您现在的位置是:首页 >其他 >从传统MVC架构推演DDD架构网站首页其他
从传统MVC架构推演DDD架构
文章目录
为什么要做架构推演这个事情?
工作中遇到过的研发问题
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 效率低 | 1、搭建新项目,从老项目拷贝 2、对接效率:历史原因基础服务无对接文档,接口文档等 3、基础组件:通用问题未沉淀通用方案 | 1、定制脚手架 2、留存研发各流程阶段文档,并制定文档模板 3、沉淀通用解决方案形成pom依赖 |
| 交接/学习成本 | 老项目无文档,接手成本高 | 1、留存研发各流程阶段文档2、并审核保证文档质量 |
| 问题成本 | 公司无脚手架工程,新项目从老项目拷贝,pom依赖集成问题, 其他人也可能遇到,相同问题反复处理 | 1、制定脚手架 2、规范脚手架依赖 |
| 研发效率 | 技术侧,通用问题未沉淀通用方案,如一致性、分布式事务等,导致各业务系统开发人员各自为政自己去实现 | 1、沉淀通用解决方案形成pom依赖 |
| 沟通成本 | 各个业务系统会依赖调用基础服务,历史原因基础服务没有相关文档, 各个业务系统开发人员分别去咨询基础服务负责人, 或者各业务系统开发人员咨询最先对接那个人 | 1、留存研发各流程阶段文档 2、梳理基础服务二方接口形成文档 |
| 系统维护困难 | 1、项目结构及分包不统一(无架构规范) 2、编码风格不统一(无明确规范) 3、编码可读性、扩展性不够优雅(cr缺失) 4、对底层中间件的使用方式不统一(无基础组件沉淀) 5、业务系统中日志处理不统一(通用功能未沉淀) 6、日子格式不统一 7、调用链路不规范,分层分包未约束(老项目),方法之间调用各自model转化 | 1、制定分层分包规范 2、制定编码规范(使用阿里开发规范) 3、定期拉会分享学习阿里规范 4、审核方案设计 5、代码CR |
| 问题预警 | 无监控无追踪,目前若为某个业务预警只能在代码中硬编码 | 1、监控体系 2、通过监控数据预警 |
| 问题处理 | 1、elk缺失、无链路追踪,定位问题速度和精准度落后 2、无监控,一出现性能问题,可能无从下手 | 1、搭建日志平台 2、搭建监控平台 3、搭建链路追踪 |
上述问题总的来说解决方案分三个维度
- 规范研发流程,保证各阶段质量与交付
- 搭建基础平台体系
- 架构(mvc)质量升级与定制
如何去推动这三个维度事项落地?
对于第1、2点任任何一家达到一定规模的公司,领导层应该都会有意识的落地。
而对于第3点,可不就是这么容易的事情了,困难在哪儿?
- 公司已有的框架,大家已经习惯,人都会有一个舒适区,接触新的东西不习惯(思想层面难以接受)
- 领导层可能已经不在编码,结果导向,不关心架构质量问题在未来引发的问题
基于这些困难,所以需要一篇具有说服力的方案,有理有据才能打动人心。小编在完成这篇文章后呢,又编写了编写《从MVC架构推演DDD架构》感悟及方法论。
注意:名词概念参考文档,在推演过程中出现了一些概念,可在参看文档中学习
传统mvc架构问题

虽然说mvc三层架构简单,易上手,但是在企业级复杂业务下存在问题:
| 问题 | 描述 | 解决方案 |
|---|---|---|
| 业务与技术耦合 | 技术组件升级困难 | 业务与技术解耦,业务内敛,技术组件下沉 |
| 业务堆积在service逐渐形成大泥球 | 业务迭代会越来越困难,只能不断堆代码,后期甚至不敢在改动老代码 | 业务分包 |
| rpc调用分散 | 各个业务service直接应用rpc,当rpc改动时,影响本多个service | 屏蔽外部变化,防腐处理 |
业务与技术解耦设计方案
思考技术组件的共性
mysql、redis、mq,他们的共性是数据存储与传递,那为什么dao操作mysql,而redis和mq的操作确要放在service?是否可以抽离出一个基础设施层来完成这个事情?
以商品发布举例,操作步骤如下:
- 新增一个商品到mysql
- 新增商品缓存到redis
- 新增商品发布消息到MQ
- 另外一个服务订阅MQ将商品同步到ES
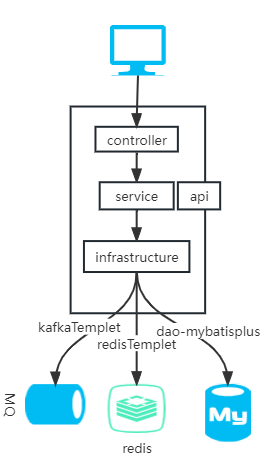
提问:这么分带来的好处是什么?
- service层与技术解耦,未来组件升级不用动service层
- 替换组件更加容易,如mysql替换为MongoDB,mq从卡夫卡替换rocketMQ
- 如果技术组件不下沉,后期技术组件升级替换是基本不可能的
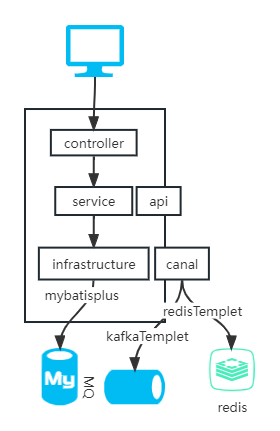
思考这儿mysql和redis等中间件数据一致性怎么保证?数据异构方案
mysql主从,其他所有组件都可以看着mysql slave,通过canal同步数据,高可用保证可在canal和其他中间件之间加MQ
RPC调用防腐设计方案
各个业务service直接应用rpc,当rpc改动时,影响本多个service
RPC调用目前还在service中,我们不妨将RPC抽象,是不是就是获取数据传输数据存储,这跟infrastructure是不是功能类似了?所有rpc调用应该下层
并且应该封装rpc屏蔽外部变化,故而infrastructure中应该存在一个防腐分包(acl)

业务堆积设计方案
上述将技术与业务进行了分离,怎么解决业务堆积在service逐渐形成大泥球,业务在service该怎么落地呢?
大泥球:业务堆积、service交织、可读性没得到控制、技术耦合分散在各个service
怎么解决这个大泥球?举两个例子如下
购物车:
查询用户购物车数据
购物车渲染:数量、选中状态、添加删除、过滤、计价
更新购物车
上诉操作传统做法全耦合在service,面向数据操作,既有流程编排(用户故事),又有业务实现细节(购物车渲染),当业务细节封装不好,甚至面向过程编码,导致可读性很差,一眼难以辨别业务
- 业务与技术解耦:1和3实现细节应该放在基础设施层
- 业务内敛:2相关业务操作内敛到一个用户购物车对象中,通过该对象聚合业务
下单:
验单:商品验证、用户验证、价格验证等(订单服务)
锁定库存(商品服务)
锁优惠劵(优惠价服务)
生成订单(订单服务)
删除购物车购买商品(购物车服务)
上诉操作传统做法全耦合在service,service之间相互调用混乱,最后形成大泥球
业务内敛后,service调用的就是聚合对象进行操作,这儿有订单聚合、商品聚合、购物车聚合等,
service编排聚合对象,完成用户故事提供具有业务意义的功能
什么叫用户故事?用户故事或用例流,一件用户通过系统完成他一个有价值的目标(买一罐饮料)的事就是“用户故事”或“用例流”
内敛的聚合放在哪儿?
业务内敛的目标:是高内聚低耦合
聚合存放位置:
- 在service中分个包承载这些聚合
- 另起一个层,service层依赖它
承载聚合的位置应该叫什么?领域(domain)即问题空间,是一种边界,可以理解为业务边界

分层优化后职责讨论
domain的持久化
注意:domain指业务边界,聚合内敛业务,聚合中包含有数据库实体
- infrastructure本质是对原始数据的存储与查询,而domain是对元素数据的封装,提供业务意义操作动作,业务执行完domain状态变化后,应该要持久化这种状态
- 现在这种结构只能通过service从domain拿到需要持久化的数据操作infrastructure进行持久化
当前这种架构domain如何持久化?
- 当一个domain中有多个数据库实体需要持久化时(如商品,有sku、规格等),需在service分别拿到相应分别数据持久化,事务就被拆开需在service保证,退化
- 现在我们的service职责清晰化为流程编排,明显上述操作在职责之外,所以domain与infrastructure之间有交互
是否能直接通过infrastructure持久化domain(聚合)?infrastructure依赖domain即可

该架构问题
开发可直接在domain使用基础技术服务,开发者是不可控的,需难免出现滥用的情况,造成domain的污染
domain高内聚低耦合保证
要保证domain不被被污染,domain就不能依赖其他任何外部,但是domain持久化又需与infrastructure产生关系,故只能infrastructure去依赖domain,这样domain就操作不了外部,规约了开发滥用

那现在domain怎么与infrastructure交互?
domain与infrastructure交互思考
domain持久化应该要用定义持久化的操作接口,实现在infrastructure中,这些接口叫仓储(repository)

好处:domain中分包repository定义持久化操作接口,屏蔽存储细节,实现在infrastructure,当存储组件切换时,无需动domain层,修改infrastructure的仓储实现就行
domain不是银弹
如一个聚合执行完业务,要紧接着执行一个任务,这个任务可能与我们的业务无关(任务的触发不应该在聚合中),如数据上报(用于监控,也当前业务无关)怎么处理?放在service层进行编排不就好了吗?
这样做是能达到效果,但service层中多个service都用到该domain都编排下?如果哪天需求变动,除非了数据上报,还行需要对该动作判定危险级别,这样在service层改动就大了
所有在domain中应该有个地方承载上诉关系,在domain分包domainservice(领域服务)

这样的话service层编排职责清晰为:编排domain中的聚合和领域服务
事件处理机制
事件的发布订阅职责应该在那层?
事件的发布
事件发布跟在某个业务动作后,跟domain执行业务状态变化要持久化一样,应该落在infrastructure层,包括事件的追踪溯源,在这儿可以设计事件记录表,通过aop记录事件日志
infrastructure封装技术细节,这儿封装的是发布细节,如kafka、rocketmq、spring提供的事件机制
事件的订阅
事件发布是通知其他人要做什么事情,订阅者订阅事件后要触发相应业务,与业务相关的层在domain和service
事件的发布订阅是影响业务的,事件这儿大致分两类,分为微服务内和微服务之间的事件
微服务之间事件发布订阅
后续相应业务处理可能涉及本业务编排,甚至还会依赖其他微服务进行编排,而其他服务的编排在service层,所有应该放在service层
微服务内事件发布订阅
一个业务动作后触发另外一个业务,貌似service层和domain层都能放
放在service:需要区别服务间和服务的事件和订阅了
放在domain:明确知道是一个damian动作触发了另外damian动作
所以放在domain更好
进程内通信机制,这儿可以采用spring提供的事件机制

发布事件通知领域触发业务,这样的事件叫领域事件
事务处理及控制
事务分:本地事务和分布式事务
本地事务:无外乎操作了多张表,需要保证一致性,讨论几种情况保证事务
- 单个领域设计多张表操作(如生成订单):通过repository实现控制本地事务
- 单个领域涉及服务内事件:spring事件机制默认用当前线程,在repository实现也能控制本地事务;若使用多线程异步处理,需要改写事务管理
- 单个领域涉及服务间事件(如发布商品):通过mq保证最终一致性
- 多个领域编排保证事务:(应该放在领域服务domainservice)
- 若放在在service保证事务?可以,但是事务范围扩大了,大事务存在问题
- 如5个领域对象编排,操作了10张表,只有其中两个领域对象需要保证数据一致性,如何保证这两个领域事务而不包含另外三个领域?
- 若放在service层:service层对多个领域编排就行抽离一个方法,编排需要保证事务的两个领域
- 若放在domain:只需在领域服务编排这两个领域控制事务,service层编排领域服务和聚合就行
- 多个领域对象编排涉及服务间事件:事务保证与4一样的

分布式事务:本地事务如何和外部服务保证事务一致性,如何保证?
- 多个领域对象编排涉及服务间事件:
- 通过MQ保证最终一致性
- 通过rocketMQ保证强一致性
- 多个领域对象编排和rpc调用(写操作)组合,如何保证分布式事务?大致几种方案如下
- 在不借助额外技术手段的情况(下述还是存在问题)
- rpc调用与领域对象编排无顺序依赖,rpc调用提前,rpc调用失败本地事务不执行,rpc调用成功只需保证本地事务只需成功(重试机制)
- rpc调用在最后,本地事务失败回滚,rpc调用不执行;本地事务成功,保证rpc调用成功(重试机制)
- rpc调用在多个领域对象编排中间,保证rpc调用和其之后的本地事务成功(重试机制)
- 将rpc调用,改写为事件形式,保证最终一致性或强一致
- 本地事务表
- 引入seta技术组件保证事务
- 多个领域对象编排涉及服务间事件和rpc调用:方案与2类似
总结:一个domain对应一个事务,在repository保证,多个domain事务在domainservice中保证,分布式事务在service服务编排层保证
定时任务应该在那层?
目前定时任务采用分布式定时任务
定时任务一般做什么?1、定时执行某个业务 2、定时同步数据 3、定时执行脚本(如lua脚本)
- 定时任务一旦与业务有依赖的定时任务放在service层
- 与业务无关的定时任务可放在infrastructure,如通过定时同步数据
建议都放在service层,太零散不好管理
抛弃传统mvc架构?
分层后的职责含义变化,是否就抛弃了传统mvc架构?
对一些简单操作,没有什么业务,就是简单的将数据持久化,在传统mvc架构中,service直接调用dao就行
上述分层怎么做?强行走一波domain?走domain链路拉长,开发效率降低,所以传统mvc架构中service职责还是有所保留
如商品下架,简单的根据id根据上下架状态,调用链路controller->service->infrastructure
回头看service层
- 现在service已经很薄了,业务与技术解耦,业务解耦,业务细节到在domain和domainservice中,service层编排对外提供应用级别功能(如下单)
- 也能通过操作infrastructure将一些基础功能暴露
- 总的来说service层已经没有业务逻辑了,通过编排通过应用功能,改名应用层(application)更为贴切

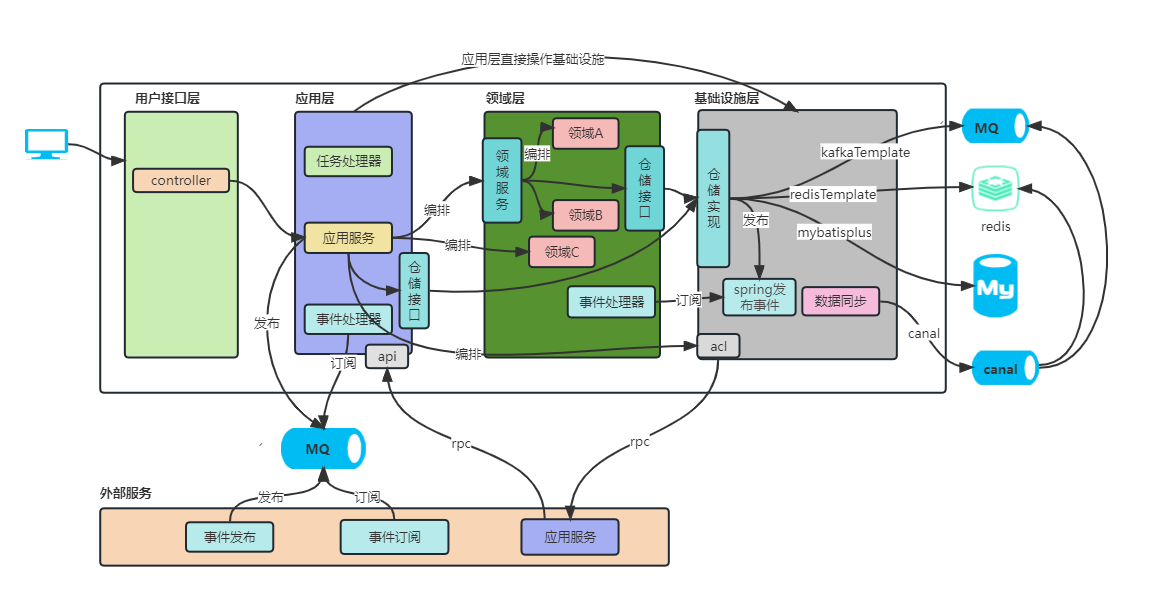
回头看controller层
controller接受用户请求(用户指令),我们抽象下controller是否就是一个指令接收器,接受http调用是指令、rpc调用是指令,事件是指令等指令。controller适配不同的指令,转化为内部语言,执行内部业务。controller改叫适配层更贴切
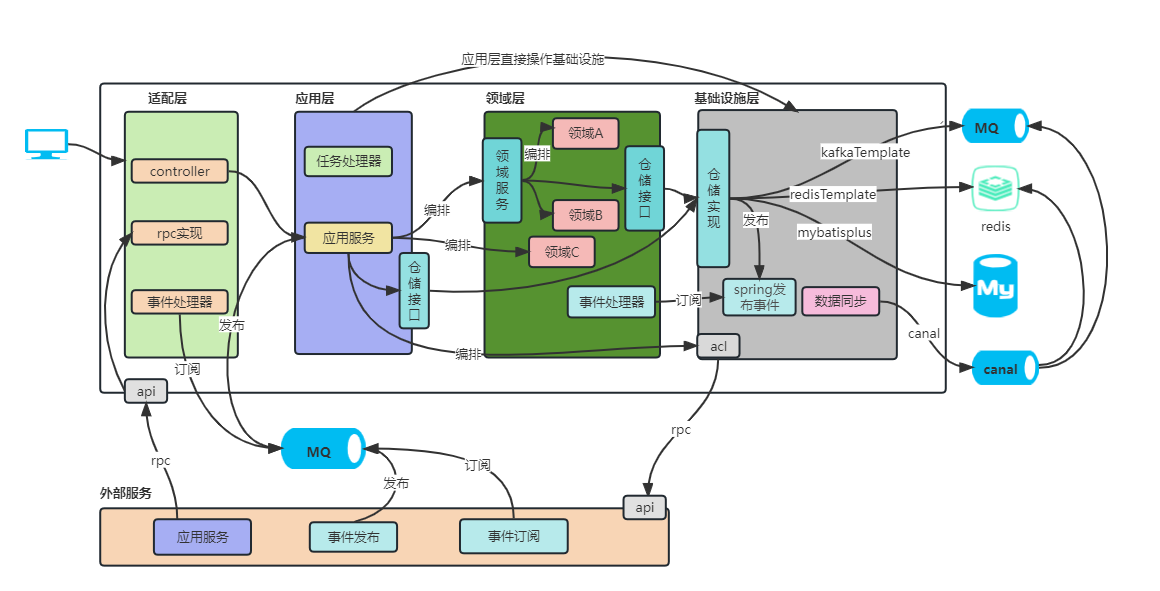
架构演进后职责总结
项目结构
├─ddd-boot-parent(父POM)
│ ├─ddd-boot-api(暴露二方接口)
│ ├─ddd-boot-adapter (适配层)
│ ├─ddd-boot-application (应用层)
│ ├─ddd-boot-domain (领域层)
│ ├─ddd-boot-infrastructure (基础设施层)
- 适配层:负责接收指令和响应,可以是http指令、rpc指令、事件指令、自动化测试指令、批处理脚本指令等。
- 应用层:很薄的一层,理论不应该存在业务规则或逻辑,主要面向用例和流程相关操作,编排领域层中聚合、领域服务以及外部服务,协同完成业务操作。
- 领域层:内敛核心业务逻辑,体现领域模型的业务能力,它用来表达业务概念、业务状态和业务规则。
- 基础设施层:贯穿所有层,为其他各层提供技术和基础服务支持,包括第三方工具、驱动、消息中间件、网关、文件、缓存以及数据库等。比较常见的功能还是提供数据库持久化。
架构演后分包
├─ddd-boot-parent(父POM,管理依赖版本)
│ ├─ddd-boot-api(暴露二方接口)
│ ├─├─api(定义暴露接口)
│ ├─├─model(定义暴露实体)
│ ├─├─├─cqrs(命名Qry结尾[查询实体,读操作],命名以Cmd结尾[命令实体,写操作])
│ ├─├─├─dto(主要用于返回响应)
│ ├─ddd-boot-infrastructure (基础设施层,不同的技术沉淀为组件,在该层引用)
│ ├─├─aspect(切面)
│ ├─├─├─annotation(切面注解)
│ ├─├─repository(仓储实现)
│ ├─├─publisher(事件发布器)
│ ├─├─acl(防腐,封装远程rpc调用,转化为内部语言)
│ ├─├─config(配置,这儿可以考虑放入技术名分包中)
│ ├─├─do(持久化实体,用于支持基础组件,如mybatisplus、jpa、springdate-es等)
│ ├─├─convertor(转换器,转化上层与该层实体)
│ ├─├─utils(工具包)
│ ├─├─mybatisplus
│ ├─├─├─handler(mybatis类型转化器)
│ ├─├─├─mapper
│ ├─├─├─xml
│ ├─├─easyexcel
│ ├─├─├─converter(easyexcel类型转化器)
│ ├─├─redis
│ ├─├─├─lock(基于redis分布式锁实现)
│ ├─├─oos(对象存储)
│ ├─├─es(搜索引擎)
│ ├─├─mq(消息队列)
│ ├─├─shardingsphere(分库分表)
│ ├─├─elasticjob(分布式定时任务)
│ ├─├─canal(数据同步)
│ ├─├─....根据技术分包
│ ├─ddd-boot-domain (领域层,按业务分包)
│ ├─├─├─domainservice(领域服务无状态,可编排业务)
│ ├─├─├─subscribe(事件订阅器)
│ ├─├─xxx(业务名)
│ ├─├─├─aggregates(聚合,有状态)
│ ├─├─├─repository(仓储接口)
│ ├─ddd-boot-application (应用层)
│ ├─├─service(应用服务,编排流程)
│ ├─├─job(任务处理器)
│ ├─├─model(内部实体)
│ ├─├─├─cqrs(命名Qry结尾[查询实体,读操作],命名以Cmd结尾[命令实体,写操作])
│ ├─├─├─dto(主要用于方法返回响应)
│ ├─ddd-boot-adapter (适配层,注意rpc和controller不是共存的)
│ ├─├─rpc(rpc接口实现,app移动端项目toc)
│ ├─├─controller(web控制器,web后台项目tob)
│ ├─├─subscribe(事件订阅器)
讨论上述分包结构在实战可能会遇到的情况:
- model实体类该怎么放,怎么规范?
- aop怎么放?
- 异常怎么处理?
model实体类该怎么放,怎么规范?
首先明确model分类
| 分类维度 | 描述 |
|---|---|
| 编码规范 | 可分DO、DTO等 |
| 请求类型 | 读和写 |
| 是否暴露 | 可分为内部model和外部model |
| 作用范围 | 全局model和局部model |
| 层与层/方法 | 入参与返回 |
| 通用性 | 如分页实体,响应体Response等 |
根据编码规范区分:
| model | 概念 |
|---|---|
| POJO | (Plain ordinary java object) 简单java对象:POJO专指只有setter/getter/toString的简单类,包括DO/DTO/BO/VO等一个POJO持久化以后就是PO;直接用它传递、传递过程中就是DTO;直接用来对应表示层就是VO |
| PO和DO | (Persistant Object) 持久对象:用于表示数据库中的一条记录映射成的 java 对象。PO 仅仅用于表示数据,没有任何数据操作。通常遵守 Java Bean 的规范,拥有 getter/setter 方法**(Data Object)**:阿里规范,与数据库表结构一一对应,通过DAO层向上传输数据源对象 |
| BO和DO | (Business Object) 业务对象:封装对象、复杂对象,里面可能包含多个类 主要作用是把业务逻辑封装为一个对象。这个对象可以包括一个或多个其它的对象。**(Domain Object):**DDD中领域对象等同BO用于表示一个业务对象。BO 包括了业务逻辑,常常封装了对 DAO、RPC 等的调用,可以进行 PO 与 VO/DTO 之间的转换。BO 通常位于业务层,要区别于直接对外提供服务的服务层:BO 提供了基本业务单元的基本业务操作,在设计上属于被服务层业务流程调用的对象,一个业务流程可能需要调用多个 BO 来完成。比如一个简历,有教育经历、工作经历、社会关系等等。 我们可以把教育经历对应一个PO,工作经历对应一个PO,社会关系对应一个PO。 建立一个对应简历的BO对象处理简历,每个BO包含这些PO。 这样处理业务逻辑时,我们就可以针对BO去处理。 |
| VO | (Value Object) 表现对象:显示层对象,通常是Web向模板渲染引擎层传输的对象。 |
| DTO | (Data Transfer Object) 数据传输对象:泛指用于展示层与服务层之间的数据传输对象 |
| AO | (Application Object)应用对象: 在Web层与Service层之间抽象的复用对象模型,极为贴近展示层,复用度不高。 |
指令类型区分和层与层(方法)
层与层之间:model的传递起始是在方法的入参与返回
| 区分 | 描述 |
|---|---|
| Qry | query缩写表示读操作实体 |
| Cmd | command缩写表示写操作实体 |
| Event | 事件 |
model命名规范=业务+后缀,这样就知道model用于那个业务的读写,还是事件监听
读写操作区分:
- web中可根据请求类型注解区分,也就是restful接口风格。若是命名区分不了在,在远程调用(feign)时调用方还是不能见名知意
- RPC调用只能通过方法命名区分
传统项目:
- RPC调用一般使用DTO
- 在web项目中,请求参数可能通过Param或Query区分
统一规范:
- 入参采用Qry和Cmd方式,RPC可采用QryDTO或CmdDTO
- 返回采用DTO方式
一个本质:数据传输起始都可以认为是DTO
是否暴露:
这儿的暴露之是否暴露给外部服务,需暴露的model应该放在api工程中
作用范围:
全局model:如Result响应体、全局code码等应该贯穿整个工程,可以放在infrastructure,如果这些公用model沉淀为组件后可在父工程中引入,全局使用
局部model:如领域层中聚合也是model实体,提供给领域服务、应用层、仓储使用
通用性:
包括Response、PageQuery等,返回的DTO数据会通过Response包装,分页请求数据通过PageQuery包装
当出现异常时会通过Response包装异常相关信息返回
所以通用model应该是贯穿整个项目,应该放在infrastructure,最好是沉淀为组件,在组infrastructure中使用
model之间的转化

api模块model流转:适配层->应用层,所以应用层应该引用api
内部model流程:Qry/Cmd/DTO,适配层->应用层,model应该在应用层定义
aop怎么放?
日常开发中aop使用场景
- 分布式锁
- 幂等处理
- 重试机制
- 系统日志记录
- 业务日志
上诉场景不涉及业务,都是技术侧的非功能性性需求,并且这些功能很通用,应该放在infrastructure,最好是沉淀为组件,在组infrastructure中使用
那aop中涉及业务的场景呢?如果有这样的情况放在应用层吧
异常怎么处理?
异常分为异常定义、异常code和异常处理,应该贯穿整个项目,可以放在infrastructure,最好是沉淀为组件,在组infrastructure中使用
架构演进前后对比

概念参考文档






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结