您现在的位置是:首页 >技术交流 >RDD的Stage划分原理网站首页技术交流
RDD的Stage划分原理
1. 什么是RDD
RDD(Resilient Distributed Dataset)叫做分布式数据集,是Spark 中最基本的数据抽象,它代表一个不可变、可分区、里面的元素可并行计算的集合。在Spark 中,对数据的所有操作不外乎创建RDD、转化已有RDD 以及调用RDD 操作进行求值。每个RDD 都被分为多个分区,这些分区运行在集群中的不同节点上。RDD 可以包含Python、Java、Scala 中任意类型的对象, 甚至可以包含用户自定义的对象。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,这极大地提升了查询速度。RDD 支持两种操作:transformation操作和action操作。RDD 的转化操作是返回一个新的RDD 的操作,比如map()和filter(),而action操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如count() 和first()。
Spark 采用惰性计算模式,RDD 只有第一次在一个行动操作中用到时,才会真正计算。Spark 可以优化整个计算过程。默认情况下,Spark 的RDD 会在你每次对它们进行行动操作时重新计算。
2. 宽依赖与窄依赖
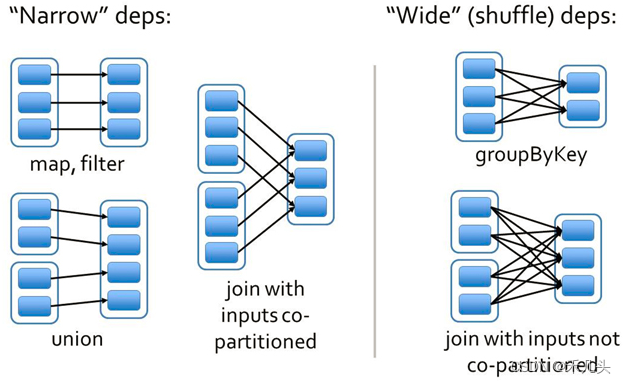
- 定义
-
窄依赖是指父RDD的每个分区只被子RDD的一个分区所使用,子RDD分区通常对应常数个父RDD分区(O(1),与数据规模无关)
-
相应的,宽依赖是指父RDD的每个分区都可能被多个子RDD分区所使用,子RDD分区通常对应所有的父RDD分区(O(n),与数据规模有关)
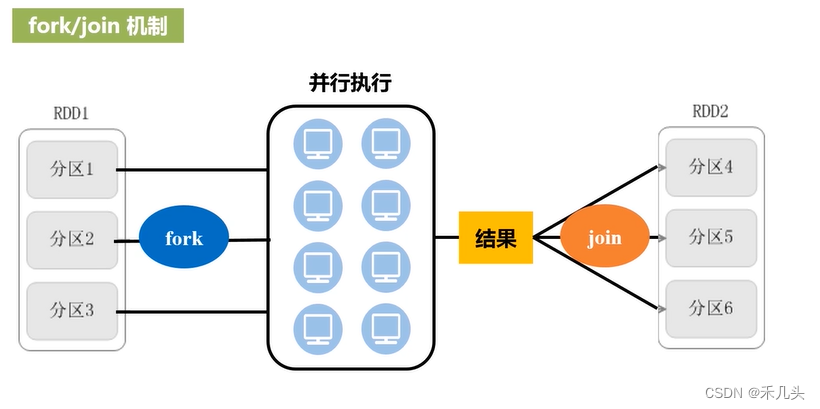
- 并行计算框架中的fork/join机制

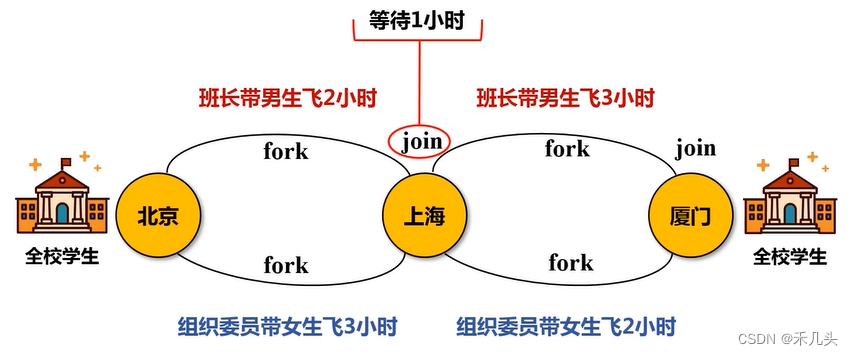
- 实例解释为什么窄依赖可以进行流水线优化,宽依赖无法进行流水线优化
假设需要将学校的学生分不同的线路运送到厦门,途中在上海集合等待后继续前往厦门,如图所示,最后所有学生到达厦门所需时间为6小时,这里发现学生运送过程中没必要在上海进行集合,此过程可以省略,最后的运送总时间将缩短为5小时,这就是一个窄依赖优化的例子。
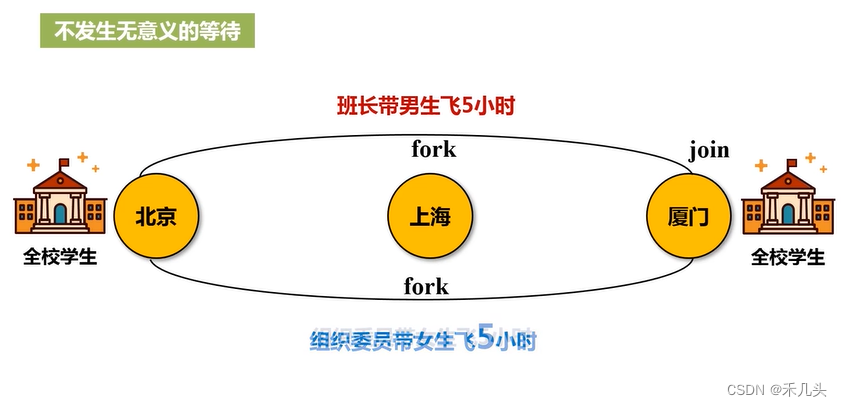
接下来考虑另外一种情况,当学生到达上海后,学生需要重新分配路线,比如班长带所有1班学生走1号线,组织委员带2班学生走2号线,此时就不得不在上海聚集进行人员的重新分配,这就是一个宽依赖的例子,这种情况下则无法按照上述的方式进行流水线优化
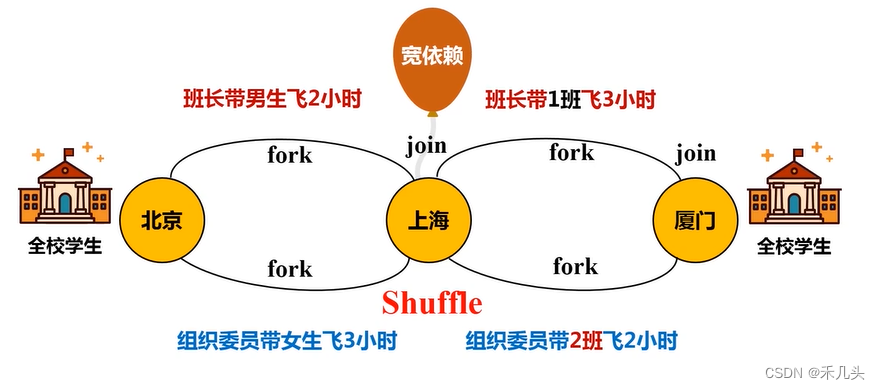
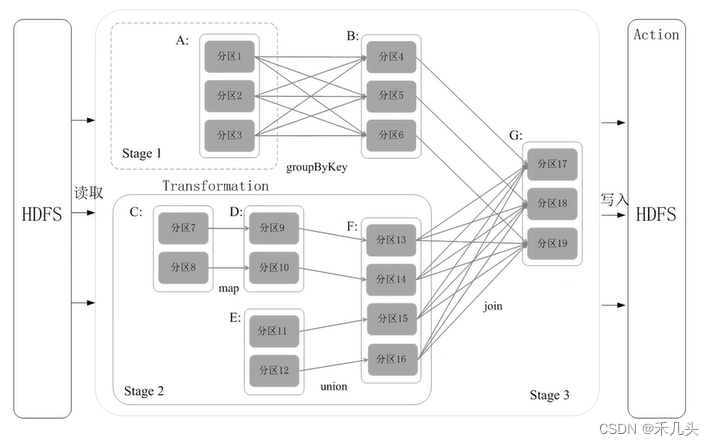
将例子运用到RDD的运行过程中就是一个DAG(有向无环图),可以将DAG划分为不同的阶段,窄依赖之间不需要反复join操作可以将一系列的窄依赖操作归为一个stage进行流水线优化,而宽依赖则直接归为一个stage,如下图所示
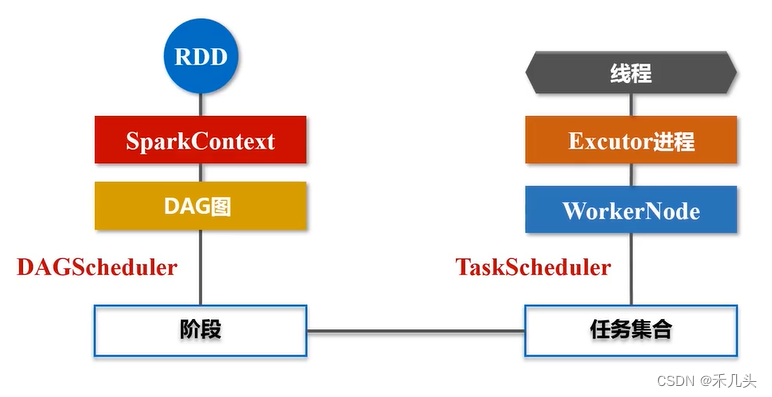
由此RDD的整个运行流程如下:
文章中的实例内容参考于中国大学mooc网中的厦门大学大数据课程内容
宽依赖窄依赖参考





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结