您现在的位置是:首页 >学无止境 >2023五一数学建模思路 - 案例:随机森林网站首页学无止境
2023五一数学建模思路 - 案例:随机森林
简介2023五一数学建模思路 - 案例:随机森林
## 0 赛题思路
(赛题出来以后第一时间在CSDN分享)
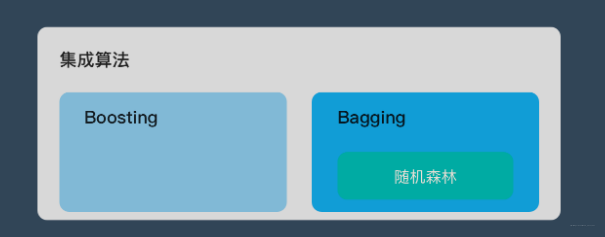
1 什么是随机森林?
随机森林属于 集成学习 中的 Bagging(Bootstrap AGgregation 的简称) 方法。如果用图来表示他们之间的关系如下:
决策树 – Decision Tree
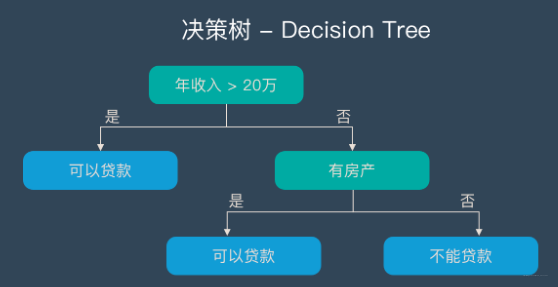
在解释随机森林前,需要先提一下决策树。决策树是一种很简单的算法,他的解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法,上面的图片可以直观的表达决策树的逻辑。
随机森林 – Random Forest | RF
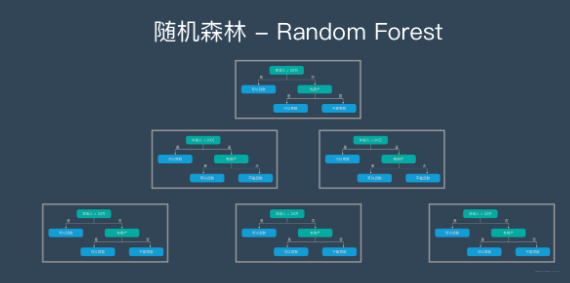
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
2 随机深林构造流程

-
- 一个样本容量为N的样本,有放回的抽取N次,每次抽取1个,最终形成了N个样本。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
-
- 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
-
- 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
-
- 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
3 随机森林的优缺点
3.1 优点
- 它可以出来很高维度(特征很多)的数据,并且不用降维,无需做特征选择
- 它可以判断特征的重要程度
- 可以判断出不同特征之间的相互影响
- 不容易过拟合
- 训练速度比较快,容易做成并行方法
- 实现起来比较简单
- 对于不平衡的数据集来说,它可以平衡误差。
- 如果有很大一部分的特征遗失,仍可以维持准确度。
3.2 缺点
- 随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合。
- 对于有不同取值的属性的数据,取值划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的
4 随机深林算法实现
数据集:https://archive.ics.uci.edu/ml/machine-learning-databases/undocumented/connectionist-bench/sonar/
import csv
from random import seed
from random import randrange
from math import sqrt
def loadCSV(filename):#加载数据,一行行的存入列表
dataSet = []
with open(filename, 'r') as file:
csvReader = csv.reader(file)
for line in csvReader:
dataSet.append(line)
return dataSet
# 除了标签列,其他列都转换为float类型
def column_to_float(dataSet):
featLen = len(dataSet[0]) - 1
for data in dataSet:
for column in range(featLen):
data[column] = float(data[column].strip())
# 将数据集随机分成N块,方便交叉验证,其中一块是测试集,其他四块是训练集
def spiltDataSet(dataSet, n_folds):
fold_size = int(len(dataSet) / n_folds)
dataSet_copy = list(dataSet)
dataSet_spilt = []
for i in range(n_folds):
fold = []
while len(fold) < fold_size: # 这里不能用if,if只是在第一次判断时起作用,while执行循环,直到条件不成立
index = randrange(len(dataSet_copy))
fold.append(dataSet_copy.pop(index)) # pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
dataSet_spilt.append(fold)
return dataSet_spilt
# 构造数据子集
def get_subsample(dataSet, ratio):
subdataSet = []
lenSubdata = round(len(dataSet) * ratio)#返回浮点数
while len(subdataSet) < lenSubdata:
index = randrange(len(dataSet) - 1)
subdataSet.append(dataSet[index])
# print len(subdataSet)
return subdataSet
# 分割数据集
def data_spilt(dataSet, index, value):
left = []
right = []
for row in dataSet:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 计算分割代价
def spilt_loss(left, right, class_values):
loss = 0.0
for class_value in class_values:
left_size = len(left)
if left_size != 0: # 防止除数为零
prop = [row[-1] for row in left].count(class_value) / float(left_size)
loss += (prop * (1.0 - prop))
right_size = len(right)
if right_size != 0:
prop = [row[-1] for row in right].count(class_value) / float(right_size)
loss += (prop * (1.0 - prop))
return loss
# 选取任意的n个特征,在这n个特征中,选取分割时的最优特征
def get_best_spilt(dataSet, n_features):
features = []
class_values = list(set(row[-1] for row in dataSet))
b_index, b_value, b_loss, b_left, b_right = 999, 999, 999, None, None
while len(features) < n_features:
index = randrange(len(dataSet[0]) - 1)
if index not in features:
features.append(index)
# print 'features:',features
for index in features:#找到列的最适合做节点的索引,(损失最小)
for row in dataSet:
left, right = data_spilt(dataSet, index, row[index])#以它为节点的,左右分支
loss = spilt_loss(left, right, class_values)
if loss < b_loss:#寻找最小分割代价
b_index, b_value, b_loss, b_left, b_right = index, row[index], loss, left, right
# print b_loss
# print type(b_index)
return {'index': b_index, 'value': b_value, 'left': b_left, 'right': b_right}
# 决定输出标签
def decide_label(data):
output = [row[-1] for row in data]
return max(set(output), key=output.count)
# 子分割,不断地构建叶节点的过程对对对
def sub_spilt(root, n_features, max_depth, min_size, depth):
left = root['left']
# print left
right = root['right']
del (root['left'])
del (root['right'])
# print depth
if not left or not right:
root['left'] = root['right'] = decide_label(left + right)
# print 'testing'
return
if depth > max_depth:
root['left'] = decide_label(left)
root['right'] = decide_label(right)
return
if len(left) < min_size:
root['left'] = decide_label(left)
else:
root['left'] = get_best_spilt(left, n_features)
# print 'testing_left'
sub_spilt(root['left'], n_features, max_depth, min_size, depth + 1)
if len(right) < min_size:
root['right'] = decide_label(right)
else:
root['right'] = get_best_spilt(right, n_features)
# print 'testing_right'
sub_spilt(root['right'], n_features, max_depth, min_size, depth + 1)
# 构造决策树
def build_tree(dataSet, n_features, max_depth, min_size):
root = get_best_spilt(dataSet, n_features)
sub_spilt(root, n_features, max_depth, min_size, 1)
return root
# 预测测试集结果
def predict(tree, row):
predictions = []
if row[tree['index']] < tree['value']:
if isinstance(tree['left'], dict):
return predict(tree['left'], row)
else:
return tree['left']
else:
if isinstance(tree['right'], dict):
return predict(tree['right'], row)
else:
return tree['right']
# predictions=set(predictions)
def bagging_predict(trees, row):
predictions = [predict(tree, row) for tree in trees]
return max(set(predictions), key=predictions.count)
# 创建随机森林
def random_forest(train, test, ratio, n_feature, max_depth, min_size, n_trees):
trees = []
for i in range(n_trees):
train = get_subsample(train, ratio)#从切割的数据集中选取子集
tree = build_tree(train, n_features, max_depth, min_size)
# print 'tree %d: '%i,tree
trees.append(tree)
# predict_values = [predict(trees,row) for row in test]
predict_values = [bagging_predict(trees, row) for row in test]
return predict_values
# 计算准确率
def accuracy(predict_values, actual):
correct = 0
for i in range(len(actual)):
if actual[i] == predict_values[i]:
correct += 1
return correct / float(len(actual))
if __name__ == '__main__':
seed(1)
dataSet = loadCSV('sonar-all-data.csv')
column_to_float(dataSet)#dataSet
n_folds = 5
max_depth = 15
min_size = 1
ratio = 1.0
# n_features=sqrt(len(dataSet)-1)
n_features = 15
n_trees = 10
folds = spiltDataSet(dataSet, n_folds)#先是切割数据集
scores = []
for fold in folds:
train_set = folds[
:] # 此处不能简单地用train_set=folds,这样用属于引用,那么当train_set的值改变的时候,folds的值也会改变,所以要用复制的形式。(L[:])能够复制序列,D.copy() 能够复制字典,list能够生成拷贝 list(L)
train_set.remove(fold)#选好训练集
# print len(folds)
train_set = sum(train_set, []) # 将多个fold列表组合成一个train_set列表
# print len(train_set)
test_set = []
for row in fold:
row_copy = list(row)
row_copy[-1] = None
test_set.append(row_copy)
# for row in test_set:
# print row[-1]
actual = [row[-1] for row in fold]
predict_values = random_forest(train_set, test_set, ratio, n_features, max_depth, min_size, n_trees)
accur = accuracy(predict_values, actual)
scores.append(accur)
print ('Trees is %d' % n_trees)
print ('scores:%s' % scores)
print ('mean score:%s' % (sum(scores) / float(len(scores))))
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结