您现在的位置是:首页 >学无止境 >【大数据之Hadoop】二十一、MapReduce、HDFS、Yarn配合工作(作业提交全过程)网站首页学无止境
【大数据之Hadoop】二十一、MapReduce、HDFS、Yarn配合工作(作业提交全过程)
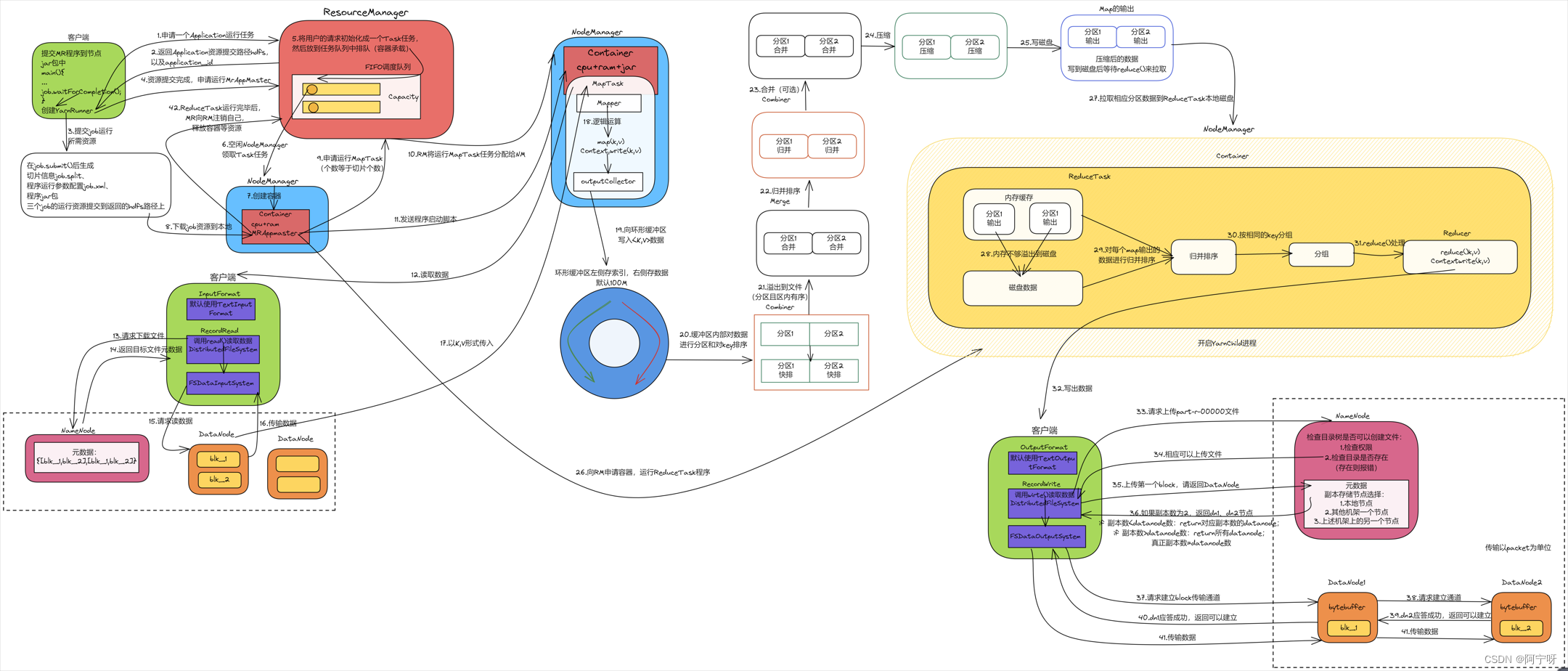
1-11、26为Yarn;12-17为HDFS写数据流程;18-25、27-31为MapReduce;19-25为Shuffle;32-41为HDFS写数据流程。
(0)MR程序提交到客户端所在的节点,在集群模式中运行MR程序,当运行到主函数的waitForCompletion()函数时创建YarnRunner(本地模式是LocalRunner)。
(1)YarnRunner向ResourceManager申请一个Application运行任务。
(2)RM将该应用程序的资源路径返回给YarnRunner,让YarnRunner把提交的job放到集群路径上。
(3)该程序将运行所需资源提交到HDFS集群路径上,包括split切片信息(控制开启MapTask的数量)、配置参数文件xml(控制任务按照xml里的参数运行)以及jar包(程序代码)。
(4)程序资源提交完毕后,YarnRunner申请运行MrAppMaster。
(5)RM将用户的请求初始化成一个Task任务,然后放到任务队列中排队(任务队列默认是容器)。
(6)空闲NodeManager领取Task任务。
(7)该NodeManager创建容器Container(任务的执行只能发生在容器中,容器中封装了资源),并在容器中启动MRAppmaster进程。
(8)Container从HDFS集群路径上拷贝资源(即切片信息等)到本地。
(9)容器拿到切片信息后,由MRAppmaster向RM 再次申请运行MapTask(切片个数=MapTask个数,有多少切片就申请开启多少MapTask)。
(10)RM将运行MapTask任务分配给NodeManager,NodeManager领取任务并创建容器(MapTask对应的容器有可能在同一个NodeManager节点上),并拷贝cpu、ram和jar包资源。
(11)MRAppMaster向接收到任务的NodeManager发送程序启动命令,NodeManager分别启动MapTask,然后开启YarnChild进程。
(12)MapTask向客户端读数据。
(13)客户端的InputFormat默认使用TextInputFormat,通过DistributedFileSystem分布式文件系统向NameNode请求下载文件,NameNode通过查询权限和元数据,找到文件块所在的DataNode地址。
(14)NameNode返回目标文件的元数据。
(15)客户端创建流,通过流对象挑选一台DataNode服务器,请求读取数据(串行读取)。(就近原则,然后随机;同时需要考虑当前节点的负载均衡,判断数据流量,当达到一定的量级时可用先访问其他节点)
(16)DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验),客户端以Packet为单位接收,先在本地缓存。
(17)数据以<k,v>的形式传入到MapTask。
(18)进入Mapper阶段,将解析出的key/value交给用户编写map()函数处理,并产生一系列新的key/value。
(19)当数据处理完成后,一般会调用OutputCollector.collect()输出结果,将生成的key/value分区(调用Partitioner),并写入一个环形内存缓冲区中。
(20)缓冲区内部对数据分区存储,当数据进入到环形缓冲区时就进行分区标记(会根据分区进入到不同的reduce),缓冲区一侧存数据,一侧存索引,当数据达到80%时进行反向溢写。溢写之前需要对分区中的数据进行排序(对索引使用快速排序)。
(21)当环形缓冲区满后,产生大量的溢写文件,先要对数据进行一次本地排序,MapReduce会将数据写到本地磁盘上,生成临时文件。
(22)当所有数据处理完成后(即溢写完成后),MapTask对所有临时文件(溢写文件)归并排序。
(23)对数据进行合并操作。
(24)对分区的数据进行压缩。
(25)将压缩好的数据安装分区写入磁盘。
(26)MrAppMaster向RM再次申请容器运行ReduceTask程序。
(27)ReduceTask拉取相应分区数据先存储到内存。
(28)内存不够时溢出到磁盘。
(29)针对内存和C盘中的每个map输出的数据进行归并排序。
(30)按照相同的key分组。
(31)对于相同的key的数据进入到同一个reduce()处理函数。
(32)将计算结果通过OutputFormat(输出)的RecordWriter调用write()写出数据。
(33)客户端通过分布式文件系统向NameNode请求上传文件,NameNode检查权限,以及目标文件是否已存在,父目录是否存在。
(34)NameNode响应是否可以上传。
(35)客户端请求第一个Block返回上传块的DataNode服务器。
(36)NameNode根据节点是否可用、负载均衡以及哪个节点距离最近等因素返回DataNode节点。
(37)客户端创建流,通过FSDataOutputStream流请求第一个DataNode节点上传数据)。
(38)dn1收到请求会继续调用dn2,将这个通信管道建立完成。(以Packet为单位建立管道)。
(39-40)FSDataOutputStream流建立一个ACK队列用于接收应答,由dn逐层应答,只有都应答成功才会上传一个块。
(41)客户端开始往dn1上传第一个块Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2;dn1每传一个packet会放入一个应答队列等待应答。当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。
(42)ReduceTask程序运行完毕后,MrAppMaster会向RM申请注销自己,释放容器等资源。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结