您现在的位置是:首页 >学无止境 >ByteHouse云数仓版查询性能优化和MySQL生态完善网站首页学无止境
ByteHouse云数仓版查询性能优化和MySQL生态完善
ByteHouse云数仓版是字节跳动数据平台团队在复用开源 ClickHouse runtime 的基础上,基于云原生架构重构设计,并新增和优化了大量功能。在字节内部,ByteHouse被广泛用于各类实时分析领域,最大的一个集群规模大于2400节点,管理的总数据量超过700PB。本分享将介绍ByteHouse云原生版的整体架构,并重点介绍ByteHouse在查询上的优化(如优化器、MPP执行模式、调度优化等)和对MySQL生态的完善(基于社区MaterializedMySQL功能),最后结合实际应用案例总结优化的效果。
在2023云数据库技术沙龙 “MySQL x ClickHouse” 专场上,火山引擎ByteHouse的研发工程师游致远,为大家分享一下《ByteHouse云数仓版查询优化和MySQL生态完善》的一些工作。
本文内容根据演讲录音以及PPT整理而成。

火山引擎ByteHouse的研发工程师游致远
游致远,火山引擎ByteHouse资深研发工程师,负责ByteHouse云数仓版引擎计算模块。之前先后就职于网易、菜鸟集团、蚂蚁集团,有多年大数据计算引擎、分布式系统相关研发经历。

ByteHouse云数仓版查询优化和MySQL生态完善
今天我主要分享的内容大纲,分为下面这四个部分。首先主要是跟大家讲一下ByteHouse云数仓版的背景和整体架构、然后重点讲下查询引擎上做的优化和完善 MySQL 生态的一些工作,最后是总结。
内容大纲
Clickhouse 是基于 shared nothing 架构,这种架构也带来了比较极致的性能。字节跳动的话,从2018年就开始在线上 使用 Clickhouse,然后到现在已经是非常大的机器量和数据量。但是 Clickhouse 的shared nothing 架构,也给我们带来了很大的困难,主要是数据的扩缩容比较难,包括存储和计算资源的绑定,导致我们想做一些弹性的伸缩也比较难。然后读写不分离带来的影响,以及在公共集群上中小业务的查询的影响。
为了彻底解决这个问题,然后我们在2020年的时候,开始做一个基于云原生架构的Clickhouse,当时内部的代号叫CNCH,现在在火山上叫ByteHouse云数仓版。然后现在CNSH在内部也是有非常大的使用规模,到2022年的时候,我们决定把这个回馈给社区,当时跟 Clickhouse 社区也进行了一些讨论,后来觉得架构差异太大,然后就单独以ByConity项目开源了,在今年1月份已经在GitHub上开源了。欢迎大家去关注和参与一下。

Clickhouse基于shared nothing架构
下图就是 ByteHouse云数仓版的整体架构,这是比较经典的架构。服务层负责就是数据,事务查询计划的协调,资源的管理。中间这层是可伸缩的计算组,我们叫做virtual warehouse(VW),也叫虚拟数仓,业务是可以按virtual warehouse进行隔离,相互不会影响,可以随意的扩缩容,是一个无状态的计算资源。最下面是数据存储,我们是抽象了虚拟的文件层,可以支持HDFS,以及还有对象存储S3等。当然在实际查询的时候,就是我们也会做一些热数据的local cache.
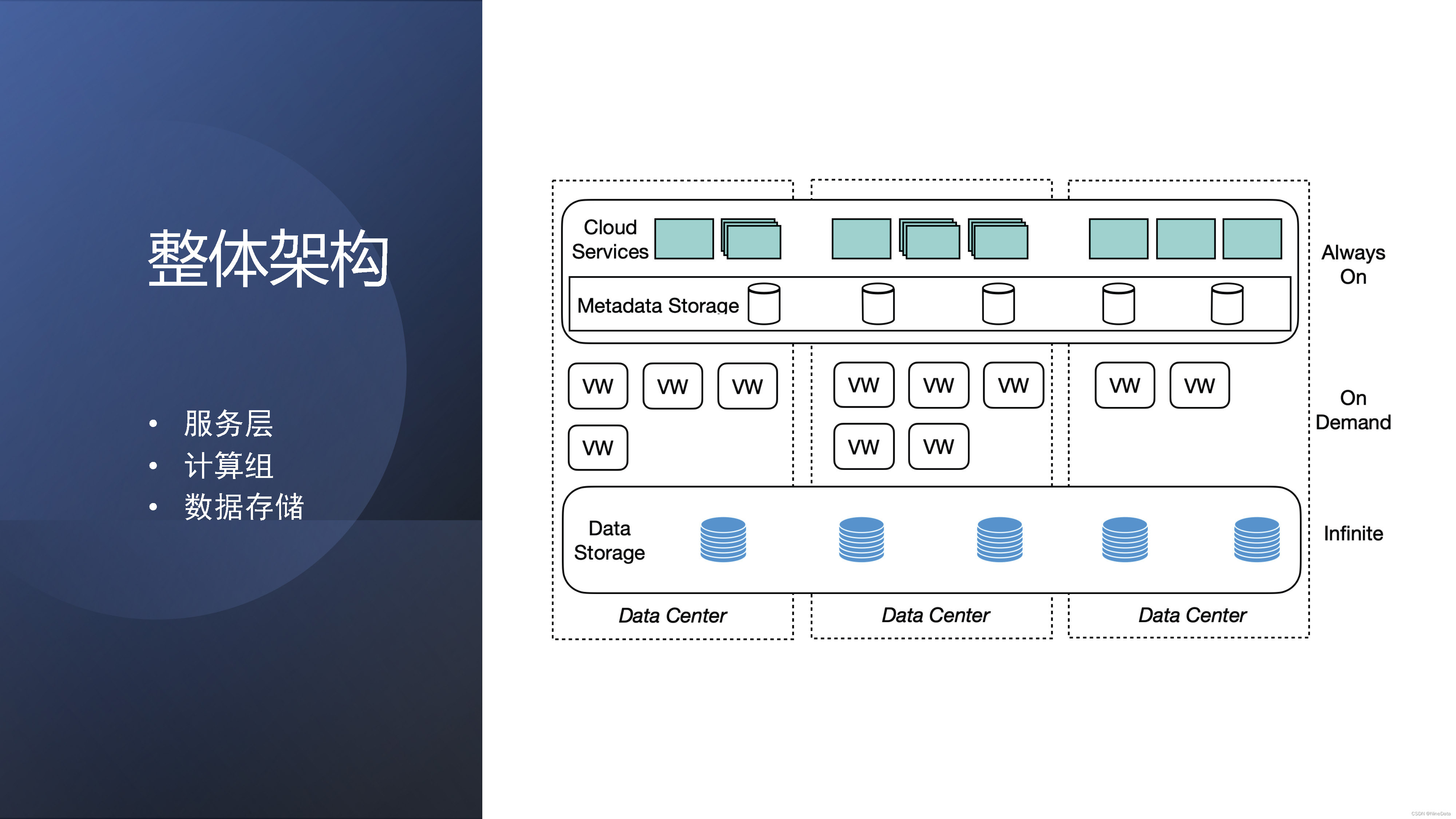
ByteHouse云数仓版的整体架构
下面重点来讲我们在查询引擎的优化。我们知道ClickHouse的单机执行非常强,然后这个是2021年的ClickHouse的单机执行逻辑,非常简单的count(*)的聚合运算。ClickHouse 首先会生成一个逻辑计划,叫QueryPlan。这里可以通过 EXPLAIN 看到每一步,就query plan step,就是读表,然后做聚合。

ClickHouse的单机执行
然后再通过 QueryPlan 会生成一个 QueryPipeline。这个过程中可以看到,query plan step被翻译成了QueryPipeline里面的一步,叫做processor,或者叫做物理算子。

QueryPlan 会生成一个 QueryPipeline
ClickHouse的单机模型其实是非常的强的,然后整体Pipeline驱动模式可以参考下面这个图,这里就不再具体展开。
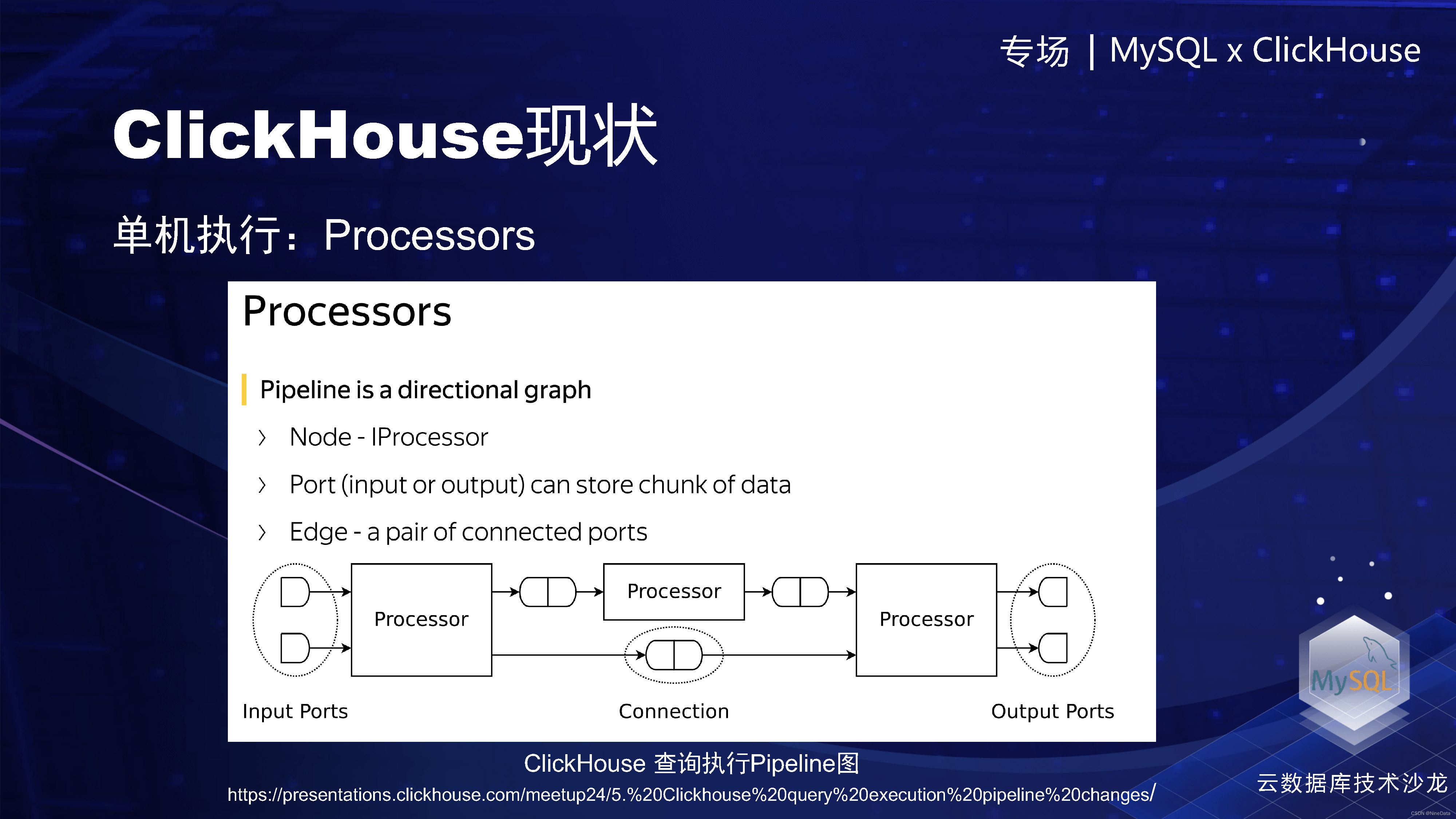
ClickHouse的单机模型
接下来我们就看下另外一个场景,分布式执行。这是一个分布式表,然后有三个分片。做一个简单的count,在ClickHouse这块的话,就是把它改写成三个本地执行的子查询,然后分别计算,生成中间的Partial merge result,最后在coordinator节点上进行聚合,最后生成一个完整的结果返回给用户。
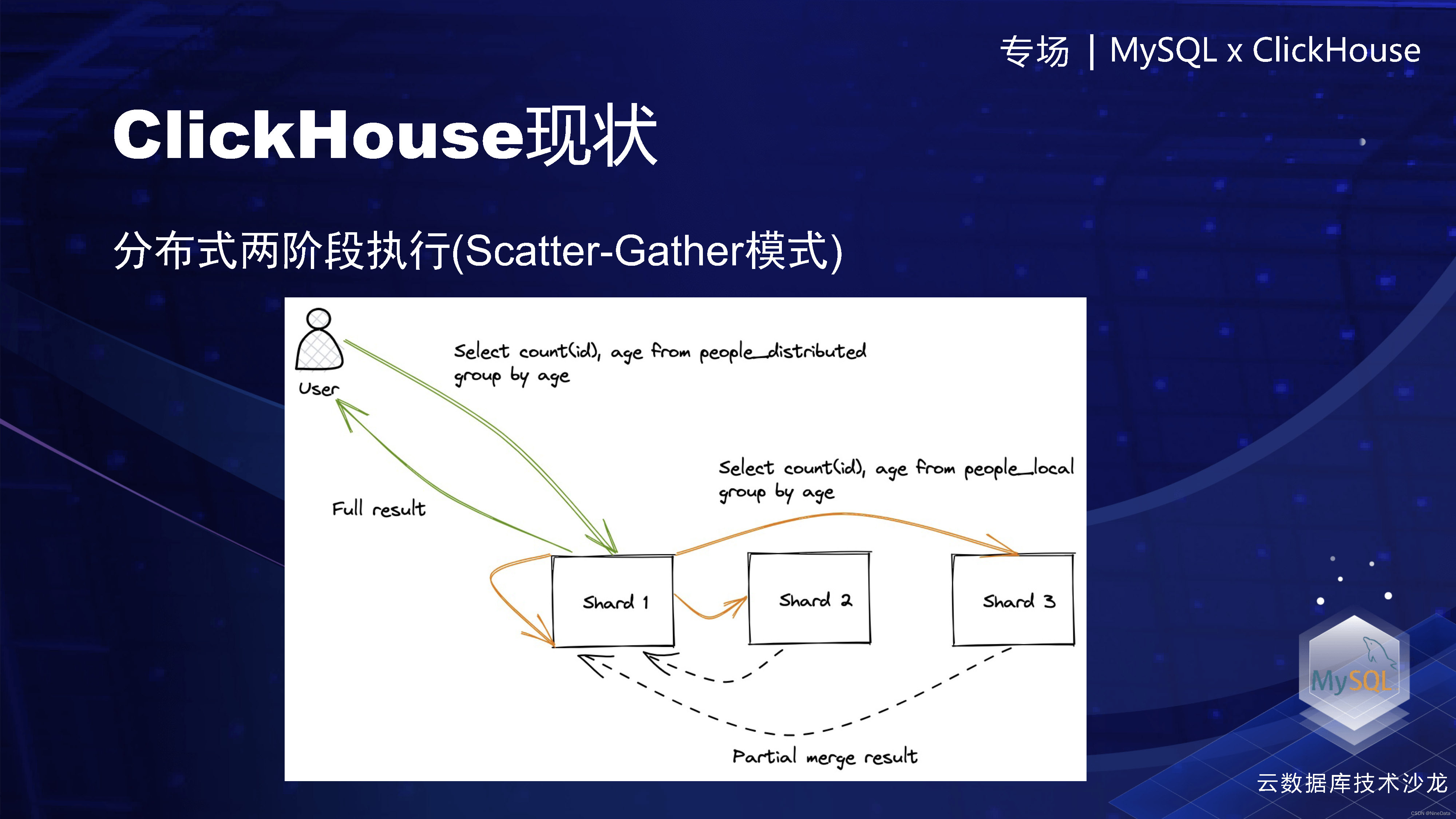
ClickHouse分布式执行
这个模型特点就是非常的简单,然后实现起来也是非常高效,但是在实际业务中也发现一些缺点。首先对于两阶段的话,第二个阶段的计算如果比较复杂,Coordinator 的计算压力会非常的大,很容易出现瓶颈。在聚合运算的时候,比如count distinct的经常会出现OOM或者算不出来,它整个架构是没有Shuffle的。如果有Hash Join,右表的大小不能放到一个单机的内存里面,基本上就是跑不出来。整个计划层的话,下发ast或者sql的方式,表达能力是非常有限的,我们之前是想基于这个做一些复杂优化,也是不太好做,灵活度也比较低。最后的它只有一个基于规则的优化,像一些比较重要的join reorder的排序也是没法做。

ClickHouse模型的优缺点
基于上面提到的问题,我们是基本上重写了分布式执行的查询引擎。主要做了两点,一个是就是支持多阶段执行,这也是大部分主流的MPP数据库,以及一些数仓产品的做法。第二个我们自研的整个优化器。下面是一个比较完整的执行图。可以看到,相比于刚才二阶段执行,一个查询过来之后,他的第二阶段就是Final agg可以在两个节点上了。TableScan做完之后,通过一定的规则进行shuffle。这个是通过exchange。然后最后的结果再汇集到Coordinator。当然这里还有ByteHouse云数仓的一些其他组件,这里不再细讲。
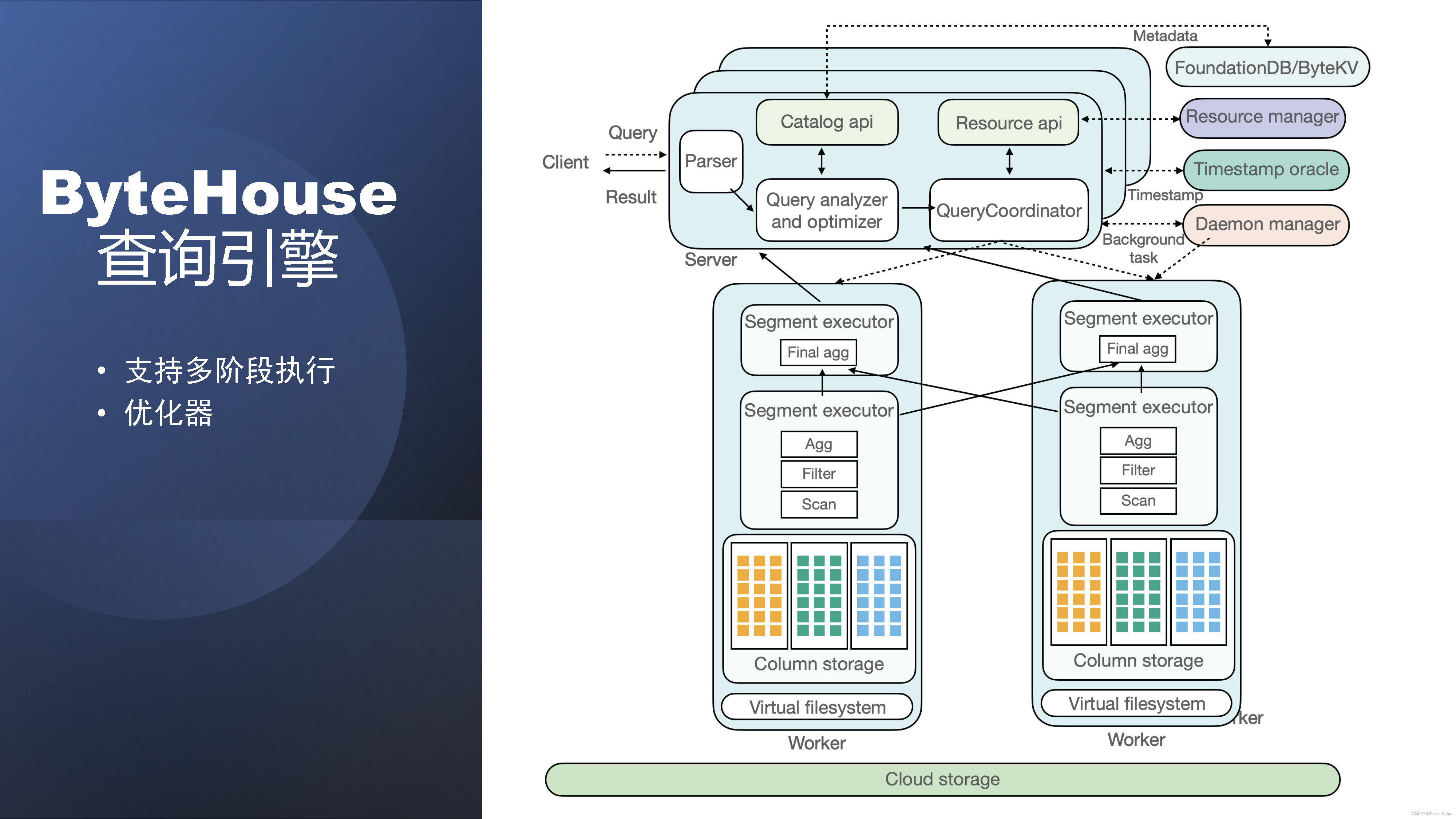
ByteHouse分布式执行的查询引擎
为了支持多阶段的执行模型,我们就引入了PlanSegment。简单说就是每一个worker上的一段逻辑的执行计划。从实现上来讲,它其实就是单机计划的QueryPlan,再加上输入输出的一些描述。然后这边就是PlanSegment的介绍,输入的PlanSegment和输出要到输出到哪个PlanSegment。

多阶段的执行模型概念PlanSegment
了解PlanSegment之后,可以就会问这个PlanSegment是从哪里来的。其实刚才介绍了,就是通过优化器进行计划生成和优化得来的。整体的一个流程就是从Parser把一个SQL变成了一个AST(抽象语法树),然后在优化器这个模块里面,在interpreter里面变成了一个PlanSegmentTree,切分成一组PlanSegment再下发给各个worker。
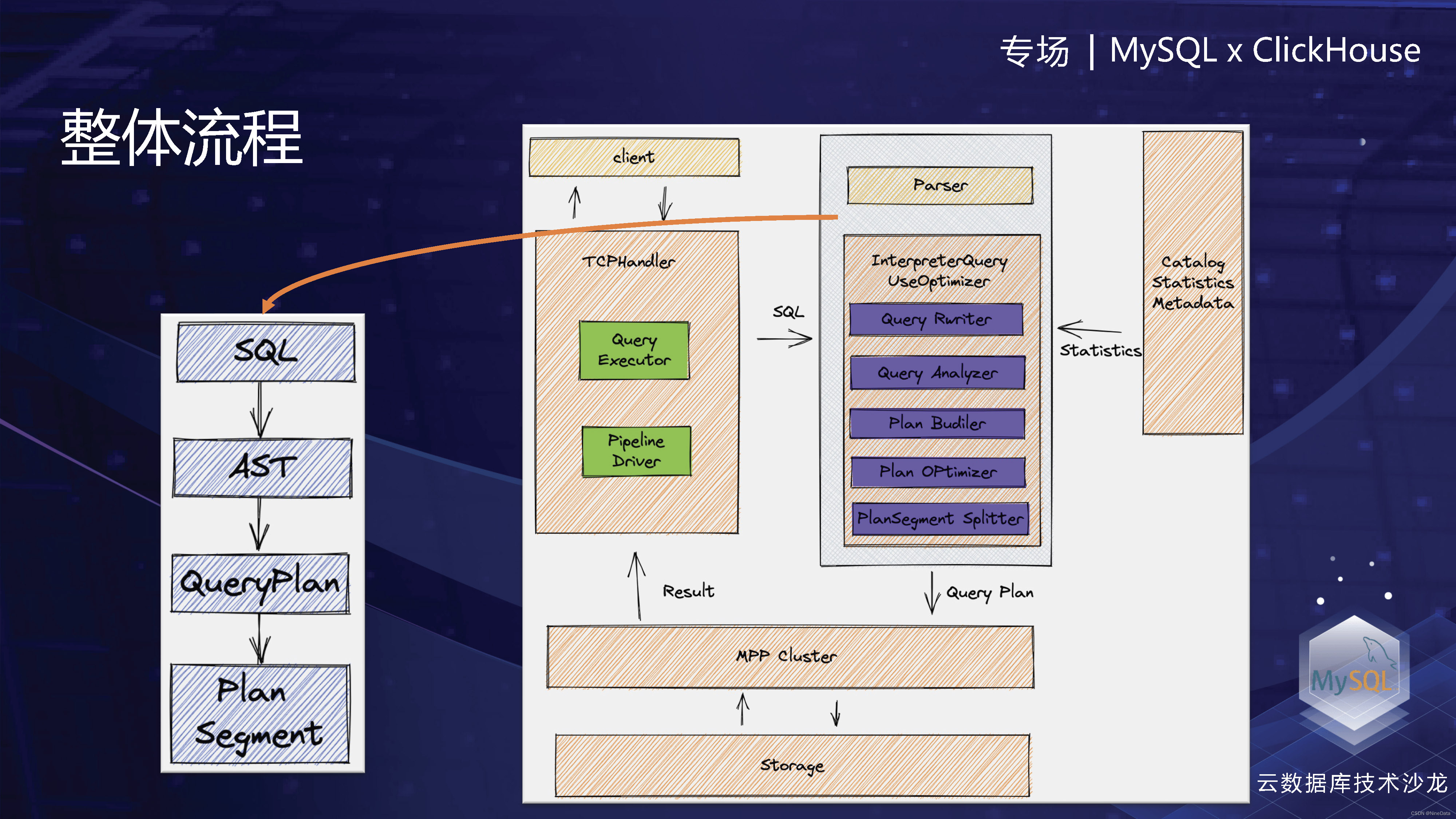 PlanSegment整体流程
PlanSegment整体流程
优化器,主要就是查询计划的变换。分为rule based optimizer和cost based optimizer,就是基于规则和基于代价。基于规则的话,我们是实现了一个种基于visitor的一个改写框架,主要做一些全局的改写,支持从上到下,从下到上的方式,包括一些condition的下推,还有SQL指纹,这种像需要正则化SQL的。我们还支持基于局部的pattern-match改写,例如。发现两个Filter是相连的,那就会到合并到一起,Projection也是类似的做法。

优化器RBO
CBO,下面是一个通用的CBO的框架。当一个查询计划过来的时候,我们会通过optimizer Task的规则,和Property来不断的扩充这个grouping。中间这个是memo,记录等价的QueryPlan。然后把所有的QueryPlan生成之后,根据计算的代价,最后选择代价比较低的作为输出。当然在具体实现的时候,其实是有很多考虑,会包括生成的时候怎么降低等价plan的数量,以及怎么在生成的同时选择分布式计划最优方案。
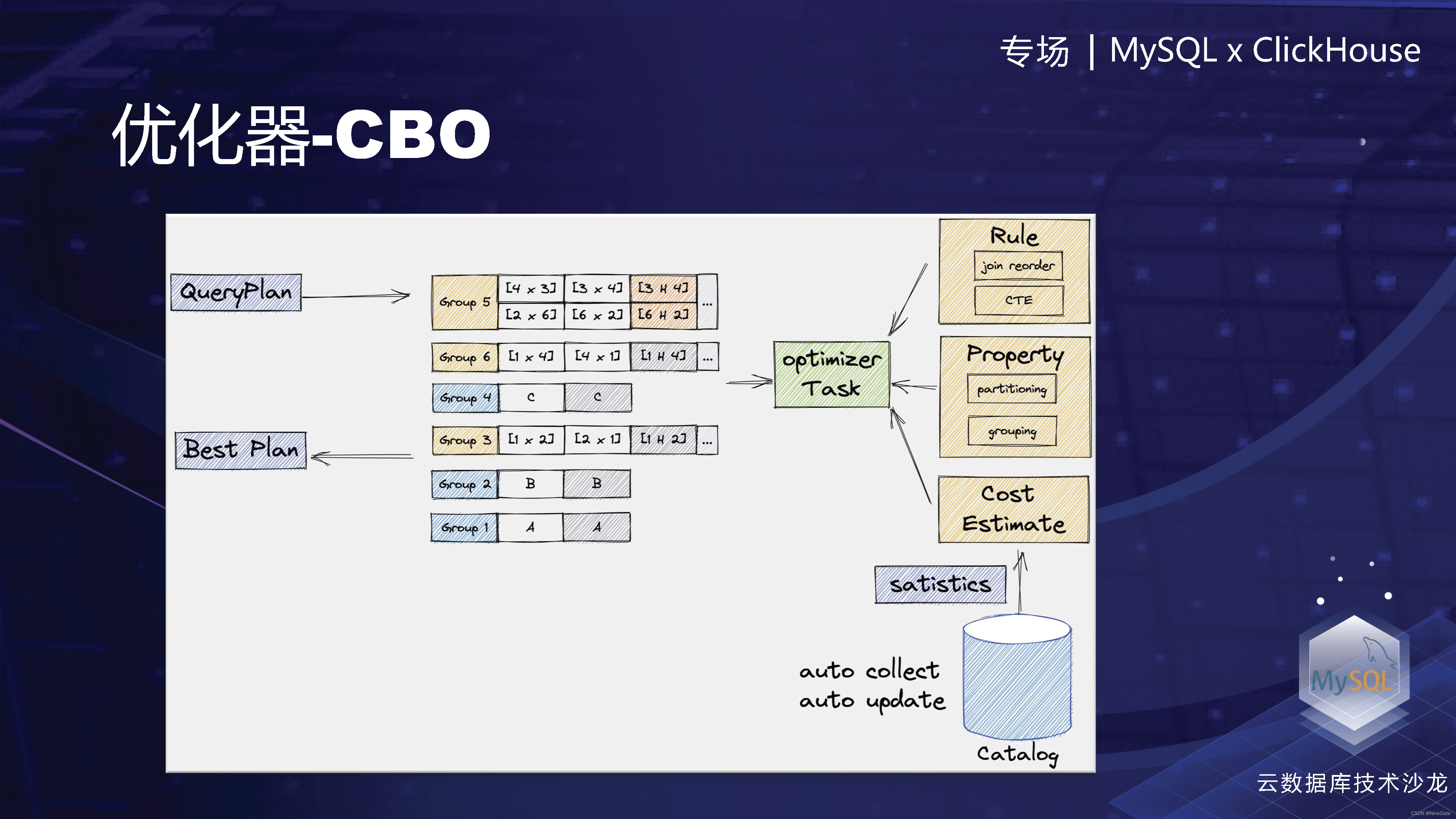
优化器CBO
当优化器生成了PlanSegment的时候,就涉及到该如何下发。下面就是我们的调度器模块。当查询生成完一组PlanSegment之后,我们可以根据调度的类型,现在我们主要是MPP的多阶段执行。就会把它生成一个子图一次下发,后面也会考虑其他的一些调度方式,根据任务类型,包括类似于Spark的BSP,或者是分阶段调度。生成完这个一个子图的调度之后,马上就要选择PlanSegment到哪些worker执行?
这里的话。就是刚才讲service层,congresource manager拿各个worker层的负载信息,调度source的话,我们是主要考虑缓存的亲和度;然后调度计算plansegment的话是worker可以纯无状态,我们是主要考虑负载,就是尽量保证负载均衡来进行调度。这里也是尽量避开一些慢节点,以及一些已经死掉的节点。当然我们也在做其他的调度的方式,就是一些资源的预估和预算。这个具体解决问题可以后面再讲。我们生成完PlanSegment,然后发给worker之后,它的执行就是刚才讲的clickhouse的单机执行了。
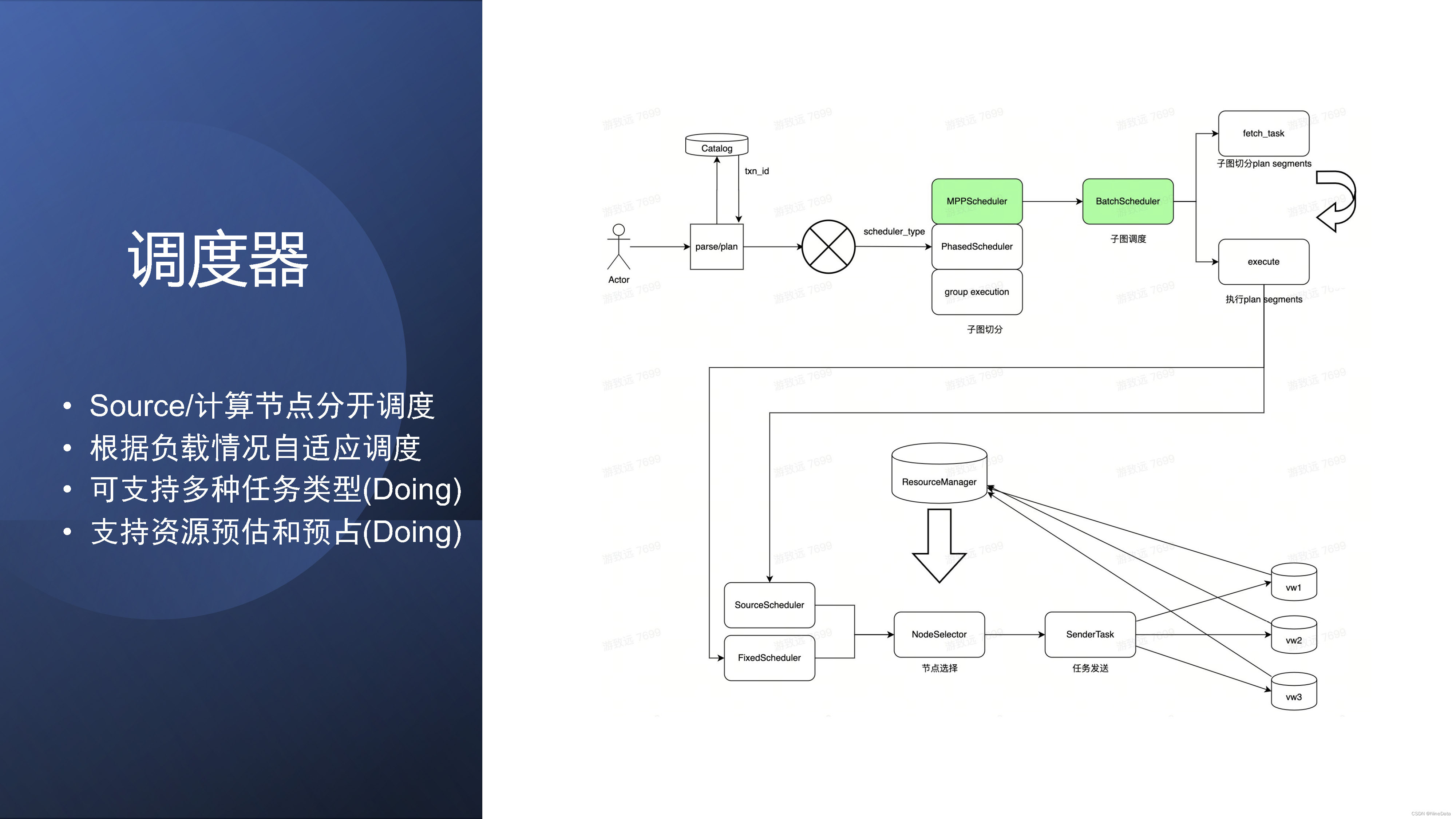
调度器模块
刚刚提到一点,就是数据的就是的传入和传出,这个是依赖于Exchange模块。Exchange就是数据在PlanSegment的实例之间进行数据交换的逻辑概念,从具体实现上的话,我们是把它分的数据传输层以及算子层。
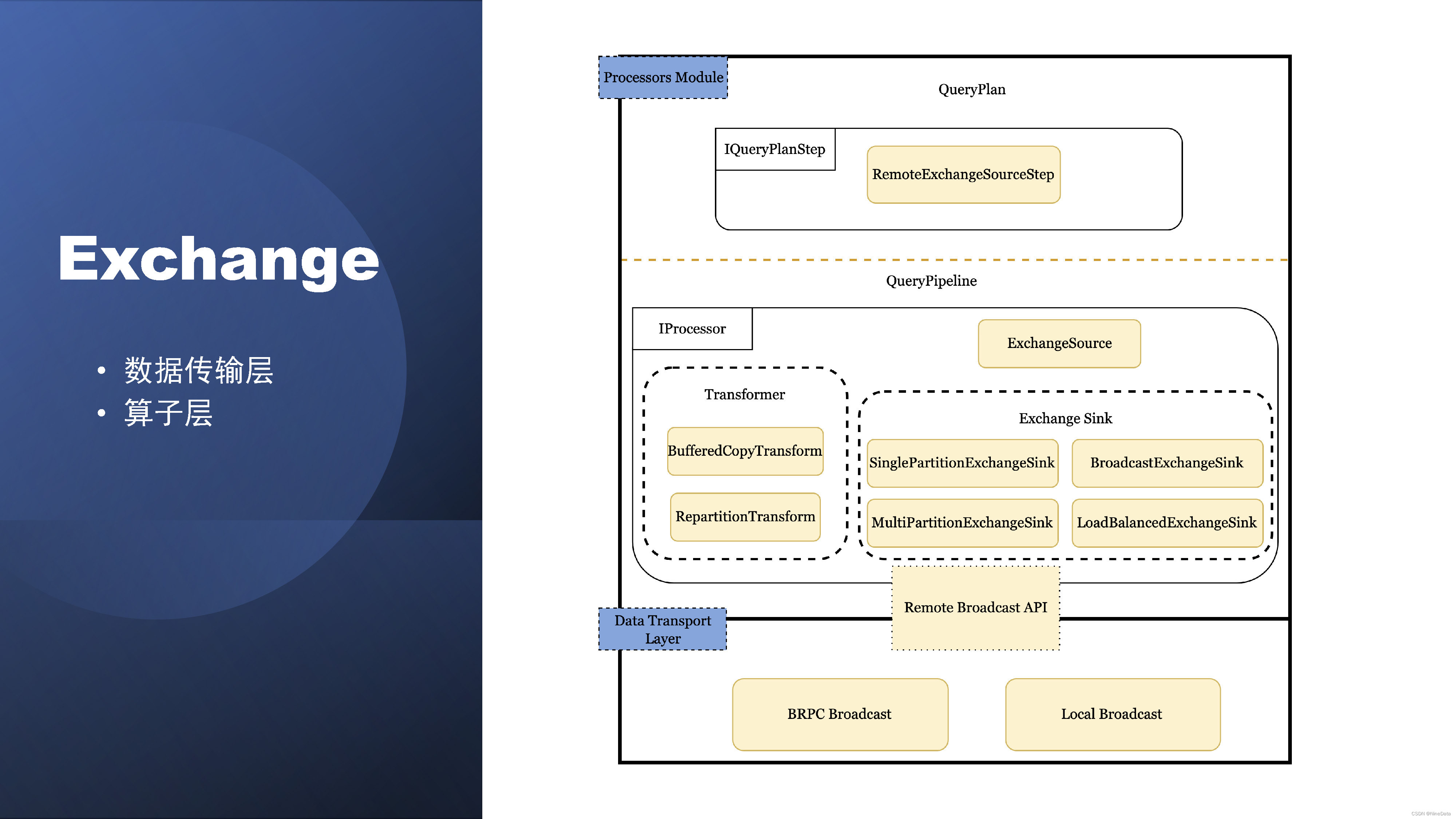
Exchange模块
数据传输层的话,其主要是基于定义Receiver/ Sender的接口,然后同进程传输基于队列,跨进程是基于基于BRPC Stream,支持保序、状态码传输、压缩、连接池复用。连接池复用、简单来说,就是把大集群上的两个节点之间的只建立一个连接,所有的查询都在这个连接上通信,当然我们是连接池,所以实际上是两个节点之间是固定数量的一个连接,这样会比单连接的稳定好更高。
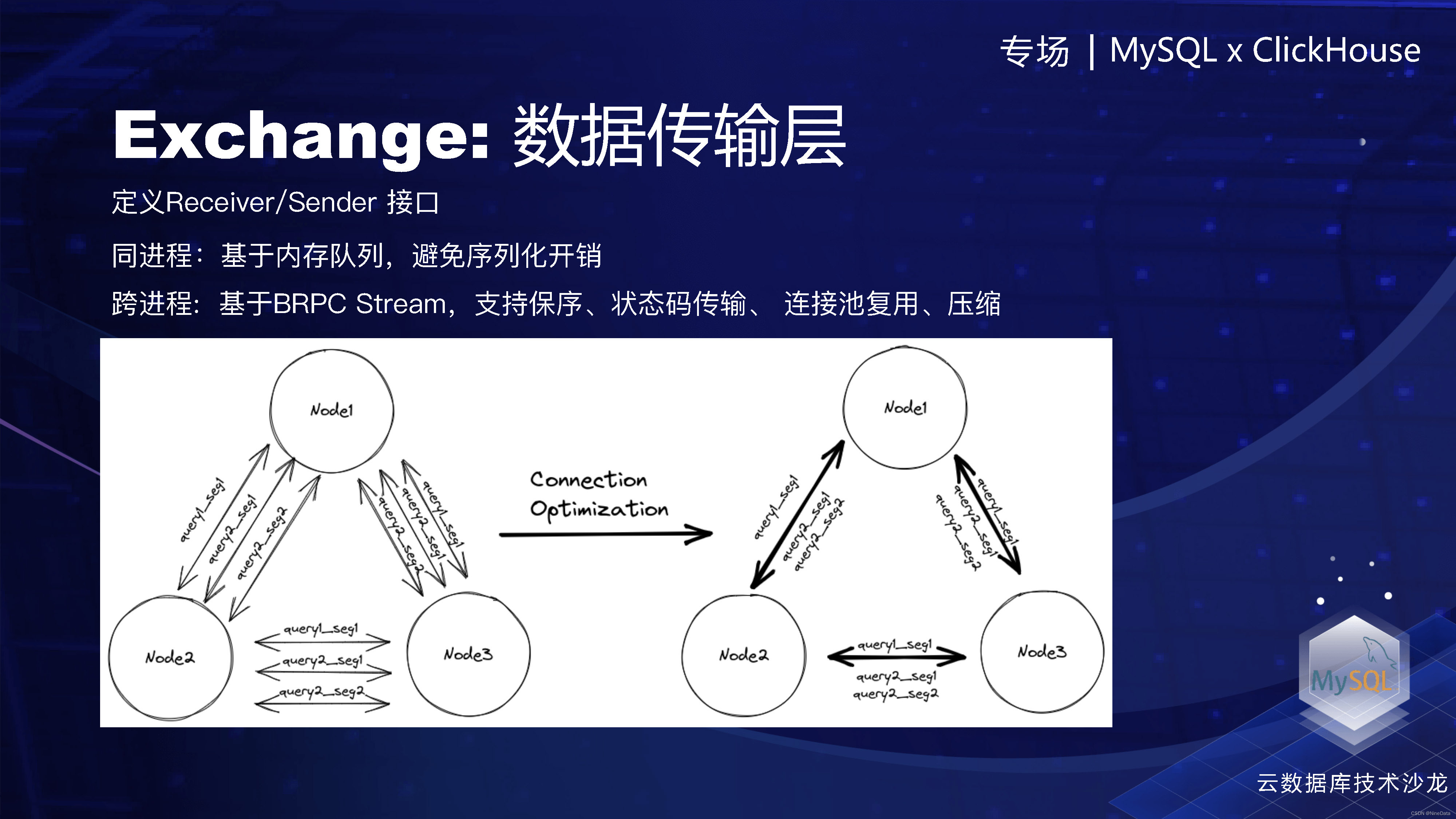
Exchange数据传输层
算子层的话,我们是支持了四种场景。一个是一对多的Broadcast。然后多对多的Repartition,以及是多对一的Gather,一般在本进程之间的Round-Robin。这里面也做了一些优化,包括Broadcast怎么样避免重复的序列化,然后Repartition怎么提升性能,以及sink怎么攒批。在大集群下,怎样通过一个ExchangeSouce读取多个receiver的数据,来降低线程数。

算子层
这里是比较高阶的一些优化点,第一,RuntimeFilter 就是在执行期间生成的动态filter,比如这是两张表的一个等值join。我们可以在右表构建哈希table的时候,会生成一个bloom filter(或者其他类型的filter)。然后把各个worker上的bloom filter的收集后merge成一个,然后再发给左表所在的worker,这样在左表进行table scan的时候,可以过滤掉非常多不必要的数据,然后也可以节省一些计算的资源。这个的话需要优化器整个参与决策,因为生成和传输过程也是有代价的,看哪个代价更低。或者他还会判断一下过滤能力。
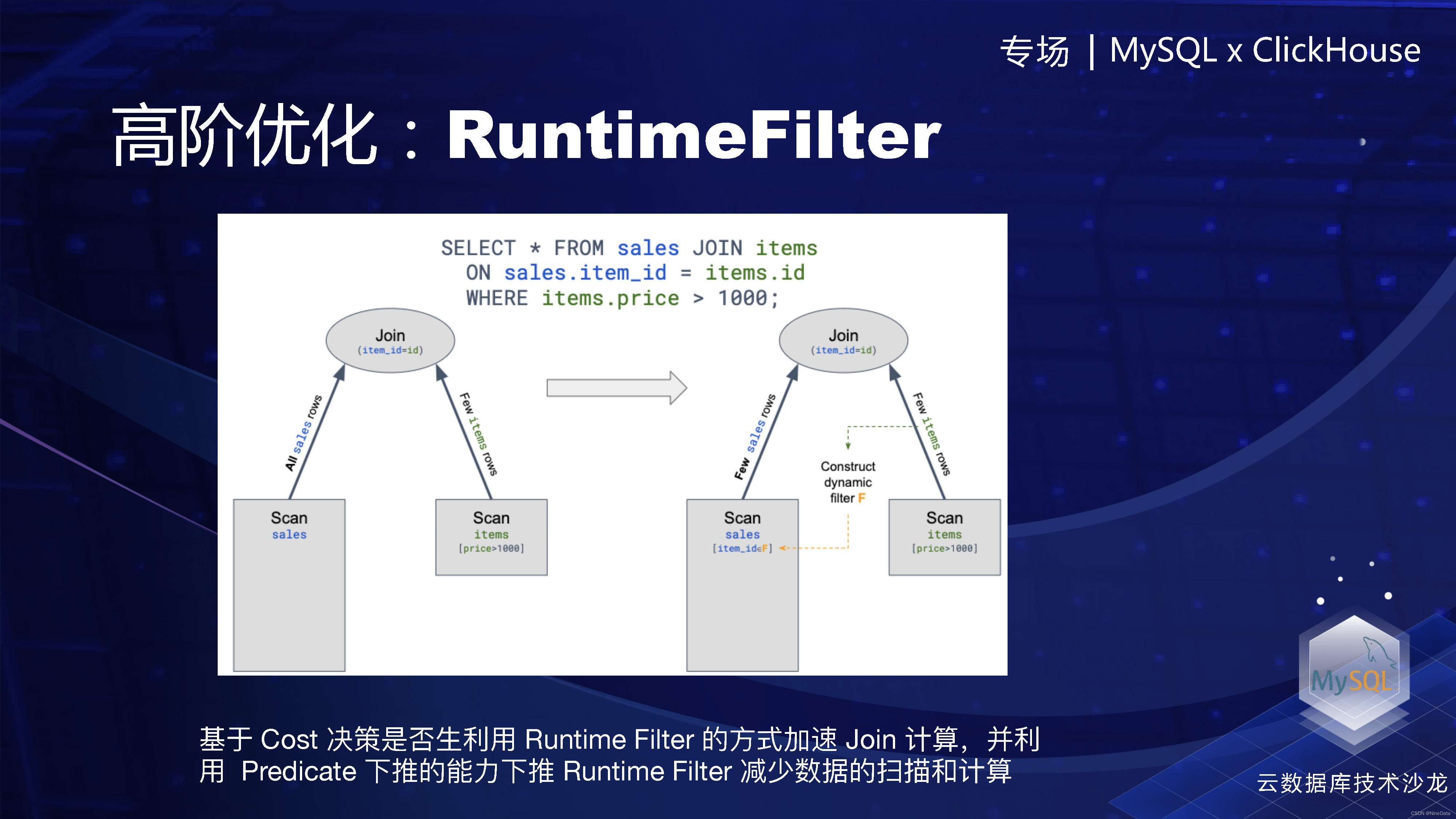
高阶优化:RuntimeFilter
另外就是在执行层的话,我们有一些压缩算法的优化,就比如说表级别的全局字典。我们知道社区有一个低级数类型,它的字典是part级别的,已经可以在一些计算上做到不解压计算了,当我们扩展成表级别的时候,大部分的计算都可以直接在编码值上或者在字典上进行,就完全不需要去解压数据了,甚至传输也可以传输编码后数据的。函数计算,聚合运算也是,这块在TPCDS上应该有20%的提升。

高阶优化:表级别的全局字典
其他的优化,这里可以简单的说一下,包括Windows算子的并行化,然后Windows里面 Partition 的 top下推;公共表达式的复用;以及现在多阶段模型下,对社区为两阶段模型实现的aggregation、join的算子做了一些重构,为了更好的适应这个模型。我们还支持Bucket Join、简单查询上并发性能的优化。最后就是ClickHouse单机模型的缺点,就是它每个Pipeline是独立的线程池,当并发比较高的时候线程会比较多,上下文的切换的开销比较大。我们会把它做成协程化,避免过多的线程。

其他优化详情
这是整体的一个效果。然后在社区的两阶段,我们通过改写,能跑完26个SQL。我们在多阶段执行和优化器完成之后,基本上是整个TPC-DS的99个SQL都是可以跑完的,性能也是得到了极大的提升。

整体效果
然后下面讲一下过程碰到的挑战,以及没有解决的问题。第一个就是所有并行计算框架的老大难问题:数据倾斜。如果比较有热点key,或者聚合件里面的key过少的话,即使有再多的worker,最后也只会在一个worker上进行计算。计划层,其实是可以做两阶段聚合的调整,然后把key过少的问题可以解决,但是热点key的问题还是很难解决,其实可以在执行层做一些自适应的执行,这个还是在探索阶段,可能类似于Spark的AQE,但是因为MPP的话有很多限制,做不到这么完善。

数据倾斜
第二个挑战,超大的MPP集群的问题。业内的话一般超过200个的MPP集群,就是会碰到一些比较多的慢节点的问题,或短板效应导致线性度急剧下降,稳定性也会下降。我们在内部已经有大概将近800个节点的计算组,然后可能马上就会有超过上千个节点的一个计算组。是要怎么样保证这种大超大MPP集群的稳定性和性能,我们做了一些自适应的控制,提高整体的稳定性。就我刚才讲的自适应调度、资源的预估和预占是一个方面,另外就是限制每一个查询的复杂度和使用资源,避免大查询导致把某个work的资源就是占的过满,然后导致的慢节点。最后一个就是对用户无感的一个VW的一个自动划分,划分一些小的子集,这个子集的话是固定的,是为了保证cache的亲和度,我们会根据查询的大小来自动的选择,这个也算规避了超大的问题。

超大的MPP集群
最难的还是怎么构建容错的能力,在这种大集群情形下,如果假设每一个节点的错误率为e的话,那节点数量为N的话,那运行正常概率就是(1-e)^N。节点数量扩大,错误率就会指数级上升。我们在探索就是query的状态的snapshot,类似于flink异步的snapshot的方案,可以构建一定的恢复能力,另外一个我们是有bucket table,就是会有一些计算是在闭合在bucket内部的,某一个bucket失败可完全不影响其他bucket,是可以单独去重试的。这是我们碰到的两个主要的挑战。

构建容错的能力构建容错的能力
这个专场是关于MySQL和ClickHouse,我们也讲一下ByteHouse在MySQL生态上做的一些事情。我们知道把从MySQL数据导入到ClickHouse的话,主要现在有三种方案。一种是ClickHouse的MySQL表引擎,你可以直接通过数据库引擎建一个MySQL的外表,然后用insert select的方式一次性的把数据导入,但是有数据量的限制不能太大,也不能持续的同步。其实在GitHub上有开源的工具,它是基于binlog同步的。但这个操作是比较复杂的,然后并且在已经停止更新了。社区最近是开发了一个materialized MySQL的一个功能。这个我认为是未来的一个最佳实践。

MySQL数据导入到ClickHouse
Materialized MySQL的话,它的原理也比较简单。用户的话就是创建一个 Materialized MySQL的数据库引擎,这样ClickHouse会有后台的一个线程,然后异步的去拉取MySQL的Binlog。然后会写到一个Replacing MergeTree里面。这个为什么要用replacing MergeTree,因为它是可以进行逐渐的去重。它虽然是那种异步的,但也是可以近似的完成去重工作。然后ClickHouse是做了一些trick,就是在这个replacing MergeTree里面可以给同步的Binlog加两个字段,一个是sign,一个是version,然后后续replacing MergeTree,就依靠这两个字段会进行一些去重,sign表示的是。数据的是否删除,version代表的是这次数据的版本,如果你加了final的话,它会就是在查询的时候,会用最高的版本覆盖低的版本。
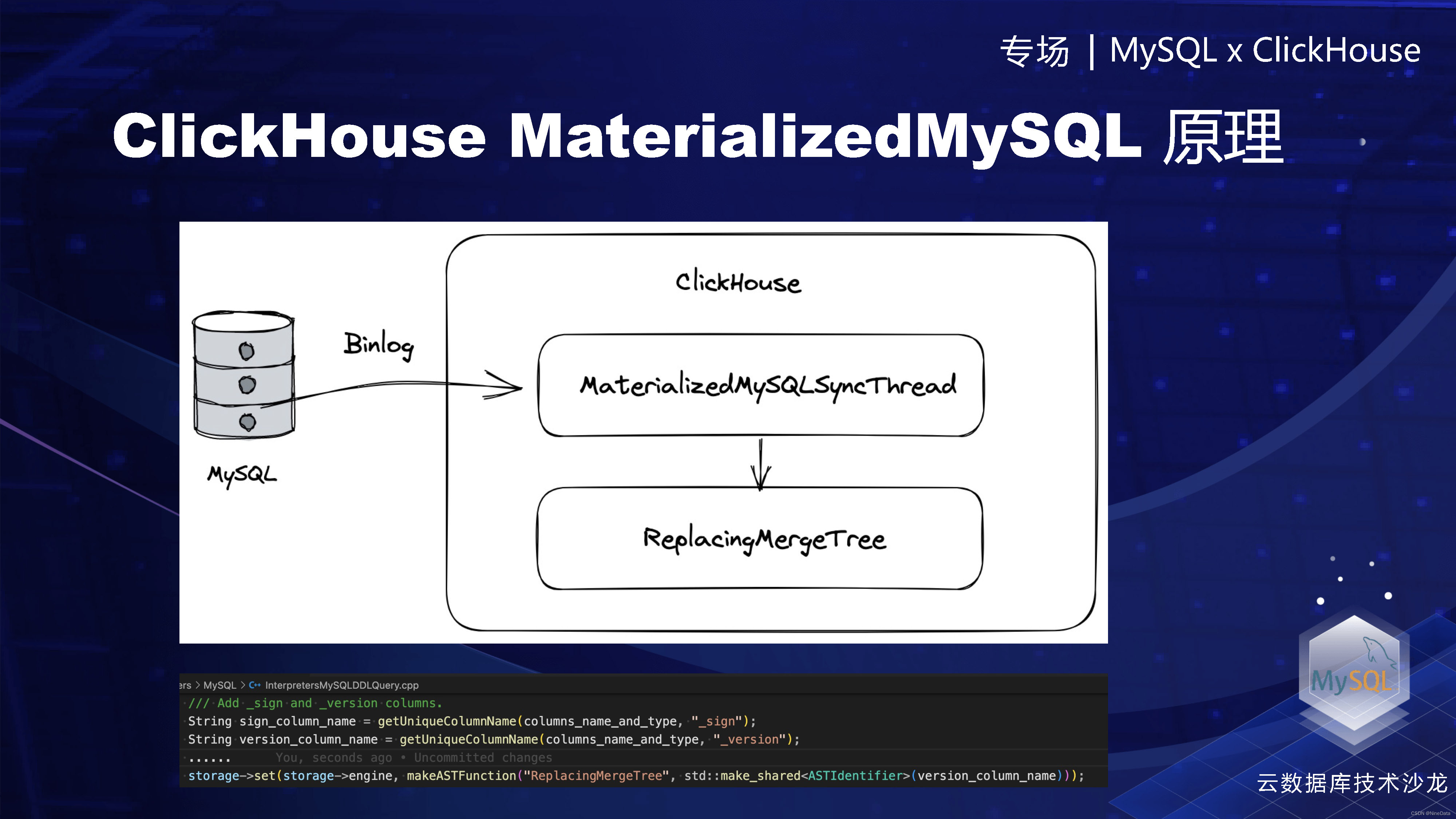
Materialized MySQL的原理
这个介绍大概的使用,用户从Materialized MySQL的数据库引擎。在ClickHouse里面创建,然后在MySQL里面通过insert语句去写入各种数据,你在ClickHouse里面可以查到,当然还有一些没有展示,就是你在Materialized MySQL里面去创建一些表。然后也会动态的在ClickHouse这边生成,就是DDL的也可以同步过来的。刚才我为啥说这个是未来的最佳实践,因为这个还是实验性的功能,它会有很多不完善的地方。

Materialized MySQL的数据库引擎
首先,它是不支持不兼容的DDL,只要有一个报错,然后整个同步就停止了,然后停止又是悄无声息,你没有办法去手动的去触发它的再同步。第二点,就是社区的Materialized MySQL的replacing MergeTree其实是一个单机引擎,只能在单点上同步,如果出现一个单节点的故障的话,就是高可用会成为问题,另外单节点也会有吞吐量的限制。第三个就是刚才讲的运维的困难,看不到同步的状态、现在同步的信息、以及没有同步重启的任务。

Materialized MySQL的优势和不足
然后ClickHouse的做了一个CNCH的Materialized MySQL的数据库引擎,也是把引擎给云化,修复了社区的一些缺陷,真正做到的生产可用。它的原理主要就是通过我们的service层,按照表的力度去在各个worker上去调度线程,写到我们的唯一键引擎里面。
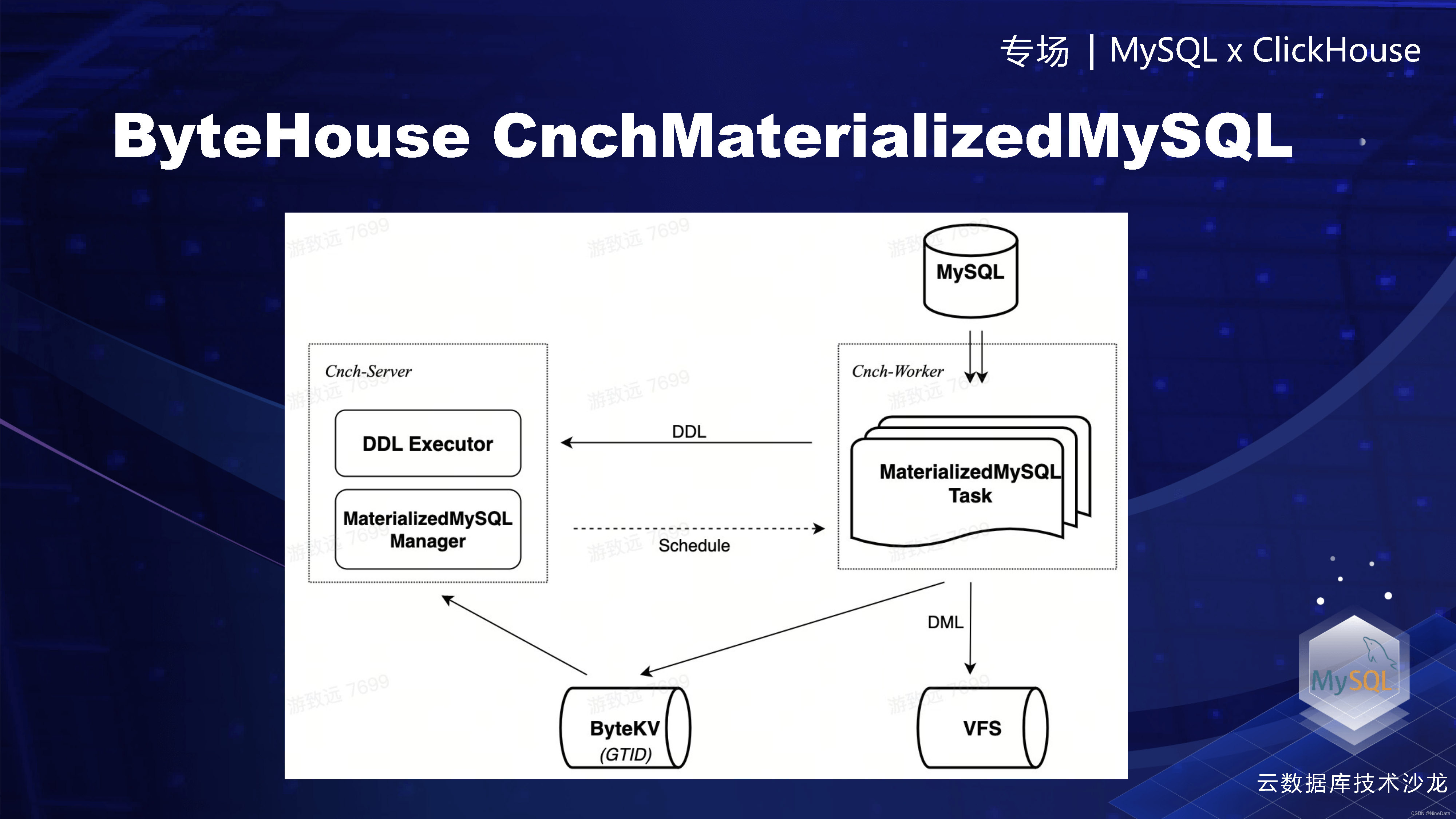
Materialized MySQL的数据库引擎原理
现在讲一下解决的这些问题,第一个有非常详细的系统表,可以看到现在运行的状态。然后也有停止启动重启的各种指令,就是这个整个运维是可用了。我们支持按表多worker的并发消费。因为是基于原生的架构,存算分离,如果单个work失败,可以马上自动的重新调度Rebalance。最后我们是基于唯一键引擎,它是为读优化的,就查询性能会更好。最后是支持配置跳过不兼容的DDL。做了这些工作之后,我们这个引擎基本上是可以说是生产可用了。

CnchMaterialized MySQL解决的问题
总结一下,今天的一些主要的内容吧,就是主要给大家讲了一下,ByteHouse云数仓版的背景以及整体架构。第二部分是重点讲了在查询引擎上的整体设计和优化点。最后讲了一下我们生产可用的云数仓版的Materialized MySQL的表引擎,为了完善MySQL生态做的一些工作。

2023首届云数据库技术沙龙 MySQL x ClickHouse 专场,在杭州市海智中心成功举办。本次沙龙由玖章算术、菜根发展、良仓太炎共创联合主办。围绕“技术进化,让数据更智能”为主题,汇聚字节跳动、阿里云、玖章算术、华为云、腾讯云、百度的6位数据库领域专家,深入 MySQL x ClickHouse 的实践经验和技术趋势,结合企业级的真实场景落地案例,与广大技术爱好者一起交流分享。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结