您现在的位置是:首页 >技术交流 >【Hello Network】HTTP协议网站首页技术交流
【Hello Network】HTTP协议
HTTP协议
HTTP协议
HTTP协议概念
HTTP(Hyper Text Transfer Protocol)协议又叫做超文本传输协议 是一个简单的请求-响应协议 HTTP通常运行在TCP之上
在编写网络通信代码时 我们可以自己进行协议的定制 但实际有很多优秀的工程师早就已经写出了许多非常成熟的应用层协议 其中最典型的就是HTTP协议
URL概念
首先我们要明白一个概念 我们每天上网的时候请求的图片 文章 css html等我们把它们称之为“资源”
同时我们服务器的后台是使用Linux做的
我们平时写程序的时候使用ip+port确定唯一一个进程 但是我们却无法确定唯一的一个资源
实际上我们所谓的资源都是被保存在网络中的Linux主机上的 而LInux中的所有东西我们都可以看作是一个文件 而文件一般是被保存在磁盘上的
所以说我们可以通过唯一的一个公网IP和路径来确定一份资源
而在我们的生活中IP一般是由域名来呈现的 路径则是由分隔符+目录名呈现
那么什么叫做URL呢?
URL(Uniform Resource Lacator)叫做统一资源定位符也就是我们通常所说的网址

其中服务器地址就是域名对应着我们的IP地址 带层次的文件路径实际上就是我们Linux中的路径
接下来我们来较为全面的认识下上面URL
一、协议方案名
http://表示的是协议名称 表示请求时需要使用的协议 通常使用的是HTTP协议或安全协议HTTPS
HTTPS是以安全为目标的HTTP通道 在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性
二、登录信息
usr:pass表示的是登录认证信息 包括登录用户的用户名和密码
虽然登录认证信息可以在URL中体现出来 但绝大多数URL的这个字段都是被省略的 因为登录信息可以通过其他方案交付给服务器
三、服务器地址
www.example.jp表示的是服务器地址 也叫做域名
什么是域名?
域名是IP地址的助记符 便于用户记忆和访问 世界上任何网站都不存在重复域名
简单来理解 他就是为了方便我们记忆而设计出来和IP地址一一对应的助记符
我们之前访问的www.baidu.com www.qq.com 其实都是域名
我们可以在Linux上尝试ping一下这些域名
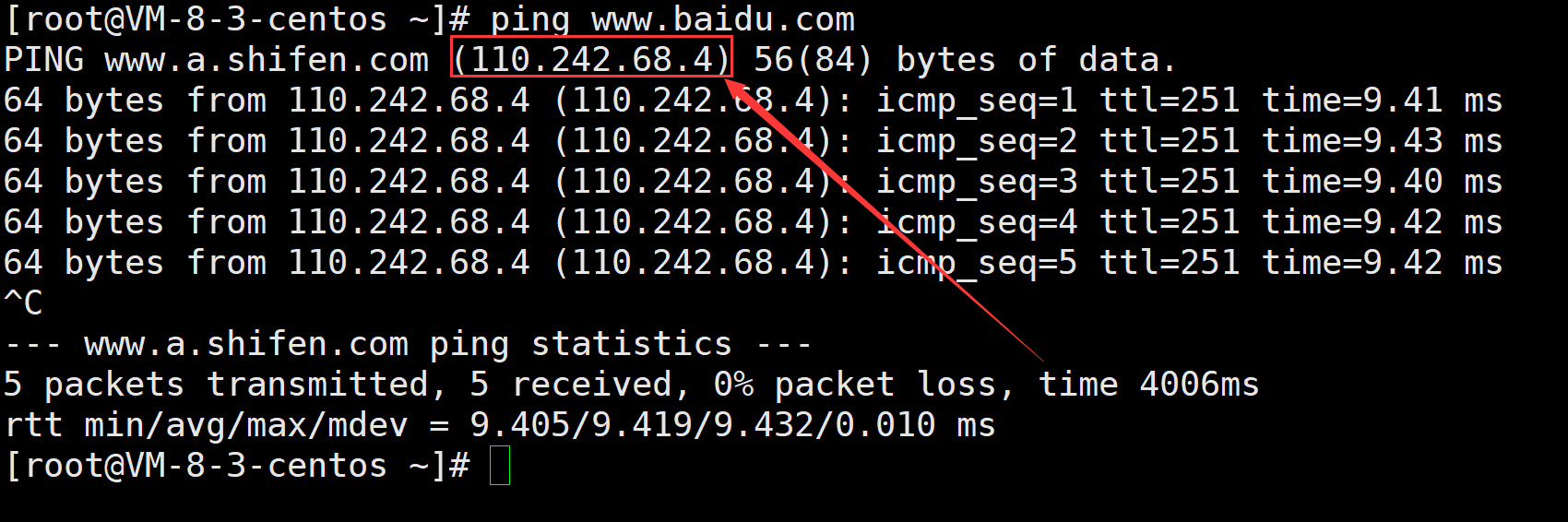
ping过之后我们会得到一个ip地址 这个实际上就是百度服务器的ip 如果我们在网页上直接输入这个ip也能够访问百度的网站
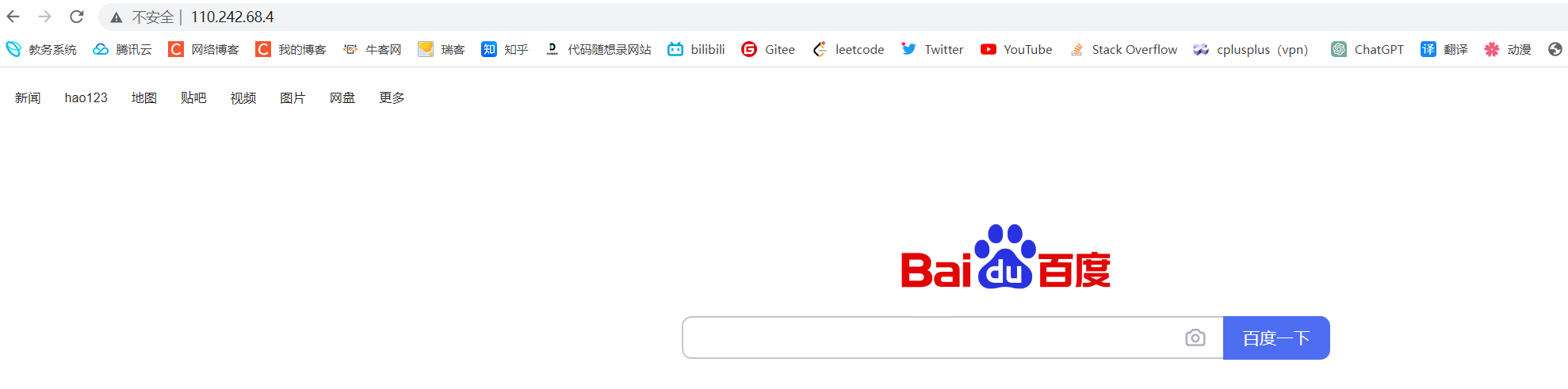
四、服务器端口号
80表示的是服务器端口号 HTTP协议和套接字编程一样都是位于应用层的 在进行套接字编程时我们需要给服务器绑定对应的IP和端口 而这里的应用层协议也同样需要有明确的端口号
常见协议对应的端口号:
| 协议名称 | 对应端口号 |
|---|---|
| HTTP | 80 |
| HTTPS | 443 |
| SSH | 22 |
当我们使用某种协议时 该协议实际就是在为我们提供服务 现在这些常用的服务与端口号之间的对应关系都是明确的 所以我们在使用某种协议时实际是不需要指明该协议对应的端口号的 因此在URL当中服务器的端口号一般也是被省略的
五、带层次的文件路径
/dir/index.htm表示的是要访问的资源所在的路径 这个路径实际上就是我们Linux服务器的一个路径
过前面的域名和端口已经能够找到对应的服务器进程了 此时要做的就是指明该资源所在的路径
我们可以发现Windows上的路径分隔符是 这也就侧面证明了该路径是Linux操作系统上的路径
当我们发起网页请求的时候本质是是得到了一张网页信息 之后浏览器对于这些网页信息进行解释便得到了我们现在所看到的网页
以百度为例 如果我们单击f12之后找到index表 我们会发现这样子的一张html表
我们将这种资源称为网页资源 而HTTP协议之所以称为超文本传输协议正是因为它传输的资源啊可能不是文本资源
六、查询字符串
uid=1表示的是请求时提供的额外的参数 这些参数是以键值对的形式 通过&符号分隔开的
当我们在百度上搜索HTTP的时候可以在最上面的URL发现这样一段文字
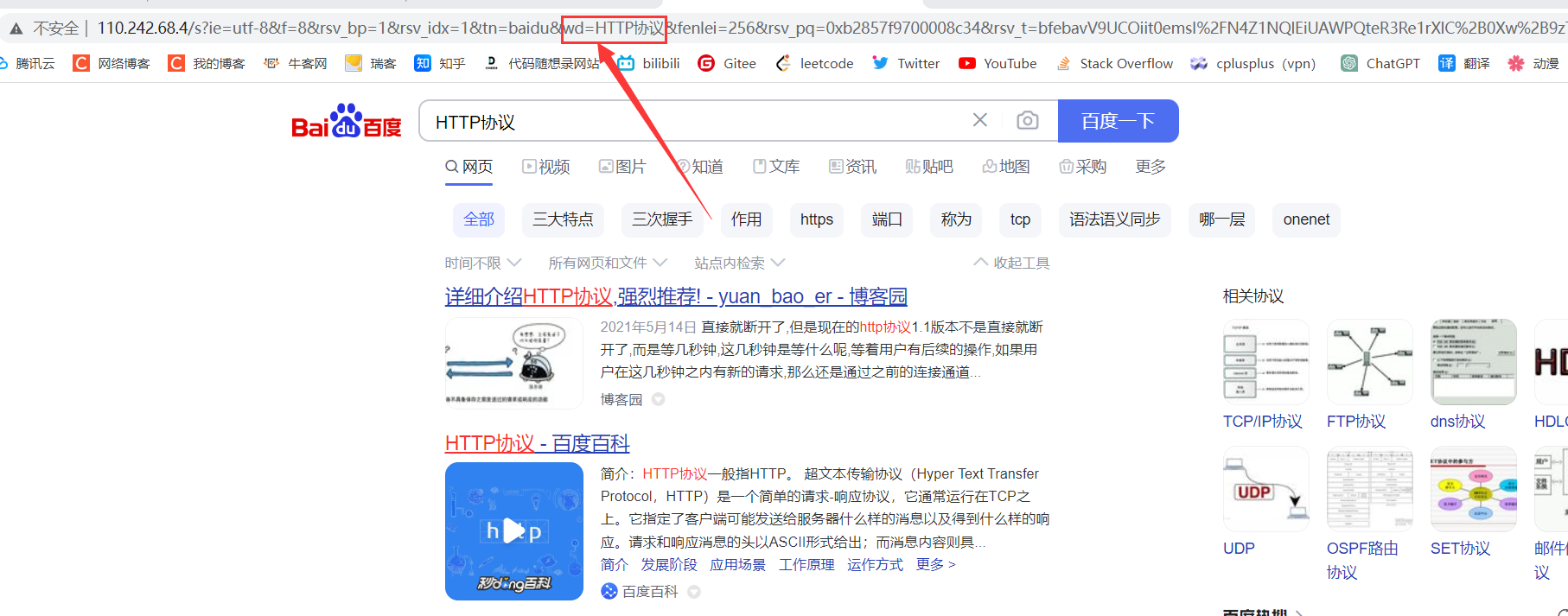
这代表着我们搜索的关键字是HTTP协议
七、片段标识符
ch1是一个片段标识符
片段标识符是指URL中的一个特殊字符“#”后面的部分 它通常用于指定文档中的某个位置
例如HTML文档中的锚点 在浏览器中 当用户点击一个链接时 浏览器会自动滚动到该链接指定的位置
片段标识符不会被发送到服务器 因此不会影响服务器的响应
urlencode和urldecode
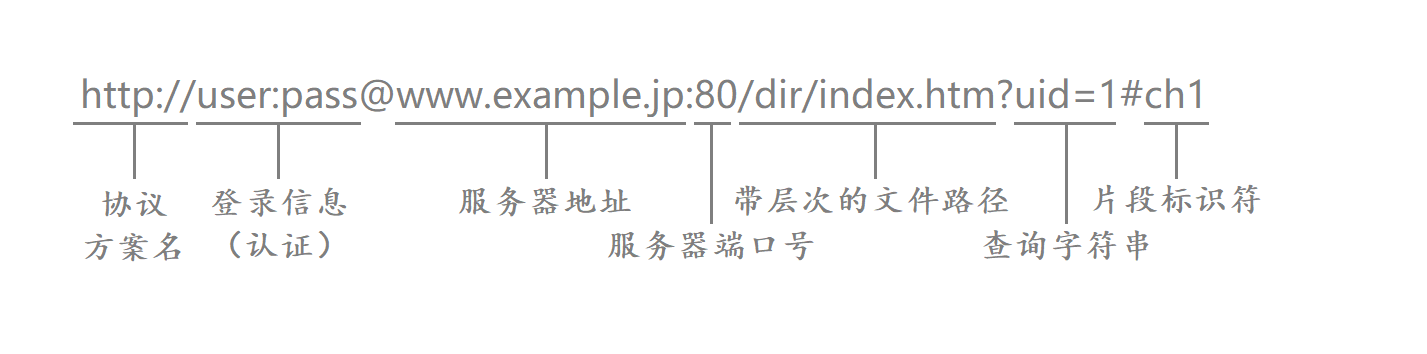
我们再次观察上面的URL
我们可以发现像是 . ? / 这些字符在外面的URL中有特殊的作用 所以说如果我们要使用这些字符的话 URL就会对这些特殊字符进行转义
其中将这些特殊字符进行转义的过程就叫做encode
将转义后的字符变为可阅读字符的过程就叫做decode
需要注意的是如果我们输入的字符中含有中文 那么中文也会被转义
HTTP协议格式
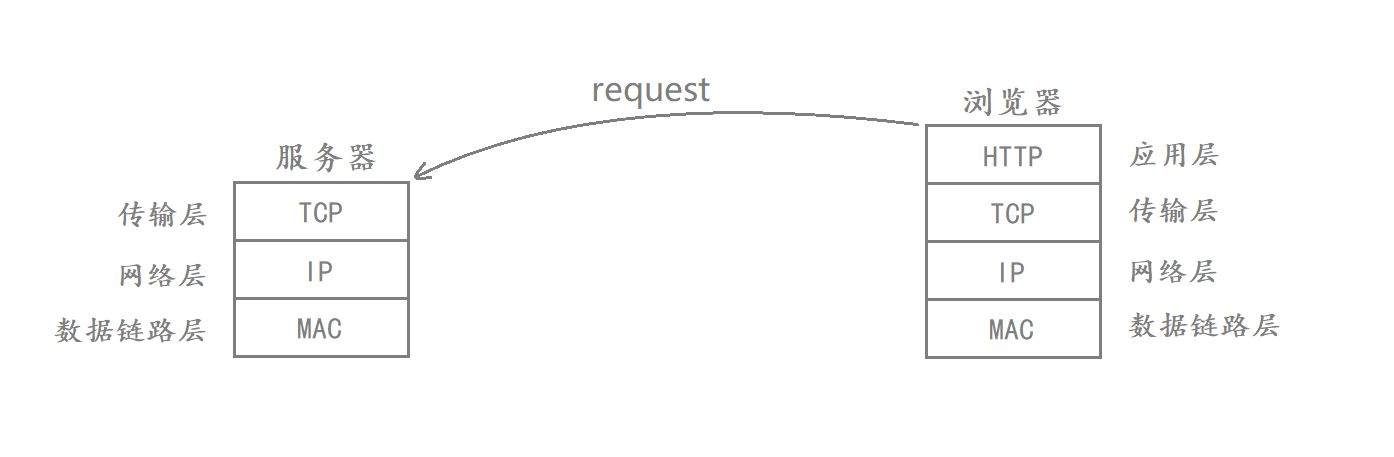
在TCP/IP四层协议中 应用层最常见的协议是HTTP/HTTPS协议
传输层最常见的协议是TCP/UDP协议
网络层最常见的协议是IP协议
数据链路层最常见的协议是MAC帧
在应用层进行通信的时候 如果不考虑下三层 那么应用层就可以认为是自己和对面的应用层直接通信的

在这四层协议当中 下三层负责的是通信细节 而应用层则负责的是如何使用传输的内容
而这其中最常见的协议是HTTP协议
HTTP服务是基于请求和相应的服务 作为客户端会向服务端发送一个request 客户端接受并分析这个request之后 得出你想要获得什么资源 然后客户端会构建出一个response 完成一次HTTP服务
这种基于request & response的工作方式我们交称为cs格式 其中c是client s是sever
由于HTTP是基于请求和响应的应用层访问 所以说我们必须要了解HTTP的请求和响应格式
HTTP请求协议格式
HTTP的请求协议格式如下:

HTTP协议由以下四部分组成:

我们可以看到HTTP请求由四部分组成
- 请求行:[请求方法]+[url]+[http版本]
- 请求报头:请求的属性 这些属性都是以key: value的形式按行陈列的
- 空行:遇到空行表示请求报头结束
- 请求正文:请求正文允许为空字符串 如果请求正文存在 则在请求报头中会有一个Content-Length属性来标识请求正文的长度
其中前面三部分是由HTTP协议自带的 而请求正文则是用户的相关信息和数据 如果说用户没有信息要上传给服务器 此时正文则为空
如何将HTTP请求的报头与有效载荷进行分离?
首先我们要明白哪里是报头哪里是有效载荷
请求报头:请求行+请求报头
有效载荷:请求正文
细心的同学就可以发现了 事实上报头和有效载荷之间隔着一个空行
如果我们将整个http协议想象成一个线性的结构 每一行都是使用
来进行分隔的 那么如果我们连续读取到两个
的话就说明报头读取完毕了开始读取有效载荷
获取浏览器的HTTP请求
在网络协议栈中 应用层的下一层叫做传输层 而HTTP协议底层通常使用的传输层协议是TCP协议
因此我们可以用套接字编写一个TCP服务器 然后启动浏览器访问我们的这个服务器
由于我们的服务器是直接用TCP套接字读取浏览器发来的HTTP请求 此时在服务端没有应用层对这个HTTP请求进行过任何解析
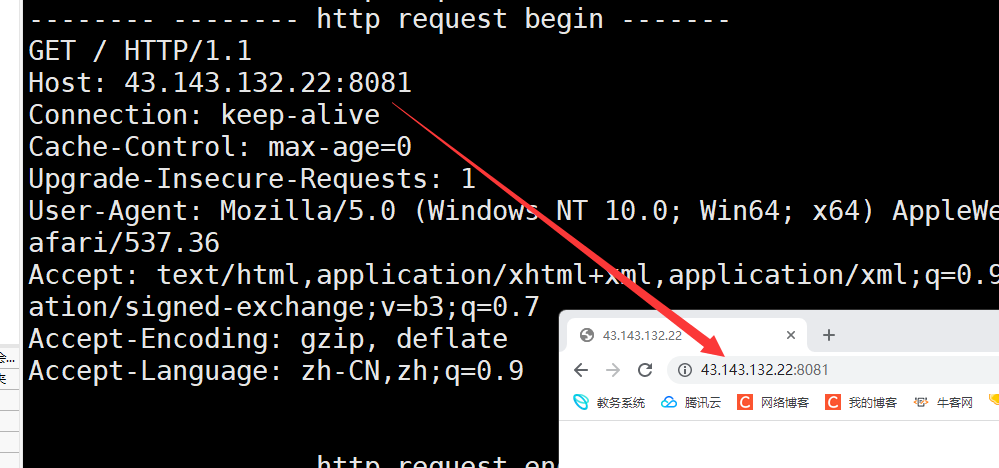
因此我们可以直接将浏览器发来的HTTP请求进行打印输出 此时就能看到HTTP请求的基本构成
下面我们要写一个简单的TCP服务器 它的作用就是使用TCP套接字来接受浏览器发送过来的数据
代码表示如下
int main()
{
int listen_sock = socket(AF_INET , SOCK_STREAM , 0);
if (listen_sock < 0)
{
cerr << "socket error" << endl;
exit(1);
}
struct sockaddr_in local;
memset(&local , '�' , sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(8081);
local.sin_addr.s_addr = htonl(INADDR_ANY);
if (bind(listen_sock , (struct sockaddr*)&local , sizeof(local)) < 0 )
{
cerr << "bind error" << endl;
exit(2);
}
if (listen(listen_sock , 5) < 0)
{
cerr << "listen error" << endl;
exit(3);
}
struct sockaddr_in peer;
memset(&peer , '�' , sizeof(peer));
socklen_t len;
for(;;)
{
int sock = accept(listen_sock , (struct sockaddr*)&peer , &len);
if (sock < 0)
{
cerr << "accept error" << endl;
continue;
}
if (fork() == 0)
{
// father
close(listen_sock);
if (fork() > 0)
{
// father
exit(0);
}
// child
char buff[1024];
recv(sock , buff , sizeof(buff) , 0);
cout << "-------- -------- http request begin -------" << endl;
cout << buff << endl;
cout << "-------- -------- http request end -------" << endl;
close(sock);
exit(0);
}
close(sock);
waitpid(-1 , nullptr , 0);
}
return 0;
}
运行服务器之后我们就可以 使用浏览器访问了
说明下:
- 浏览器向我们的服务器发起HTTP请求 因为我们的服务器没有对进行响应 此时浏览器就会认为服务器没有收到 然后再不断发起新的HTTP请求 因此虽然我们只用浏览器访问了一次 但会受到多次HTTP请求
- 由于浏览器默认使用的就是HTTP协议 所以我们输入URL的时候不用制定协议
- url当中的
/不能称之为我们云服务器上根目录 这个/表示的是web根目录 这个web根目录可以是你的机器上的任何一个目录 这个是可以自己指定的 不一定就是Linux的根目录
web根目录
如果说我们请求资源的时候不带上具体的资源 比如说我们前面的这种格式
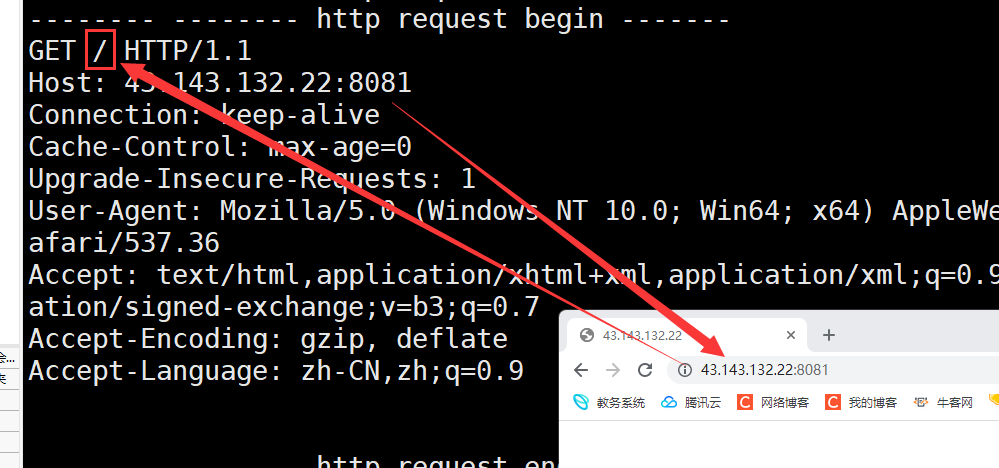
此时浏览器并不会请求此服务器中根目录下所有的信息 而是会返回一个网站的首页 网站首页的格式一般是index.html 和index.htm
一般来说所有的网站都要有一个默认的首页
我们再次回看服务器发送给我们的请求格式
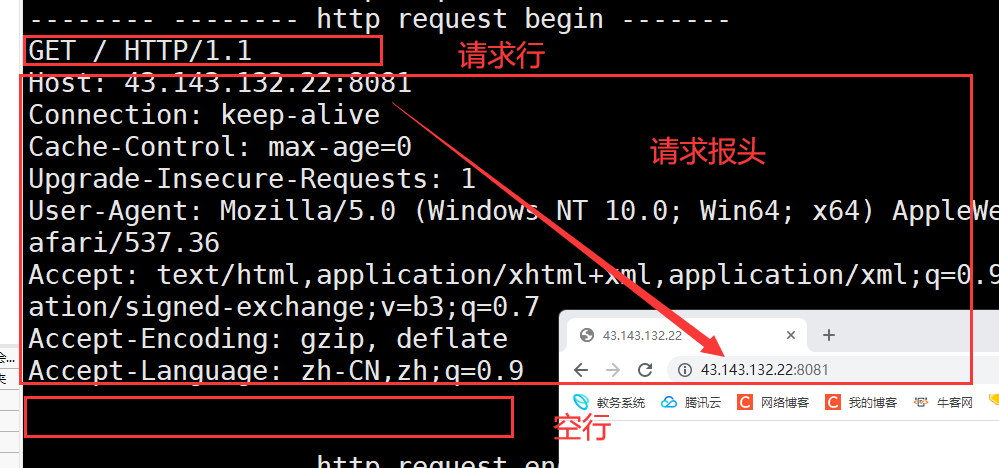
我们可以发现确实符合上面的格式
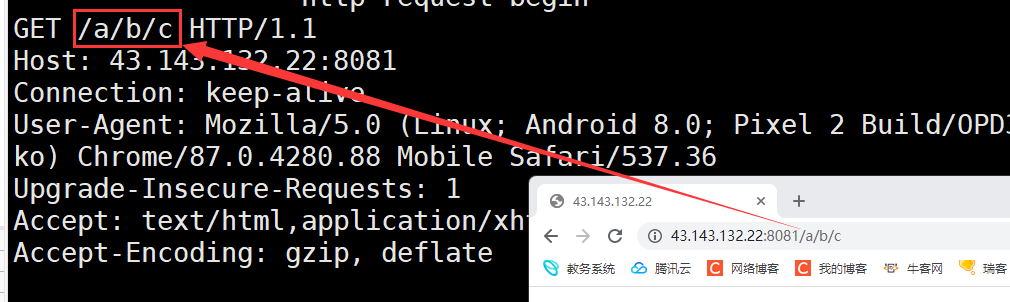
此外我们请求行中的url一般是不带域名和端口号的 因为在请求报头中的Host字段会指明 请求行中的url一般会指明你要访问服务器上哪一路径的资源
如果浏览器在访问我们的服务器时指明要访问的资源路径 那么此时浏览器发起的HTTP请求当中的url也会跟着变成该路径
HTTP响应格式
HTTP响应协议格式如下:

HTTP响应由以下四部分组成:
- 状态行:[http版本]+[状态码]+[状态码描述]
- 响应报头:响应的属性 这些属性都是以key: value的形式按行陈列的
- 空行:遇到空行表示响应报头结束
- 响应正文:响应正文允许为空字符串 如果响应正文存在 则响应报头中会有一个Content-Length属性来标识响应正文的长度 比如服务器返回了一个html页面 那么这个html页面的内容就是在响应正文当中的
如何将HTTP响应的报头与有效载荷进行分离?
对于HTTP响应来讲 这里的状态行和响应报头就是HTTP的报头信息 而这里的响应正文实际就是HTTP的有效载荷
而报头信息和响应正文之间我们使用换行符来进行分隔
当客户端收到一个HTTP响应后 就可以按行进行读取 如果读取到空行则说明报头已经读取完毕
构建HTTP响应给浏览器
服务器读取到客户端发来的HTTP请求后 需要对这个HTTP请求进行各种数据分析 然后构建成对应的HTTP响应发回给客户端
而我们的服务器连接到客户端后 实际就只读取了客户端发来的HTTP请求就将连接断开了
接下来我们可以主动构建一个统一的HTTP响应给服务器
string http_response = "http/1.0 200 OK
";
http_response += "Content-type : text/plain
";
http_response += "
";
http_response += "HELLO HTTP";
send(sock , http_response.c_str() , http_response.size() , 0);
响应的代码格式如上 如果此时网页端访问我们的服务器 我们的服务器就能得到这个http的响应
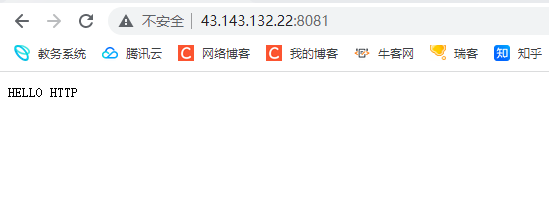
上面的格式就是我们HTTP响应的格式 至于里面的关键字是什么意思 我们后面再详细讲解
HTTP为什么要交互版本?
HTTP请求当中的请求行和HTTP响应当中的状态行 当中都包含了http的版本信息
HTTP请求是由客户端发的 因此HTTP请求当中表明的是客户端的http版本
而HTTP响应是由服务器发的 因此HTTP响应当中表明的是服务器的http版本
客户端和服务器双方在进行通信时会交互双方http版本 主要还是为了兼容性的问题 因为服务器和客户端使用的可能是不同的http版本 为了让不同版本的客户端都能享受到对应的服务 此时就要求通信双方需要进行版本协商
客户端在发起HTTP请求时告诉服务器自己所使用的http版本 此时服务器就可以根据客户端使用的http版本 为客户端提供对应的服务 而不至于因为双方使用的http版本不同而导致无法正常通信 因此为了保证良好的兼容性 通信双方需要交互一下各自的版本信息
HTTP的方法
在HTTP中常见的方法如下
| 方法 | 说明 | 支持的HTTP协议版本 |
|---|---|---|
| GET | 获取资源 | 1.0、1.1 |
| POST | 传输实体主体 | 1.0、1.1 |
| PUT | 传输文件 | 1.0、1.1 |
| HEAD | 获得报文首部 | 1.0、1.1 |
| DELETE | 删除文件 | 1.0、1.1 |
| OPTIONS | 询问支持的方法 | 1.1 |
| TRACE | 追踪路径 | 1.1 |
| CONNECT | 要求用隧道协议连接代理 | 1.1 |
| LINK | 建立和资源之间的联系 | 1.0 |
| UNLINK | 断开连接关系 | 1.0 |
在上面所有的方法中 我们最常用的就是GET和POST方法
GET方法和POST方法
GET和POST方法是HTTP协议中用于向服务器发送请求的两种方式
一般来说GET方法用于获取资源 而POST方法用于上传资源 但是事实上GET方法也可以用来上传数据 POST方法也可以用来请求数据 比如说我们使用百度提交数据的时候我们使用的就是GET方法
GET方法和POST方法都可以带参 但是它们的传参方式有所不同
- GET方法是通过url传参的
- POST方法是通过正文传参的
从它们的传参方式我们就可以看出 GET方法传递的参数是有限的 因为url的长度是有限的
而POST方法能够传递更多的参数 因为正文的限制长度比url的限制长度多得多
此外我们使用POST传参更加私密一点
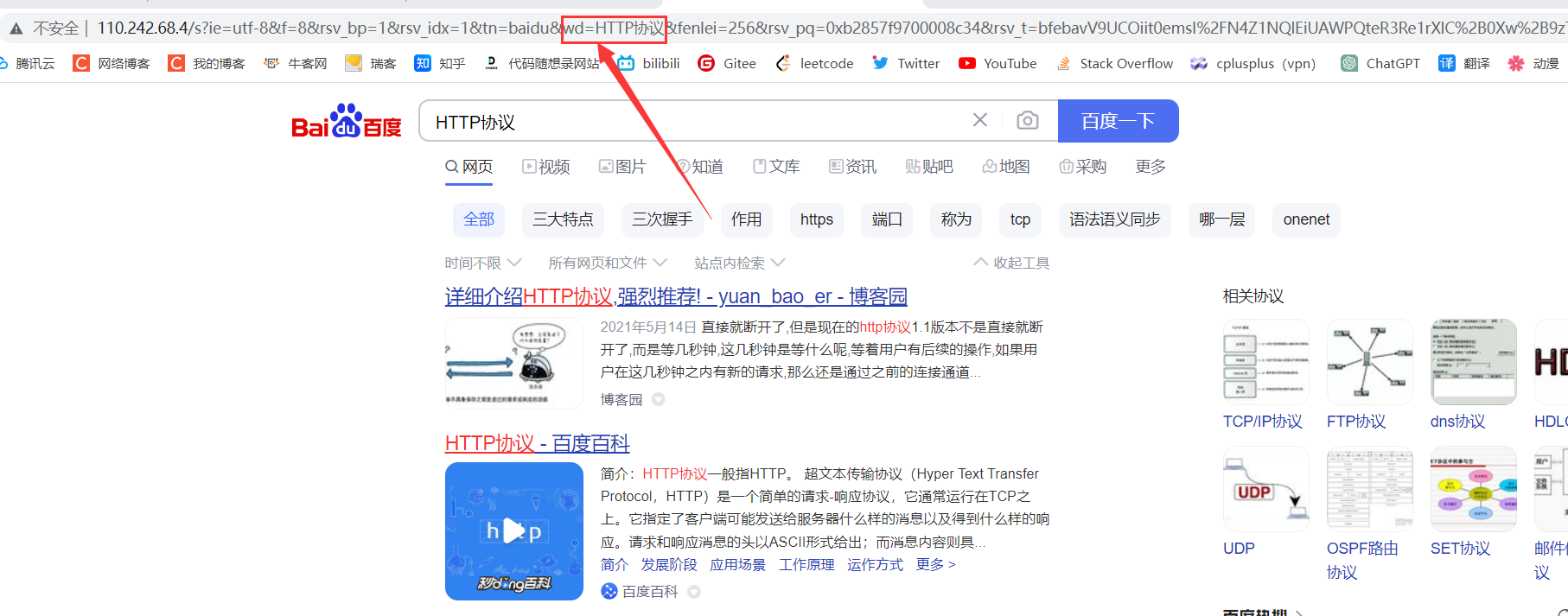
当我们使用GET方法传参的时候参数会暴露在url中 而POST方法则不会
所以我们可以说POST方法比GET方法安全一点
但是实际上这两种方法都是不安全的 它们都能够被抓包工具抓包从而导致信息泄漏 想要数据安全我们只能对于这些信息进行加密
TCP套接字演示GET和POST的区别
为了演示GET和POST传参的区别 就需要让浏览器提交参数
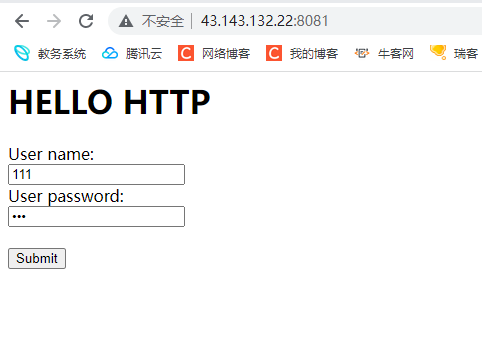
此时我们就可以在网页中增加两个表单 当作是用户的用户名和密码
再增加一个提交按钮 此时用户就能够向我们的服务器提交数据了
<html>
<head></head>
<body>
<h1>HELLO HTTP</h1>
<form method="GET" action="/">
User name:<br>
<input type="text" name="username">
<br>
User password:<br>
<input type="password" name="passwd">
<br><br>
<input type="submit" value="Submit">
</form>
</body>
</html>
此时我们便可以在网页中提交数据
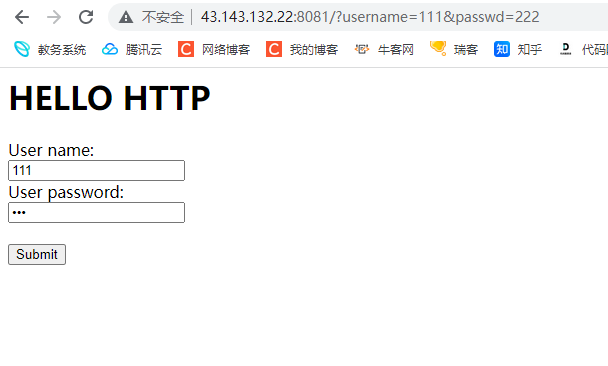
因为此时我们是用GET方式传递的参数 所以说参数会明文显示到url中
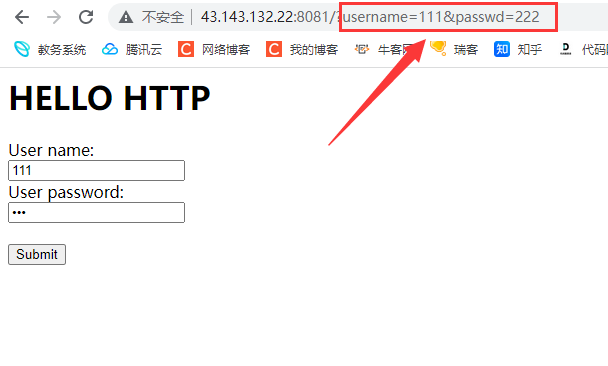
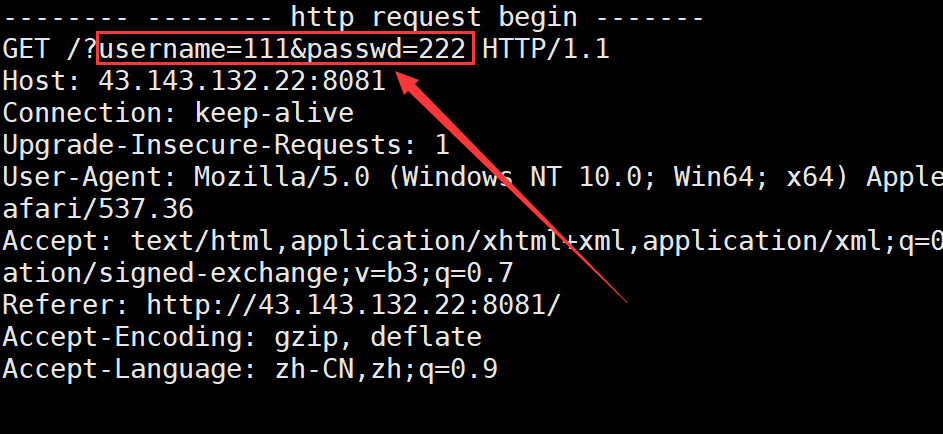
同样的 服务器这边也得到了我们在浏览器提交的参数
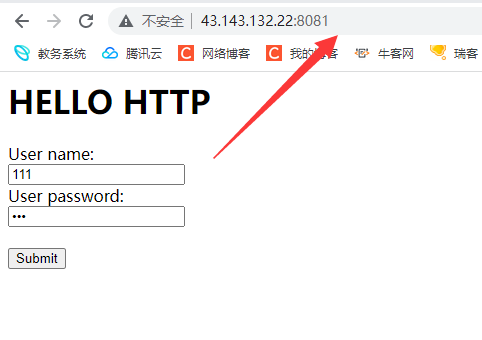
但是如果我们使用POST方法提交参数的时候 此时网页会将参数信息在正文中提交给服务器
此时我们就会发现url中没有参数了
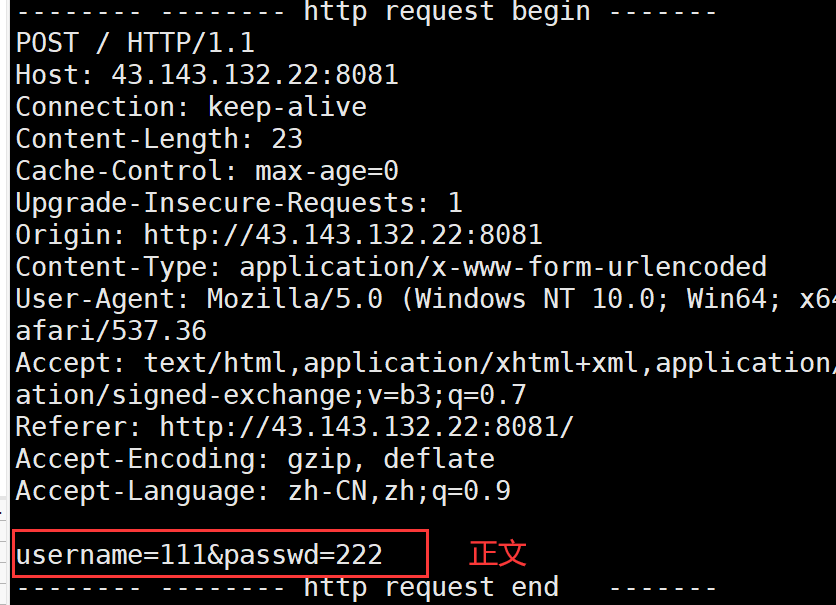
而我们会在服务器中的正文部分收到网页端传递的参数
HTTP状态码
HTTP的状态码如下:
| 编号 | 类别 | 意义 |
|---|---|---|
| 1XX | Informational(信息性状态码) | 接收的请求正在处理 |
| 2XX | Success(成功状态码) | 请求正常处理完毕 |
| 3XX | Redirection(重定向状态码) | 需要进行附加操作以完成请求 |
| 4XX | Client Error(客户端错误状态码) | 服务器无法处理请求 |
| 5XX | Server Error(服务器错误状态码) | 服务器处理请求出错 |
其中我们要记住的有下面这几个
101 信息请求中
101表示客户端发送的请求正在处理中 但是因为网速变快 这种状态已经不怎么常见了
200 OK
这是最常见的一个状态码 也就是我们访问网页成功的时候网页返回的响应行
301 永久重定向
比如果一个老的网站废弃不用了使用一个新的网站 那么此时这个网站就可以使用永久重定向 如果有人还在访问这个网站就会跳转到新网站上
此外如果收藏夹中收藏了老的网站 新的网站会覆盖收藏夹中老的网站
302 307 临时重定向
从名字看就更好理解了 和301永久重定向相比一个是永久的一个是临时的 它并不会覆盖掉收藏夹中的老网站
403 权限不足
这个常见于我们去实习的时候 自己的权限特别低 如果leader丢给你一个文档而你没有观看的权限就会出现这个状态码
404 NOT FOUND
常见于资源消失不见(被删除或过期) 又或者说资源根本不存在
比如说你访问一个网站的时候带上一个不存在的资源路径你就会看到这个状态码
504 Bad Gateway
常见于服务器出现问题 和客户端无关
Redirection(重定向状态码)
除了上面那些要记住的状态码之外 我们还需要更深入的理解重定向状态码
重定向又分为永久重定向和临时重定向 其中301表示永久重定向 302 307表示临时重定向
临时重定向和永久重定向本质是影响客户端的标签 决定客户端是否需要更新目标地址
如果某个网站是永久重定向 那么第一次访问该网站时由浏览器帮你进行重定向 但后续再访问该网站时就不需要浏览器再进行重定向了 此时你访问的直接就是重定向后的网站
而如果某个网站是临时重定向 那么每次访问该网站时如果需要进行重定向 都需要浏览器来帮我们完成重定向跳转到目标网站
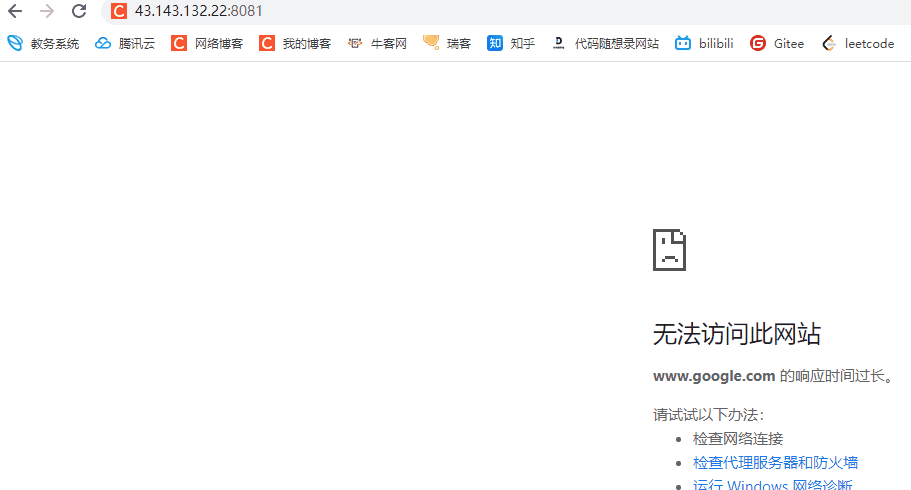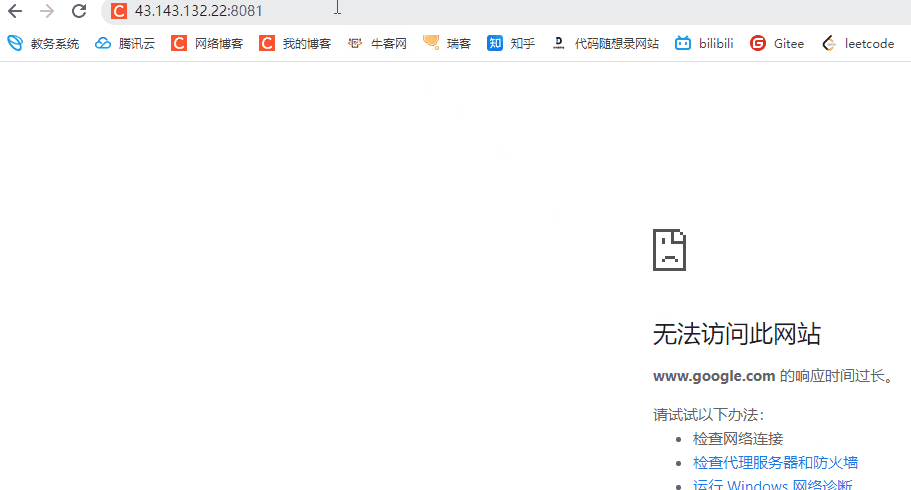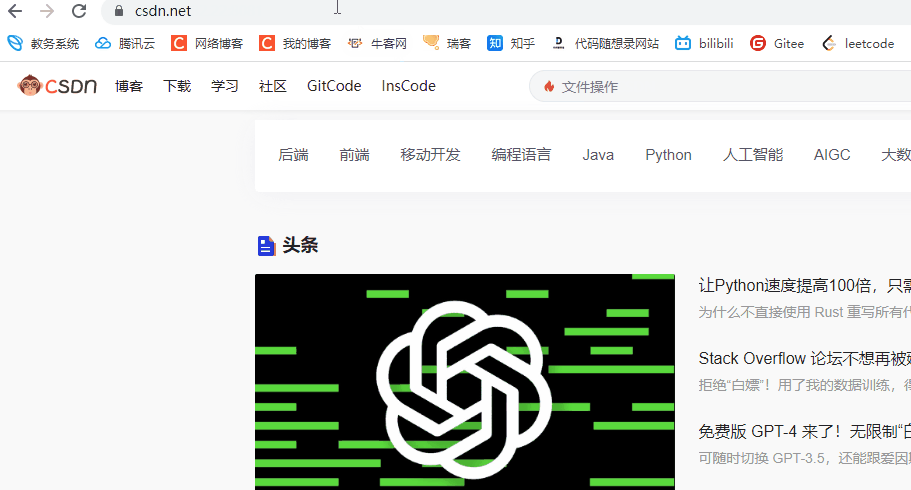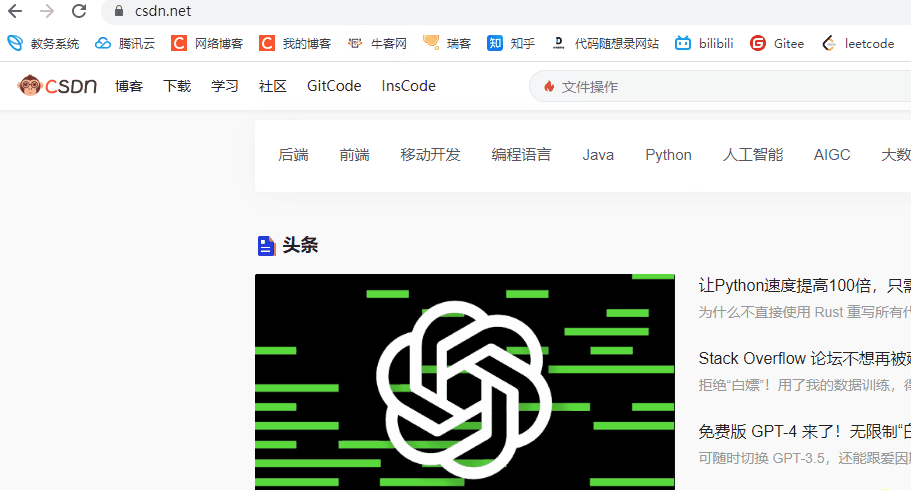
临时重定向演示
string status_line = "http/1.1 307 Temporary Redirect
";
string response_header = "Location: https://www.csdn.net/
";
我们只需要在HTTP的响应行和响应报头加上这两行代码
此时如果我们访问这个我们的域名就会自动访问csdn的官网
HTTP中常见Header
HTTP常见的Header如下:
- Content-Type:数据类型(text/html等)
- Content-Length:正文的长度
- Host:客户端告知服务器 所请求的资源是在哪个主机的哪个端口上
- User-Agent:声明用户的操作系统和浏览器的版本信息
- Referer:当前页面是哪个页面跳转过来的
- Location:搭配3XX状态码使用 告诉客户端接下来要去哪里访问
- Cookie:用于在客户端存储少量信息 通常用于实现会话(session)的功能
Host
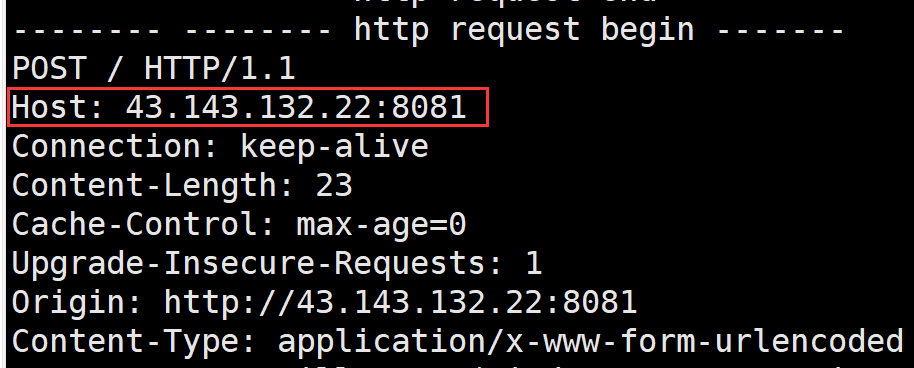
Host字段表明了客户端要访问的服务的IP和端口
比如当浏览器访问我们的服务器时 浏览器发来的HTTP请求当中的Host字段填的就是我们的IP和端口
但客户端不就是要访问服务器吗? 为什么客户端还要告诉服务器它要访问的服务对应的IP和端口
因为有些服务器实际提供的是一种代理服务 也就是代替客户端向其他服务器发起请求 然后将请求得到的结果再返回给客户端 在这种情况下客户端就必须告诉代理服务器它要访问的服务对应的IP和端口 此时Host提供的信息就有效了
User-Agent
User-Agent字段代表着客户端对应的操作系统和浏览器版本信息

这个字段是十分有用的 比如说我们我们在百度搜索中搜索QQ下载这四个字符 它会优先给我们判断QQWINDOWS端的下载连接 这是因为我们使用的就是WINDOWS操作系统
Referer
Referer代表的是你当前是从哪一个页面跳转过来的
Referer记录上一个页面的好处一方面是方便回退 另一方面可以知道我们当前页面与上一个页面之间的相关性
比如说我们别人使用307状态码跳转到我们主页的时候 我们就可以通过Referer字段来找到是从哪个网站跳转过来的
Keep-Alive(长连接)
HTTP/1.0是通过request&response的方式来进行请求和响应的 HTTP/1.0常见的工作方式就是客户端和服务器先建立链接 然后客户端发起请求给服务器 服务器再对该请求进行响应 然后立马端口连接
但如果一个连接建立后客户端和服务器只进行一次交互 就将连接关闭 就太浪费资源了
因此现在主流的HTTP/1.1是支持长连接的 所谓的长连接就是建立连接后 客户端可以不断的向服务器一次写入多个HTTP请求 而服务器在上层依次读取这些请求就行了 此时一条连接就可以传送大量的请求和响应 这就是长连接
如果HTTP请求或响应报头当中的Connect字段对应的值是Keep-Alive 就代表支持长连接
Cookie和Session
HTTP实际上是一种无状态协议 HTTP的每次请求/响应之间是没有任何关系的 但你在使用浏览器的时候发现并不是这样的
我们只要第一次登录了B站以后 下次再点击这个网站的时候我们就不用自己主动登录了
这是因为COOKIE的存在
我们可以点击url前面的锁 来查看COOKIE信息
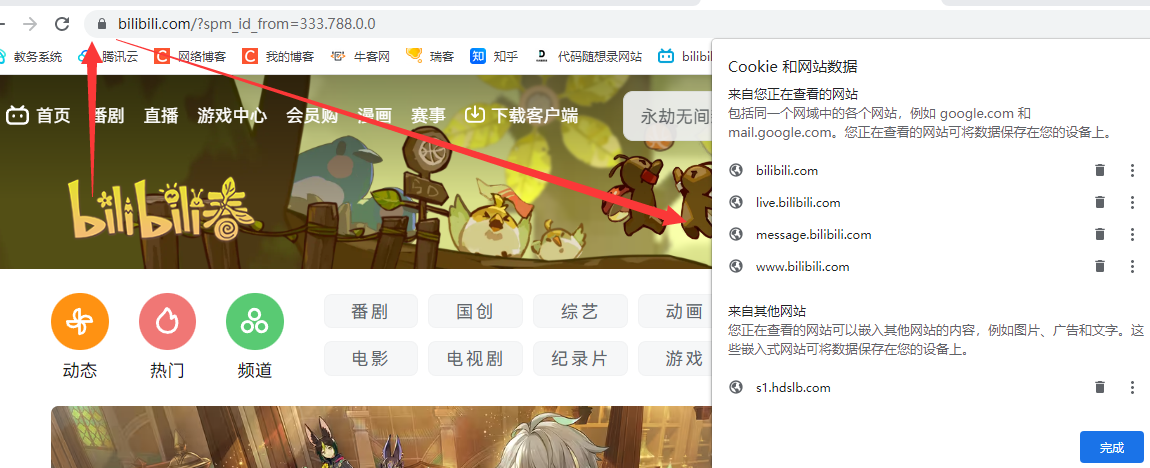
这些cookie数据实际都是对应的服务器方写的 如果我们将这些信息全部删除的话 那么下次我们访问这个网站的时候就需要再次登录了
cookie是什么呢?
Cookie是一种能够让网站服务器把少量数据储存到客户端的硬盘或内存 或是从客户端的硬盘读取数据的一种技术 它的目的是给用户更好的体验
比如你是某个视频网站的VIP 这个网站里面的VIP视频有成百上千个 你每次点击一个视频都要重新进行VIP身份认证 而HTTP不支持记录用户状态 那么我们就需要有一种独立技术来帮我们支持 这种技术目前现在已经内置到HTTP协议当中了 叫做cookie
当我们第一次登录某个网站时 需要输入我们的账号和密码进行身份认证 此时如果服务器经过数据比对后判定你是一个合法的用户 那么为了让你后续在进行某些网页请求时不用重新输入账号和密码 此时服务器就会进行Set-Cookie的设置
当认证通过并在服务端进行Set-Cookie设置后 服务器在对浏览器进行HTTP响应时就会将这个Set-Cookie响应给浏览器 而浏览器收到响应后会自动提取出Set-Cookie的值 将其保存在浏览器的cookie文件当中 此时就相当于我的账号和密码信息保存在本地浏览器的cookie文件当中
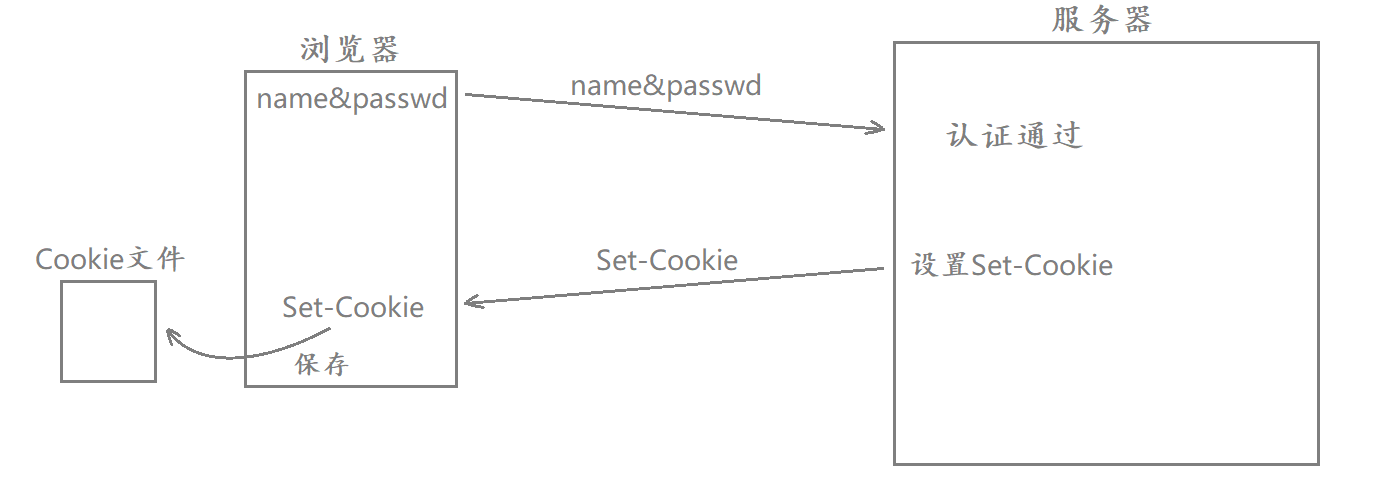
从第一次登录认证之后 浏览器再向该网站发起的HTTP请求当中就会自动包含一个cookie字段 其中携带的就是我第一次的认证信息 此后对端服务器需要对你进行认证时就会直接提取出HTTP请求当中的cookie字段 而不会重新让你输入账号和密码了
也就是在第一次认证登录后 后续所有的认证都变成了自动认证 这就叫做cookie技术
内存级别&文件级别
cookie就是在浏览器当中的一个小文件 文件里记录的就是用户的私有信息
cookie文件可以分为两种 一种是内存级别的cookie文件 另一种是文件级别的cookie文件
- 将浏览器关掉后再打开 访问之前登录过的网站 如果需要你重新输入账号和密码 说明你之前登录时浏览器当中保存的cookie信息是内存级别的
- 将浏览器关掉甚至将电脑重启再打开 访问之前登录过的网站 如果不需要你重新输入账户和密码 说明你之前登录时浏览器当中保存的cookie信息是文件级别的
cookie被盗
如果你浏览器当中保存的cookie信息被非法用户盗取了 那么此时这个非法用户就可以用你的cookie信息 以你的身份去访问你曾经访问过的网站 我们将这种现象称为cookie被盗取了。
比如你不小心点了某个链接 这个链接可能就是一个下载程序 当你点击之后它就会通过某种方式把程序下载到你本地 并且自动执行该程序 该程序会扫描你的浏览器当中的cookie目录 把所有的cookie信息通过网络的方式传送给恶意方 当对方拿到你的cookie信息后就可以拷贝到它的浏览器对应的cookie目录当中 然后以你的身份访问你曾经访问过的网站
SessionID
我们单纯使用Cookie技术是十分不安全的 因为Cookie里面就是你的私密信息 一旦Cookie被盗取了你的私密信息也就被盗取了
为了防止这种现象的发生 我们发明了SessionID技术
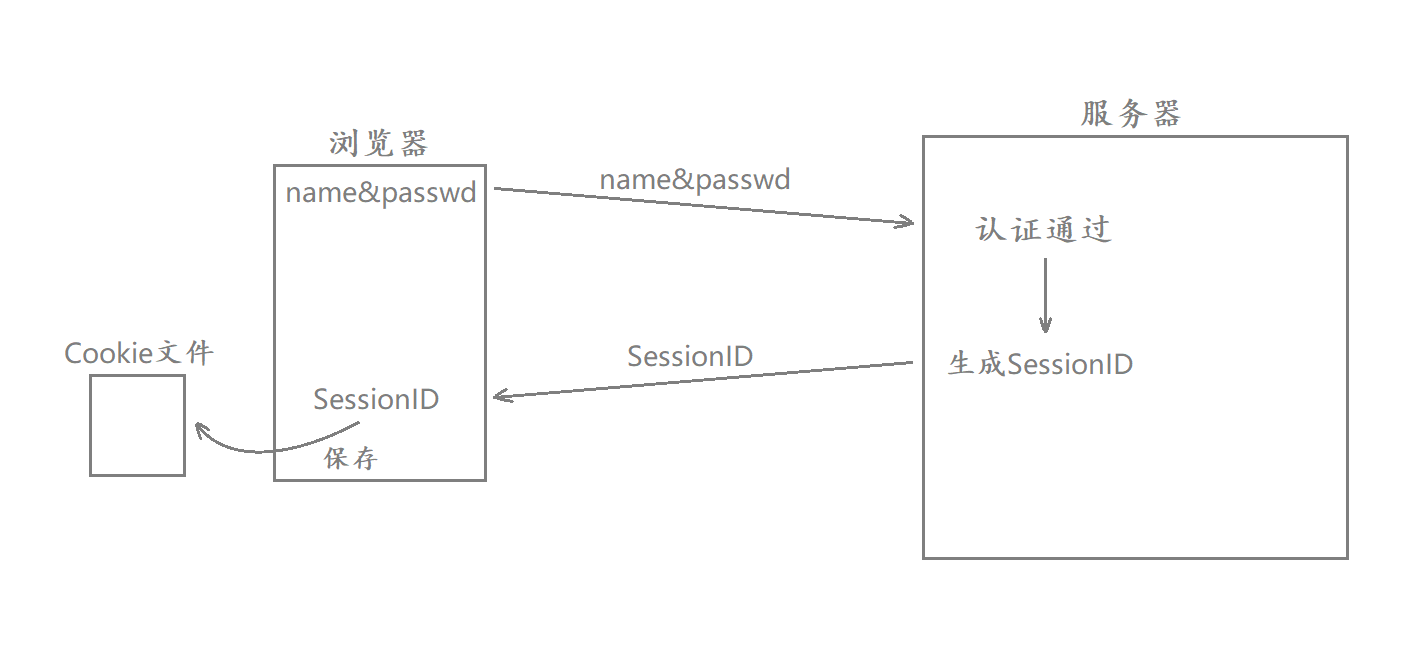
当我们首次登录某个网站的时候 该网站对应的服务器会生成一个SessionID 该ID是和用户的信息是一一对应的 生成该ID之后网站会将用户的信息保存到服务器的某个特定目录当中
这样子就算用户的SessionID被盗取了也不会影响用户隐私安全
并且当用户使用该SessionID登录网站的时候服务器也能够立刻调取对应的Cookie信息来优化用户的体验
安全是相对的
当我们引入SessionID之后我们的信息并不是就绝对安全了 事实上通过上面的恶意程序我们还是能够获取到用户浏览器上的SessionID 再通过这个SessionID来以用户的身份访问网站 而在这些网站当中用户也可能保存了自己隐私信息 所以说使用SessionID的方案并不是绝对安全的
事实上 互联网上并不存在绝对安全这一概念 我们对于安全通常是这么理解的
如果获取你隐私的收益远远小于获取你隐私的成本 那么你的隐私数据就是安全的
接下来我们再比较下之前和现在的工作方式
- 之前我们将隐私信息保存在本地的Cookie中 每次连接的时候都是在网络中明文发送自己的账号和密码
- 有了SessionID之后 我们只需要第一次登录时发送用户名和密码 之后发送SessionID即可
引入SessionID后的好处
- 在引入SessionID之前 用户登录的账号信息都是保存在浏览器内部的 此时的账号信息是由客户端去维护的
- 而引入SessionID后 用户登录的账号信息是有服务器去维护的 在浏览器内部保存的只是SessionID
此时虽然SessionID可能被非法用户盗取 但服务器也可以使用各种各样的策略来保证用户账号的安全
- 我们可以通过IP来定位每次网站的登录地点 如果说两次登录的IP相差距离太远 那么此时服务器就可以要求用户重新输入账号密码来防范SessionID被盗
- 当操作者要执行一些高权限的操作的时候 需要用户再次输入密码 但是黑客此时只知道用户的SessionID便无法进行后序操作了
- SessionID有时间限制 有可能只是一个小时有用 如果过了一个小时这个SessionID就没用了
HTTPS协议
HTTPS VS HTTP
我们前面说过 如果使用HTTP协议不管你是使用POST方法传参还是使用GET方法传参都是不安全的 都能很简单的被抓包工具抓到
为了解决这个问题 我们发明出了HTTPS协议 HTTPS实际就是在应用层和传输层协议之间加了一层加密层(SSL&TLS) 这层加密层本身也是属于应用层的 它会对用户的个人信息进行各种程度的加密
HTTPS在交付数据时先把数据交给加密层 由加密层对数据加密后再交给传输层
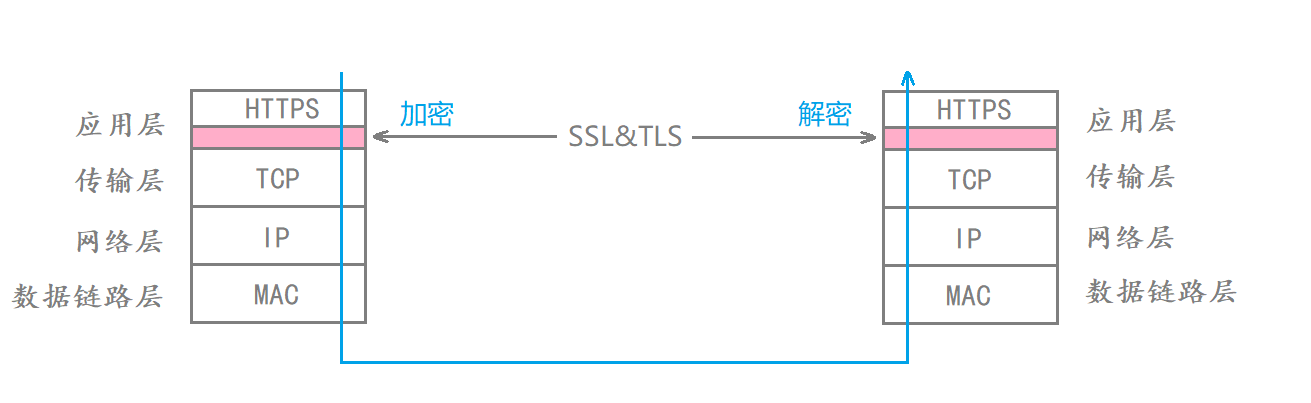
此时数据在网络中传输的时候就是经过HTTPS加密过的数据 就算中间被截获了别人也看不懂
当然 通信双方必须都要使用HTTPS协议 如果一方使用的HTTPS一方使用的是HTTP的话那么数据就无法被解密了
对称加密和非对称加密
- 对称加密 通信双方使用同一把密钥 该密钥既可以进行加密也可以进行解密
- 非对称加密 采用公钥和私钥来进行加密和解密 使用公钥加密的数据必须要使用私钥来解秘
对于非对称加密 一般来说 公钥是公开的 私钥是不公开的
对称加密的效率更高 非对称加密的效率很低 通常会以秒为单位
加密的过程
如果我们选择对称加密的话 我们一开始需要将对称加密的密钥发送给对方(我们默认对称加密的密钥是别人都不知道的 因为如果大家都知道这个加密就无意义了) 但是如果选择明文发送的话该密钥就在中间被截获 那么这样子加密就没有意义了
所以说我们一开始传输数据的时候要选择非对称加密
比如说客户端发送的数据的时候将自己的公钥发送服务端
之后服务端利用这个公钥将对称密钥进行加密之后发送给客户端
此时因为这个数据是用客户端的公钥加密的 只有客户端的私钥能解开 别人截获了之后也没有用
当客户端收到这个数据之后利用自己的私钥解开服务端发送的密钥
此时它们就能够通过密钥进行对称加密通话了
中间人攻击
上面的对称加密+非对称加密的组合方式看上去无懈可击 但是事实上并非如此
我们通过中间人攻击就能够很轻松的破解
我们可以在客户端发送数据之后截取这些数据 并且将所有的数据改掉 自己加密发送给服务器
服务器返回密钥之后使用中间人的私钥解开 获取密钥 之后再将该密钥通过客户端的公钥加密之后发送给客户端
此时中间人就能不留痕迹的获取了客户端服务端通话的密钥 从而监听双方的对话了
CA证书机构
为了防止上面情况的发生 世界上诞生了一个叫做CA证书机构的组织
CA证书组织有自己的私钥和公钥 它们的公钥是公布再网络中的
它们会给每个收到信任的网站颁发证书 该证书包括网站的域名和相关信息 + 该机构使用私钥加密的一段数据
当网站给客户端第一次发送公钥的时候会附带上该证书 此时中间人就不能够对网站发送的信息做任何的修改了
- 如果修改网站信息等 那么客户端使用CA证书机构的公钥解密之后会发现信息对不上
- 如果修改CA证书机构加密的数据同理
- 如果修改两段信息 那么用户就会发现自己请求的域名和返回的域名不一致 我们知道域名和IP是一一对应的 所以说此时用户就会产生警惕心里
那么此时的加密过程就是相对安全的了
简单理解对称加密
非对称加密算法现在用的比较多的就是基于因式分解的算法
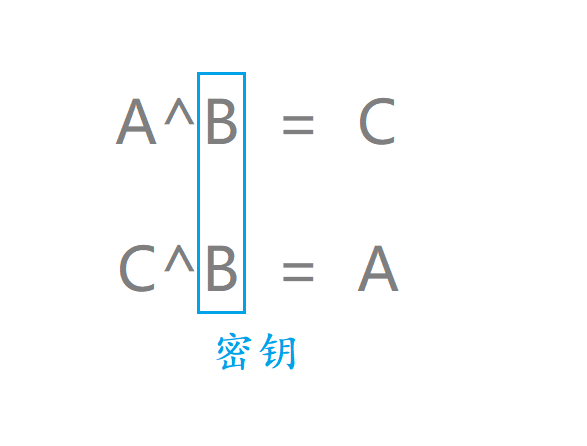
而对称加密算法可以使用异或法理解一下
我们可以规定任何一个数字为我们的密钥
之后让我们想要发送的数据与该密钥进行异或 该过程我们就叫做加密
之后将加密过的数据再次与该密钥进行异或 该过程我们就叫做解密





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结