您现在的位置是:首页 >学无止境 >AI题目整理网站首页学无止境
AI题目整理
1、网络配置时batchsize的大小怎样设置?过小和过大分别有什么特点?
Batch size是指一次迭代过程中,输入到神经网络的样本数量。
batchsize太小的缺点:
①耗时长,训练效率低。
②训练数据就会非常难收敛,从而导致欠拟合。
batchsize增大的优缺点
①大的batchsize减少训练时间
②大的batchsize所需内存容量增加
③大的batch size梯度的计算更加稳定
④大的batchsize可能导致模型泛化能力下降
一般需要考虑训练速度、泛化误差和模型收敛性等因素,根据模型的复杂度、训练数据集的大小、计算资源的可用性等因素进行调整,并结合实际情况进行优化调整。
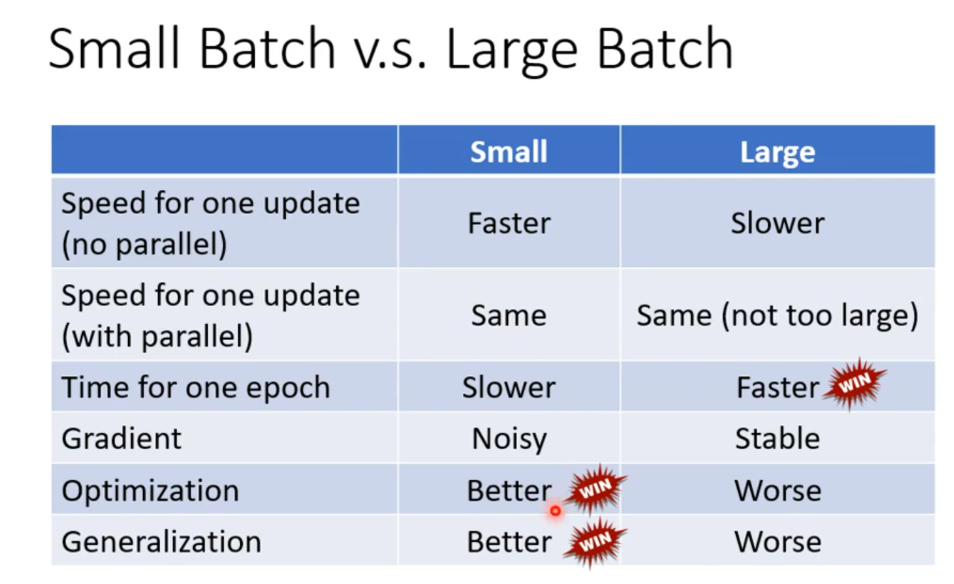
batchsize太小的缺点&随着batchsize逐渐增大的优缺点&如何平衡batchsize的大小
2、设置学习率衰减的原因?
学习率控制了模型在每一次更新权重时所采取的步长大小。如果学习率过高,模型可能会无法收敛,导致训练不稳定;如果学习率过低,损失函数的变化速度很慢,会大大增加网络的收敛复杂度,并且很容易被困在局部最小值。
为了防止学习率过大,在收敛到全局最优点的时候会来回摆荡,所以要让学习率随着训练轮数不断按指数级下降,收敛梯度下降的学习步长。
深度学习——学习率衰减(learning rate decay)
3、有哪些分类算法?
常用的分类算法包括:NBC(Naive Bayesian Classifier,朴素贝叶斯分类)算法、LR(Logistic Regress,逻辑回归)算法、ID3(Iterative Dichotomiser 3 迭代二叉树3 代)决策树算法、C4.5 决策树算法、C5.0 决策树算法、SVM(Support Vector Machine,支持向量机)算法、KNN(K-Nearest Neighbor,K 最近邻)算法、ANN(Artificial Neural Network,人工神经网络)算法等。
数据挖掘算法——常用分类算法总结
【10分钟算法】朴素贝叶斯分类器-带例子/Naive Bayes Classifier
【10分钟算法】层次聚类之最近邻算法-带例子/Nearest Neighbor Algorithm
【五分钟机器学习】机器分类的基石:逻辑回归Logistic Regression
【五分钟机器学习】向量支持机SVM: 学霸中的战斗机
4、分类和回归的区别?
1、输出变量类型:分类问题的输出变量通常是离散的,表示数据点所属的类别或标签,而回归问题的输出是连续的,表示预测的数值。
2、目的:分类问题的目的是对数据进行分类或标记,而回归问题的目的是找到最优拟合,通过回归算法得到是一个最优拟合线,这个线条可以最好的接近数据集中的各个点。
3、评估方法:分类问题通常使用准确率或 F1 分数等指标来评估模型的性能。对于回归问题,通常使用均方误差(Mean Squared Error,MSE)或平均绝对误差(Mean Absolute Error,MAE)等指标来评估模型的性能。
4、数据类型:分类问题通常使用分类数据,即离散变量。而在回归问题中,通常使用连续数据。
5、请描述一下K-means聚类的过程?
步骤
①首先确定要聚类的簇的个数 k,并选取 k 个随机数据点作为 k 个簇的初始中心点。
②对于每一个剩余的数据点,计算其与每个簇的中心点之间的距离,并将该数据点分配到离其最近的簇中。
③对每个簇的数据点重新计算平均值(该簇各个点坐标之和/该簇数据点数)(X,Y分别加和),并将其视为新的簇中心点。这个过程一直执行,直到聚类结果不再发生显著改变或达到预设阈值为止。
④将每个数据点划分至距其最近的簇中,分配规则基于计算的距离。
⑤重新计算每个簇的中心点,再次划分每个数据点。
重复步骤4和5直到算法收敛(每个簇的数据点个数不变或达到阈值)。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结