您现在的位置是:首页 >技术杂谈 >虚拟化与云计算实验网站首页技术杂谈
虚拟化与云计算实验
文章目录
- 一、实验目的
- 二、实验内容
- 三、实验步骤及结果分析
- 四、[MapReduce]编程实验:单词计数统计实现
一、实验目的
学习Hadoop 开源云计算平台的安装、配置和应⽤。实习MapReduce 并⾏计算程序编程。
二、实验内容
2.1 部署方式
Hadoop主要有两种安装方式,即传统解压包方式和Linux标准方式。安装Hadoop的同时,还要明确工作环境的构建模式。Hadoop部署环境分为单机模式、伪分布模式和分布式模式三种。下面主要进行单机模式和分布式安装
2.2 部署步骤(简述)
步骤1:制定部署规划;
步骤2:部署前工作;
步骤3:部署Hadoop;
步骤4:测试Hadoop。
2.3 准备环境
由于分布式计算需要用到很多机器,部署时用户须提供多台机器。本节使用Linux较成熟的发行版CentOS部署Hadoop,须注意的是新装系(CentOS)的机器不可以直接部署Hadoop,须做些设置后才可部署,这些设置主要为:改机器名,添加域名映射,关闭防火墙,安装JDK。
2.4 关于Hadoop依赖软件
Hadoop部署前提仅是完成修改机器名、添加域名映射、关闭防火墙和安装JDK这四个操作,其他都不需要。
2.5 传统解压包部署
相对于标准Linux方式,解压包方式部署Hadoop有利于用户更深入理解Hadoop体系架构,建议先采用解压包方式部署Hadoop,熟悉后可采用标准Linux方式部署Hadoop。以下将实现在三台机器上部署Hadoop。
三、实验步骤及结果分析
1.1 Linux服务器的安装
- 通过安装VMware安装Linux机器,点击创建新虚拟机,选择自定义配置

- 选择稍后安装操作系统
- 选择CentOS 7
- 选择安装路径
- CPU核数默认即可
- 虚拟机内存设置
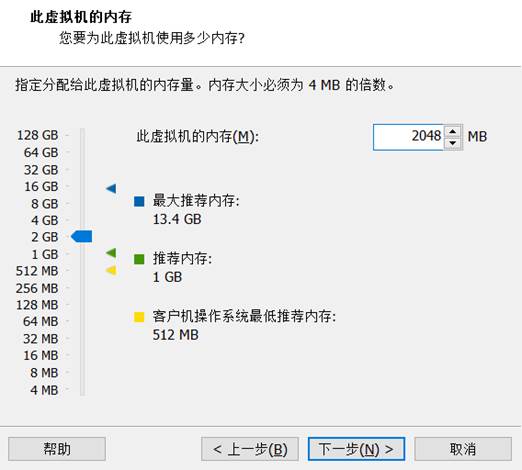
- 网络配置选择
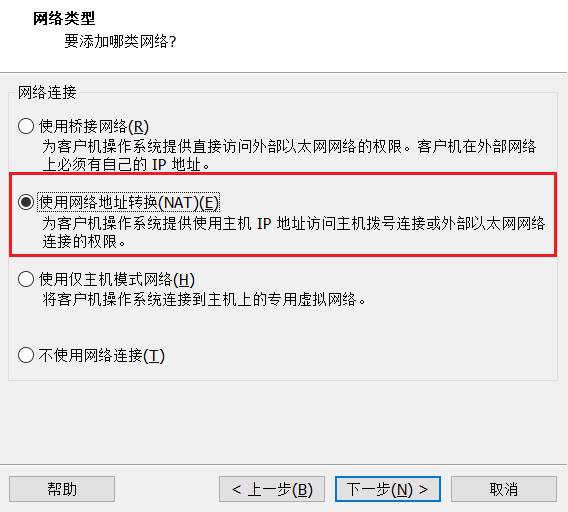
- 新建虚拟磁盘
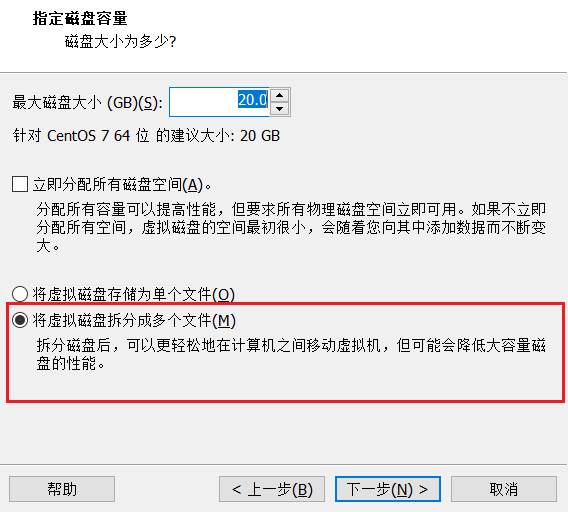
默认即可
- 完成创建
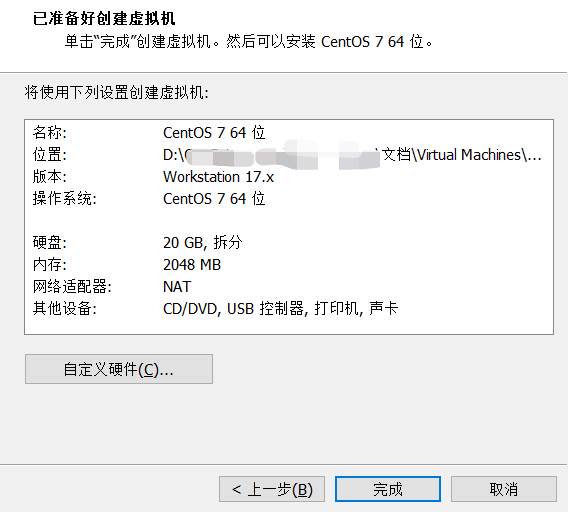
10.挂载操作系统
通过虚拟机设置挂载操作系统
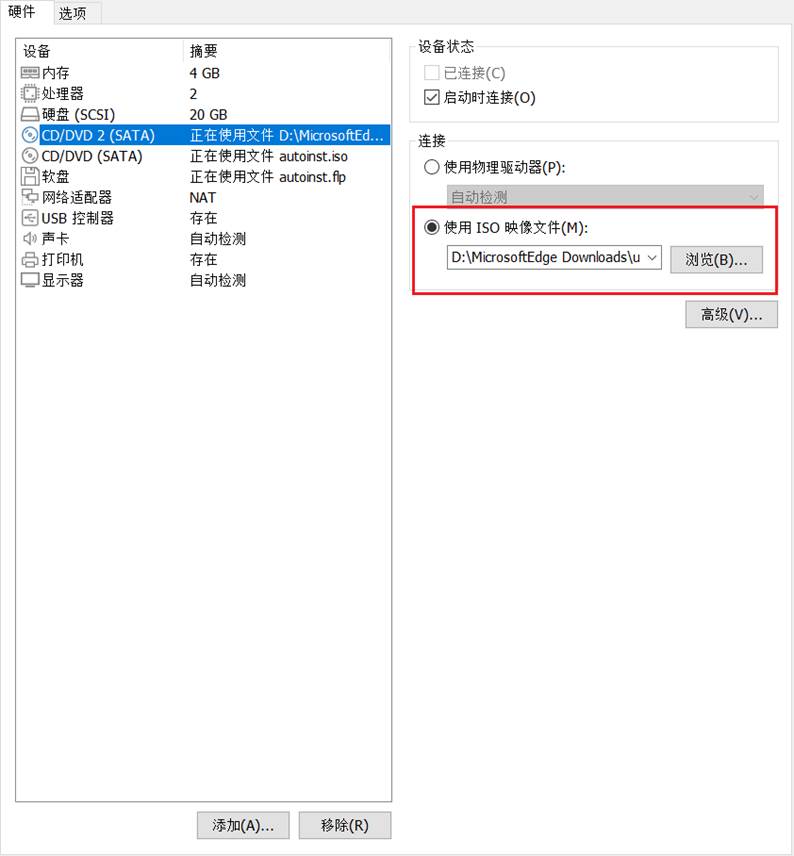
设置完成,启动虚拟机进行配置
11.进行网络配置
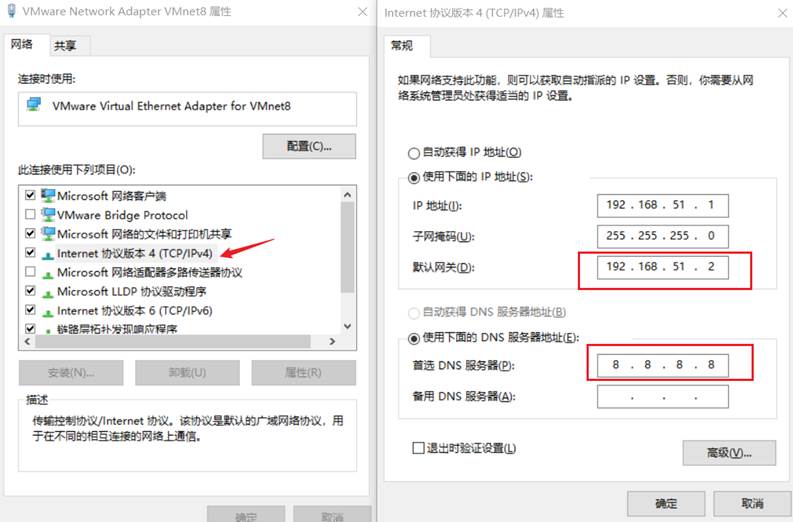
登录虚拟机,编辑网络配置文件
输入编辑命令

编辑文件
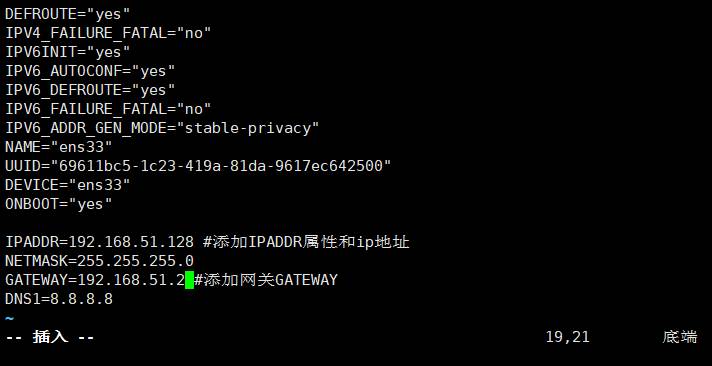
更改配置后,重启网络服务

12.克隆机器

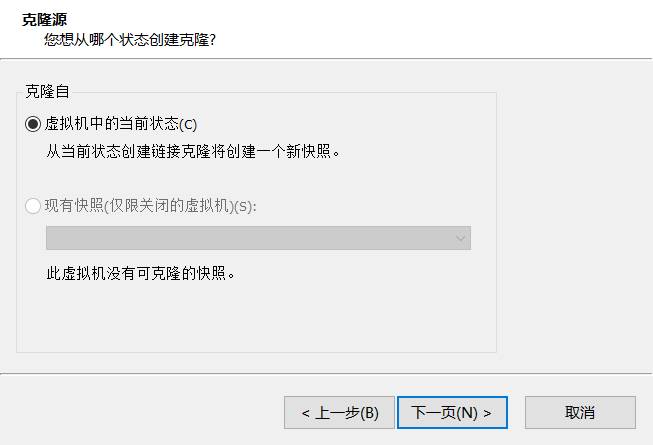
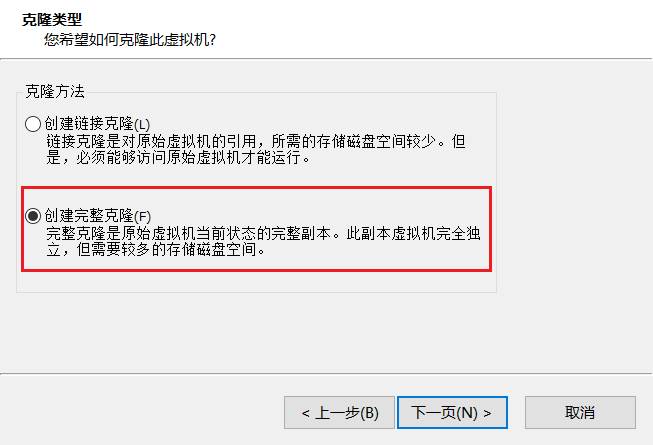
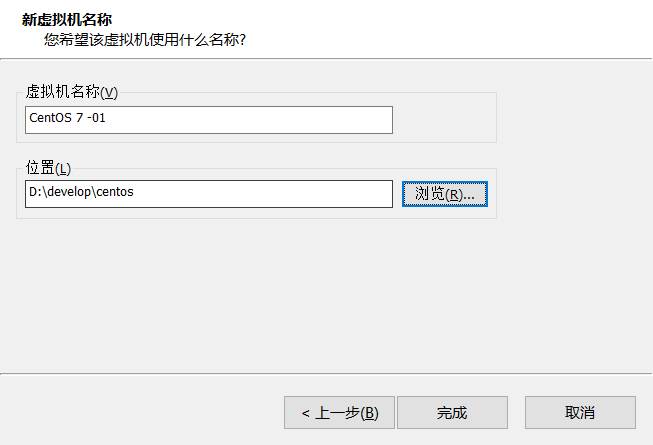
13.更改克隆机器地址
三台机器ip地址分别为192.168.51.129、192.168.51.130、192.168.51.131
克隆机器ip均为192.168.51.129,启动虚拟机编辑网络配置文件的ip地址即可
命令:vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改内容:
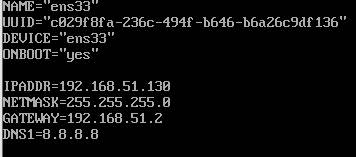
第三台机器同理。
1.2 部署大数据集群前的环境准备
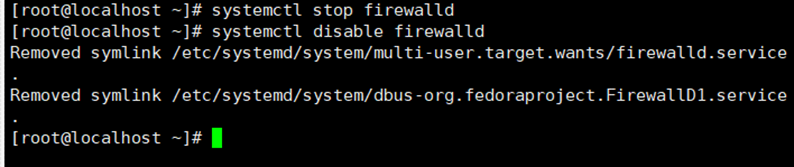
1.2.1 关闭防火墙
输入命令:systemctl stop firewalld
systemctl disable firewalld
1.2.2 机器关闭selinux
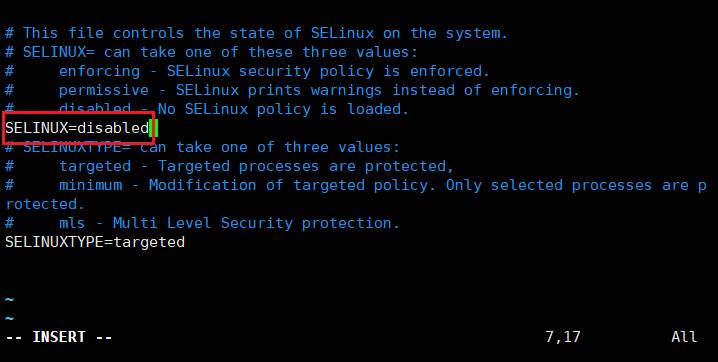
执行以下命令:vim /etc/sysconfig/selinux
修改配置:SELINUX=disabled
1.2.3 机器更改主机名
三台机器执行命令:
hostnamectl set-hostname Hadoop01
将机器名修改为Hadoop01,三台机器执行如下:



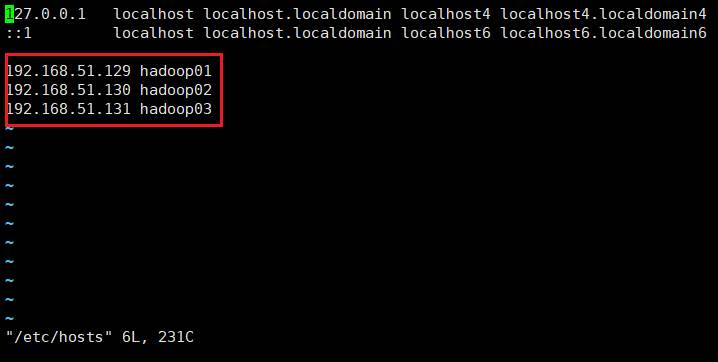
1.2.4 主机名与IP地址的映射
执行命令:
vi /etc/hosts
修改配置:
1.2.5 时钟同步
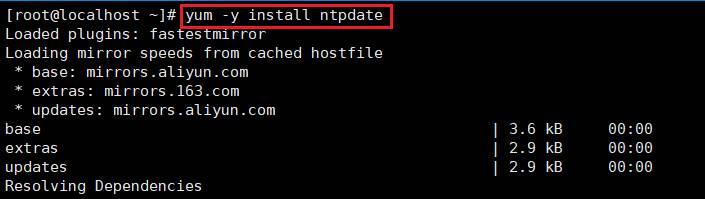
- 安装npdate
执行命令:yum -y install ntpdate
- 阿里云同步服务器
执行命令:ntpdate ntp4.aliyun.com

- 定时任务
执行命令:crontab -e
添加如下内容:

1.2.6 添加普通用户
三台linux服务器统一添加普通用户hadoop,并给以sudo权限,统一设置普通用户的密码为 123456
- 执行如下命令
useradd hadoop
passwd hadoop
- 为普通用户添加sudo权限
执行如下命令:
visudo
增加如下内容
hadoop ALL=(ALL) ALL
1.2.7 关机重启
执行命令:sudo reboot -h now
1.2.8 hadoop用户免密码登录
- 机器在hadoop用户下执行以下命令生成公钥与私钥
执行如下命令:
ssh-keygen -t rsa
- 三台机器在hadoop用户下,执行命令拷贝公钥到hadoop01服务器
执行命令:ssh-copy-id hadoop01
- hadoop01服务器将公钥拷贝给hadoop02与hadoop03
hadoop01服务器执行如下命令:
cd /home/hadoop/.ssh/
scp authorized_keys hadoop02:$PWD
scp authorized_keys hadoop03:$PWD
- 验证;从任意节点是否能免秘钥登陆其他节点

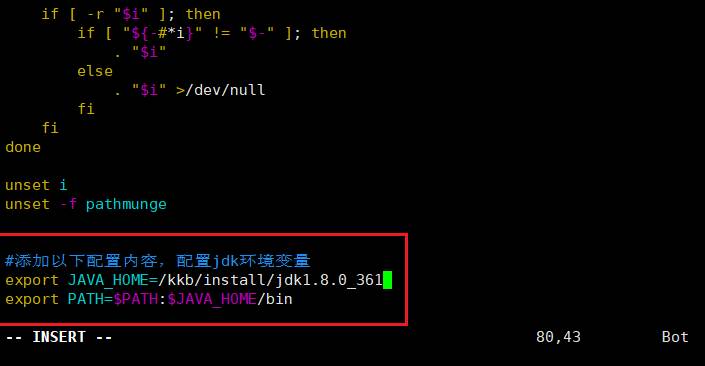
1.2.9 安装JDK
执行命令:cd /kkb/soft
解压压缩包:tar - xzvf jdk-8u361-linux-x64.tar.gz -C /kkb/install(在本地使用WinSCP上传压缩包到虚拟机)
修改配置:sudo vim /etc/profile
使配置生效,执行命令:
source /etc/profile
查看是否安装成功,命令:java -version

1.3 Hadoop集群的安装
配置文件代码
1.3.1 修改系统配置文件
Hadoop01执行命令:
cd /kkb/install/hadoop-3.3.1/etc/hadoop/
vim hadoop-env.sh
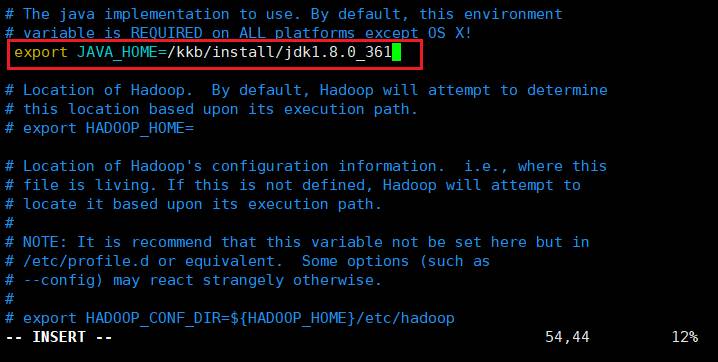
修改配置,添加export JAVA_HOME=/kkb/install/jdk1.8.0_361
1.3.2 修改core-site.xml
Hadoop01执行以下命令:
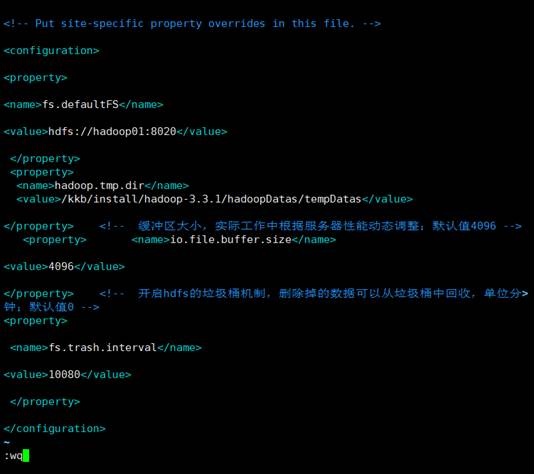
vim core-site.xml
修改文件,添加配置:
1.3.3 修改hdfs-site.xml
Hadoop01执行命令:
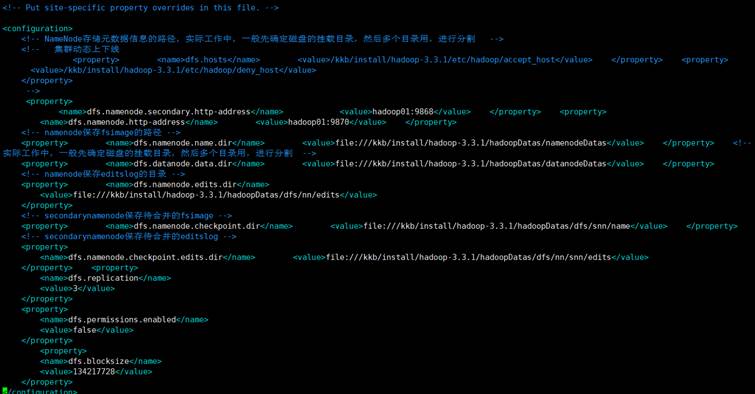
vim hdfs-site.xml
修改文件:
1.3.4 修改mapred-site.xml
hadoop01执行如下命令:
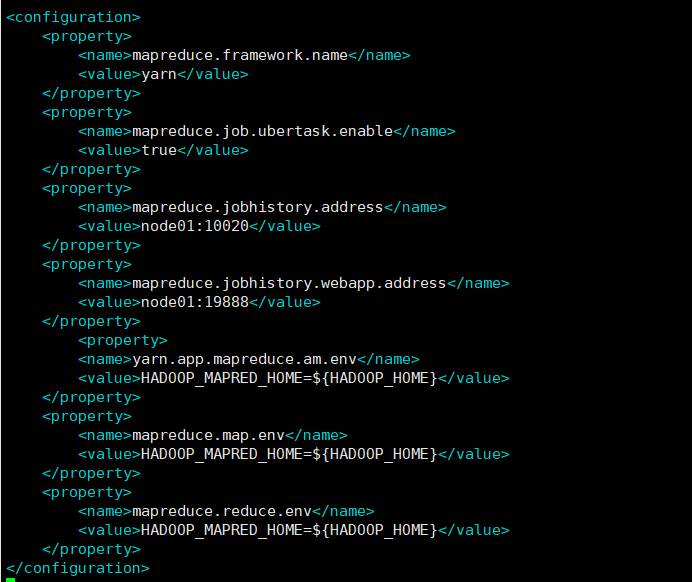
vim mapred-site.xml
修改文件:
1.3.5 修改yarn-site.xml
hadoop01执行如下命令:
vim yarn-site.xml
修改文件:
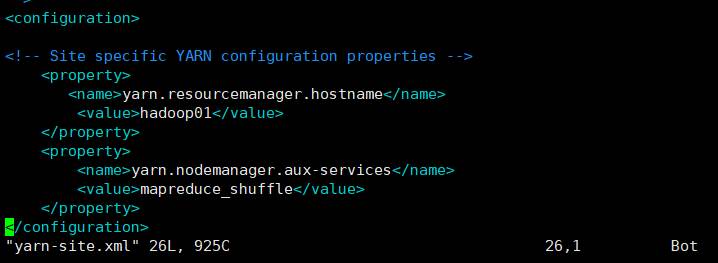
1.3.6 修改workers文件
hadoop01执行如下命令:
vim workers
修改文件,原内容替换如下:

1.3.7 创建文件存放目录
Hadoop01执行如下命令创建目录:
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/tempDatas
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/namenodeDatas
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/datanodeDatas
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/dfs/nn/edits
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/dfs/snn/name
mkdir -p /kkb/install/hadoop-3.3.1/hadoopDatas/dfs/nn/snn/edits
1.3.8 安装包的分发scp与rsync
1.3.8.1 通过scp直接拷贝
通过scp进行不同服务器之间的文件或文件夹的复制
hadoop01执行如下命令:
cd /kkb/install/
scp -r hadoop-3.3.1/ hadoop02:$PWD
scp -r hadoop-3.3.1/ hadoop03:$PWD
1.3.8.2 通过rsync来实现增量拷贝
rsync 远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去
虚拟机都执行如下命令进行安装rsync工具:
```bash
sudo yum -y install rsync
```
基本语法
hadoop01执行以下命令同步zk安装包
rsync -av /kkb/soft/apache-zookeeper-3.6.2-bin.tar.gz node02:/kkb/soft/
命令 选项参数 要拷贝的文件路径/名称 目的用户@主机:目的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
1.3.8.3 xsync集群分发脚本
(1)需求:循环复制文件到所有节点的相同目录下
(2)需求分析:
(a)rsync命令原始拷贝:
rsync -av /opt/module hadoop@hadoop01:/opt/
(b)期望脚本:
xsync要同步的文件名称
(c)期望脚本在任何路径都能使用
(3)脚本实现
(a)在/home/hadoop目录下创建bin目录,并在bin目录下xsync创建文件,文件内容如下:
hadoop01执行如下命令:
cd ~
cd /home/hadoop/bin
touch xsync
vim xsync
文件内容如下:
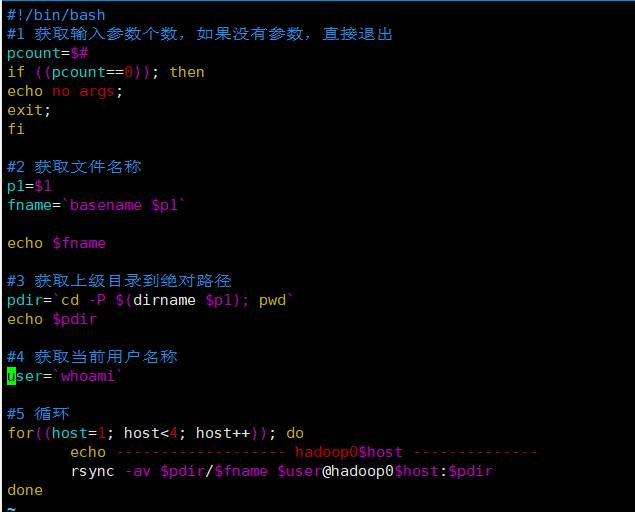
b)修改脚本 xsync 具有执行权限
chmod +x xsync
(c)测试脚本
xsync /home/hadoop/bin
(d)将脚本复制到/usr/local/bin中,以便全局调用
sudo cp xsync /usr/local/bin
1.3.9 配置hadoop的环境变量
虚拟机均执行如下命令:
sudo vim /etc/profile
修改文件,添加配置:
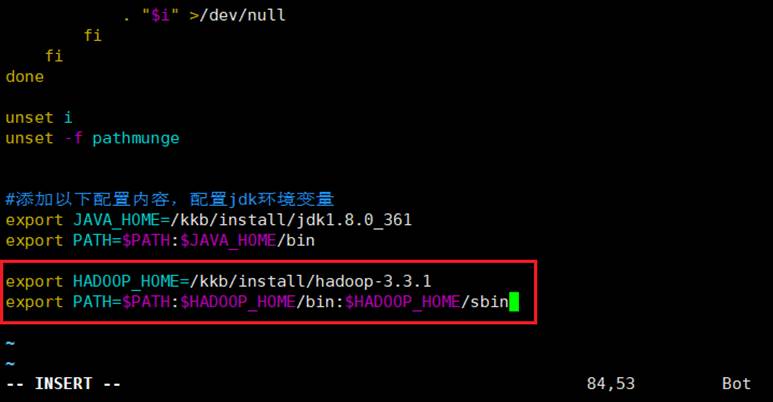
修改完成后使配置生效
执行命令:
source /etc/profile
1.3.10 格式化集群
要启动 Hadoop 集群,需要启动 HDFS 和 YARN 两个集群。
注意:首次启动HDFS时,必须对其进行格式化操作。本质上是一些清理和准备工作,因为此时的 HDFS 在物理上还是不存在的。格式化操作只有在首次启动的时候需要,以后再也不需要了
hadoop01执行一遍即可
命令如下:
hdfs namenode -format 或 hadoop namenode –format
1.3.11 集群启动
启动集群有两种方式:
① 脚本一键启动;
②单个进程逐个启动
1.3.11.1 启动HDFS、YARN、Historyserver
如果配置了 etc/hadoop/workers 和 ssh 免密登录,则可以使用程序脚本启动所有Hadoop 两个集群的相关进程,在主节点所设定的机器上执行。
启动集群
主节点hadoop01节点上执行以下命令
启动集群
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver
停止集群(主节点hadoop01节点上执行):
stop-dfs.sh
stop-yarn.sh
mapred --daemon stop historyserver
1.3.11.2 一键启动hadoop集群的脚本
为了便于一键启动hadoop集群,我们可以编写shell脚本
在hadoop01服务器的/home/hadoop/bin目录下创建脚本
执行命令:
cd /home/hadoop/bin/
vim hadoop.sh
文件内容如下:
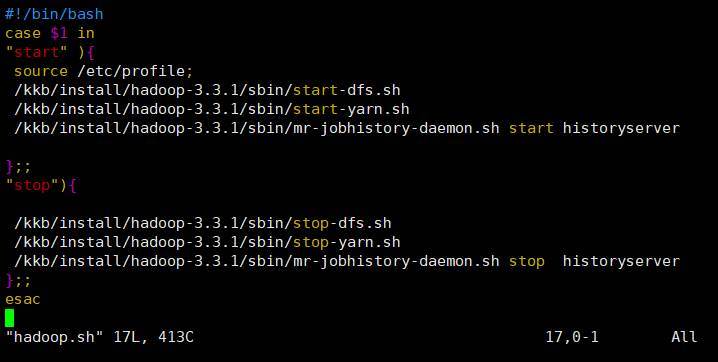
修改脚本权限
执行如下命令:
chmod 777 hadoop.sh
[hadoop@hadoop01 bin]$ ./hadoop.sh start # 启动hadoop集群
[hadoop@hadoop01 bin]$ ./hadoop.sh stop # 停止hadoop集群
1.3.12 验证集群
1.3.12.1 查看网站
(1)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop01:9870
(b)查看HDFS上存储的数据信息
(2)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop01:8088
(b)查看YARN上运行的Job信息
(3)查看JobHistory
浏览器输入:http://hadoop01:19888/jobhistory
注意:未配置本地电脑hosts文件的根据ip地址进行修改,将主机名称改为ip地址
1.3.12.2 查看进程脚本
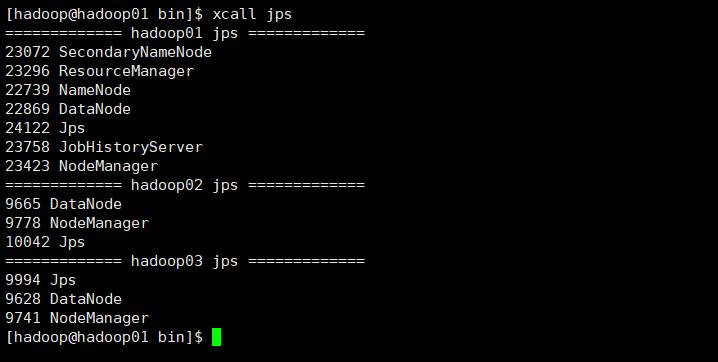
我们也可以通过jps在每台机器上面查看进程名称,为了方便我们以后查看进程,我们可以通过脚本一键查看所有机器的进程
在hadoop01服务器的/home/hadoop/bin目录下创建文件xcall
执行命令:
vim xcall
文件内容如下:
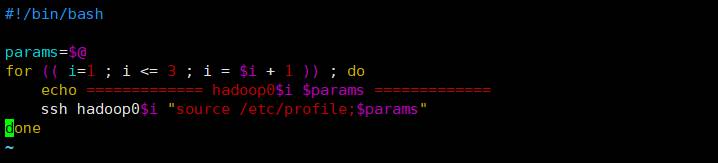
修改脚本权限并分发
命令如下:
chmod 777 /home/hadoop/bin/xcall
xsync /home/hadoop/bin/
将脚本复制到/usr/local/bin中,以便全局调用
sudo cp xcall /usr/local/bin
调用脚本
xcall jsp
各节点进程如下图:
1.3.12.3 运行一个mr例子
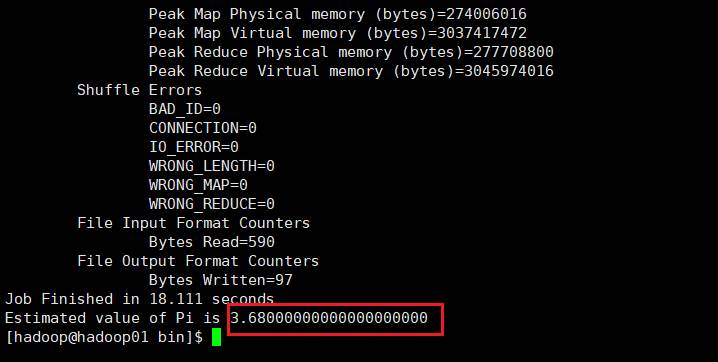
执行命令:
hadoop jar /kkb/install/hadoop-3.3.1/share/hadoop/mapreduce/
hadoop-mapreduce-examples-3.3.1.jar pi 5 5
结果如下:
四、[MapReduce]编程实验:单词计数统计实现
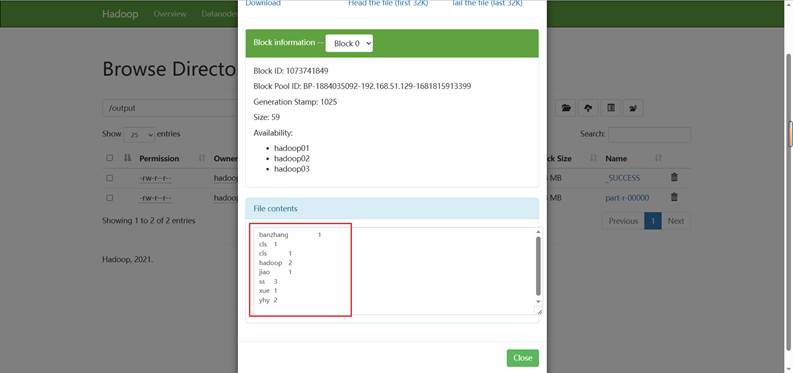
需求:现有数据格式如下,每一行数据之间都是使用空格进行分割,求取每个单词出现的次数
hadoop hadoop
banzhang
xue
cls cls
jiao
ss ss ss
yhy yhy
2.1 创建maven工程并导入以下jar包
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<hadoop.version>3.0.0</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/junit/junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.testng</groupId>
<artifactId>testng</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<!-- <verbal>true</verbal>-->
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.2 定义WordCountMapper类
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key的类型:LongWritable
* VALUEIN,map阶段输入value类型:Text
* KEYOUT,map阶段输出的Key类型:Text
* VALUEOUT,map阶段输出的value类型:IntWritable
*/
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 循环写出
for (String word : words) {
// 封装outk
outK.set(word);
// 写出
context.write(outK, outV);
}
}
}
2.3 定义WordCountReducer类
package com.hadoop.mapreduce.wordcount;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN, reduce阶段输入的key的类型:Text
* VALUEIN,reduce阶段输入value类型:IntWritable
* KEYOUT,reduce阶段输出的Key类型:Text
* VALUEOUT,reduce阶段输出的value类型:IntWritable
*/
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// 累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
// 写出
context.write(key,outV);
}
}
2.4 定义WordCountDriver类
package com.atguigu.mapreduce.wordcount2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
运行结果:
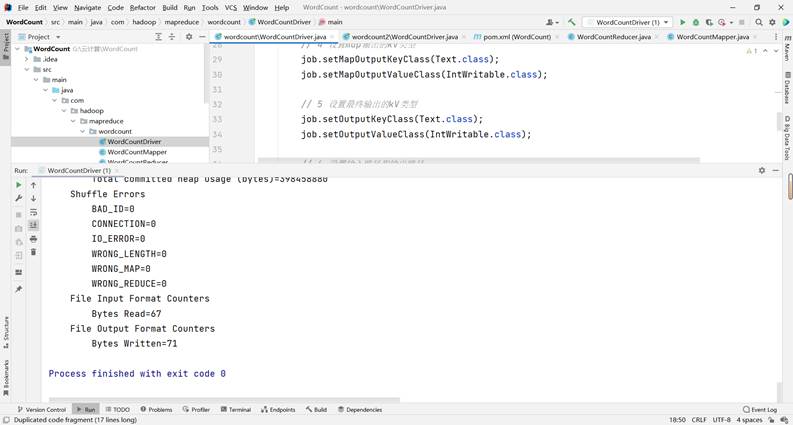
输出结果:

2.5 集群测试
将程序进行打成jar包
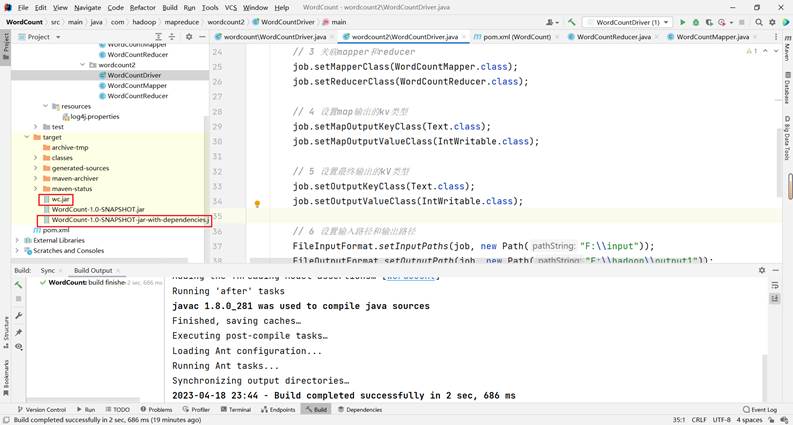
修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群的/kkb/install/hadoop-3.1.3路径。
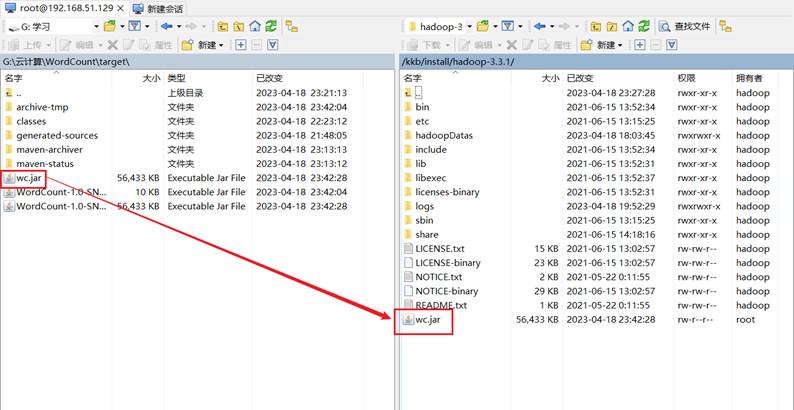
执行WordCount程序:
hadoop jar wc.jar com.hadoop.mapreduce.wordcount.WordCountDriver /input /output
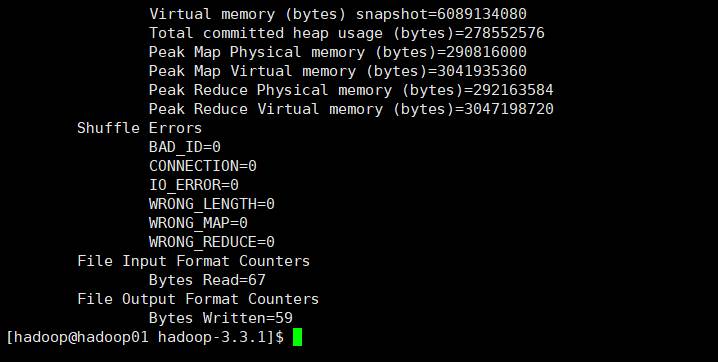
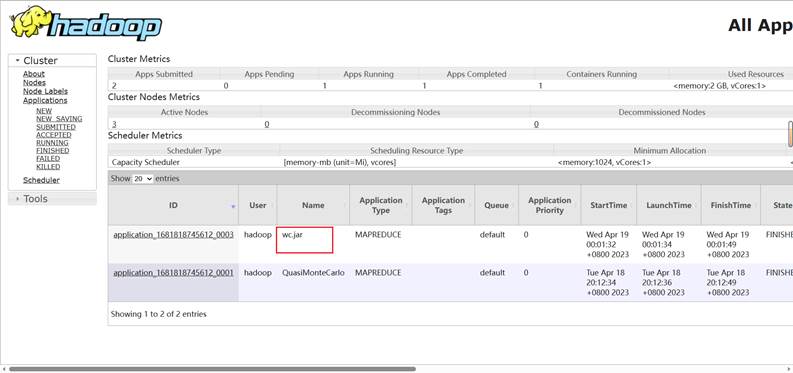
运行结果:






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结