您现在的位置是:首页 >学无止境 >执行kubectl命令失败server was refused问题解决网站首页学无止境
执行kubectl命令失败server was refused问题解决
在宿主机上执行kubectl 命令时,出现如下错误
[root@root ~] kubectl get namespaces
The connection to the server xxx.xx.xx.xx:6443 was refused - did you specify the right host or port?然后再网上找寻解决方案,发现各种各样的解决方案都存在。有说IP映射错了的、有说没有admin.conf文件的,还有说是看看k8s部分组件启动失败的等等,好多都解决不了我的问题。但是也不失为排查的一些思路,于是整理下来。
下面是各种方案:
一、排除k8s组件是否存在启动失败的情况
6443端口是kubelet的api监听端口,可能是kubelet启动失败,查看kubelet状态,分析日志。
1.查看状态
systemctl status kubelet
2.查看日志
journalctl -xefu kubelet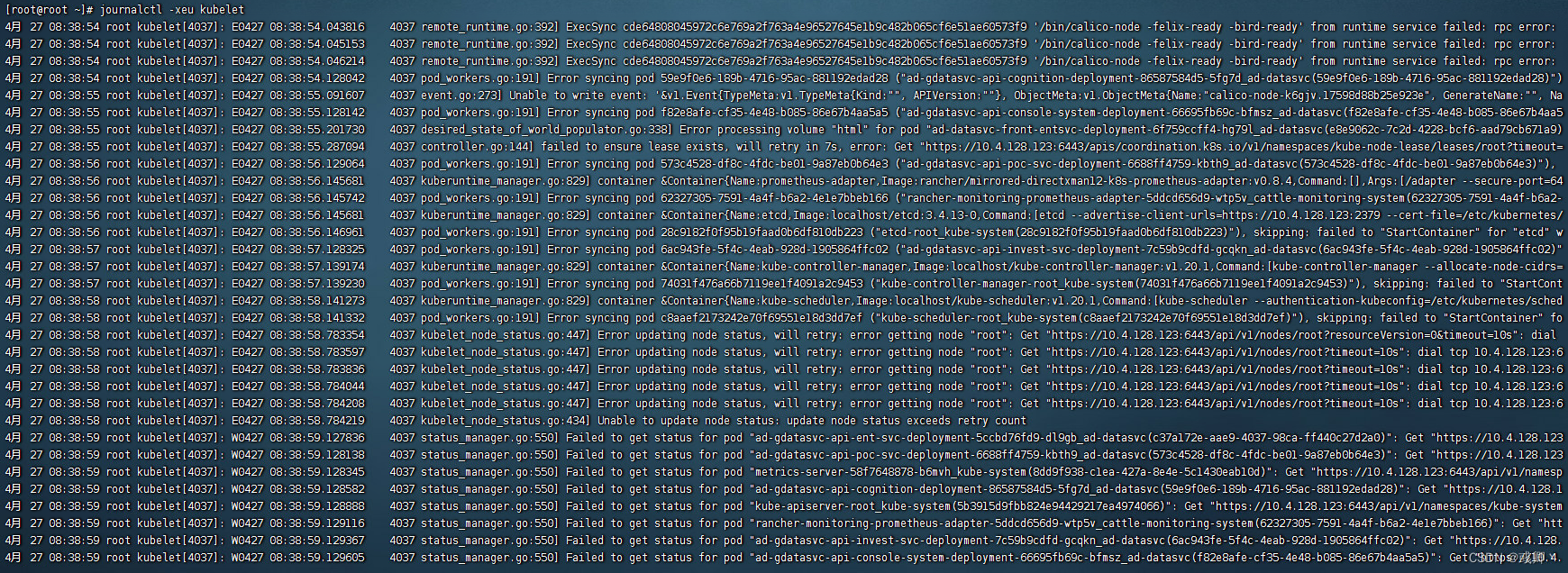
经过上面两个步骤发现,日志好像并没有起到作用,就是一直请求失败,看不出任何原因。
3.查看容器状态
ps ef -a查看k8s相关的组件是否启动失败,如果你刚重启过k8s,最好仔细排查,可能就是某些组件没有启动成功导致的。
下面是k8s某些组件没有启动成功的状态:
[root@master ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
56f463b5684b 9b60aca1d818 "kube-controller-man…" 40 hours ago Exited (2) 39 hours ago k8s_kube-controller-manager_kube-controller-manager-master_kube-system_8f99a56fb3eeae0c61283d6071bfb1f4_5
5043f1103f1f aaefbfa906bd "kube-scheduler --au…" 40 hours ago Exited (2) 39 hours ago k8s_kube-scheduler_kube-scheduler-master_kube-system_285062c53852ebaf796eba8548d69e43_5
2d707069ab22 bfe3a36ebd25 "/coredns -conf /etc…" 41 hours ago Exited (0) 39 hours ago k8s_coredns_coredns-6d56c8448f-mt7vz_kube-system_abc65488-0a54-4a1a-8e23-339f3f23f6d2_0
0dadfca20cb7 bfe3a36ebd25 "/coredns -conf /etc…" 41 hours ago Exited (0) 39 hours ago k8s_coredns_coredns-6d56c8448f-hdtlf_kube-system_e1f90d02-77d0-4529-bea5-b4a72cdb4cf5_0
f25051c775cf registry.aliyuncs.com/google_containers/pause:3.2 "/pause" 41 hours ago Exited (0) 39 hours ago k8s_POD_coredns-6d56c8448f-mt7vz_kube-system_abc65488-0a54-4a1a-8e23-339f3f23f6d2_0
b24a10712152 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" 41 hours ago Exited (0) 39 hours ago k8s_POD_coredns-6d56c8448f-hdtlf_kube-system_e1f90d02-77d0-4529-bea5-b4a72cdb4cf5_0
fed8e33864c1 e708f4bb69e3 "/opt/bin/flanneld -…" 41 hours ago Exited (137) 39 hours a
如果出现上面的情况,重启对应的容器,启动成功问题大概就解决了。
由于我的容器全部启动成功,而且近期没有重启k8s的操作。所以不是这儿的问题,需要继续往下排除了。。。
二、admin.conf 文件
kubectl命令需要使用kubernetes-admin来运行,需要admin.conf文件。
conf文件是通过“ kubeadmin init”命令在主节点/etc/kubernetes 中创建,但是从节点没有conf文件,也没有设置 KUBECONFIG =/root/admin.conf环境变量,所以需要复制conf文件到从节点,并设置环境变量。
1.主节点的admin.conf拷贝到从节点
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
2.设置环境变量
#拷贝admin.conf注意路径
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
source ~/.bash_profile
=========
这个方案网上出现的最多,但我的是master节点,查看/etc/kubernetes目录下是存在 admin.conf文件的。且之前kubectl 命令是可用,证明环境变量也是存在的。无法解决我的问题。
三、IP映射问题
如果查看kubectl日志,出现如下日志,大概率是IP映射的问题了。
journalctl -xeu kubelet
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.314060 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.414432 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.514811 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.615160 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.715273 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.815516 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:58 master.com kubelet[1049]: E0530 17:42:58.915924 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:59 master.com kubelet[1049]: E0530 17:42:59.000379 1049 event.go:273] Unable to write event: 'Post "https://192.168.127.128:6443/api/v1/namespaces/default/events">
5月 30 17:42:59 master.com kubelet[1049]: E0530 17:42:59.016347 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:59 master.com kubelet[1049]: E0530 17:42:59.116651 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:59 master.com kubelet[1049]: E0530 17:42:59.217157 1049 kubelet.go:2183] node "master.com" not found
5月 30 17:42:59 master.com kubelet[1049]: E0530 17:42:59.317429 1049 kubelet.go:2183] node "master.com" not found这说明master节点无法找到 master.com,查看kubelet配置的ip
1. 查看kubelet配置的ip
cat /etc/kubernetes/kubelet.conf
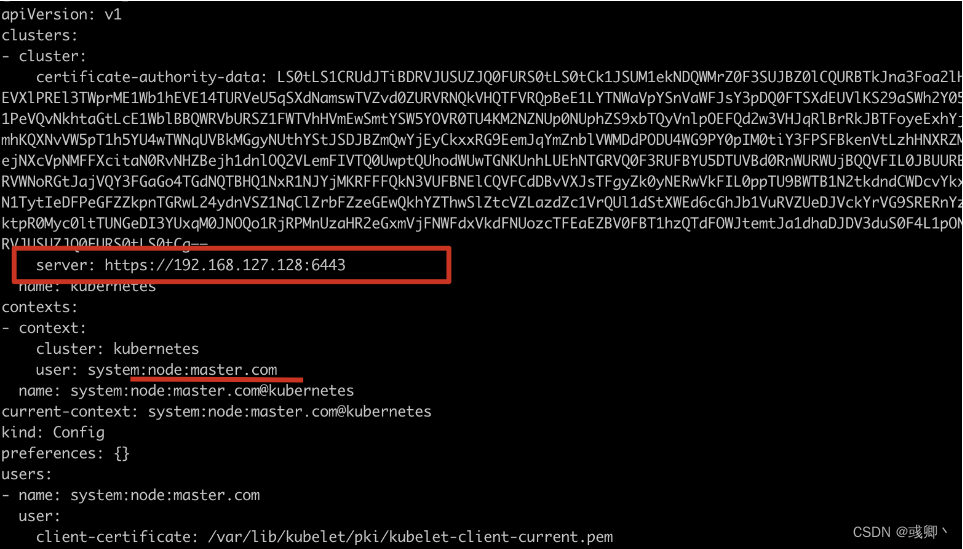
2.查看宿主机ip
ifconfig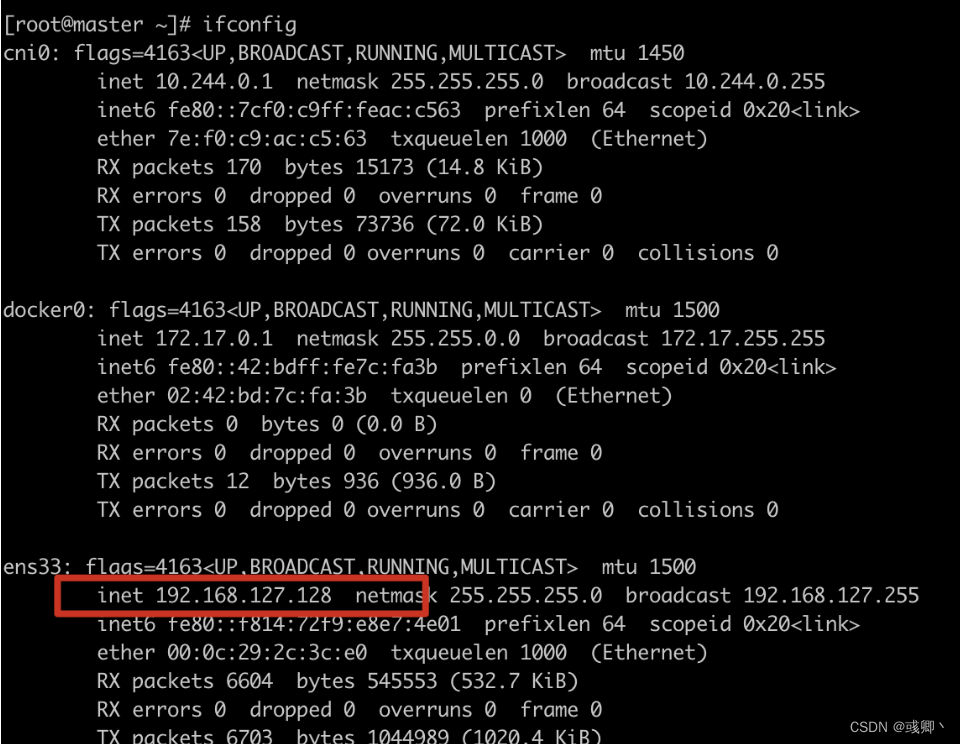
两者一致,说明ip是正确的,这说明宿主机的/ets/hosts 配置有问题。如果ip不一致,则需要修改kubelet、kubeadm、api-server对应的ip。
3.查看host文件
cat /etc/hosts
修改主机名为 master.com即可
但我的依旧配置正确,前面也提到了,我之前的 kubectl 命令是可以用的,只是忽然失效了。所以继续排除ing...
四、排除宿主机磁盘空间
其实在输入命令行的时候就已经发现有问题了。
使用 cd 命令 Tab 键进行命令补全时提示:无法为立即文档创建临时文件: 设备上没有空间

磁盘空间不足了,解决步骤如下:
1.查看磁盘空间使用情况
df -Th可以看到,我的 /dev/mapper/cemtos-root 和 docker overlay 已经爆满了。
2.查看大文件
cd /
# 其中--max-depth=1就是递归查看深度为1
du -h --max-depth=1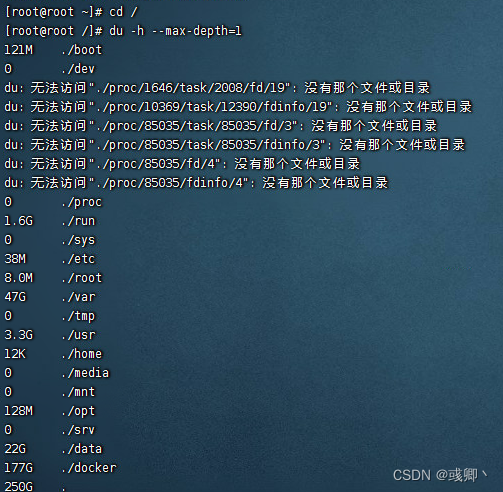
可以看到 /docker 路径下占用了 177G,基本上就是docker overlay2占用了大量的磁盘空间,但对于docker镜像那些可以用的,那些是不可以用的,我们也不清楚,所以不能单纯的用 rm -rf 的命令直接删除了。
3.删除无用镜像或容器
#用于清理磁盘,删除关闭的容器、无用的数据卷和网络,以及dangling镜像(即无tag的镜像)
docker system prune
#清理得更加彻底,可以将没有容器使用Docker镜像都删掉
docker system prune -a我的问题到了这一步就解决了,kubectl 命令恢复了。如果你的问题到达这一步依旧不行,只能进行 docker 的迁移,或者宿主机升配了。
其实到这里也能发现, kubectl 命令失败server was refused 的问题,不仅仅是一种情况导致的,可能会有各种各样的问题。我都想象不到磁盘空间占满还能导致 kubectl 命令不可用。
总之网上的解决方案有很多,但不一定适合你,你要做的是把其他的贴子当作参考,并细心的排查自己的问题了。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结