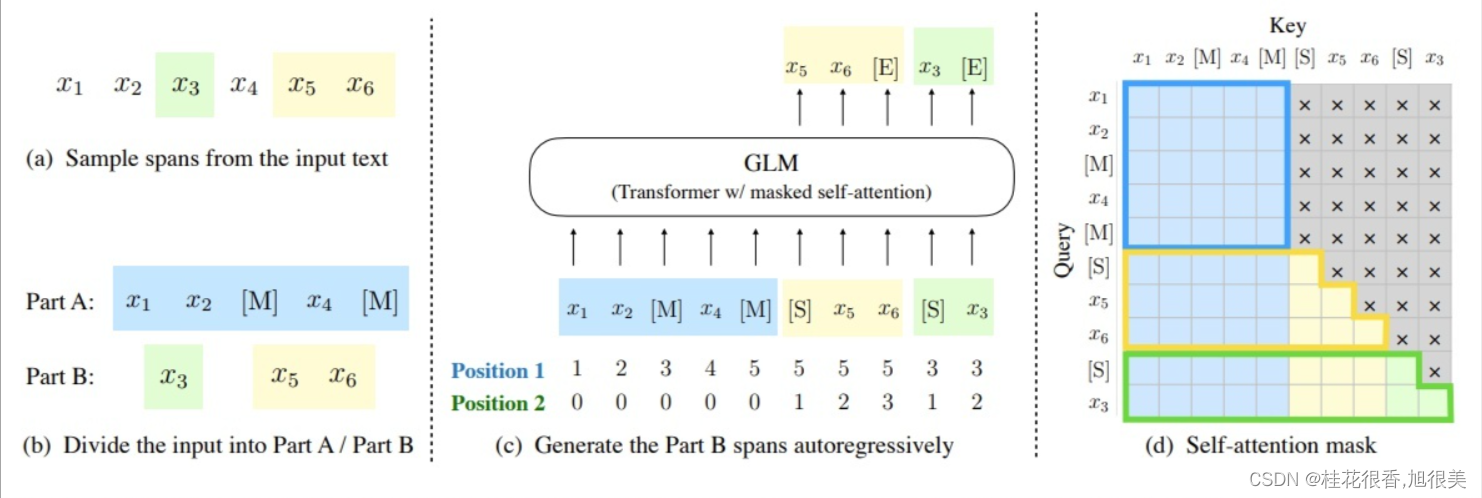
GLM的核心是:Autoregressive Blank Infilling
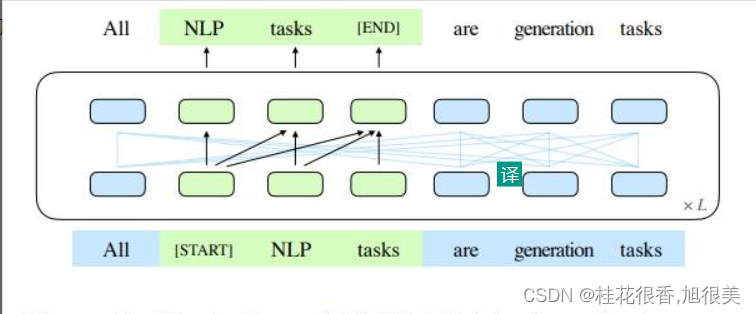
即,将文本中的一段或多段空白进行填充识别。

GLM 的 多任务训练
NLU 和 NLG 的 训练方式 是存在差异的,GLM 对于文档和句子采用不同的空白填充方式:
- 文档:span的长度从原始长度的50%-100%的均匀分布中抽取。该目标旨在生成长文本;
- 句子:限制masked span必须是完整的句子。多个span(句子)被取样,以覆盖15%的的原始标记。这个目标是针对seq2seq任务,其预测往往是完整的句子或段落。
GLM 模型架构
GLM 主要 在 Transformer 的 架构上进行 修改:
- 调整layer normalization和residual connection的顺序;
- 使用单一线性层进行输出token预测;
- 将ReLU激活函数替换为GeLUs;
在 NLG 中,GLM 如何让 模型 不知道 生成query 长度?
两个位置id通过可学习嵌入表投影到两个向量,这两个向量都被添加到输入标记嵌入中。
该编码方法确保模型在重建时不知道被屏蔽的跨度的长度。
这种设计适合下游任务,因为通常生成的文本的长度是事先未知的。
GLM 微调
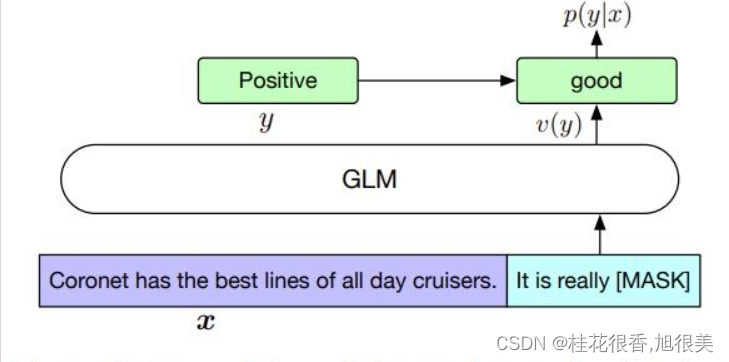
1 对 NLU任务 进行微调
对于 NLU任务,在模板后面预测类别。
- It’s a beautiful day, I’m in a great mood. it is [MASK]. [S] good
- I failed in the exam today. I was very depressed. it is [MASK] [S] bad
2 对 NLG任务 进行微调
对于 NLG任务 ,输入的文本视为A部分,在该部分后面添加[MASK],使用自回归来生成文本。
GLM 微调方式的优点
微调方式的优点 在于 能够预训练和微调是保持一致的。
参考
THUDM/ChatGLM-6B
GLM: General Language Model Pretraining with Autoregressive Blank Infilling
NLP 百面百搭
THUDM/GLM






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结