您现在的位置是:首页 >技术杂谈 >爬虫学习| 尚硅谷网站首页技术杂谈
爬虫学习| 尚硅谷
简介爬虫学习| 尚硅谷
urllib——爬取网页
1个类型,6个返回值
urllib.request.urlopen(url) 得到的类型是HTTPResponse

下载 —— 可以下载网页、图片、视频
![]()

请求对象的定制
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36 Edg/108.0.1462.54'}
请求头,有很多标签。 前面带: 的都不能要
传递url的参数——转成unicode编码
1.get方法
a.1个参数:get请求的quote方法

b.多个参数:get请求的urlencode方法
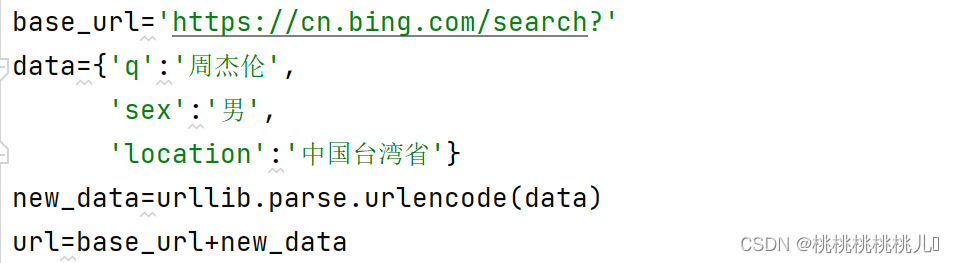
# request=urllib.request.Request(url=url,headers=headers) # response=urllib.request.urlopen(request)
2.post方法
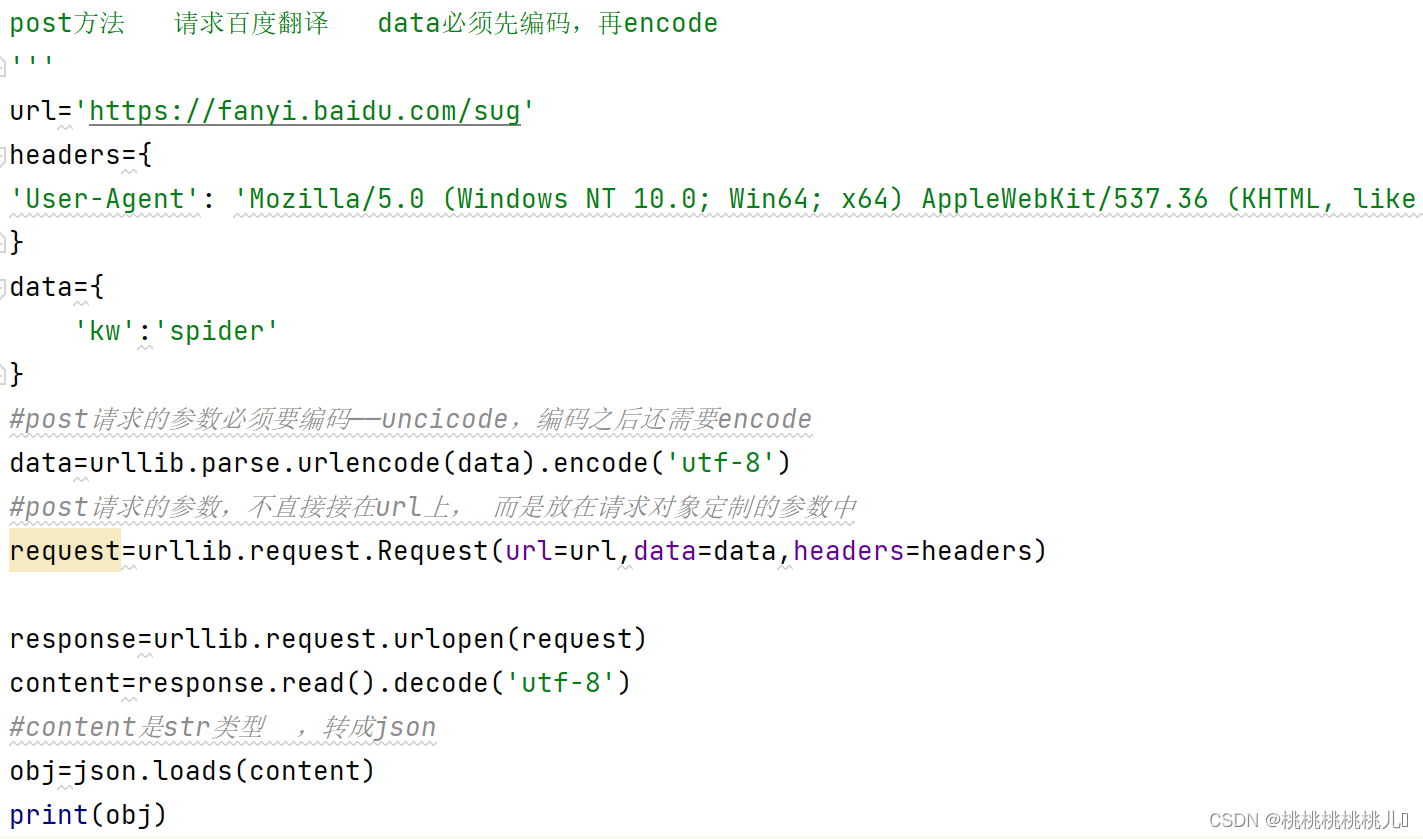
爬取页数限制 ——ajax的get请求
指定页码内容爬取
解析网页
xpath
可以解析本地html文件、服务器响应内容(常用)
需要安装lxml库

用xpath插件可以检查 查询的内容是否正确

提取图片时, 会有“懒加载”, 即图片的标签在图片全部加载显示完毕后可能会变, 要以变之前的标签为准来提取 【参考072】

jsonpath
只能解析本地文件,不能解析服务器文件
1.在网页[network]中找到接口,保存为本地文件
2.对本地文件进行解析
需要把提取到的content清理之后以json格式存入到本地文件中,再对本地文件操作

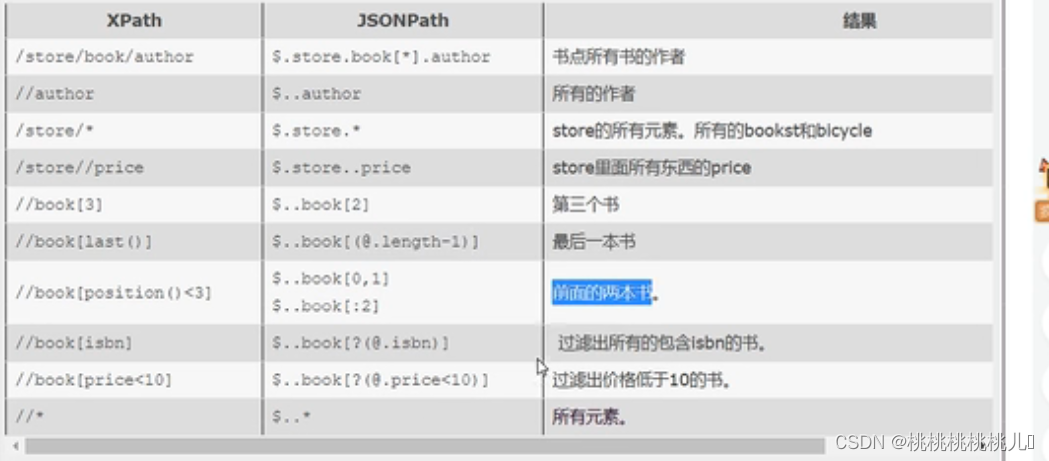
条件过滤需要 加? [?(@.isbn)]
beautifulSoup
可以解析本地文件、网页数据
b4库中 ,有无空格不影响
soup.select()返回的是列表
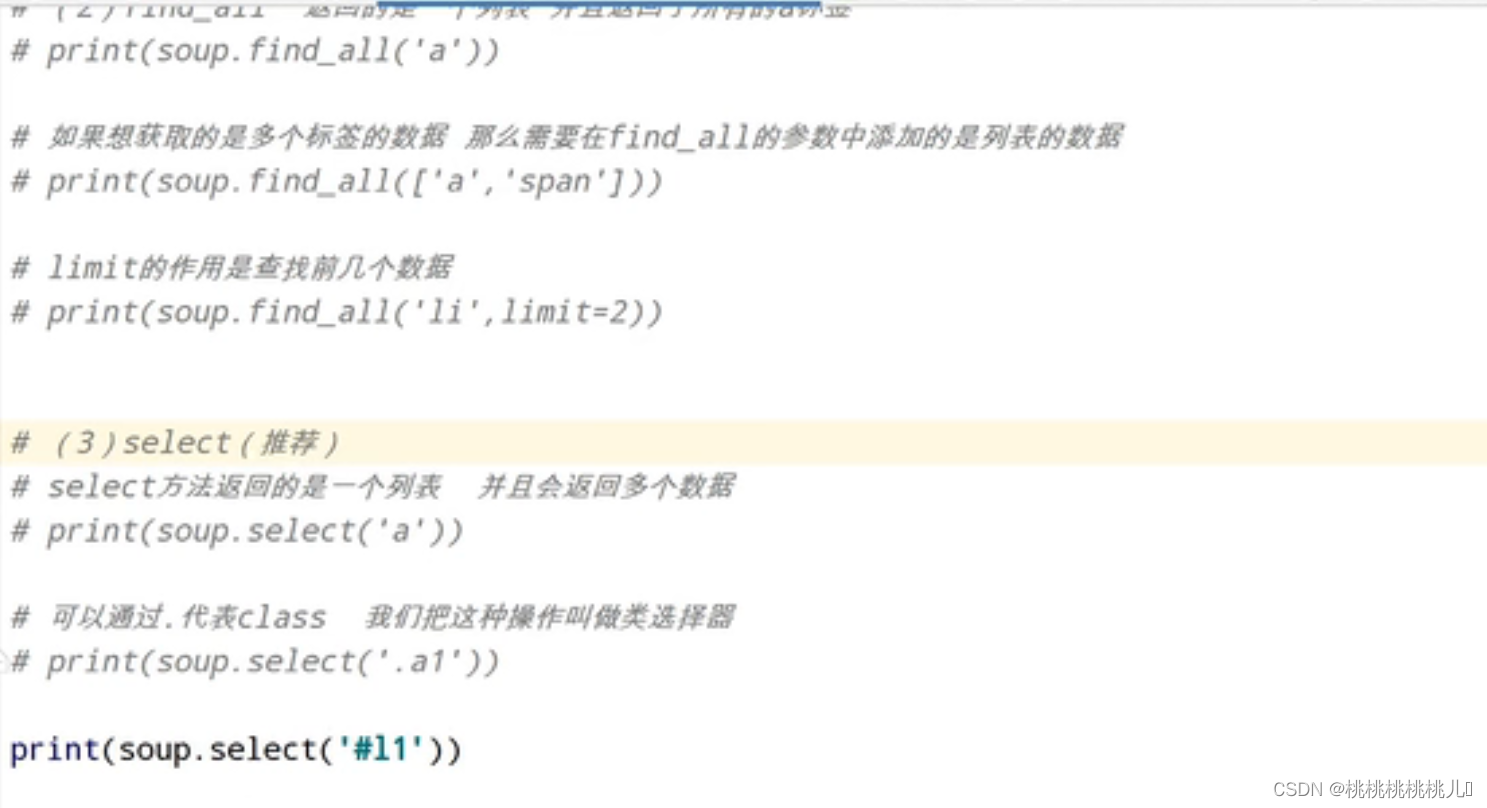


获取节点信息


bs4有一些坑,建议用xpath,下图为二者对比

反爬
可以用以下代码检查是否有反爬机制,若content包含想要内容,则正常爬取
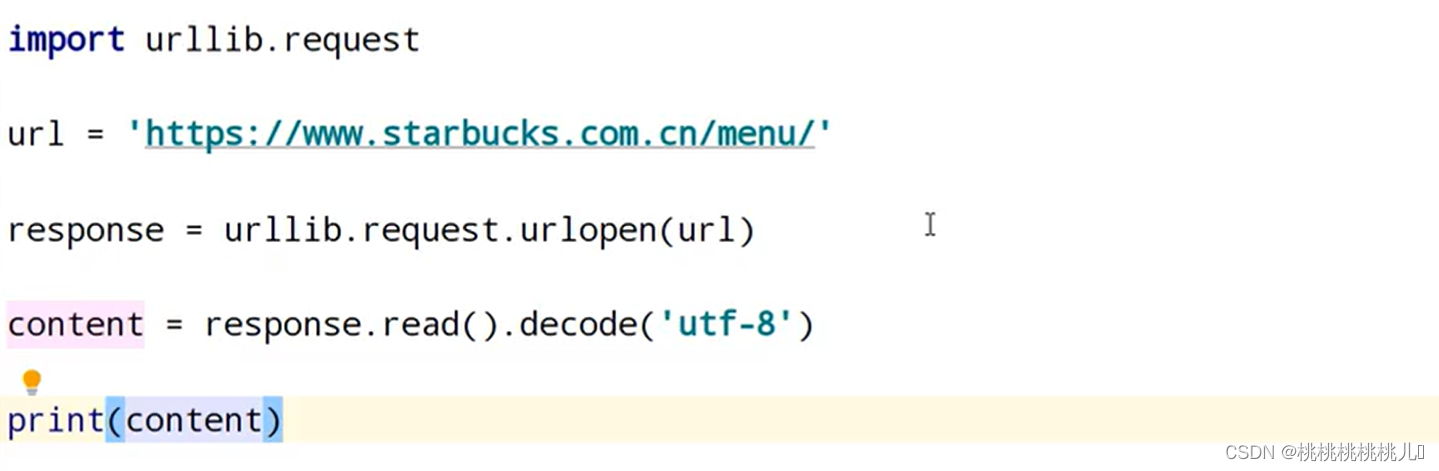
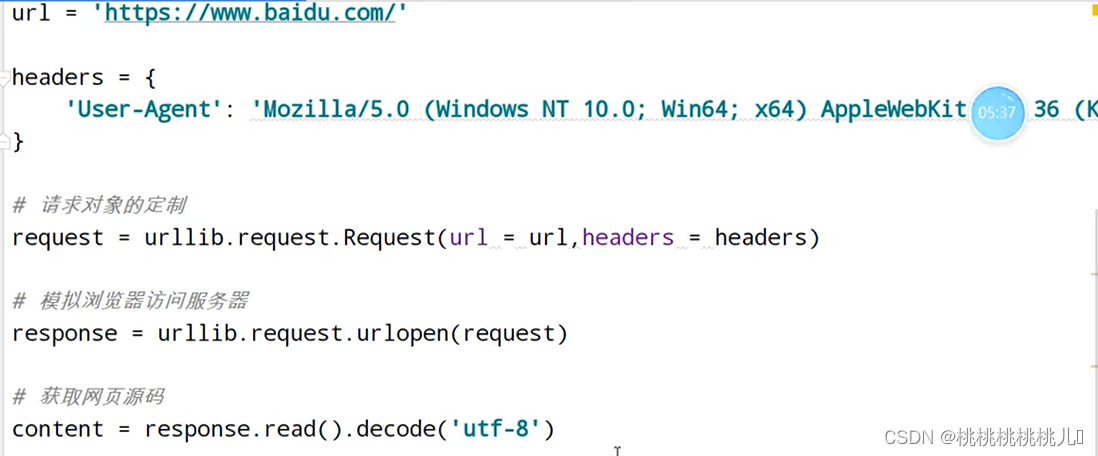
若不包含,则有反爬机制;使用headers进行爬取
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结