您现在的位置是:首页 >技术杂谈 >深度学习 -- Dataset与DataLoader网站首页技术杂谈
深度学习 -- Dataset与DataLoader
简介深度学习 -- Dataset与DataLoader
前言
在模型训练的步骤中,数据的部分非常重要,它的过程主要分为数据收集、数据划分、数据读取、数据预处理。
数据收集的有原始样本和标签(Img,label)
数据集的划分需要分为训练集、验证集、测试集。
训练集负责训练模型,验证集负责验证模型是否过拟合,测试集是用来测试性能的。
数据读取主要就是DataLoader的内容
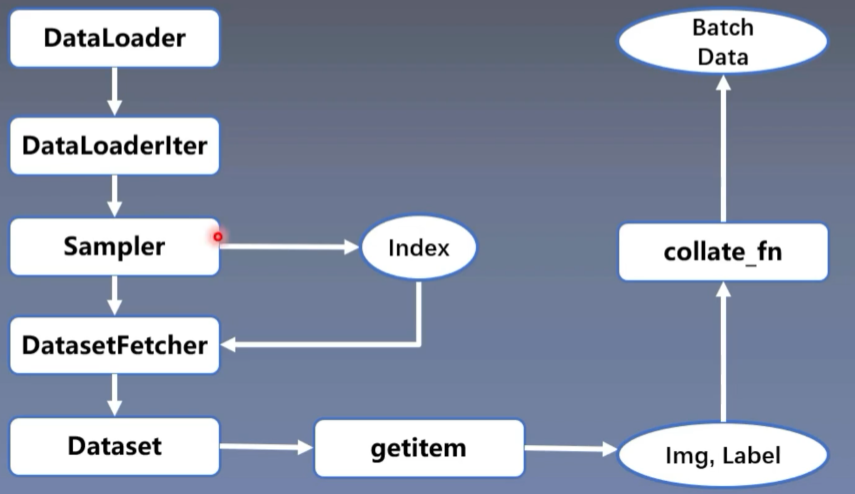
- DataLoader分为两个子模块,分别是Sampler和DataSet
Sampler的功能是生成索引(Index)
DataSet则是根据索引来读取数据
数据预处理需要用transforms来实现
DataLoader 和 Dataset
DataLoader 和 Dataset是pytorch数据读取的核心
- torch.utils.data.DataLoader
功能:构建可跌倒的数据装载器

- dataset:Dataset类,决定数据从哪读取及如何读取
- batchsize:批大小
- num_works:是否多进程读取数据
- shuffle:每个epoch是否乱序
- drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch:所有训练样本都一输入到模型中,称之为一个Epoch
Iteration:一批样本输入到模型中,称之为一个Iteration
Batchsize:批大小,决定一个Epoch有多少个Iteration
Dataset
torch.utils.data.Dataset
功能:Dataset抽象类,所有自定义的Dataset需要继承它,并且复写__ getitem __()
getitem:
接收一个索引,返回一个样本

数据读取的三个问题
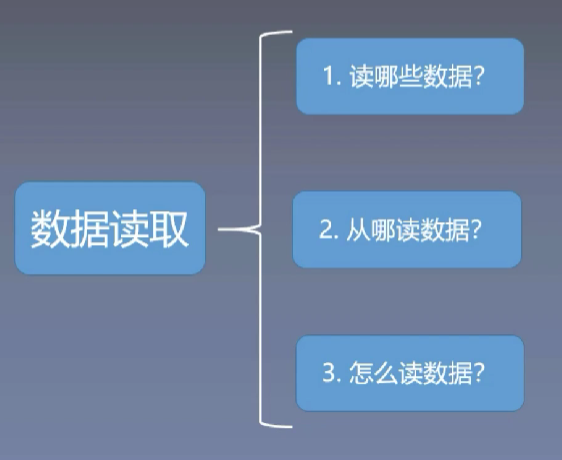
1、读哪些数据?
2、从哪读数据?
通过os库对硬盘上的文件读取
3、怎么读数据?
if __name__ == '__main__':
random.seed(1)
dataset_dir = ps.path.join('..','data')
split_dir = ps.path.join('..','split')
train_dir = os.path.join(split_dir,'train')
valid_dir = os.path.join(split_dir,'valid')
test_dir = os.path.join(split_dir,'test')
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
构建MyDataset实例
train_data = MyDataset(data_dir=train_dir,transform=train_transform)
valid_data = MyDataset(data_dir=train_dir,transform=valid_transform)
构建DataLoder
train_loader = DataLoader(dataset=train_data,batch_size=tensor(32,32),shuffle=True)
valid_loader = DataLoader(dataset=valid_data,batch_size=tensor(32,32))
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结