您现在的位置是:首页 >技术教程 >大数据之Hadoop数据仓库Hive网站首页技术教程
大数据之Hadoop数据仓库Hive
目录:
一、简介
Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。
特点:
- 简单、容易上手 (提供了类似 sql 的查询语言 hql),使得精通 sql 但是不了解 Java 编程的人也能很好地进行大数据分析;
- 灵活性高,可以自定义用户函数 (UDF) 和存储格式;
- 为超大的数据集设计的计算和存储能力,集群扩展容易;
- 统一的元数据管理,可与 presto/impala/sparksql 等共享数据;
- 执行延迟高,不适合做数据的实时处理,但适合做海量数据的离线处理。
二、HQL的执行流程
Hive 在执行一条 HQL 的时候,会经过以下步骤:
- 语法解析:Antlr 定义 SQL 的语法规则,完成 SQL 词法,语法解析,将 SQL 转化为抽象 语法树 AST Tree;
- 语义解析:遍历 AST Tree,抽象出查询的基本组成单元 QueryBlock;
- 生成逻辑执行计划:遍历 QueryBlock,翻译为执行操作树 OperatorTree;
- 优化逻辑执行计划:逻辑层优化器进行 OperatorTree 变换,合并不必要的 ReduceSinkOperator,减少
shuffle 数据量; - 生成物理执行计划:遍历 OperatorTree,翻译为 MapReduce 任务;
- 优化物理执行计划:物理层优化器进行 MapReduce 任务的变换,生成最终的执行计划。
HQL建表语句示例:
CREATE TABLE students(
name STRING, -- 姓名
age INT, -- 年龄
subject ARRAY<STRING>, --学科
score MAP<STRING,FLOAT>, --各个学科考试成绩
address STRUCT<houseNumber:int, street:STRING, city:STRING, province:STRING> --家庭居住地址
) ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
三、索引
2.3 创建索引
CREATE INDEX index_name --索引名称
ON TABLE base_table_name (col_name, ...) --建立索引的列
AS index_type --索引类型
[WITH DEFERRED REBUILD] --重建索引
[IDXPROPERTIES (property_name=property_value, ...)] --索引额外属性
[IN TABLE index_table_name] --索引表的名字
[
[ ROW FORMAT ...] STORED AS ...
| STORED BY ...
] --索引表行分隔符 、 存储格式
[LOCATION hdfs_path] --索引表存储位置
[TBLPROPERTIES (...)] --索引表表属性
[COMMENT "index comment"]; --索引注释
2.4 查看索引
--显示表上所有列的索引
SHOW FORMATTED INDEX ON table_name;
2.4 删除索引
删除索引会删除对应的索引表。
DROP INDEX [IF EXISTS] index_name ON table_name;
如果存在索引的表被删除了,其对应的索引和索引表都会被删除。如果被索引表的某个分区被删除了,那么分区对应的分区索引也会被删除。
2.5 重建索引
ALTER INDEX index_name ON table_name [PARTITION partition_spec] REBUILD;
重建索引。如果指定了 PARTITION,则仅重建该分区的索引。
四、索引案例
3.1 创建索引
在 emp 表上针对 empno 字段创建名为 emp_index,索引数据存储在 emp_index_table 索引表中
create index emp_index on table emp(empno) as
'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
with deferred rebuild
in table emp_index_table ;
此时索引表中是没有数据的,需要重建索引才会有索引的数据。
3.2 重建索引
alter index emp_index on emp rebuild;
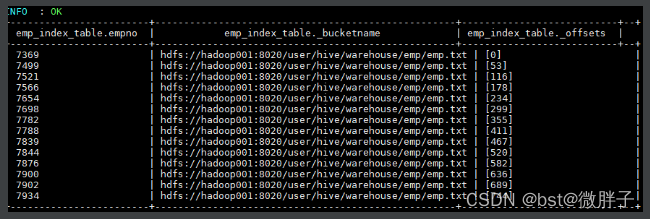
Hive 会启动 MapReduce 作业去建立索引,建立好后查看索引表数据如下。三个表字段分别代表:索引列的值、该值对应的 HDFS 文件路径、该值在文件中的偏移量。
五、Hive常用DDL操作
1.1 查看数据列表
show databases;
1.2 使用数据库
USE database_name;
1.3 新建数据库
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name --DATABASE|SCHEMA 是等价的
[COMMENT database_comment] --数据库注释
[LOCATION hdfs_path] --存储在 HDFS 上的位置
[WITH DBPROPERTIES (property_name=property_value, ...)]; --指定额外属性
示例:
CREATE DATABASE IF NOT EXISTS hive_test
COMMENT 'hive database for test'
WITH DBPROPERTIES ('create'='heibaiying');
1.4 查看数据库信息
语法:
DESC DATABASE [EXTENDED] db_name; --EXTENDED 表示是否显示额外属性
示例:
DESC DATABASE EXTENDED hive_test;
1.5 删除数据库
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
默认行为是 RESTRICT,如果数据库中存在表则删除失败。要想删除库及其中的表,可以使用 CASCADE 级联删除。
示例:
DROP DATABASE IF EXISTS hive_test CASCADE;
二、创建表
2.1 建表语法
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --表名
[(col_name data_type [COMMENT col_comment],
... [constraint_specification])] --列名 列数据类型
[COMMENT table_comment] --表描述
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --分区表分区规则
[
CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS
] --分桶表分桶规则
[SKEWED BY (col_name, col_name, ...) ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
] --指定倾斜列和值
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)]
] -- 指定行分隔符、存储文件格式或采用自定义存储格式
[LOCATION hdfs_path] -- 指定表的存储位置
[TBLPROPERTIES (property_name=property_value, ...)] --指定表的属性
[AS select_statement]; --从查询结果创建表
2.2 内部表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
2.3 外部表
CREATE EXTERNAL TABLE emp_external(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY " "
LOCATION '/hive/emp_external';
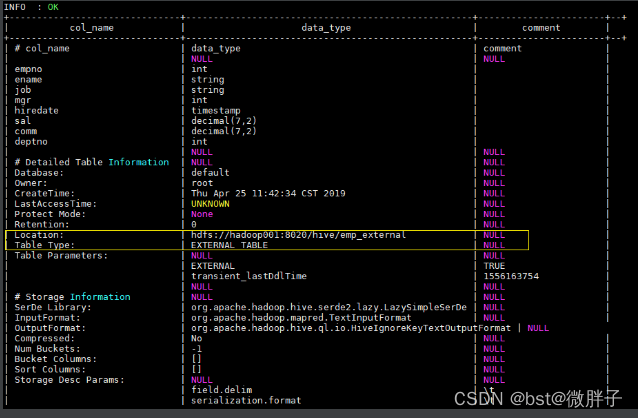
使用 desc format emp_external 命令可以查看表的详细信息如下:
2.4 分区表
CREATE EXTERNAL TABLE emp_partition(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY " "
LOCATION '/hive/emp_partition';
2.5 分桶表
CREATE EXTERNAL TABLE emp_bucket(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
CLUSTERED BY(empno) SORTED BY(empno ASC) INTO 4 BUCKETS --按照员工编号散列到四个 bucket 中
ROW FORMAT DELIMITED FIELDS TERMINATED BY " "
LOCATION '/hive/emp_bucket';
2.6 倾斜表
通过指定一个或者多个列经常出现的值(严重偏斜),Hive 会自动将涉及到这些值的数据拆分为单独的文件。在查询时,如果涉及到倾斜值,它就直接从独立文件中获取数据,而不是扫描所有文件,这使得性能得到提升。
CREATE EXTERNAL TABLE emp_skewed(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
SKEWED BY (empno) ON (66,88,100) --指定 empno 的倾斜值 66,88,100
ROW FORMAT DELIMITED FIELDS TERMINATED BY " "
LOCATION '/hive/emp_skewed';
2.7 临时表
临时表仅对当前 session 可见,临时表的数据将存储在用户的暂存目录中,并在会话结束后删除。如果临时表与永久表表名相同,则对该表名的任何引用都将解析为临时表,而不是永久表。临时表还具有以下两个限制:
不支持分区列;
不支持创建索引。
CREATE TEMPORARY TABLE emp_temp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
2.8 CTAS创建表
支持从查询语句的结果创建表:
CREATE TABLE emp_copy AS SELECT * FROM emp WHERE deptno='20';
2.9 复制表结构
语法:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name --创建表表名
LIKE existing_table_or_view_name --被复制表的表名
[LOCATION hdfs_path]; --存储位置
示例:
CREATE TEMPORARY EXTERNAL TABLE IF NOT EXISTS emp_co LIKE emp
2.10 加载数据到表
加载数据到表中属于 DML 操作,这里为了方便大家测试,先简单介绍一下加载本地数据到表中:
– 加载数据到 emp 表中
load data local inpath "/usr/file/emp.txt" into table emp;
其中 emp.txt 的内容如下,你可以直接复制使用,也可以到本仓库的resources 目录下载:
7369 SMITH CLERK 7902 1980-12-17 00:00:00 800.00 20
7499 ALLEN SALESMAN 7698 1981-02-20 00:00:00 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-02-22 00:00:00 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-04-02 00:00:00 2975.00 20
7654 MARTIN SALESMAN 7698 1981-09-28 00:00:00 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-05-01 00:00:00 2850.00 30
7782 CLARK MANAGER 7839 1981-06-09 00:00:00 2450.00 10
7788 SCOTT ANALYST 7566 1987-04-19 00:00:00 1500.00 20
7839 KING PRESIDENT 1981-11-17 00:00:00 5000.00 10
7844 TURNER SALESMAN 7698 1981-09-08 00:00:00 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-05-23 00:00:00 1100.00 20
7900 JAMES CLERK 7698 1981-12-03 00:00:00 950.00 30
7902 FORD ANALYST 7566 1981-12-03 00:00:00 3000.00 20
7934 MILLER CLERK 7782 1982-01-23 00:00:00 1300.00 10
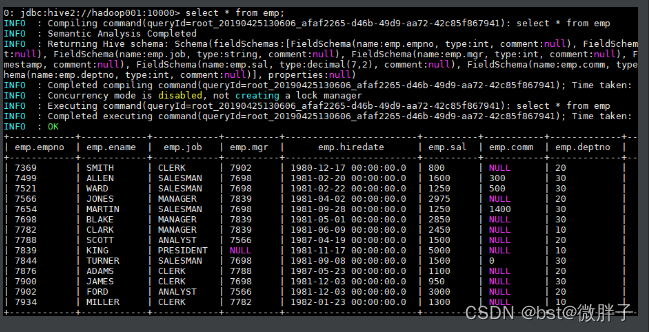
加载后可查询表中数据:
三、修改表
3.1 重命名表
语法:
ALTER TABLE table_name RENAME TO new_table_name;
示例:
ALTER TABLE emp_temp RENAME TO new_emp; --把 emp_temp 表重命名为 new_emp
3.2 修改列
语法:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type
[COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];
示例:
-- 修改字段名和类型
ALTER TABLE emp_temp CHANGE empno empno_new INT;
-- 修改字段 sal 的名称 并将其放置到 empno 字段后
ALTER TABLE emp_temp CHANGE sal sal_new decimal(7,2) AFTER ename;
-- 为字段增加注释
ALTER TABLE emp_temp CHANGE mgr mgr_new INT COMMENT 'this is column mgr';
3.3 新增列
示例:
ALTER TABLE emp_temp ADD COLUMNS (address STRING COMMENT 'home address');
四、清空表/删除表
4.1 清空表
语法:
-- 清空整个表或表指定分区中的数据
TRUNCATE TABLE table_name [PARTITION (partition_column = partition_col_value, ...)];
目前只有内部表才能执行 TRUNCATE 操作,外部表执行时会抛出异常 Cannot truncate non-managed table XXXX。
示例:
TRUNCATE TABLE emp_mgt_ptn PARTITION (deptno=20);
4.2 删除表
语法:
DROP TABLE [IF EXISTS] table_name [PURGE];
内部表:不仅会删除表的元数据,同时会删除 HDFS 上的数据;
外部表:只会删除表的元数据,不会删除 HDFS 上的数据;
删除视图引用的表时,不会给出警告(但视图已经无效了,必须由用户删除或重新创建)。
五、其他命令
5.1 Describe
查看数据库:
DESCRIBE|Desc DATABASE [EXTENDED] db_name; --EXTENDED 是否显示额外属性
查看表:
DESCRIBE|Desc [EXTENDED|FORMATTED] table_name --FORMATTED 以友好的展现方式查看表详情
5.2 Show
- 查看数据库列表
-- 语法
SHOW (DATABASES|SCHEMAS) [LIKE 'identifier_with_wildcards'];
-- 示例:
SHOW DATABASES like 'hive*';
LIKE 子句允许使用正则表达式进行过滤,但是 SHOW 语句当中的 LIKE 子句只支持 *(通配符)和 |(条件或)两个符号。例如 employees,emp *,emp * | * ees,所有这些都将匹配名为 employees 的数据库。
- 查看表的列表
-- 语法
SHOW TABLES [IN database_name] ['identifier_with_wildcards'];
-- 示例
SHOW TABLES IN default;
- 查看视图列表
SHOW VIEWS [IN/FROM database_name] [LIKE 'pattern_with_wildcards']; --仅支持 Hive 2.2.0 +
- 查看表的分区列表
SHOW PARTITIONS table_name;
- 查看表/视图的创建语句
```commonlisp
SHOW CREATE TABLE ([db_name.]table_name|view_name);
六、Hive 常用DML操作
案例分析:
新建分区表:
CREATE TABLE emp_ptn(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2)
)
PARTITIONED BY (deptno INT) -- 按照部门编号进行分区
ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
从 HDFS 上加载数据到分区表:
LOAD DATA INPATH "hdfs://hadoop001:8020/mydir/emp.txt" OVERWRITE INTO TABLE emp_ptn PARTITION (deptno=20);
emp.txt 文件可在本仓库的 resources 目录中下载
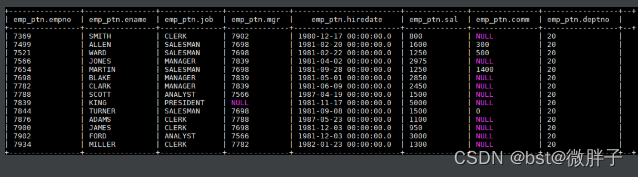
加载后表中数据如下,分区列 deptno 全部赋值成 20:
七、查询结果插入到表
案例分析:
新建 emp 表,作为查询对象表
CREATE TABLE emp(
empno INT,
ename STRING,
job STRING,
mgr INT,
hiredate TIMESTAMP,
sal DECIMAL(7,2),
comm DECIMAL(7,2),
deptno INT)
ROW FORMAT DELIMITED FIELDS TERMINATED BY " ";
-- 加载数据到 emp 表中 这里直接从本地加载
load data local inpath "/usr/file/emp.txt" into table emp;
为清晰演示,先清空 emp_ptn 表中加载的数据:
TRUNCATE TABLE emp_ptn;
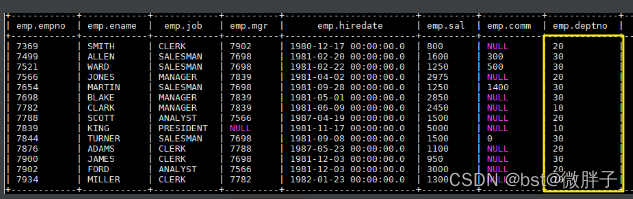
静态分区演示:从 emp 表中查询部门编号为 20 的员工数据,并插入 emp_ptn 表中,语句如下:
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno=20)
SELECT empno,ename,job,mgr,hiredate,sal,comm FROM emp WHERE deptno=20;
完成后 emp_ptn 表中数据如下:

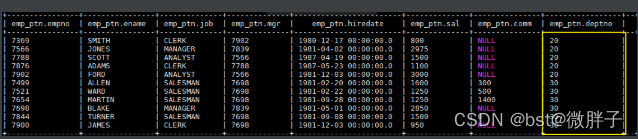
动态分区演示:
-- 由于我们只有一个分区,且还是动态分区,所以需要关闭严格默认。因为在严格模式下,用户必须至少指定一个静态分区
set hive.exec.dynamic.partition.mode=nonstrict;
-- 动态分区 此时查询语句的最后一列为动态分区列,即 deptno
INSERT OVERWRITE TABLE emp_ptn PARTITION (deptno)
SELECT empno,ename,job,mgr,hiredate,sal,comm,deptno FROM emp WHERE deptno=30;
结果:
八、更新和删除操作
更新和删除的语法比较简单,和关系型数据库一致。需要注意的是这两个操作都只能在支持 ACID 的表,也就是事务表上才能执行。
-- 更新
UPDATE tablename SET column = value [, column = value ...] [WHERE expression]
--删除
DELETE FROM tablename [WHERE expression]
案例分析:
- 修改配置
首先需要更改 hive-site.xml,添加如下配置,开启事务支持,配置完成后需要重启 Hive 服务。
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.in.test</name>
<value>true</value>
</property>
- 创建测试表
创建用于测试的事务表,建表时候指定属性 transactional = true 则代表该表是事务表。需要注意的是,按照官方文档 的说明,目前 Hive 中的事务表有以下限制:
必须是 buckets Table;
仅支持 ORC 文件格式;
不支持 LOAD DATA …语句。
CREATE TABLE emp_ts(
empno int,
ename String
)
CLUSTERED BY (empno) INTO 2 BUCKETS STORED AS ORC
TBLPROPERTIES ("transactional"="true");
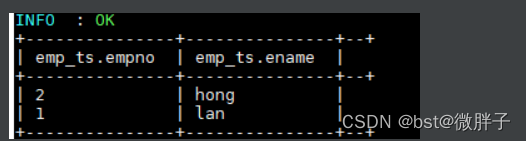
- 插入测试数据
INSERT INTO TABLE emp_ts VALUES (1,"ming"),(2,"hong");
插入数据依靠的是 MapReduce 作业,执行成功后数据如下:
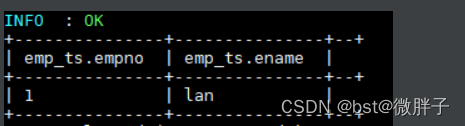
- 测试更新和删除
--更新数据
UPDATE emp_ts SET ename = "lan" WHERE empno=1;
--删除数据
DELETE FROM emp_ts WHERE empno=2;
更新和删除数据依靠的也是 MapReduce 作业,执行成功后数据如下:
九、查询结果写出到文件系统
5.1 语法
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format]
SELECT ... FROM ...
- OVERWRITE 关键字表示输出文件存在时,先删除后再重新写入;
- 和 Load 语句一样,建议无论是本地路径还是 URL 地址都使用完整的;
写入文件系统的数据被序列化为文本,其中列默认由^A 分隔,行由换行符分隔。如果列不是基本类型,则将其序列化为 JSON 格式。其中行分隔符不允许自定义,但列分隔符可以自定义,如下:
-- 定义列分隔符为' '
insert overwrite local directory './test-04'
row format delimited
FIELDS TERMINATED BY ' '
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY ':'
select * from src;
5.2 示例
这里我们将上面创建的 emp_ptn 表导出到本地文件系统,语句如下:
INSERT OVERWRITE LOCAL DIRECTORY '/usr/file/ouput'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' '
SELECT * FROM emp_ptn;
导出结果如下:
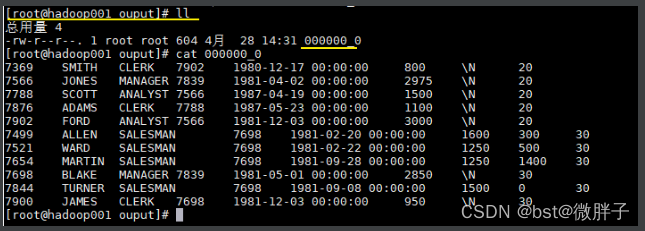
十、Hive CLI和Beeline命令行的基本使用
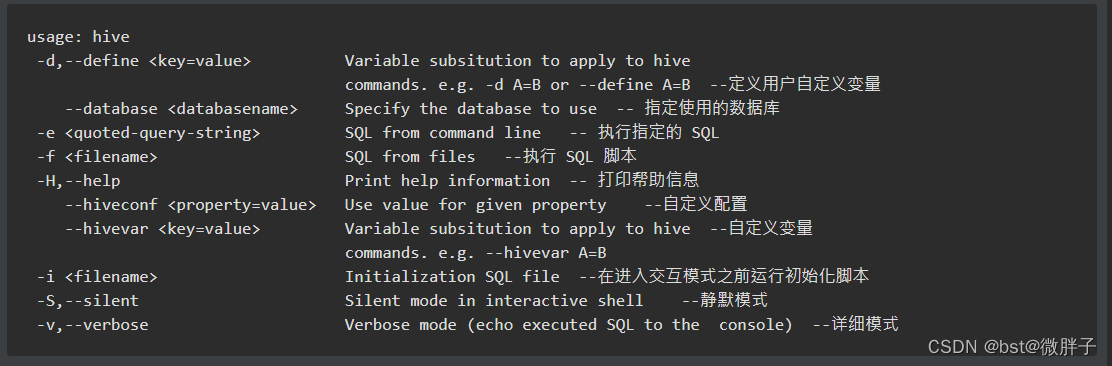
1.1 Help
使用 hive -H 或者 hive --help 命令可以查看所有命令的帮助,显示如下:
1.2 交互式命令行
直接使用 Hive 命令,不加任何参数,即可进入交互式命令行。
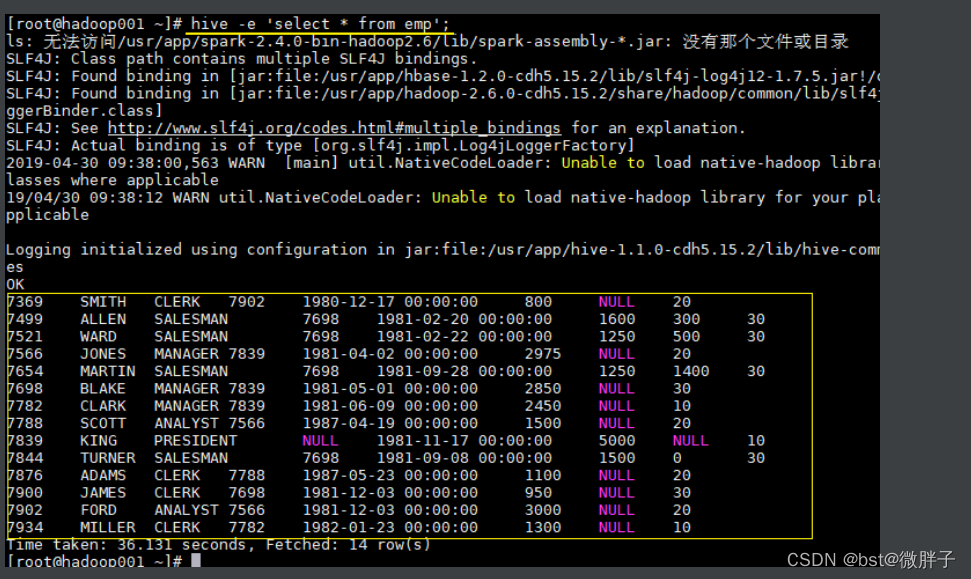
1.3 执行SQL命令
在不进入交互式命令行的情况下,可以使用 hive -e 执行 SQL 命令。
hive -e 'select * from emp';
1.4 执行SQL脚本
用于执行的 sql 脚本可以在本地文件系统,也可以在 HDFS 上。
# 本地文件系统
hive -f /usr/file/simple.sql;
# HDFS文件系统
hive -f hdfs://hadoop001:8020/tmp/simple.sql;
其中 simple.sql 内容如下:
select * from emp;
1.5 配置Hive变量
可以使用 --hiveconf 设置 Hive 运行时的变量。
hive -e 'select * from emp'
--hiveconf hive.exec.scratchdir=/tmp/hive_scratch
--hiveconf mapred.reduce.tasks=4;
hive.exec.scratchdir:指定 HDFS 上目录位置,用于存储不同 map/reduce 阶段的执行计划和这些阶段的中间输出结果。
1.6 配置文件启动
使用 -i 可以在进入交互模式之前运行初始化脚本,相当于指定配置文件启动。
hive -i /usr/file/hive-init.conf;
其中 hive-init.conf 的内容如下:
set hive.exec.mode.local.auto = true;
hive.exec.mode.local.auto 默认值为 false,这里设置为 true ,代表开启本地模式。
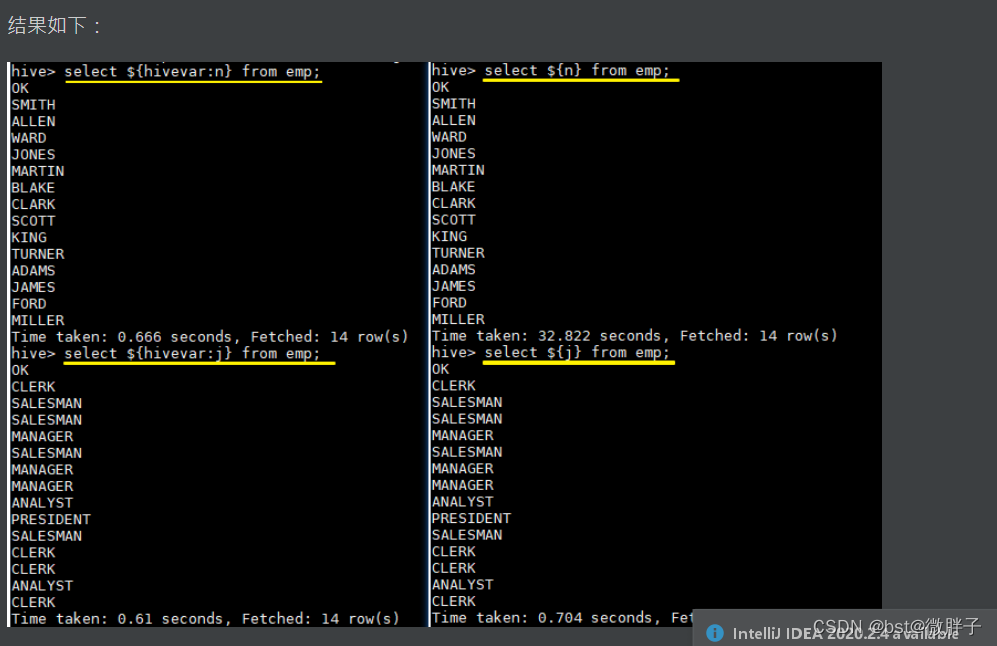
1.7 用户自定义变量
–define <key=value> 和 --hivevar <key=value> 在功能上是等价的,都是用来实现自定义变量,这里给出一个示例:
定义变量:
hive --define n=ename --hiveconf --hivevar j=job;
在查询中引用自定义变量:
# 以下两条语句等价
hive > select ${n} from emp;
hive > select ${hivevar:n} from emp;
# 以下两条语句等价
hive > select ${j} from emp;
hive > select ${hivevar:j} from emp;
十一、Hive配置
可以通过三种方式对 Hive 的相关属性进行配置,分别介绍如下:
3.1 配置文件
方式一为使用配置文件,使用配置文件指定的配置是永久有效的。Hive 有以下三个可选的配置文件:
- hive-site.xml :Hive 的主要配置文件;
- hivemetastore-site.xml: 关于元数据的配置;
- hiveserver2-site.xml:关于 HiveServer2 的配置。
示例如下,在 hive-site.xml 配置 hive.exec.scratchdir:
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/mydir</value>
<description>Scratch space for Hive jobs</description>
</property>
3.2 hiveconf
方式二为在启动命令行 (Hive CLI / Beeline) 的时候使用 --hiveconf 指定配置,这种方式指定的配置作用于整个 Session。
hive --hiveconf hive.exec.scratchdir=/tmp/mydir
3.3 set
方式三为在交互式环境下 (Hive CLI / Beeline),使用 set 命令指定。这种设置的作用范围也是 Session 级别的,配置对于执行该命令后的所有命令生效。set 兼具设置参数和查看参数的功能。如下:
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir=/tmp/mydir;
No rows affected (0.025 seconds)
0: jdbc:hive2://hadoop001:10000> set hive.exec.scratchdir;
+----------------------------------+--+
| set |
+----------------------------------+--+
| hive.exec.scratchdir=/tmp/mydir |
+----------------------------------+--+
3.4 配置优先级
配置的优先顺序如下 (由低到高):
hive-site.xml - >hivemetastore-site.xml- >hiveserver2-site.xml - >-- hiveconf- > set






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结