您现在的位置是:首页 >其他 >Haar特征和级联分类器目标检测介绍及应用网站首页其他
Haar特征和级联分类器目标检测介绍及应用
Haar特征和级联分类器目标检测介绍及应用
Haar特征和级联分类器是一种经典的目标检测算法,适用于检测物体在图像中的位置、大小和姿态等。本教程将详细介绍Haar特征和级联分类器的原理、实现和应用。
1. Haar特征
Haar特征是一种图像处理中的特征提取方法,用于描述图像中的纹理、边缘和线条等特征。基于Haar小波变换的思想,Haar特征将图像划分成不同大小、不同形状的小矩形区域,对每个区域内的像素进行加权求和得到一个特定的Haar特征值。这些Haar特征值可以作为分类器的输入,例如在人脸识别中就可以用Haar特征检测人脸的位置、大小和方向等信息。
Haar特征经常用在人脸识别中,它可以通过训练一个分类器来检测人脸的各种属性。Haar特征的计算速度相对较快,并且在处理大量数据时表现稳定,使其成为计算机视觉领域中比较受欢迎的特征提取方法之一。
2. 级联分类器
级联分类器(Cascade Classifier)是一种基于Haar特征的对象检测算法,最早由Paul Viola和Michael Jones在2001年的论文中提出。级联分类器主要用于人脸检测,但也可以用于识别其它物体。级联分类器具有高检测精度和快速检测速度的特点。
级联分类器的实现依赖于AdaBoost算法。AdaBoost是一种集成学习方法,可以将多个弱分类器组合成一个强分类器。级联分类器由多个弱分类器组成,每个弱分类器加强一次过滤效果。
级联分类器的检测过程分为多个步骤。首先是图像预处理,将图像转换为灰度图像,然后进行归一化和直方图均衡化。接着,级联分类器将在图像的不同位置和不同大小的窗口中,对每个窗口进行Haar特征的计算。Haar特征是一种计算图像中黑白相间矩形框的差值的方法。计算得到的Haar特征值会被送入AdaBoost分类器进行分类,如果分类器的输出值大于预设的阈值,则认为当前窗口中有目标物体。如果级联分类器中的所有弱分类器都通过了当前窗口的验证,则认为整个级联分类器检测到了目标物体。
级联分类器的训练过程需要大量的正负样本。正样本是指需要检测的目标物体的图片,而负样本是指与目标物体相似但不包含目标物体的图片。在训练过程中,级联分类器会通过不断增加弱分类器的数量和调整阈值,提高检测精度。
基于级联分类器的人脸检测系统由若干级联分类器组成,每个级联分类器的弱分类器数量和阈值都不同。在每个级联分类器中,通过精细调整弱分类器的数量和阈值,使得分类器的检测精度能够达到较高的水平。整个检测系统的优点是快速高效,适合实时应用。
3. 实现步骤
以下是使用OpenCV实现Haar特征和级联分类器目标检测的基本步骤:
- 收集和准备训练数据。需要使用大量的正样本和负样本,其中正样本是包含目标的图像区域,负样本是不包含目标的图像区域。还需要把训练数据集划分为训练集和测试集,并将其分别转换为XML格式。
- 训练级联分类器。可以使用OpenCV提供的trainCascadeClassifier函数进行训练,需要设置许多参数,如Haar特征的类型和数量、正负样本比例、学习率等。训练过程需要一定时间,根据数据集的大小不同可能需要数个小时到数天不等。
- 使用级联分类器进行目标检测。加载训练好的级联分类器XML文件,使用OpenCV提供的detectMultiScale函数对图像进行检测,会返回检测到的目标位置和大小。
4.尝试训练自己的级联分类器
以下是一个基于OpenCV4的级联分类器训练的Python代码示例,你可以参考这个例子来训练你自己的级联分类器。在这个例子中,我们将训练一个可以检测人脸的级联分类器。
首先需要将正负样本从数据集文件夹中读入,我们将正样本命名为"Positive",负样本命名为"Negative",在训练级联分类器时,需要准备一些负样本。正样本是需要构建检测器检测位置的目标。
import cv2
import os
# 设置正负样本文件夹路径
pos_dir = 'Positive/'
neg_dir = 'Negative/'
# 用于存储正样本文件名和路径的列表
pos_files = []
for filename in os.listdir(pos_dir):
if filename.endswith('.jpg'):
pos_files.append(pos_dir + filename)
# 用于存储负样本文件名和路径的列表
neg_files = []
for filename in os.listdir(neg_dir):
if filename.endswith('.jpg'):
neg_files.append(neg_dir + filename)
# 加载正样本的图片
pos_images = []
for file in pos_files:
img = cv2.imread(file, 0) # 将图片转换为灰度图像
pos_images.append(img)
# 加载负样本的图片
neg_images = []
for file in neg_files:
img = cv2.imread(file, 0)
neg_images.append(img)
接下来,我们可以定义训练级联分类器所需的参数。这些参数包括Haar特征的类型和数量、正负样本比例、学习率等。这些参数的设置不仅受到数据集的影响,也需要多次尝试和优化。
# 设置训练参数
num_pos = len(pos_images) # 正样本数量
num_neg = len(neg_images) # 负样本数量
num_features = 200 # 特征数量
pos_weight = float(num_neg) / float(num_pos) # 正负样本比例
num_stages = 20 # 分类器级联层数
min_hit_rate = 0.995 # 分类器的最小检测率
max_false_alarm_rate = 0.5 # 最大假阳率
learning_rate = 0.05 # 学习率
接下来,我们可以使用trainCascadeClassifier函数来训练级联分类器。在训练过程中,模型会不断地调整Haar特征,设定阈值,去除不必要的特征,最终形成具有适应性与推广性的级联分类器。在训练级联分类器时,需要耐心等待,可能需要数小时或更长时间才能训练出一个合适的分类器。
# 训练级联分类器
cascade = cv2.CascadeClassifier()
cascade_params = cv2.CascadeClassifier_TrainParams()
cascade_params.featureParams.maxCatCount = 2
cascade_params.featureParams.maxNumFeatures = num_features
cascade_params.featureParams.minNodeSize = (1,1)
cascade_params.featureParams.maxDepth = 1
cascade_params.boostType = cv2.CASCADE_BOOST_REAL
cascade_params.weightTrimRate = 0.95
cascade_params.minHitRate = min_hit_rate
cascade_params.maxFalseAlarmRate = max_false_alarm_rate
cascade_params.stageType = cv2.CASCADE_STAGE_TYPE_HAAR
cascade_params.classifierType = cv2.CASCADE_CLASSIFIER_TYPE_REAL_HAAR
cascade_params.stages = num_stages
cascade_params.weakCount = 100
cascade_params.completeTrainingSet = False
cascade.train(pos_images, neg_images, None, None, cascade_params)
# 保存级联分类器
cascade.save('face_cascade.xml')
在训练完成后,级联分类器将被保存在当前目录下的face_cascade.xml文件中,可以随时调用它进行人脸检测。
4. 应用示例
Haar特征和级联分类器目标检测算法可以应用于很多领域,如人脸检测、车牌识别、行人检测等。其中,最为著名的应用之一就是OpenCV中的人脸检测,该算法可以实现实时、准确的人脸检测,适用于视频监控、自拍美容等应用场景。以下是使用OpenCV实现人脸检测的代码示例:
# 导入OpenCV库和urllib库
import cv2
import urllib.request
# 设置图像 URL 和文件名
url = 'http://www.lenna.org/lena_std.tif'
filename = 'lena.png'
# 通过网络下载图像,并将其保存到本地
urllib.request.urlretrieve(url, filename)
# 读取图片并转为灰度图
img = cv2.imread('lena.jpg') # 读取图片文件,返回numpy数组
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 将彩色图片转换为灰度图片
# 从GitHub中下载预训练的人脸分类器XML文件
url = 'https://raw.githubusercontent.com/opencv/opencv/master/data/haarcascades/haarcascade_frontalface_default.xml'
filename = 'haarcascade_frontalface_default.xml' # 声明下载的文件名
urllib.request.urlretrieve(url, filename) # 将文件从url下载并保存到本地
# 加载预训练的Haar特征分类器,用于人脸检测
face_cascade = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
# 在灰度图片中检测人脸
# 参数1:待检测图片,参数2:缩放比例因子,参数3:目标大小范围
faces = face_cascade.detectMultiScale(gray, 1.3, 5)
# 在人脸矩形区域绘制矩形
# 参数1:需要绘制矩形的图片,参数2:矩形左上角的坐标,参数3:矩形右下角的坐标,参数4:矩形线条颜色,参数5:矩形线条粗细
for (x, y, w, h) in faces:
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 2)
# 显示图片
# 参数1:需要显示的图片窗口名称,参数2:需要显示的图片
cv2.imshow('image', img)
cv2.waitKey(0) # 等待用户按下任意键以关闭窗口
检测结果如下所示:

这段代码的主要作用是使用OpenCV库实现人脸检测,步骤如下:
- 读取图片文件,使用cv2.imread()函数读取指定路径下的图片,返回一个numpy数组表示该图片;
- 将彩色图片转换为灰度图片,使用cv2.cvtColor()函数将读取出来的彩色图片转换为灰度图;
- 下载预训练的人脸分类器XML文件,使用urllib.request.urlretrieve()函数从GitHub上下载XML文件,保存到本地;
- 加载预训练的Haar特征分类器,使用cv2.CascadeClassifier()函数加载XML文件,得到一个分类器对象;
- 在灰度图片中检测人脸,使用CascadeClassifier.detectMultiScale()方法对灰度图片进行人脸检测,返回检测到的人脸位置;
- 在检测到的人脸上绘制矩形,使用cv2.rectangle()函数在原图片上绘制矩形框,标出人脸位置;
- 显示人脸检测结果图片,使用cv2.imshow()函数将图片显示在窗口中,最后使用cv2.waitKey()函数等待用户按下任意键,关闭窗口。
为了使用Python展示Haar检测中的积分操作,我们可以使用OpenCV库中的cv2.integral函数来计算输入图像的积分图。以下是一个示例代码,演示如何生成积分图并将其可视化显示:
# 导入必要的库
import cv2
import numpy as np
from matplotlib import pyplot as plt
import urllib.request
# 设置图像 URL 和文件名
url = 'http://www.lenna.org/lena_std.tif'
filename = 'lena.png'
# 通过网络下载图像,并将其保存到本地
urllib.request.urlretrieve(url, filename)
# 读取图像并转换为灰度图像
img = cv2.imread('lena.png') # 加载图像
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换为灰度图像
# 计算积分图
integral_img = cv2.integral(gray) # 计算积分图
# 显示原始图像和对应的积分图
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(8, 4)) # 创建子图
ax1.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) # 显示原始图像
ax1.set_title('Original Image') # 设置图像标题
ax2.imshow(integral_img, cmap='gray') # 显示积分图
ax2.set_title('Integral Image') # 设置积分图标题
plt.show() # 输出图像
代码运行结果如下所示:
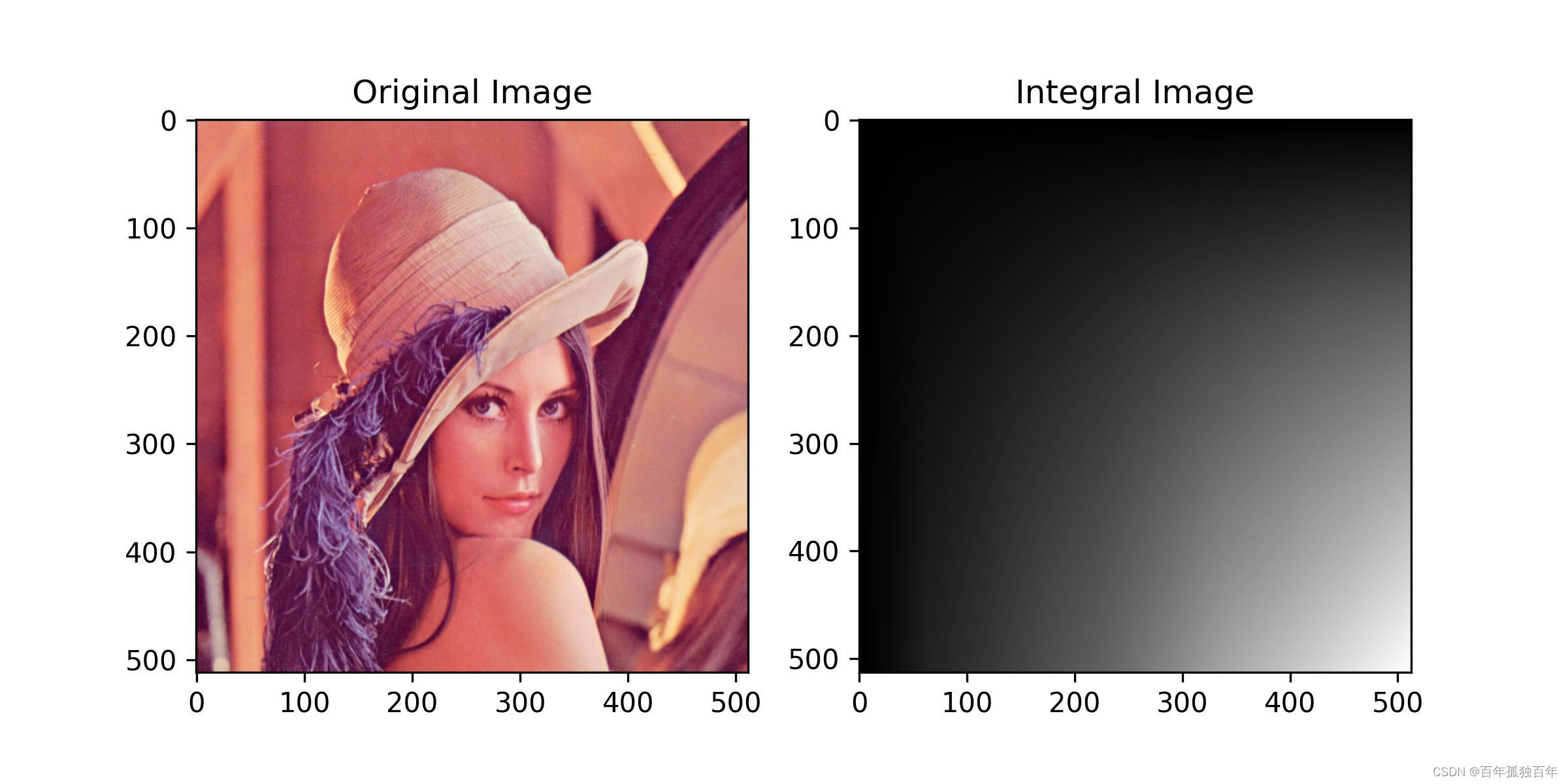
代码通过网络下载一个名为 lena.png 的图像文件,并计算了它的积分图。积分图是一种预处理方法,用于在图像中快速计算子矩形区域的和。
首先,通过导入必要的库:cv2,numpy、和 matplotlib 来让这份代码能够正常运行。并且通过 urllib 模块,通过给定的图像 URL 下载图像并存储在名为 lena.png 的本地文件中。
然后,使用 cv2.imread 函数读入图像,并使用 cv2.cvtColor 函数将其转换为灰度图像,为计算积分图做准备。
接下来,使用 cv2.integral 函数计算灰度图像的积分图,并存储在 integral_img 变量中。
最后,使用 Matplotlib 中的 subplots 函数创建一个包含两个子图的窗口,其中左侧显示原始图像,右侧显示计算得到的积分图像。在显示积分图时,使用 cmap='gray' 参数将其显示为灰度图像。设置标题后,最后显示窗口中的两个图像。
在这个示例中,我们首先读取了一张图像,并将其转换为灰度图像。接着,我们使用cv2.integral函数计算输入图像的积分图。积分图的大小与原始图像相同,并且每个像素都表示原始图像中该位置及其左上角的所有像素值的总和。最后,我们使用Matplotlib库将原始图像和积分图在一起可视化显示出来。可以看到,积分图中每个位置的值都代表了原始图像中对应位置及其左上角区域的像素值的总和。
值得注意的是,在Haar特征计算中,积分图有助于快速计算位于任意矩形区域内的像素值之和,从而避免了对该区域内的每个像素进行逐一计算。这可以使Haar特征的计算速度更快。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结