您现在的位置是:首页 >技术杂谈 >k8s之HPA(Pod水平自动伸缩)网站首页技术杂谈
k8s之HPA(Pod水平自动伸缩)
1.hpa介绍
HPA是根据指标来进行自动伸缩的,目前HPA有两个版本–v1和v2beta
HPA的API有三个版本,通过kubectl api-versions | grep autoscal可看到
kubectl api-versions | grep autosca
autoscaling/v1
autoscaling/v2beta1
autoscaling/v2beta2
查看使用的版本:
kubectl explain hpa
查看指定其他版本:
kubectl explain hpa --api-version=autoscaling/v2beta1
autoscaling/v1只支持基于CPU指标的缩放;
autoscaling/v2beta1支持Resource Metrics(资源指标,如pod内存)和Custom Metrics(自定义指标)的缩放;
autoscaling/v2beta2支持Resource Metrics(资源指标,如pod的内存)和Custom Metrics(自定义指标)和ExternalMetrics
Pod 水平自动扩缩(Horizontal Pod Autoscaler) 可以基于 CPU 利用率自动扩缩 ReplicationController、Deployment、ReplicaSet 和 StatefulSet 中的 Pod 数量。 除了 CPU 利用率,也可以基于其他应程序提供的 自定义度量指标 来执行自动扩缩。 Pod 自动扩缩不适用于无法扩缩的对象,比如 DaemonSet。
Pod 水平自动扩缩特性由 Kubernetes API 资源和控制器实现。资源决定了控制器的行为。 控制器会周期性地调整副本控制器或 Deployment 中的副本数量,以使得类似 Pod 平均 CPU 利用率、平均内存利用率这类观测到的度量值与用户所设定的目标值匹配。
管理命令
kubectl api-versions |grep metrics
kubectl top nodes
kubectl top pod -n yx-test #查看pod的cpu和内存
kubectl get hpa -n yx-test #查看hpa控制器
kubectl delete hpa osale-admin-data-test -n yx-test 删除hpa控制器
2.部署一下metrics-server,收集集群资源利用率
metrics-server版本获取:
https://github.com/kubernetes-sigs/metrics-server/releases
vim metrics-server.yaml
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:aggregated-metrics-reader
labels:
rbac.authorization.k8s.io/aggregate-to-view: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rules:
- apiGroups: ["metrics.k8s.io"]
resources: ["pods", "nodes"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: metrics-server
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
labels:
k8s-app: metrics-server
spec:
selector:
matchLabels:
k8s-app: metrics-server
template:
metadata:
name: metrics-server
labels:
k8s-app: metrics-server
spec:
serviceAccountName: metrics-server
volumes:
# mount in tmp so we can safely use from-scratch images and/or read-only containers
- name: tmp-dir
emptyDir: {}
containers:
- name: metrics-server
image: registry.cn-shenzhen.aliyuncs.com/lishanbin/metrics-server:v0.3.7
imagePullPolicy: IfNotPresent
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
ports:
- name: main-port
containerPort: 4443
protocol: TCP
securityContext:
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- name: tmp-dir
mountPath: /tmp
#nodeSelector:
# kubernetes.io/os: linux
# kubernetes.io/arch: "amd64"
---
apiVersion: v1
kind: Service
metadata:
name: metrics-server
namespace: kube-system
labels:
kubernetes.io/name: "Metrics-server"
kubernetes.io/cluster-service: "true"
spec:
selector:
k8s-app: metrics-server
ports:
- port: 443
protocol: TCP
targetPort: main-port
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- pods
- nodes
- nodes/stats
- namespaces
- configmaps
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
kubectl api-versions |grep metrics
kubectl top nodes
2.hpa基于cpu自动扩缩容
HPA伸缩过程:
收集HPA控制下所有Pod最近的cpu使用情况(CPU utilization)
对比在扩容条件里记录的cpu限额(CPUUtilization)
调整实例数(必须要满足不超过最大/最小实例数)
每隔30s做一次自动扩容的判断
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过metrics可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个Pod CPU核心的使用占比。
HPA进行伸缩算法:
计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
ceil()表示取大于或等于某数的最近一个整数
每次扩容后冷却3分钟才能再次进行扩容,而缩容则要等5分钟后。
当前Pod Cpu使用率与目标使用率接近时,不会触发扩容或缩容:
触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9
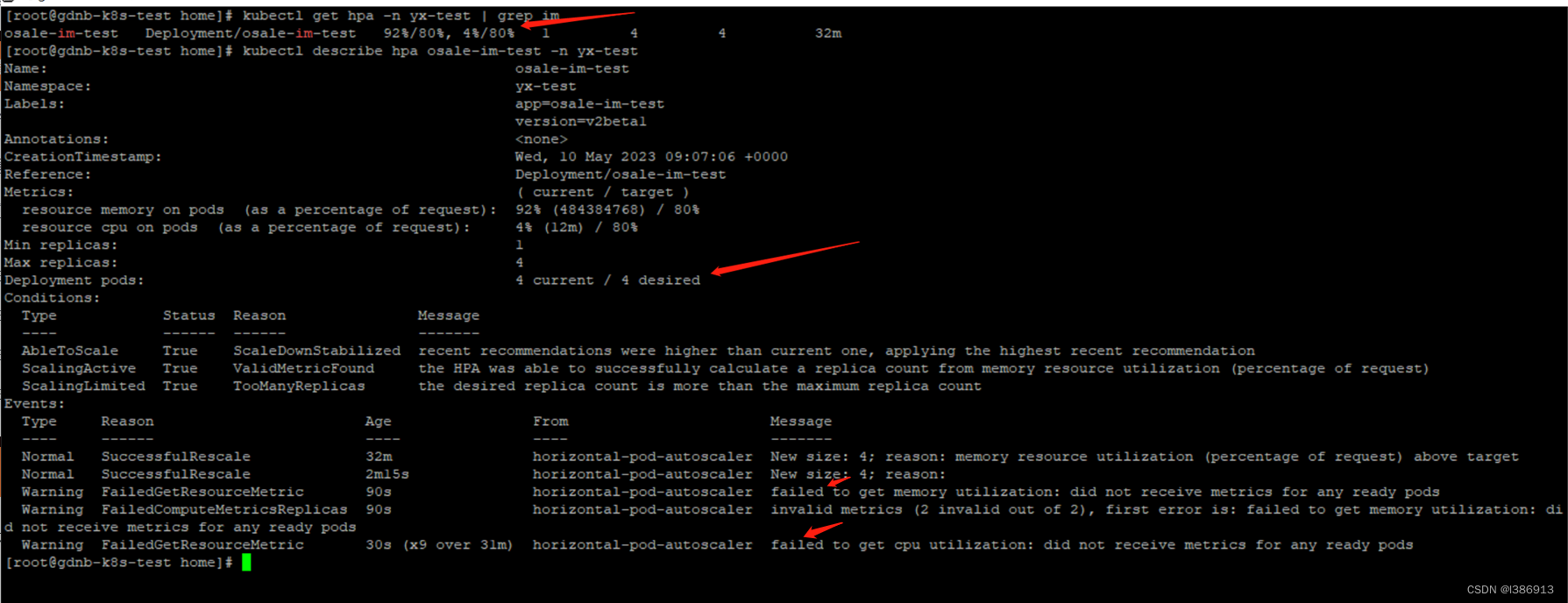
发现hpa已经超过了预定值,随之pod的副本数也变成了1个,最多可变成2个,停止负载后,副本数也会变成一个
如果出现了 failed to get cpu utilization: missing request for cpu 这样的错误信息。这是因为我们上面创建的 Pod 对象没有添加 request 资源声明,这样导致 HPA 读取不到 CPU 指标信息,所以如果要想让 HPA 生效,对应的 Pod 资源必须添加 requests 资源声明,
假如targets字段有显示unknown
原因:
刚建立,等待一段时间再查看
需要自动伸缩的目标资源并没有进行资源限制
3.hpa基于内存扩缩容
targetAverageUtilization 表示的是百分比
targetAverageValue 表示的是数值,比如100m的CPU、100Mi的内存
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: kevin-t-hap
namespace: lishanbin
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: f1
minReplicas: 1
maxReplicas: 2
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageValue: 30Mi
如上,设置了f1的deployment控制的pod的HPA限制,当cpu使用超过设置的80%,内存使用超过30Mi时就触发自动扩容,副本数最小为1,最大为2。
4.实际使用模板
apiVersion: apps/v1
kind: Deployment
metadata:
name: osale-admin-data-test
labels:
app: osale-admin-data-test
spec:
replicas: 1
revisionHistoryLimit: 10
selector:
matchLabels:
app: osale-admin-data-test
template:
metadata:
labels:
app: osale-admin-data-test
armsPilotAutoEnable: "on"
armsPilotCreateAppName: osale-admin-data-test
one-agent.jdk.version: "OpenJDK11"
spec:
imagePullSecrets:
- name: osale-secret
containers:
- name: osale-admin-data-test
image: gem-acr-p-a01-registry.cn-shenzhen.cr.aliyuncs.com/osale/osale-admin-data:test-2023-05-09-11-07-08
ports:
- containerPort: 8080
protocol: TCP
imagePullPolicy: IfNotPresent
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
resources:
limits:
cpu: 2
memory: 2Gi
requests:
cpu: 300m
memory: 200Mi
volumeMounts:
- name: logs
mountPath: /gemdale/logs
- name: data
mountPath: /gemdata/share/
volumes:
- name: logs
hostPath:
type: DirectoryOrCreate
path: /data/logs/test/osale-admin-data-test
- name: data
hostPath:
type: DirectoryOrCreate
path: /gemdata/share/
###############################
---
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: osale-admin-data-test
labels:
app: osale-admin-data-test
version: v2beta1
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: osale-admin-data-test
minReplicas: 1
maxReplicas: 4
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 80
- type: Resource
resource:
name: memory
targetAverageUtilization: 80
---
apiVersion: v1
kind: Service
metadata:
name: osale-admin-data-test
labels:
app: osale-admin-data-test
spec:
ports:
- port: 8080
targetPort: 8080
selector:
app: osale-admin-data-test
type: ClusterIP
kubectl get pods -n kube-system -l k8s-app=metrics-server #查看pod
kubectl logs -f metrics-server-f74785f7-tbk2c -n kube-system #查看日志
kubectl apply -f data.yaml -n yx-test --dry-run=client #验证模板可用性
kubectl top nodes
kubectl top pod -n yx-test #查看pod的内存和cpu使用率
kubectl get hpa -n yx-test | grep data #查看cpu和内存使用情况
kubectl describe hpa osale-admin-data-test -n yx-test #查看hap使用详细情况
kubectl delete hpa osale-admin-data-test -n yx-test #删除hpa控制器
#查看启动模板
kubectl get apiservice v1beta1.metrics.k8s.io -o yaml
kubectl get StatefulSet gem-yx-t-db1 -o yaml -n yx-test
kubectl get Deployment osale-admin-data-test -o yaml -n yx-test
request 资源声明,扩缩容基于启动时候的设置参数,所有这个一定要提前设置好,还有一个是
https://blog.csdn.net/fly910905/article/details/105375822/
遇到的故障获取不到cpu和内存信息
Metrics Server
在 HPA 的第一个版本中,我们需要 Heapster 提供 CPU 和内存指标,在 HPA v2 过后就需要安装 Metrcis Server 了,Metrics Server 可以通过标准的 Kubernetes API 把监控数据暴露出来,有了 Metrics Server 之后,我们就完全可以通过标准的 Kubernetes API 来访问我们想要获取的监控数据了:
比如当我们访问上面的 API 的时候,我们就可以获取到该 Pod 的资源数据,这些数据其实是来自于 kubelet 的 Summary API 采集而来的。不过需要说明的是我们这里可以通过标准的 API 来获取资源监控数据,并不是因为 Metrics Server 就是 APIServer 的一部分,而是通过 Kubernetes 提供的 Aggregator 汇聚插件来实现的,是独立于 APIServer 之外运行的。
kubectl logs -f metrics-server-f74785f7-tbk2c -n kube-system

我们可以发现 Pod 中出现了一些错误信息:xxx: no such host,我们看到这个错误信息一般就可以确定是 DNS 解析不了造成的,我们可以看到 Metrics Server 会通过 kubelet 的 10250 端口获取信息,使用的是 hostname,我们部署集群的时候在节点的 /etc/hosts 里面添加了节点的 hostname 和 ip 的映射,但是是我们的 Metrics Server 的 Pod 内部并没有这个 hosts 信息,当然也就不识别 hostname 了,要解决这个问题,有两种方法: 第一种方法就是在集群内部的 DNS 服务里面添加上 hostname 的解析,比如我们这里集群中使用的是 CoreDNS,我们就可以去修改下 CoreDNS 的 Configmap 信息,添加上 hosts 信息:
$ kubectl edit configmap coredns -n kube-system
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health
hosts { # 添加集群节点hosts隐射信息
10.151.30.11 ydzs-master
10.151.30.57 ydzs-node3
10.151.30.59 ydzs-node4
10.151.30.22 ydzs-node1
10.151.30.23 ydzs-node2
fallthrough
}
kubernetes cluster.local in-addr.arpa ip6.arpa {
pods insecure
upstream
fallthrough in-addr.arpa ip6.arpa
}
prometheus :9153
proxy . /etc/resolv.conf
cache 30
reload
}
kind: ConfigMap
metadata:
creationTimestamp: 2019-05-18T11:07:46Z
name: coredns
namespace: kube-system
这样当在集群内部访问集群的 hostname 的时候就可以解析到对应的 ip 了






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结