您现在的位置是:首页 >学无止境 >Python Unet ++ :医学图像分割,医学细胞分割,Unet医学图像处理,语义分割网站首页学无止境
Python Unet ++ :医学图像分割,医学细胞分割,Unet医学图像处理,语义分割
一,语义分割:分割领域前几年的发展
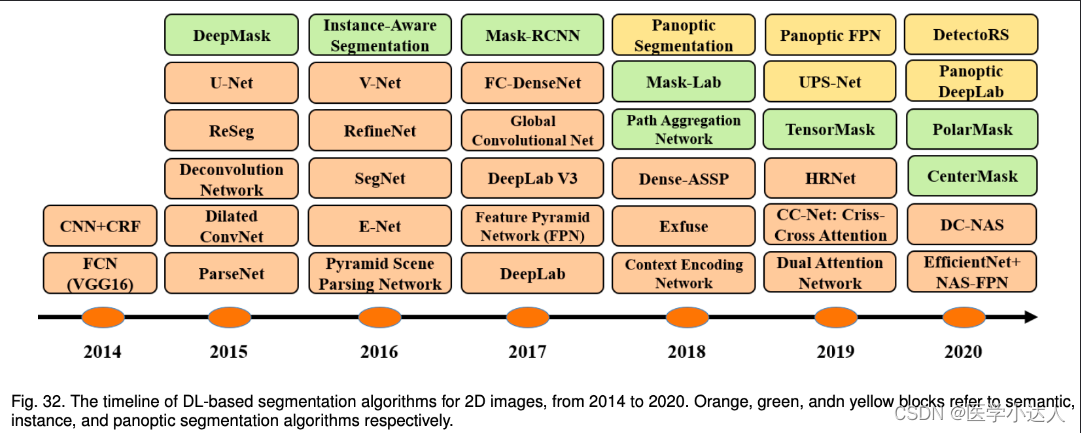
图像分割是机器视觉任务的一个重要基础任务,在图像分析、自动驾驶、视频监控等方面都有很重要的作用。图像分割可以被看成一个分类任务,需要给每个像素进行分类,所以就比图像分类任务更加复杂。此处主要介绍 Deep Learning-based 相关方法。





主要介绍unet和unet++
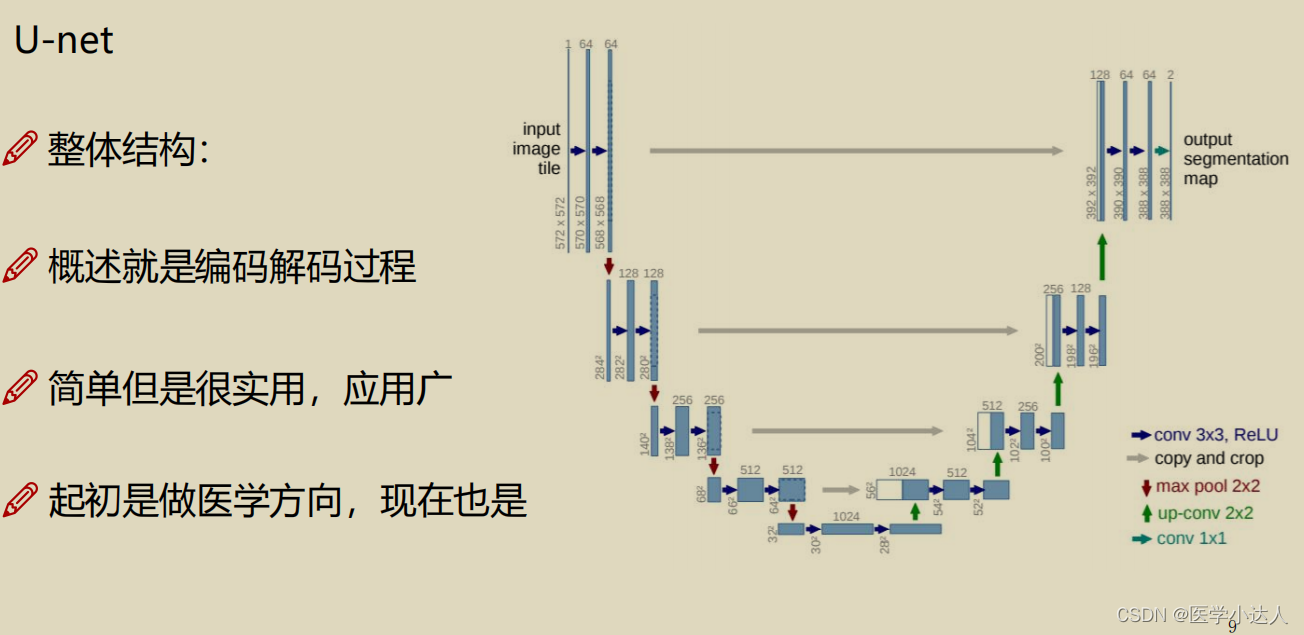
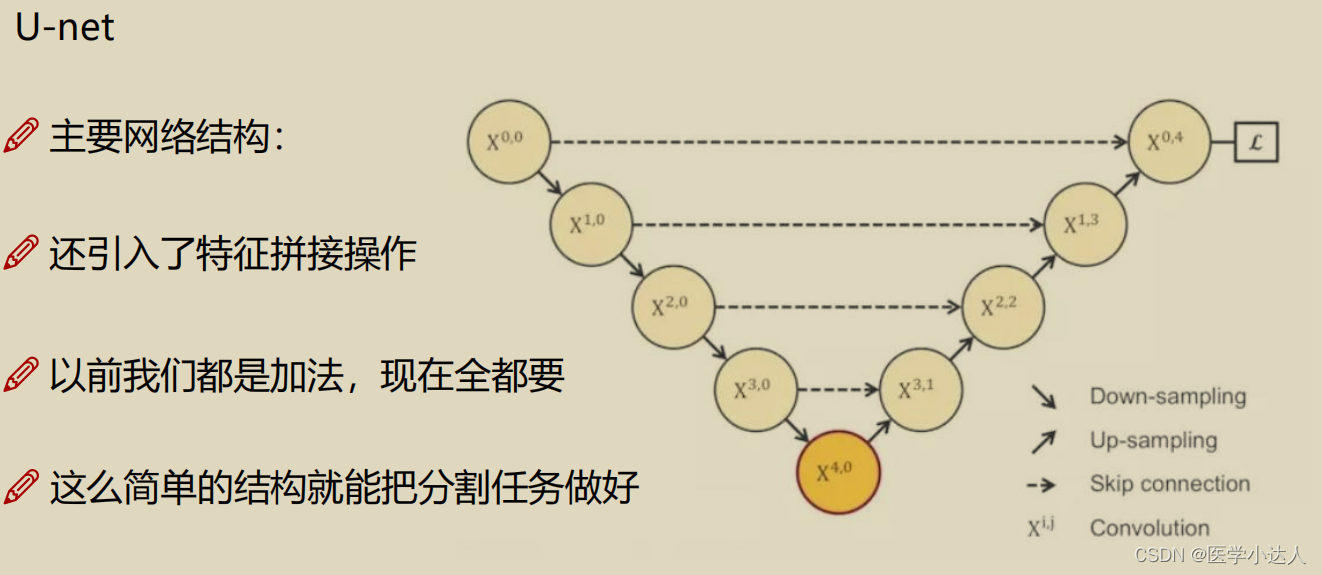
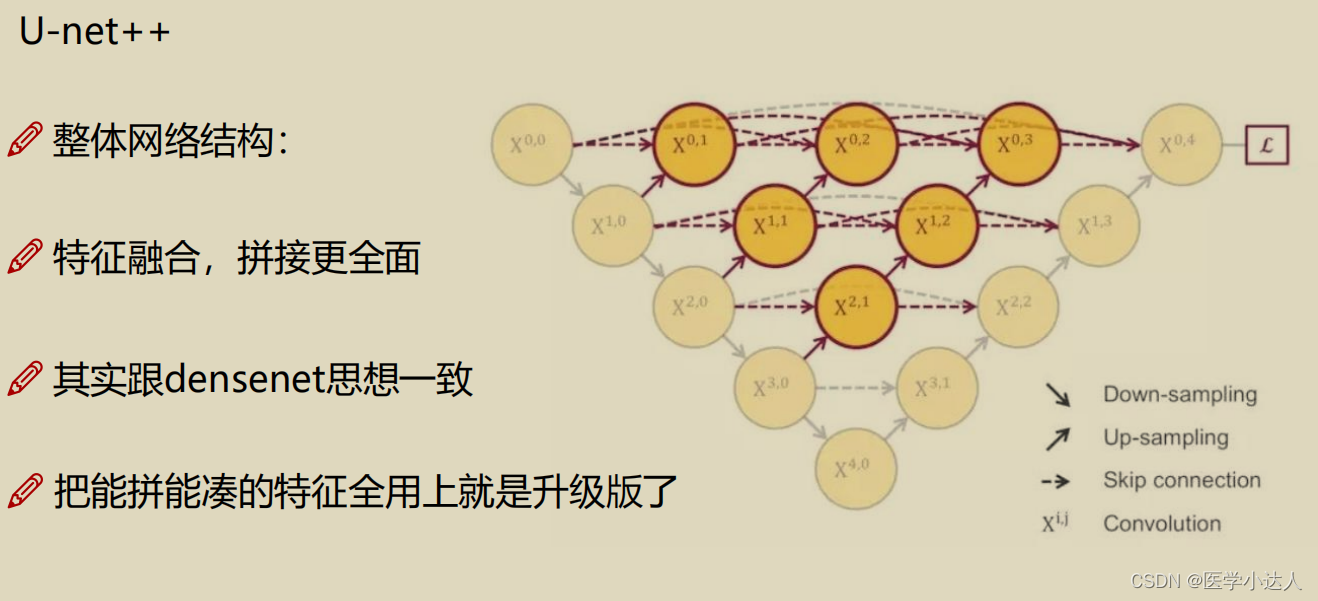

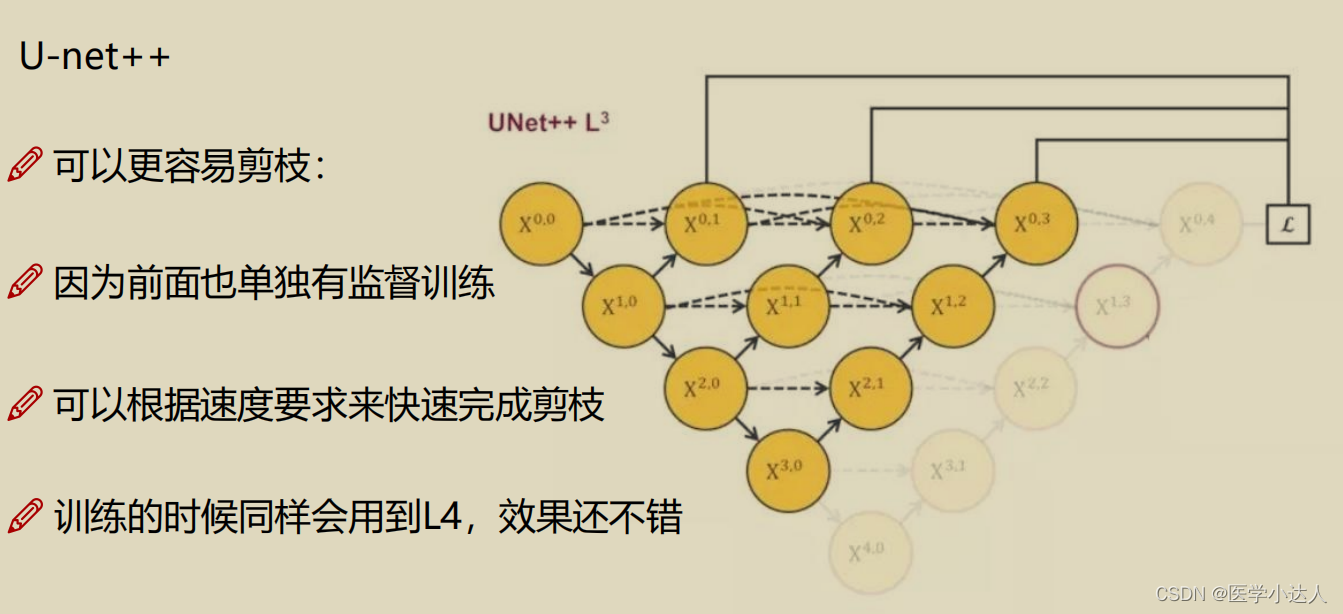
二,数据介绍---医学细胞分割任务
原数据:
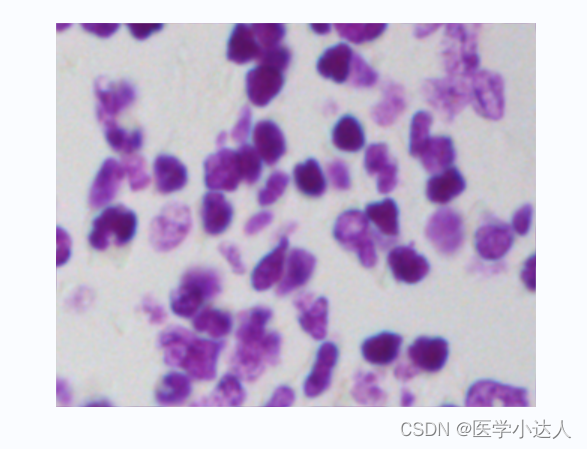
标签数据:

三,代码部分
模型包含以下文件:
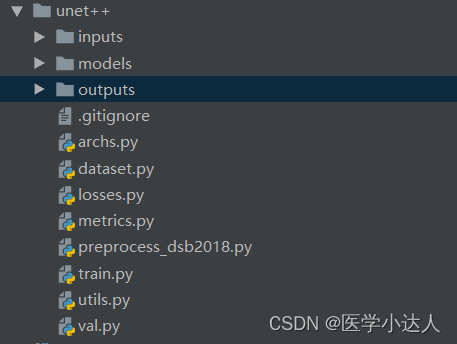
archs.py为模型的主体部分:
import torch
from torch import nn
__all__ = ['UNet', 'NestedUNet']
class VGGBlock(nn.Module):
def __init__(self, in_channels, middle_channels, out_channels):
super().__init__()
self.relu = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(in_channels, middle_channels, 3, padding=1)
self.bn1 = nn.BatchNorm2d(middle_channels)
self.conv2 = nn.Conv2d(middle_channels, out_channels, 3, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
return out
class UNet(nn.Module):
def __init__(self, num_classes, input_channels=3, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)#scale_factor:放大的倍数 插值
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv2_2 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv1_3 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
x0_0 = self.conv0_0(input)
x1_0 = self.conv1_0(self.pool(x0_0))
x2_0 = self.conv2_0(self.pool(x1_0))
x3_0 = self.conv3_0(self.pool(x2_0))
x4_0 = self.conv4_0(self.pool(x3_0))
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
x2_2 = self.conv2_2(torch.cat([x2_0, self.up(x3_1)], 1))
x1_3 = self.conv1_3(torch.cat([x1_0, self.up(x2_2)], 1))
x0_4 = self.conv0_4(torch.cat([x0_0, self.up(x1_3)], 1))
output = self.final(x0_4)
return output
class NestedUNet(nn.Module):
def __init__(self, num_classes, input_channels=3, deep_supervision=False, **kwargs):
super().__init__()
nb_filter = [32, 64, 128, 256, 512]
self.deep_supervision = deep_supervision
self.pool = nn.MaxPool2d(2, 2)
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv0_0 = VGGBlock(input_channels, nb_filter[0], nb_filter[0])
self.conv1_0 = VGGBlock(nb_filter[0], nb_filter[1], nb_filter[1])
self.conv2_0 = VGGBlock(nb_filter[1], nb_filter[2], nb_filter[2])
self.conv3_0 = VGGBlock(nb_filter[2], nb_filter[3], nb_filter[3])
self.conv4_0 = VGGBlock(nb_filter[3], nb_filter[4], nb_filter[4])
self.conv0_1 = VGGBlock(nb_filter[0]+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_1 = VGGBlock(nb_filter[1]+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_1 = VGGBlock(nb_filter[2]+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv3_1 = VGGBlock(nb_filter[3]+nb_filter[4], nb_filter[3], nb_filter[3])
self.conv0_2 = VGGBlock(nb_filter[0]*2+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_2 = VGGBlock(nb_filter[1]*2+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv2_2 = VGGBlock(nb_filter[2]*2+nb_filter[3], nb_filter[2], nb_filter[2])
self.conv0_3 = VGGBlock(nb_filter[0]*3+nb_filter[1], nb_filter[0], nb_filter[0])
self.conv1_3 = VGGBlock(nb_filter[1]*3+nb_filter[2], nb_filter[1], nb_filter[1])
self.conv0_4 = VGGBlock(nb_filter[0]*4+nb_filter[1], nb_filter[0], nb_filter[0])
if self.deep_supervision:
self.final1 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final2 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final3 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
self.final4 = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
else:
self.final = nn.Conv2d(nb_filter[0], num_classes, kernel_size=1)
def forward(self, input):
print('input:',input.shape)
x0_0 = self.conv0_0(input)
print('x0_0:',x0_0.shape)
x1_0 = self.conv1_0(self.pool(x0_0))
print('x1_0:',x1_0.shape)
x0_1 = self.conv0_1(torch.cat([x0_0, self.up(x1_0)], 1))
print('x0_1:',x0_1.shape)
x2_0 = self.conv2_0(self.pool(x1_0))
print('x2_0:',x2_0.shape)
x1_1 = self.conv1_1(torch.cat([x1_0, self.up(x2_0)], 1))
print('x1_1:',x1_1.shape)
x0_2 = self.conv0_2(torch.cat([x0_0, x0_1, self.up(x1_1)], 1))
print('x0_2:',x0_2.shape)
x3_0 = self.conv3_0(self.pool(x2_0))
print('x3_0:',x3_0.shape)
x2_1 = self.conv2_1(torch.cat([x2_0, self.up(x3_0)], 1))
print('x2_1:',x2_1.shape)
x1_2 = self.conv1_2(torch.cat([x1_0, x1_1, self.up(x2_1)], 1))
print('x1_2:',x1_2.shape)
x0_3 = self.conv0_3(torch.cat([x0_0, x0_1, x0_2, self.up(x1_2)], 1))
print('x0_3:',x0_3.shape)
x4_0 = self.conv4_0(self.pool(x3_0))
print('x4_0:',x4_0.shape)
x3_1 = self.conv3_1(torch.cat([x3_0, self.up(x4_0)], 1))
print('x3_1:',x3_1.shape)
x2_2 = self.conv2_2(torch.cat([x2_0, x2_1, self.up(x3_1)], 1))
print('x2_2:',x2_2.shape)
x1_3 = self.conv1_3(torch.cat([x1_0, x1_1, x1_2, self.up(x2_2)], 1))
print('x1_3:',x1_3.shape)
x0_4 = self.conv0_4(torch.cat([x0_0, x0_1, x0_2, x0_3, self.up(x1_3)], 1))
print('x0_4:',x0_4.shape)
if self.deep_supervision:
output1 = self.final1(x0_1)
output2 = self.final2(x0_2)
output3 = self.final3(x0_3)
output4 = self.final4(x0_4)
return [output1, output2, output3, output4]
else:
output = self.final(x0_4)
return output
dataset.py为数据的预处理部分
import os
import cv2
import numpy as np
import torch
import torch.utils.data
class Dataset(torch.utils.data.Dataset):
def __init__(self, img_ids, img_dir, mask_dir, img_ext, mask_ext, num_classes, transform=None):
"""
Args:
img_ids (list): Image ids.
img_dir: Image file directory.
mask_dir: Mask file directory.
img_ext (str): Image file extension.
mask_ext (str): Mask file extension.
num_classes (int): Number of classes.
transform (Compose, optional): Compose transforms of albumentations. Defaults to None.
Note:
Make sure to put the files as the following structure:
<dataset name>
├── images
| ├── 0a7e06.jpg
│ ├── 0aab0a.jpg
│ ├── 0b1761.jpg
│ ├── ...
|
└── masks
├── 0
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
|
├── 1
| ├── 0a7e06.png
| ├── 0aab0a.png
| ├── 0b1761.png
| ├── ...
...
"""
self.img_ids = img_ids
self.img_dir = img_dir
self.mask_dir = mask_dir
self.img_ext = img_ext
self.mask_ext = mask_ext
self.num_classes = num_classes
self.transform = transform
def __len__(self):
return len(self.img_ids)
def __getitem__(self, idx):
img_id = self.img_ids[idx]
img = cv2.imread(os.path.join(self.img_dir, img_id + self.img_ext))
mask = []
for i in range(self.num_classes):
mask.append(cv2.imread(os.path.join(self.mask_dir, str(i),
img_id + self.mask_ext), cv2.IMREAD_GRAYSCALE)[..., None])
mask = np.dstack(mask)
if self.transform is not None:
augmented = self.transform(image=img, mask=mask)#这个包比较方便,能把mask也一并做掉
img = augmented['image']#参考https://github.com/albumentations-team/albumentations
mask = augmented['mask']
img = img.astype('float32') / 255
img = img.transpose(2, 0, 1)
mask = mask.astype('float32') / 255
mask = mask.transpose(2, 0, 1)
return img, mask, {'img_id': img_id}
losses.py
import torch
import torch.nn as nn
import torch.nn.functional as F
try:
from LovaszSoftmax.pytorch.lovasz_losses import lovasz_hinge
except ImportError:
pass
__all__ = ['BCEDiceLoss', 'LovaszHingeLoss']
class BCEDiceLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input, target):
bce = F.binary_cross_entropy_with_logits(input, target)
smooth = 1e-5
input = torch.sigmoid(input)
num = target.size(0)
input = input.view(num, -1)
target = target.view(num, -1)
intersection = (input * target)
dice = (2. * intersection.sum(1) + smooth) / (input.sum(1) + target.sum(1) + smooth)
dice = 1 - dice.sum() / num
return 0.5 * bce + dice
class LovaszHingeLoss(nn.Module):
def __init__(self):
super().__init__()
def forward(self, input, target):
input = input.squeeze(1)
target = target.squeeze(1)
loss = lovasz_hinge(input, target, per_image=True)
return loss
metrics.py 模型效果评价指标
import numpy as np
import torch
import torch.nn.functional as F
def iou_score(output, target):
smooth = 1e-5
if torch.is_tensor(output):
output = torch.sigmoid(output).data.cpu().numpy()
if torch.is_tensor(target):
target = target.data.cpu().numpy()
output_ = output > 0.5
target_ = target > 0.5
intersection = (output_ & target_).sum()
union = (output_ | target_).sum()
return (intersection + smooth) / (union + smooth)
def dice_coef(output, target):
smooth = 1e-5
output = torch.sigmoid(output).view(-1).data.cpu().numpy()
target = target.view(-1).data.cpu().numpy()
intersection = (output * target).sum()
return (2. * intersection + smooth) /
(output.sum() + target.sum() + smooth)
preprocess.py 数据标签的合并处理,将同一张图的多个标签数据合并为一张
import os
from glob import glob
import cv2
import numpy as np
from tqdm import tqdm
def main():
img_size = 96
paths = glob('inputs/stage1_train/*')
os.makedirs('inputs/dsb2018_%d/images' % img_size, exist_ok=True)
os.makedirs('inputs/dsb2018_%d/masks/0' % img_size, exist_ok=True)
for i in tqdm(range(len(paths))):
path = paths[i]
img = cv2.imread(os.path.join(path, 'images',
os.path.basename(path) + '.png'))
mask = np.zeros((img.shape[0], img.shape[1]))
for mask_path in glob(os.path.join(path, 'masks', '*')):
mask_ = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE) > 127
mask[mask_] = 1
if len(img.shape) == 2:
img = np.tile(img[..., None], (1, 1, 3))
if img.shape[2] == 4:
img = img[..., :3]
img = cv2.resize(img, (img_size, img_size))
mask = cv2.resize(mask, (img_size, img_size))
cv2.imwrite(os.path.join('inputs/dsb2018_%d/images' % img_size,
os.path.basename(path) + '.png'), img)
cv2.imwrite(os.path.join('inputs/dsb2018_%d/masks/0' % img_size,
os.path.basename(path) + '.png'), (mask * 255).astype('uint8'))
if __name__ == '__main__':
main()
utils.py 其它设置
import argparse
def str2bool(v):
if v.lower() in ['true', 1]:
return True
elif v.lower() in ['false', 0]:
return False
else:
raise argparse.ArgumentTypeError('Boolean value expected.')
def count_params(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
train.py 模型训练
import argparse
import os
from collections import OrderedDict
from glob import glob
import pandas as pd
import torch
import torch.backends.cudnn as cudnn
import torch.nn as nn
import torch.optim as optim
import yaml
import albumentations as albu
from albumentations.augmentations import transforms
from albumentations.core.composition import Compose, OneOf
from sklearn.model_selection import train_test_split
from torch.optim import lr_scheduler
from tqdm import tqdm
import archs
import losses
from dataset import Dataset
from metrics import iou_score
from utils import AverageMeter, str2bool
ARCH_NAMES = archs.__all__
LOSS_NAMES = losses.__all__
LOSS_NAMES.append('BCEWithLogitsLoss')
"""
指定参数:
--dataset dsb2018_96
--arch NestedUNet
"""
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument('--name', default=None,
help='model name: (default: arch+timestamp)')
parser.add_argument('--epochs', default=100, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('-b', '--batch_size', default=8, type=int,
metavar='N', help='mini-batch size (default: 16)')
# model
parser.add_argument('--arch', '-a', metavar='ARCH', default='NestedUNet',
choices=ARCH_NAMES,
help='model architecture: ' +
' | '.join(ARCH_NAMES) +
' (default: NestedUNet)')
parser.add_argument('--deep_supervision', default=False, type=str2bool)
parser.add_argument('--input_channels', default=3, type=int,
help='input channels')
parser.add_argument('--num_classes', default=1, type=int,
help='number of classes')
parser.add_argument('--input_w', default=96, type=int,
help='image width')
parser.add_argument('--input_h', default=96, type=int,
help='image height')
# loss
parser.add_argument('--loss', default='BCEDiceLoss',
choices=LOSS_NAMES,
help='loss: ' +
' | '.join(LOSS_NAMES) +
' (default: BCEDiceLoss)')
# dataset
parser.add_argument('--dataset', default='dsb2018_96',
help='dataset name')
parser.add_argument('--img_ext', default='.png',
help='image file extension')
parser.add_argument('--mask_ext', default='.png',
help='mask file extension')
# optimizer
parser.add_argument('--optimizer', default='SGD',
choices=['Adam', 'SGD'],
help='loss: ' +
' | '.join(['Adam', 'SGD']) +
' (default: Adam)')
parser.add_argument('--lr', '--learning_rate', default=1e-3, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='momentum')
parser.add_argument('--weight_decay', default=1e-4, type=float,
help='weight decay')
parser.add_argument('--nesterov', default=False, type=str2bool,
help='nesterov')
# scheduler
parser.add_argument('--scheduler', default='CosineAnnealingLR',
choices=['CosineAnnealingLR', 'ReduceLROnPlateau', 'MultiStepLR', 'ConstantLR'])
parser.add_argument('--min_lr', default=1e-5, type=float,
help='minimum learning rate')
parser.add_argument('--factor', default=0.1, type=float)
parser.add_argument('--patience', default=2, type=int)
parser.add_argument('--milestones', default='1,2', type=str)
parser.add_argument('--gamma', default=2/3, type=float)
parser.add_argument('--early_stopping', default=-1, type=int,
metavar='N', help='early stopping (default: -1)')
parser.add_argument('--num_workers', default=0, type=int)
config = parser.parse_args()
return config
def train(config, train_loader, model, criterion, optimizer):
avg_meters = {'loss': AverageMeter(),
'iou': AverageMeter()}
model.train()
pbar = tqdm(total=len(train_loader))
for input, target, _ in train_loader:
input = input.cuda()
target = target.cuda()
# compute output
if config['deep_supervision']:
outputs = model(input)
loss = 0
for output in outputs:
loss += criterion(output, target)
loss /= len(outputs)
iou = iou_score(outputs[-1], target)
else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)
# compute gradient and do optimizing step
optimizer.zero_grad()
loss.backward()
optimizer.step()
avg_meters['loss'].update(loss.item(), input.size(0))
avg_meters['iou'].update(iou, input.size(0))
postfix = OrderedDict([
('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()
return OrderedDict([('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg)])
def validate(config, val_loader, model, criterion):
avg_meters = {'loss': AverageMeter(),
'iou': AverageMeter()}
# switch to evaluate mode
model.eval()
with torch.no_grad():
pbar = tqdm(total=len(val_loader))
for input, target, _ in val_loader:
input = input.cuda()
target = target.cuda()
# compute output
if config['deep_supervision']:
outputs = model(input)
loss = 0
for output in outputs:
loss += criterion(output, target)
loss /= len(outputs)
iou = iou_score(outputs[-1], target)
else:
output = model(input)
loss = criterion(output, target)
iou = iou_score(output, target)
avg_meters['loss'].update(loss.item(), input.size(0))
avg_meters['iou'].update(iou, input.size(0))
postfix = OrderedDict([
('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg),
])
pbar.set_postfix(postfix)
pbar.update(1)
pbar.close()
return OrderedDict([('loss', avg_meters['loss'].avg),
('iou', avg_meters['iou'].avg)])
def main():
config = vars(parse_args())
if config['name'] is None:
if config['deep_supervision']:
config['name'] = '%s_%s_wDS' % (config['dataset'], config['arch'])
else:
config['name'] = '%s_%s_woDS' % (config['dataset'], config['arch'])
os.makedirs('models/%s' % config['name'], exist_ok=True)
print('-' * 20)
for key in config:
print('%s: %s' % (key, config[key]))
print('-' * 20)
with open('models/%s/config.yml' % config['name'], 'w') as f:
yaml.dump(config, f)
# define loss function (criterion)
if config['loss'] == 'BCEWithLogitsLoss':
criterion = nn.BCEWithLogitsLoss().cuda()#WithLogits 就是先将输出结果经过sigmoid再交叉熵
else:
criterion = losses.__dict__[config['loss']]().cuda()
cudnn.benchmark = True
# create model
print("=> creating model %s" % config['arch'])
model = archs.__dict__[config['arch']](config['num_classes'],
config['input_channels'],
config['deep_supervision'])
model = model.cuda()
params = filter(lambda p: p.requires_grad, model.parameters())
if config['optimizer'] == 'Adam':
optimizer = optim.Adam(
params, lr=config['lr'], weight_decay=config['weight_decay'])
elif config['optimizer'] == 'SGD':
optimizer = optim.SGD(params, lr=config['lr'], momentum=config['momentum'],
nesterov=config['nesterov'], weight_decay=config['weight_decay'])
else:
raise NotImplementedError
if config['scheduler'] == 'CosineAnnealingLR':
scheduler = lr_scheduler.CosineAnnealingLR(
optimizer, T_max=config['epochs'], eta_min=config['min_lr'])
elif config['scheduler'] == 'ReduceLROnPlateau':
scheduler = lr_scheduler.ReduceLROnPlateau(optimizer, factor=config['factor'], patience=config['patience'],
verbose=1, min_lr=config['min_lr'])
elif config['scheduler'] == 'MultiStepLR':
scheduler = lr_scheduler.MultiStepLR(optimizer, milestones=[int(e) for e in config['milestones'].split(',')], gamma=config['gamma'])
elif config['scheduler'] == 'ConstantLR':
scheduler = None
else:
raise NotImplementedError
# Data loading code
img_ids = glob(os.path.join('inputs', config['dataset'], 'images', '*' + config['img_ext']))
img_ids = [os.path.splitext(os.path.basename(p))[0] for p in img_ids]
train_img_ids, val_img_ids = train_test_split(img_ids, test_size=0.2, random_state=41)
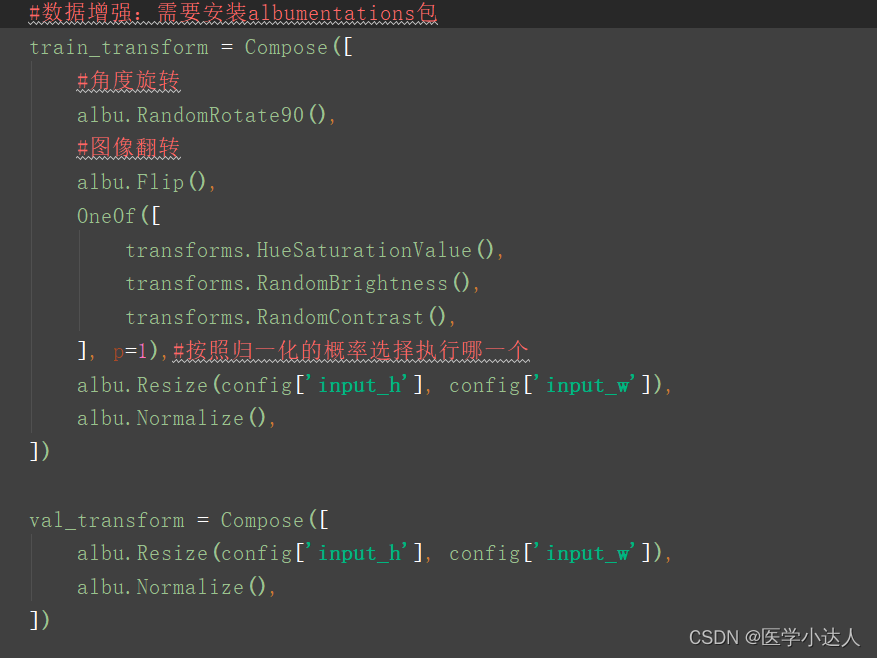
#数据增强:需要安装albumentations包
train_transform = Compose([
#角度旋转
albu.RandomRotate90(),
#图像翻转
albu.Flip(),
OneOf([
transforms.HueSaturationValue(),
transforms.RandomBrightness(),
transforms.RandomContrast(),
], p=1),#按照归一化的概率选择执行哪一个
albu.Resize(config['input_h'], config['input_w']),
albu.Normalize(),
])
val_transform = Compose([
albu.Resize(config['input_h'], config['input_w']),
albu.Normalize(),
])
train_dataset = Dataset(
img_ids=train_img_ids,
img_dir=os.path.join('inputs', config['dataset'], 'images'),
mask_dir=os.path.join('inputs', config['dataset'], 'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=train_transform)
val_dataset = Dataset(
img_ids=val_img_ids,
img_dir=os.path.join('inputs', config['dataset'], 'images'),
mask_dir=os.path.join('inputs', config['dataset'], 'masks'),
img_ext=config['img_ext'],
mask_ext=config['mask_ext'],
num_classes=config['num_classes'],
transform=val_transform)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=config['batch_size'],
shuffle=True,
num_workers=config['num_workers'],
drop_last=True)#不能整除的batch是否就不要了
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=config['batch_size'],
shuffle=False,
num_workers=config['num_workers'],
drop_last=False)
log = OrderedDict([
('epoch', []),
('lr', []),
('loss', []),
('iou', []),
('val_loss', []),
('val_iou', []),
])
best_iou = 0
trigger = 0
for epoch in range(config['epochs']):
print('Epoch [%d/%d]' % (epoch, config['epochs']))
# train for one epoch
train_log = train(config, train_loader, model, criterion, optimizer)
# evaluate on validation set
val_log = validate(config, val_loader, model, criterion)
if config['scheduler'] == 'CosineAnnealingLR':
scheduler.step()
elif config['scheduler'] == 'ReduceLROnPlateau':
scheduler.step(val_log['loss'])
print('loss %.4f - iou %.4f - val_loss %.4f - val_iou %.4f'
% (train_log['loss'], train_log['iou'], val_log['loss'], val_log['iou']))
log['epoch'].append(epoch)
log['lr'].append(config['lr'])
log['loss'].append(train_log['loss'])
log['iou'].append(train_log['iou'])
log['val_loss'].append(val_log['loss'])
log['val_iou'].append(val_log['iou'])
pd.DataFrame(log).to_csv('models/%s/log.csv' %
config['name'], index=False)
trigger += 1
if val_log['iou'] > best_iou:
torch.save(model.state_dict(), 'models/%s/model.pth' %
config['name'])
best_iou = val_log['iou']
print("=> saved best model")
trigger = 0
# early stopping
if config['early_stopping'] >= 0 and trigger >= config['early_stopping']:
print("=> early stopping")
break
torch.cuda.empty_cache()
if __name__ == '__main__':
main()
四,模型结果:


五:注意事项以及常见问题
安装增加模块albumentations,主要为数据增强模块,方便快捷
pip install albumentations常见问题:
AttributeError: module ‘cv2’ has no attribute ‘gapi_wip_gst_GStreamerPipeline’
解决:opencv-python-headless和opencv-python的版本对应即可
pip install opencv-python-headless==4.2.0.32 -i https://pypi.tuna.tsinghua.edu.cn/simple问题2
AttributeError: module ‘albumentations.augmentations.transforms’ has no attribute ‘RandomRotate90’
解决:直接导入import albumentations as albu





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结