您现在的位置是:首页 >技术交流 >深入篇【C++】类与对象:构造函数+析构函数网站首页技术交流
深入篇【C++】类与对象:构造函数+析构函数
深入篇【C++】类与对象:构造函数+析构函数

①.构造函数
如果一个类中什么成员都没有,简称为空类。
而空类并不是什么都没有,当类中什么都不写时,编译器会自动生成以下6个默认成员函数。
默认成员函数:用户没有显示的写出来,编译器会自动生成的成员函数称为默认成员函数。
主要有构造函数,析构函数,拷贝函数等。
本篇主要总结构造函数和析构函数
Ⅰ.概念
构造函数是一个特殊的成员函数,名字和类名相同,创建类类型行对象时由编译器自动调用,来保证每个数据成员都有一个合适的初始值,并且在对象整个生命周期只调用一次。
比如下面这个栈:
typedef int DataType;
struct stack//class可以定义一个类
{
public://访问限定符
void Init()
{
_array = (DataType*)malloc(sizeof(DataType) * 3);
if (_array == NULL)
{
perror("malloc");
}
_capacity = 3;
_size = 0;
}
void Push(DataType data)
{
CheckCapacity();
_array[_size] = data;
_size++;
}
void Pop()
{
if (Empty())
{
return;
}
--_size;
}
DataType Top()
{
return _array[_size - 1];
}
int Empty()
{
return _size == 0;
}
int Size()
{
return _size;
}
void Destroy()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private://访问限定符
void CheckCapacity()
{
if (_size == _capacity)
{
int newcapacity = _capacity * 2;
DataType* temp =(DataType*)realloc(_array, sizeof(DataType) * newcapacity);
if (temp == NULL)
{
perror("realloc");
}
_array = temp;
_capacity = newcapacity;
}
}
private://访问限定符
DataType* _array;
int _capacity;
int _size;
};
int main()
{
stack s;//定义一个对象
s.Init();
s.Push(1);
s.Push(2);
s.Push(3);
s.Push(4);
s.Push(5);
printf("%d
", s.Top());
printf("%d
", s.Size());
s.Pop();
s.Pop();
printf("%d", s.Top());
s.Destroy();
return 0;
}
对于这个栈,我们如果想要使用它的话,必须要先初始化它,才可以使用,不然会报错。
比如不初始化它结果:程序是卡死的。
但如果每次创建对象时都要调用初始化函数,来初始信息,未免有点复杂,那能否在对象创建的时候就将信息设置进去呢?
【现在遇到的问题】:
1.可能经常会忘记写初始化和销毁。
2.而且有些地方写起来很繁琐,令人脑大很大。
C++给出的解决方法:构造函数
Ⅱ.特性
构造函数是特殊的成员函数,需要注意的是,构造函数虽然名称叫构造,但是构造函数的主要任务并不是开空间创建对象,而是初始化对象。
特性如下:
1.函数名和类型相同。
当类名为A时,那么构造函数的名字也为A
2.无返回值,也不用写void。
构造函数无返回值,不需要写任何东西。
3.自动调用对应的构造函数。
在对象实例化时,编译器会自动调用对应的构造函数。
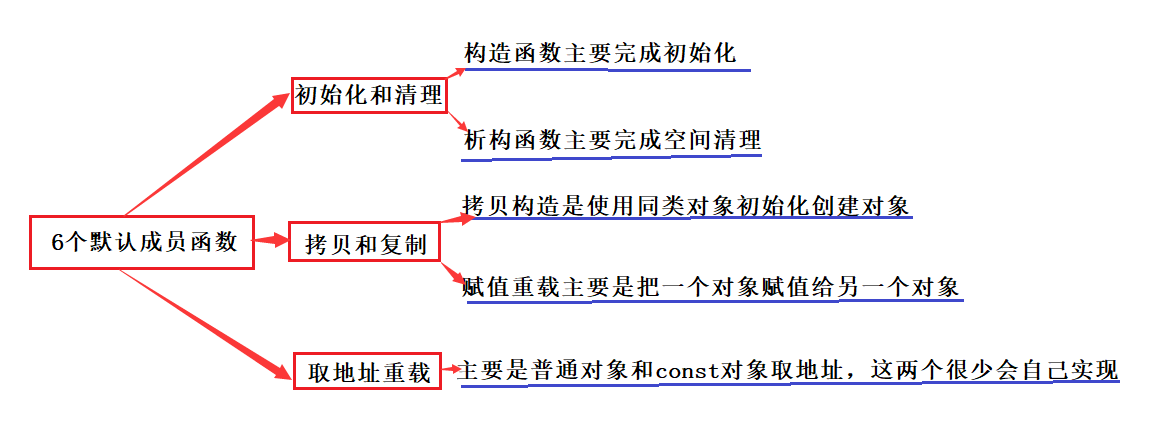
比如下面这个栈,当定义一个对象时就可以不用再调用初始化函数了。并且初始化函数Init函数就不用再存在了。
因为只要用户写了构造函数后,当对象实例化时,编译器会自动调用对应的构造函数stack(int capacity=4);
typedef int DataType;
struct stack//class可以定义一个类
{
public://访问限定符
//构造函数---在对象实例化时自动调用
stack(int capacity=4)//缺省值
{
cout << "stack(int capacipty=4)" << endl;
_array = (DataType*)malloc(sizeof(DataType) * capacity);
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
CheckCapacity();
_array[_size] = data;
_size++;
}
void Pop()
{
if (Empty())
{
return;
}
--_size;
}
void Destroy()
{
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private://访问限定符
void CheckCapacity()
{
if (_size == _capacity)
{
int newcapacity = _capacity * 2;
DataType* temp =(DataType*)realloc(_array, sizeof(DataType) * newcapacity);
if (temp == NULL)
{
perror("realloc");
}
_array = temp;
_capacity = newcapacity;
}
}
private://访问限定符
DataType* _array;
int _capacity;
int _size;
};
int main()
{
stack s;//定义一个对象
//不需要再调用初始化函数了,因为当对象实例化时,编译器会自动调用对应的构造函数stack
s.Push(1);
s.Push(2);
s.Push(3);
s.Push(4);
s.Push(5);
printf("%d
", s.Top());
printf("%d
", s.Size());
s.Pop();
s.Pop();
printf("%d", s.Top());
s.Destroy();
return 0;
}
用户没有调用,最后照样可以使用。
4.构造函数可重载
为什么?—因为可能有多种初始化方式
class Data
{
public:
//构造函数1--带参
Data(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
//构造函数2--无参
Data()
{
cout<<"xiao tao"<<endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Data d1;//对象实例化自动调用,但是调用的是无参的构造函数
Data d2(2023,5,1);//对象实例化自动调用,调用的是带参的构造函数。
}
要注意,如果通过无参构造函数创建对象时,对象后面不用跟括号,否则就跟函数声明一样了,编译器无法识别这是创建对象还是函数声明呢。
比如这样是错误的:
Data d1(void);//构造函数虽然无参,但对应的对象后面不要带括号!
5.编译器的无参构造
如果类中没有显示的定义构造函数,也就是用户没有写构造函数,则C++编译器会自动生成一个无参的默认构造函数,一旦用户显示的定义了(也就是用户自己写了构造函数),则编译器不再生成。
第一种:用户自己写了构造函数,则编译器不会再生成。
class Data
{
public:
//构造函数1--带参
Data(int year, int month, int day)
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Data d2(2023,5,1);//对象实例化自动调用,调用的是带参的构造函数。
//上面的代码是可以通过编译,因为编译器生成了一个无参的默认构造函数。
//但是下面这个代码就不可以通过了,因为一旦显示定义了任何构造函数,编译器就不再生成构造函数了。
Data d1;//编译器会自动调用对应的构造函数,它对应的构造函数应该是无参构造函数,但是现在用户显示定义的构造函数是带有三个参数的构造函数,所有编译会失败的。
}
它会说没有合适的构造函数可以用。
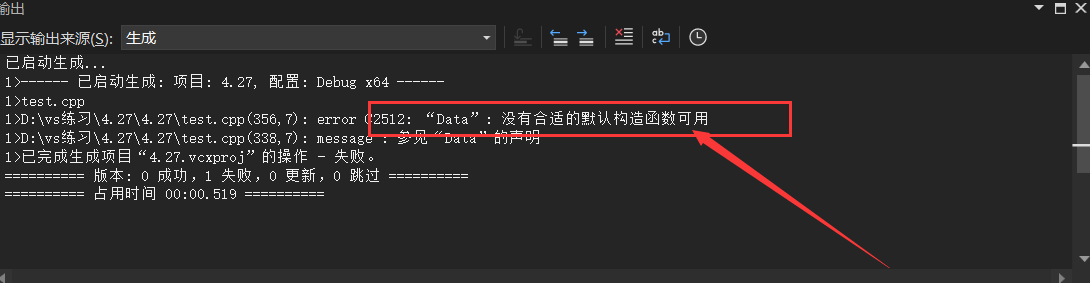
第二种:用户没有写构造函数,编译器将自己生成一个无参的构造函数。
class Data
{
public:
//用户没有写构造函数,那么编译器将自动生成一个无参
//的构造函数,当对象实例化时,编译器再自动调用这个无参的构造函数,让对象初始化。
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Data d2;//对象实例化自动调用。,调用的是编译器生成的构造函数。
d2.Print();
}
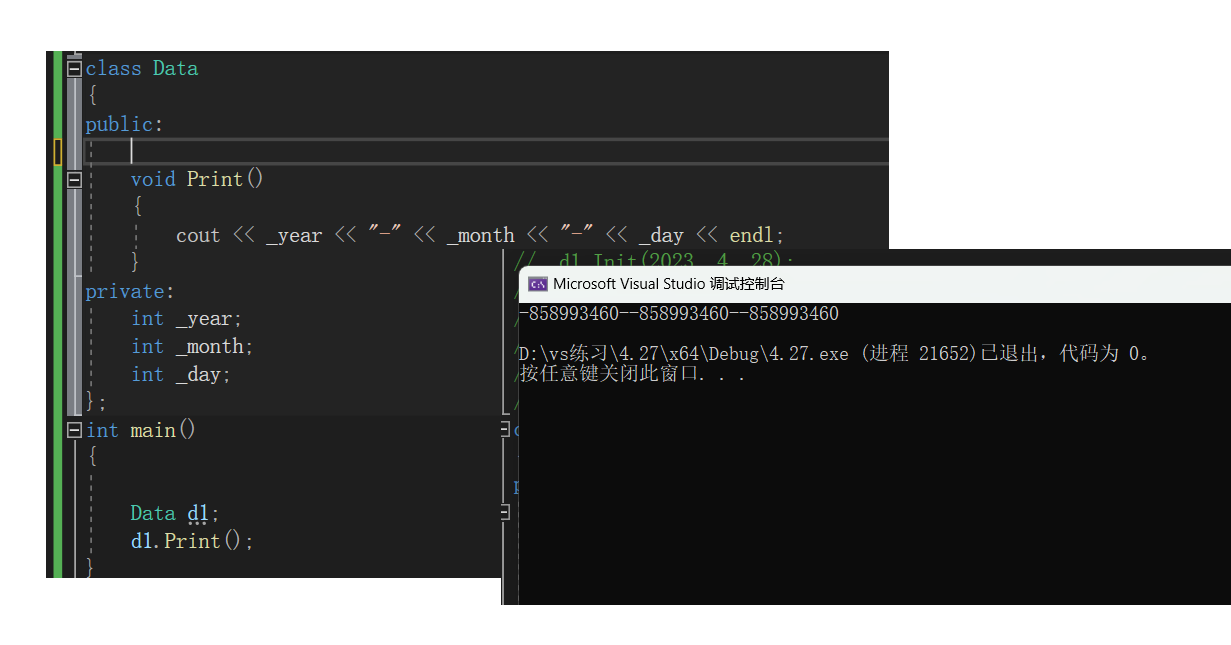
我们可以来看下编译器生成的构造函数对成员变量到底初始化没。调用Print函数打印看下:
6.编译器的无参构造特性
关于编译器生成的默认成员函数,很多人会有疑惑:用户不定义构造函数的情况下,编译器会自动生成一个默认的构造函数。但是看起来好像这个构造函数没有什么用样,d对象实例化时编译器自动调用编译器生成的默认构造函数,但是d对象的三个成员变量还是随机值呀。难道说编译器生成的默认成员函数真的没有用吗?
下面应该严格初始化为0.
其实并不是。
C++将类型分成内置类型和自定义类型,内置类型就是语言自己提供的数据类型如int,char double 指针*类型的都是内置类型。
自定义类型就是我们使用class/struct/union等自己定义的类型。
而C++编译器生成的默认成员函数对这两种类型的初始化处理是不同的。这也就造成有时看起来编译器生成默认成员函数没有用,因为它对不同的类型处理不同。
C++编译器生成的默认成员函数对内置类型的成员变量是不做初始化处理。
对自定义类型的成员变量做初始化处理。
也就是,我们如果不写构造函数,编译器会生成默认构造函数,内置类型不做处理,自定义类型会去调用他的默认构造函数。
class Data
{
public:
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
//内置类型
int _year;
int _month;
int _day;
//自定义类型
stack _st;
};
int main()
{
Data d1;
d1.Print();
}
都没有写构造函数,编译器将自动生成构造函数。
我们来看看编译器生成的默认构造函数对内置类型和自定义类型分别做了什么处理。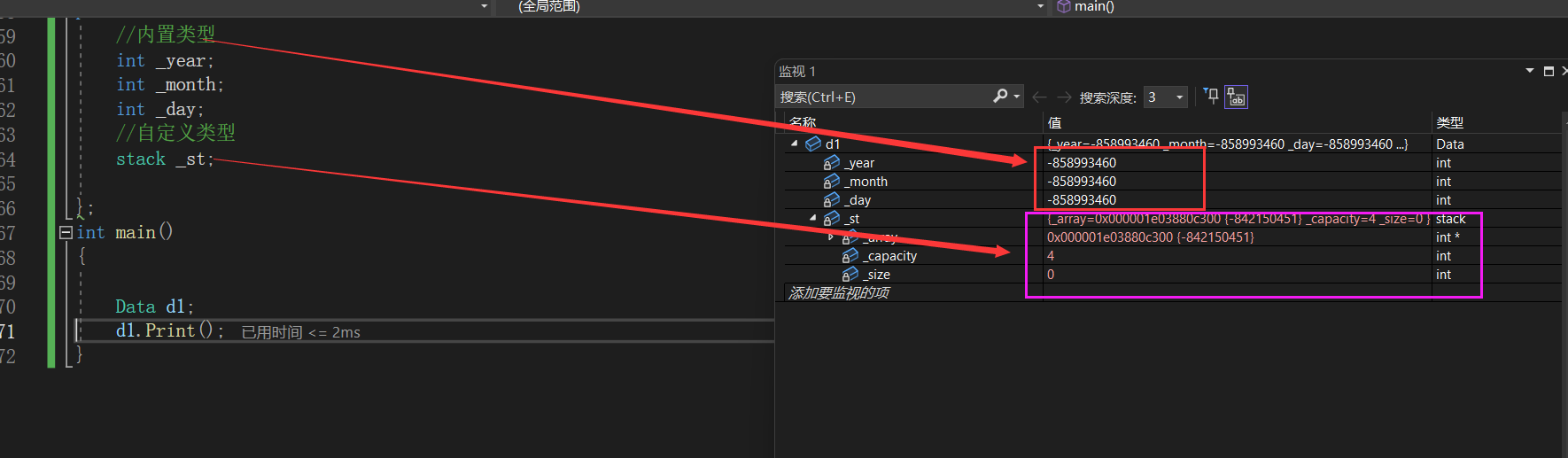
总结一下:
1.一般情况下,有内置类型成员,就需要自己写构造函数了,不能用编译器自己生成的。
2.全部都是自定义类型成员,就可以考虑让编译器自己生成。
比如说:【用栈实现队列】
就不用写构造函数了,因为默认构造函数会完成两个栈对象的初始化。
7.声明时可缺省
其实应该让默认成员函数都一视同仁,不要搞什么类型歧视啥的,不管内置类型还是自定义类型都给他初始化多好,但是规则就摆在哪里,我们这些使用者必须遵守,但又难受的一批。你要初始化就都初始化,初始一部分是啥意思。
所以C++中针对内置类型成员不初始化的缺陷,又打了补丁。
即:允许内置类型成员变量在类中声明时可以给缺省值。
class Data
{
public:
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
//内置类型
//C++对内置类型不初始化的缺陷,打了补丁
//在类中声明变量时可以给缺省值
//这里给的是默认的缺省值,给编译器默认生成的构造函数用的
int _year=1;//注意:这时成员变量的声明不是定义
int _month=1;//给缺省值即默认值
int _day=1;
//自定义类型
stack _st;
};
int main()
{
Data d1;
d1.Print();
}
注意:这时成员变量的声明不是定义。
这里给的是默认的缺省值,给编译器默认生成的构造函数用的。
当显示的初始化对象了,缺省值就没有用。(写了构造函数)
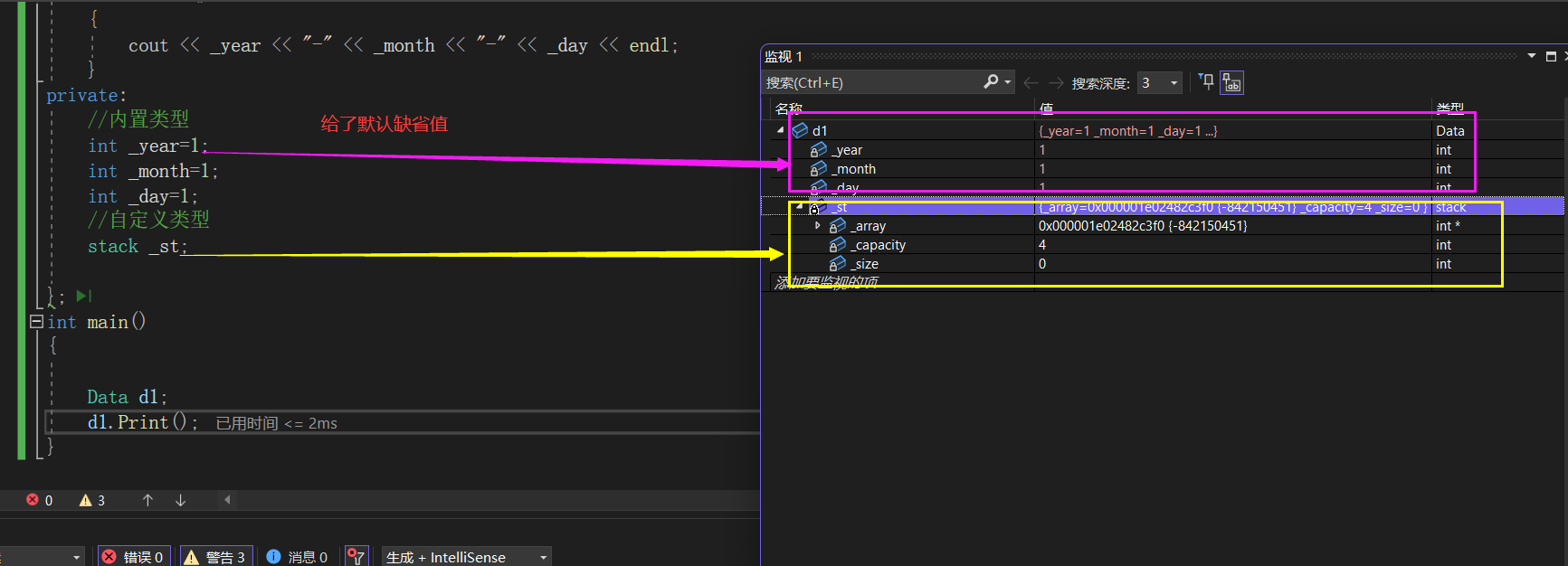
这里再总结一下:
1.一般情况下都需要写构造函数的。
2.下面这两种情况可以不写构造函数
a.有内置类型,但给了缺省值,并且缺省值符合初始化要求。
b.全是自定义类型,不需要自己写。
8.构造函数的调用
构造函数的调用很特殊。
class Data
{
public:
//构造函数1--无参
Data()
{
}
//两个函数构成重载
Data(int year, int month, int day)//构造函数2--带参
{
_year = year;
_month = month;
_day = day;
}
void Print()
{
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
//内置类型
int _year=1;
int _month=1;
int _day=1;
//自定义类型
stack _st;
};
int main()
{
Data d1;//会自动调用无参构造函数
Data d2(2023,5,1);//会自动调用有参构造函数
d1.Print();
d2.Print();
d1.Print();
}
注意这个个构造函数的调用与下面正常函数的调用有何区别?
正常函数调用都是函数+参数列表
而构造函数的调用是 对象 /对象+成员列表
是不是很奇怪,而且更奇怪的是,当调用无参构造函数时,你只能写对象,对象后面不能带括号,也就是成员列表,即使是空的,也不能写。比如这样:Data d3();
因为这样写会和函数声明有些冲突。编译器无法识别这是对象调用构造函数呢?还是函数声明呢?
9.默认构造函数
我们知道在函数传参时,可以给缺省值,缺省值又有全缺省和半缺省,所以这里面我们给构造函数全缺省或者半缺省是不是很舒服呀。当对象调用构造函数的时候可以给不给参数,也可以给一个参数,也可以给两个参数,也可以给三个参数。就存在多种调用方式,可以满足多样需求。
Data()//无参--构造函数
{
}
//两个函数构成重载
Data(int year=1, int month=1, int day=1)//构造函数2--带参--全缺省
{
_year = year;
_month = month;
_day = day;
}
那上面这两个构造函数是不是构成重载函数了。对吧
但是当调用的时候就存在不合理的地方:无参调用存在歧义。
当无参调用构造函数,那编译器会选择哪个构造函数呢?这两个构造函数都可以呀,所以就造成歧义,编译器无法判断使用哪个构造函数,所以这两种形式不能同时存在。
1.函数构成重载
2.但无参调用存在歧义
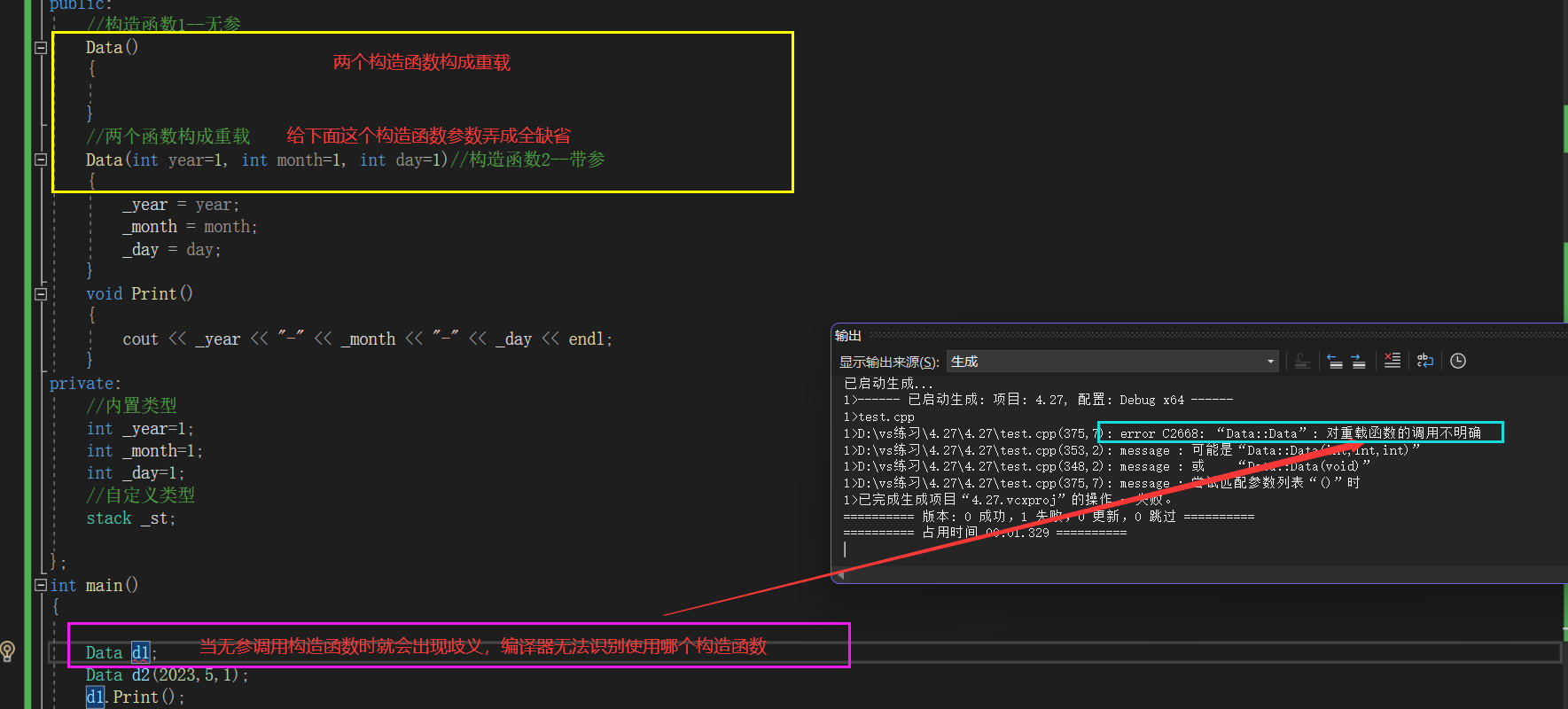
无参的构造函数和全缺省的构造函数都称为默认构造函数,并且默认构造函数只能有一个。
即不传参就可以调用的就是默认构造函数。
注意:无参构造函数,全缺省构造函数,我们没有写编译器自己生成的构造函数,都可以认为是默认构造函数。这三种只能存在一种。
②.析构函数
Ⅰ.概念
析构函数:与析构函数功能相反,析构函数不是完成对对象本身的销毁,局部变量的销毁工作是由编译器自动完成的,对象在销毁时会自动调用析构函数,完成对象种资源的清理工作。
Ⅱ.特性
特征如下:
1.类名前+符号~。
析构函数是在类名前加上符号~。
比如类名是A
则它的析构函数则是这样写: ~A()
2.无参数也无返回值。
3.析构无重载
一个类只能有一个析构函数,因为无参数,所以无法构成重载函数
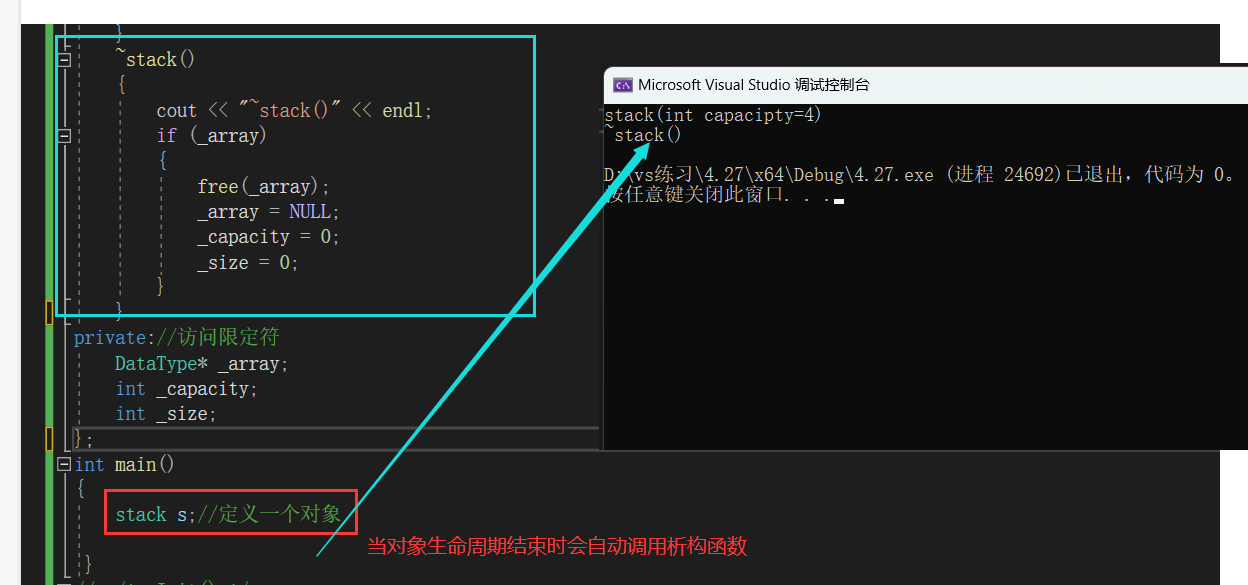
4.自动调用对应的析构函数
当对象声明周期结束时,编译器会自动调用析构函数。
typedef int DataType;
struct stack//class可以定义一个类
{
public://访问限定符
//构造函数---在对象实例化时自动调用
stack(int capacity=4)//缺省值
{
cout << "stack(int capacipty=4)" << endl;
_array = (DataType*)malloc(sizeof(DataType) * capacity);
_capacity = capacity;
_size = 0;
}
void Push(DataType data)
{
CheckCapacity();
_array[_size] = data;
_size++;
}
void Pop()
{
if (Empty())
{
return;
}
--_size;
}
DataType Top()
{
return _array[_size - 1];
}
int Empty()
{
return _size == 0;
}
int Size()
{
return _size;
}
~stack()//析构函数--在对象生命周期结束时,编译器会自动调用析构函数
{
cout << "~stack()" << endl;
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private://访问限定符
void CheckCapacity()
{
if (_size == _capacity)
{
int newcapacity = _capacity * 2;
DataType* temp =(DataType*)realloc(_array, sizeof(DataType) * newcapacity);
if (temp == NULL)
{
perror("realloc");
}
_array = temp;
_capacity = newcapacity;
}
}
private://访问限定符
DataType* _array;
int _capacity;
int _size;
};
析构函数和构造函数都是由编译器自动调用的。比如定义一个对象时,当对象生命周期结束时,编译器会自动调用析构函数。
int main()
{
stack s;//定义一个对象
//当对象生命周期结束时会自动调用析构函数
return 0;
}
5.编译器的析构特性
当用户自己不写析构函数,则编译器会自动生成默认析构函数。那编译器自动生成的析构函数会做什么呢?
跟构造函数类似。析构函数不会对内置类型清理,只对自定义类型清理。
1.对内置类型不去处理。
2.自定义类型会去调用它的析构函数
注意:这里清理的都是动态开辟的,在栈上开辟的静态空间不需要我们手动销毁,全局变量,和静态变量在程序结束后就自动销毁了所以不需要管他们,只需要清理在堆上动态开辟的资源即可。
所以说我们如果不自己写析构函数的话,让编译器生成的析构函数处理,很有可以会造成内存泄漏,因为它不对内置类型清理空间。
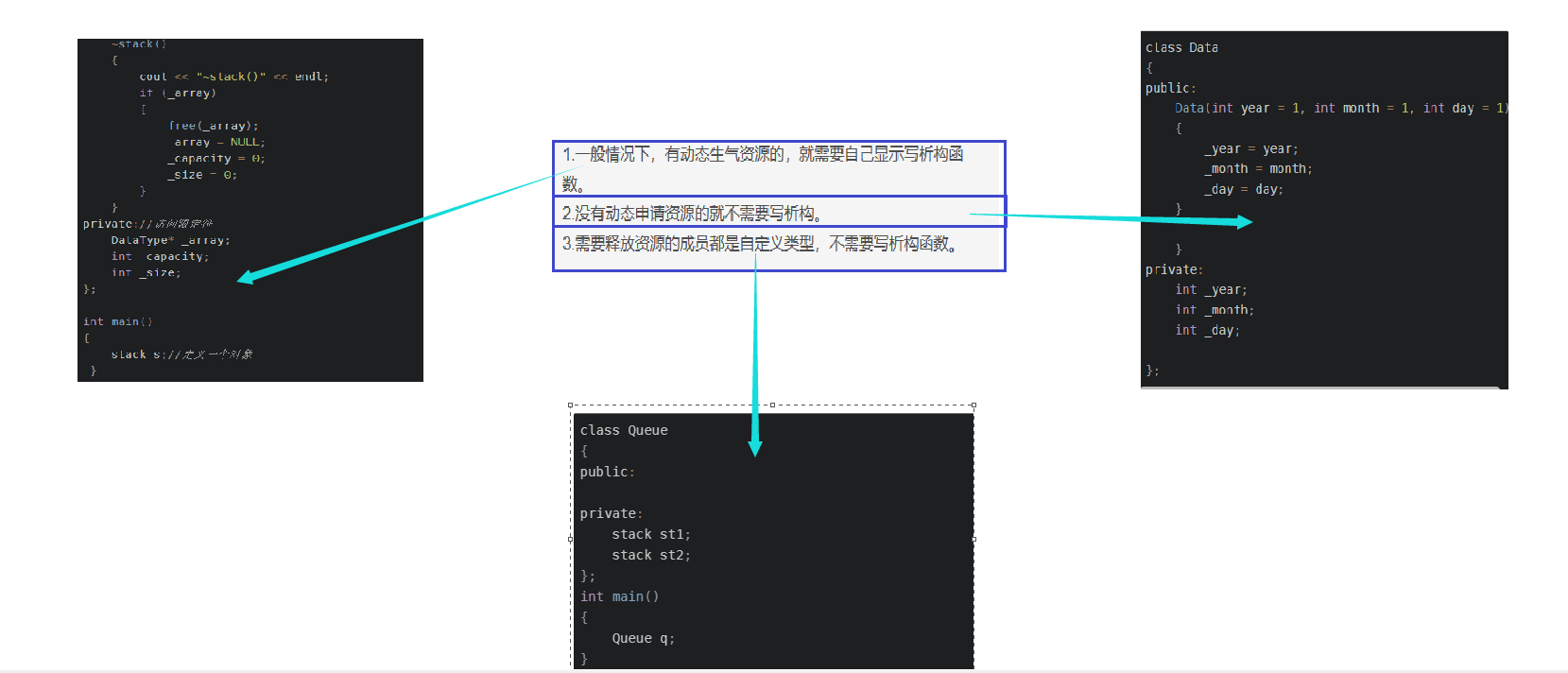
所以总结一下什么情况下需要写析构函数,什么情况下不需要写析构。
- 1.一般情况下,有动态生气资源的,就需要自己显示写析构函数。
- 2.没有动态申请资源的就不需要写析构。
- 3.需要释放资源的成员都是自定义类型,不需要写析构函数。
第一种情况:有动态资源,需要自己写的
typedef int DataType;
struct stack//class可以定义一个类
{
public://访问限定符
stack(int capacity=4)//缺省值
{
cout << "stack(int capacipty=4)" << endl;
_array = (DataType*)malloc(sizeof(DataType) * capacity);
_capacity = capacity;
_size = 0;
}
~stack()
{
cout << "~stack()" << endl;
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
private://访问限定符
DataType* _array;
int _capacity;
int _size;
};
int main()
{
stack s;//定义一个对象
}

第二种情况:没有动态资源,不要自己写。
class Data
{
public:
Data(int year = 1, int month = 1, int day = 1)
{
_year = year;
_month = month;
_day = day;
}
}
private:
int _year;
int _month;
int _day;
};
第三种情况:需要释放资源的成员全是自定义类型,不需要自己写。
class Queue
{
public:
private:
stack st1;
stack st2;
};
int main()
{
Queue q;
}





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结