您现在的位置是:首页 >其他 >Python整个颜色小网站,给刚刚失恋的他.........网站首页其他
Python整个颜色小网站,给刚刚失恋的他.........
简介Python整个颜色小网站,给刚刚失恋的他.........
一些过场剧情:
死党一直暗恋校花,但是校花对他印象也不差,
就是死党一直太怂了,不敢去找校花,
直到昨天看到校花登上了校董儿子的豪车,
死党终于彻底死心,大醉一场,作为他的兄弟,
我怎么能看他郁郁不振呢?
为了让他忘掉校花,走出阴影,
我于是决定把我新收藏的网站分享给他,
顺便分享给大家,纯纯的交流技术,
大家备好纸巾,不对,备好纸笔😂


爬取目标
网址:(实在是不敢放,满满的求生欲,官方大佬手下留情)
兄弟们啊,不要怪我,放图不行啊,我是来交流技术的。
要用的工具
软件:
- python 3.8
- pycharm 2021专业版
模块:
- requests
- parsel
没有模块 pip 安装模块即可
流程解析
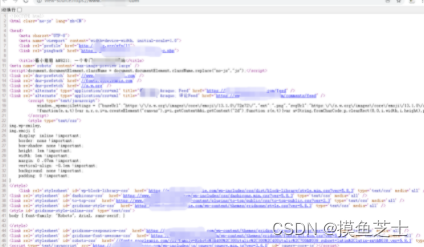
我们首先就是先进入到这个网址,向网站发送网络请求。
然后去拿到它的网页源代码数据,右键点击,查看他的网页源代码。
我们访问网站拿到的数据就是它。
实现代码
import requests
import parsel
import re
import os
for page in range(1, 11):
print(f'==================正在爬取第{page}页==================')
response = requests.get(f'https://网站不提供/page/{page}')
data_html = response.text
zip_data = re.findall('<a href="(.*?)" target="_blank"rel="bookmark">(.*?)</a>', data_html)
for url, title in zip_data:
print(f'----------------正在爬取{title}----------------')
if not os.path.exists('img/' + title):
os.mkdir('img/' + title)
resp = requests.get(url)
url_data = resp.text
selector = parsel.Selector(url_data)
img_list = selector.css('p>img::attr(src)').getall()
for img in img_list:
img_data = requests.get(img).content
img_name = img.split('/')[-1]
with open(f"img/{title}/{img_name}", mode='wb') as f:
f.write(img_data)
print(img_name, '爬取成功!!!')
print(title,'爬取成功!!!')
暗恋单恋都不可靠,
还是要胆大脸皮厚,
主动一点到手了才有结果,
不然女朋友都是别人的了,
祝大家有情人终成眷属,
没有的2023年那必有!
最后 💖
感谢你阅读我的文章哩~
本次航班到这里就结束啦 ⌚
希望本篇文章有对你带来帮助 🎊,有学习到一点知识~
躲起来的星星🏵也在努力发光,你也要努力加油(未来顶峰相见)~
如果你也认为这个文章有丢丢用的话,
点个小赞赞和收藏吧~
点了的话~
那真的是!!!!

风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结