您现在的位置是:首页 >学无止境 >基于闻达(wenda+chatGLM-6B),构建自己的知识库小助手网站首页学无止境
基于闻达(wenda+chatGLM-6B),构建自己的知识库小助手
目录
ChatGLM-6B是清华团队+智谱AI开发的,一个开源的、支持中英双语的对话语言模型,具有 62 亿参数。被很多人视为ChatGPT的平替。但是由于ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性。解决这一问题的方式大体上有两种:
一种是使用更大规模的模型来提升整体能力,提升其自我认知能力。开发者表示基于 1300 亿参数 GLM-130B 的 ChatGLM 已经在内测开发中。
另一种便是使用插件或者外挂的方式,提升模型在某一个领域的能力。
wenda就属于后者,wenda是一个大规模语言模型调用平台。旨在通过使用为小模型外挂知识库查找的方式,实现近似于大模型的生成能力。
既然我们已经了解 wenda 的作用,快让我们进入正文吧!
我的文件目录结构
# 闻达路径(我的路径为nogit,以下图片中nogit路径理解为wenda即可)
/home/user/data/wenda
# miniconda路径
/home/user/data/miniconda3安装miniconda
# 进入路径
cd /home/user/data/从 https://pan.baidu.com/s/1w33G8xp66Q6kwLN6pDC_3A?pwd=dim9 提取码: dim9
下载 Miniconda3-latest-Linux-x86_64.sh,将下载好的文件放入 /home/user/data/ 路径下
# 安装miniconda
sh Miniconda3-latest-Linux-x86_64.sh安装完成后查看是否成功
cd miniconda3/bin
./conda -V显示如下表示安装成功

拉取仓库
进入 /home/user/data/ 路径下
cd /home/user/data/ # 拉取仓库
git clone https://github.com/l15y/wenda.git使用内置python
# 进入wenda目录
cd /home/user/data/wenda # 使用conda命令创建内置python环境
/home/user/data/miniconda3/bin/conda create -p ./env python=3.8安装依赖
env/bin/pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install torch torchvision torchaudio pdfminer.six -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-chatglm.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-st.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-rwkv.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-bing.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-glm6b-lora.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-gpt4free.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-fess.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-llama.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-openai.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
env/bin/pip install -r requirements-qdrant.txt -i https://pypi.tuna.tsinghua.edu.cn/simple上传模型
我使用的模型是chatGLM-6B,大家也可以使用其他的基础模型
链接:https://pan.baidu.com/s/16L7K-2pa5EfXzcUOJEBJLA?pwd=xt9l 提取码:xt9l
下载完成后上传到 /home/user/data/wenda 路径
解压文件
cd /home/user/data/wenda
7z x -y model.7z -o/home/user/data/wenda注意,解压后的文件路径是否为 /home/user/data/wenda/model/chatglm-6b,如果不是,请修改
如果没有7z命令,需要先安装7z命令,如下:
sudo apt install p7zip-full p7zip-rar克隆及下载 text2vec-large-chinese
cd /home/user/data/wenda/model
# 从huggingface官网拉取模型指针文件
git lfs install
git clone https://huggingface.co/GanymedeNil/text2vec-large-chinese
# 下载模型
wget https://huggingface.co/GanymedeNil/text2vec-large-chinese/resolve/main/pytorch_model.bin
# 覆盖text2vec-large-chinese中的 pytorch_model.bin文件
mv pytorch_model.bin text2vec-large-chinese/修改配置
将example.config文件改名为config.xml
cd /home/user/data/wenda/
mv example.config.xml config.xml修改config.xml文件
<!--模型类型修改:我用的是glm6b模型,所以此处修改为glm6b,大家看自己所用的模型是什么,修改即可-->
<property>
<name>LLM_Type</name>
<value>glm6b</value>
<description>LLM模型类型:glm6b、rwkv、llama、chatglm</description>
</property>
<!--以下为模型位置修改,我用的是glm6b模型,所以修改此处GLM6B路径,位置为model/chatglm-6b,大家根据自己用的模型类型,修改config.xml对应位置即可-->
<GLM6B>
<property>
<name>Path</name>
<value>model/chatglm-6b</value>
<description>glm模型位置</description>
</property>
<property>
<name>Strategy</name>
<value>cuda fp16</value>
<description>glm 模型参数 支持:
"cuda fp16" 所有glm模型 要直接跑在gpu上都可以使用这个参数
"cuda fp16i8" fp16原生模型 要自行量化为int8跑在gpu上可以使用这个参数
"cuda fp16i4" fp16原生模型 要自行量化为int4跑在gpu上可以使用这个参数
"cpu fp32" 所有glm模型 要直接跑在cpu上都可以使用这个参数
"cpu fp16i8" fp16原生模型 要自行量化为int8跑在cpu上可以使用这个参数
"cpu fp16i4" fp16原生模型要 自行量化为int4跑在cpu上可以使用这个参数
</description>
</property>
<property>
<name>Lora</name>
<value></value>
<description>glm-lora模型位置</description>
</property>
</GLM6B>上传知识库(txt文件)
创建txt文件夹
cd /home/user/data/wenda/
mkdir txt将自己的txt文件上传到这里
我的txt如下
中国管理案例共享中心案例库 教学案例
1
案例正文:
飞友科技人力发展何去何从
摘要:
飞友科技有限公司(以下简称“飞友科技”)创建于 2005 年,是目前国内
最大的民航数据服务提供商。
随着飞友科技 APP 下载量与 Association for Clinical
Data Management (A-CDM)系统机场覆盖率的大大提升,飞友科技目前正以高速
发展趋势拓展业务领域,基于公司发展战略的调整,人力资源部门在完善管理体
系的过程中出现了障碍:
1.合肥是相对落后的城市,人力资源部门在本地招聘困
难;2.人力资源部门人员不稳定、流动性大,无法保证高效运作进而支持其他部
门工作。
本案例通过介绍飞友科技人力资源部门发展现状,启发案例使用者运用
战略性人力资源管理等理论知识分析公司人力资源现状背后的原因,为公司人力
资源部门的发展在未来如何适应公司及外部环境提出建议。
关键词:
IT 产业,高端人才招聘,人力资源管理,团队建设
0 引言
近年来,随着交通运输业的蓬勃发展, 生活节奏越来越快,飞机成了人们出
差旅行首选的快捷出行方式,中国航空市场也快速从原来的公务出行市场转化为
个人出行市场。
但是,由于各种自然非自然原因,航班延误,飞行取消及中转停
留等,也为乘客出行造成了不便,毕竟不是所有飞机都能风雨无阻按时起飞停降。
民航业,作为服务产业,面对竞争日益激烈的市场,如何为客户提供高速便捷的
出行服务,成为他们成功的关键。
在大环境互联网+及大用户手机网民+的背景
下,“飞常准”APP 就这样应运而生了。
正是这样一款方便快捷的航空服务 APP,
在你面对查询订票的繁琐流程以及突发情况时,帮助你更合理的安排时间,顺利
起飞。处理txt数据
/home/user/data/wenda/env/bin/python3 /home/user/data/wenda/plugins/gen_data_st.py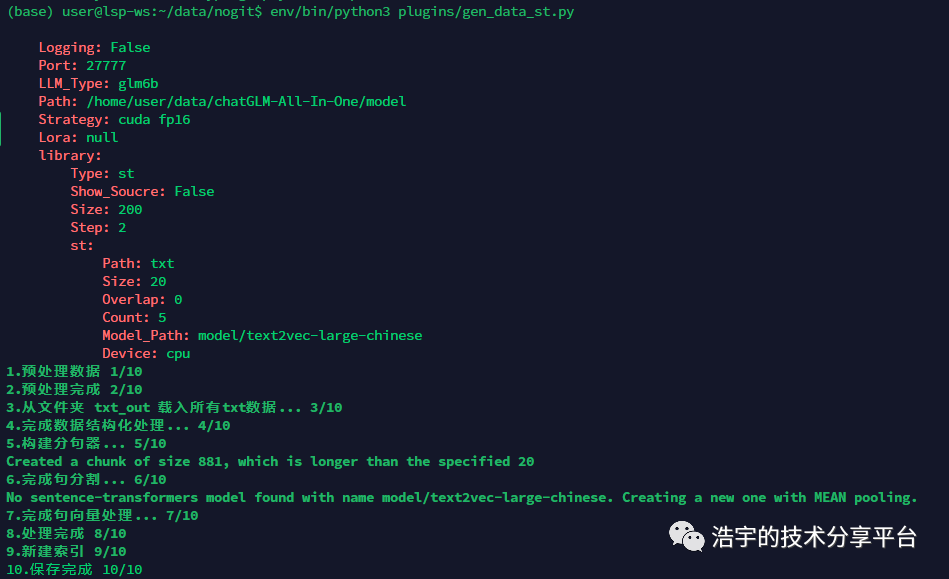
启动服务
/home/user/data/wenda/env/bin/python3 /home/user/data/wenda/wenda.py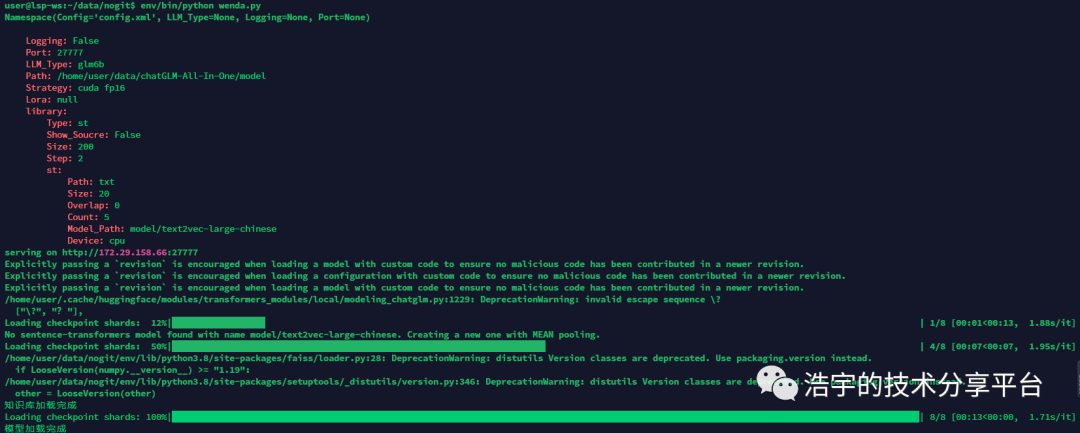
测试
未开启知识库,只使用chatglm-6b模型
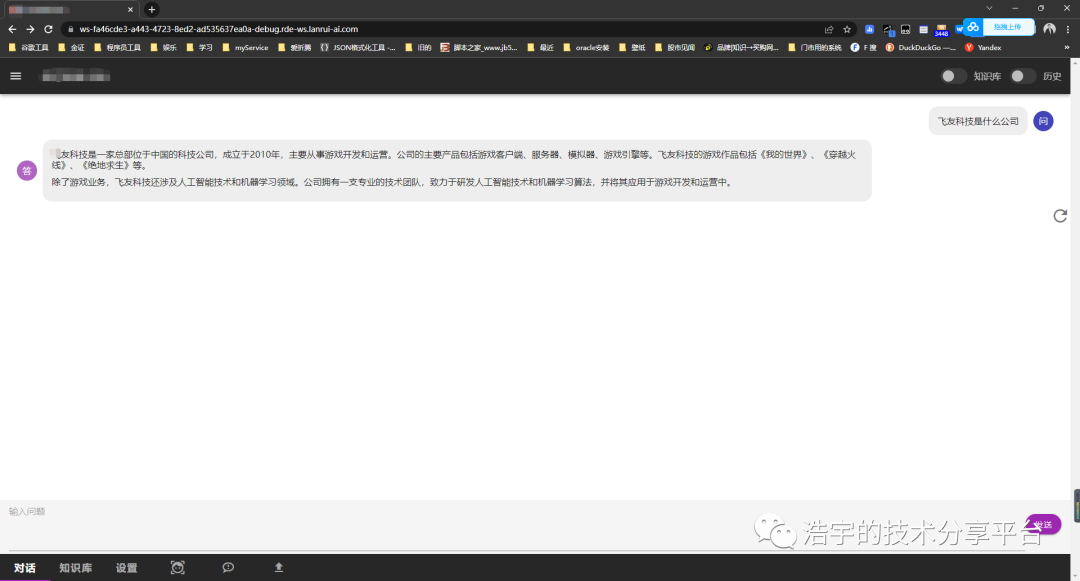
开启知识库,如下:
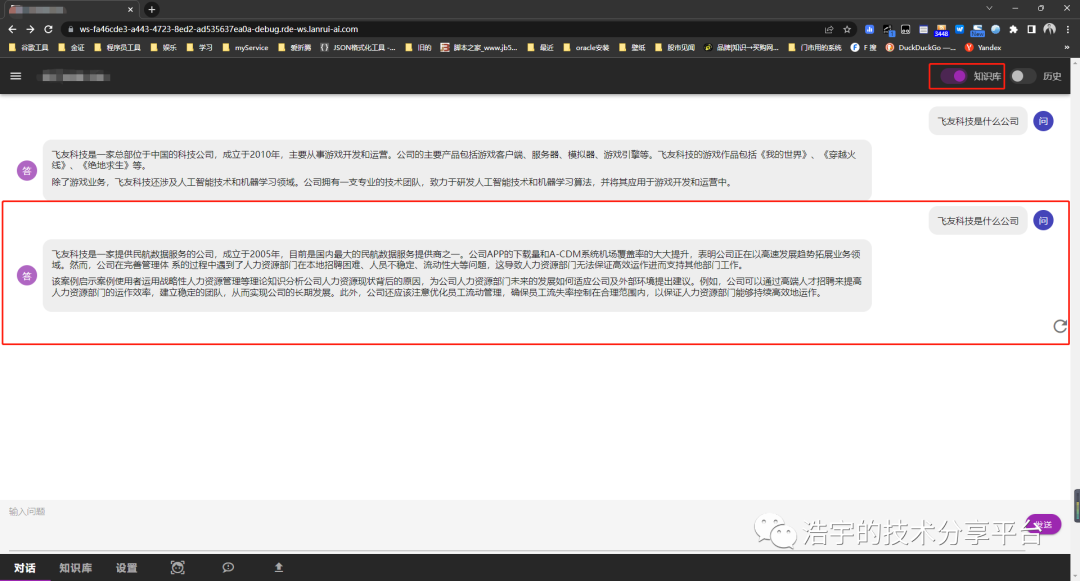
以上便是本次搭建的全部过程啦






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结