您现在的位置是:首页 >学无止境 >Flink Join操作网站首页学无止境
Flink Join操作
目录
DataStream API(函数编程)
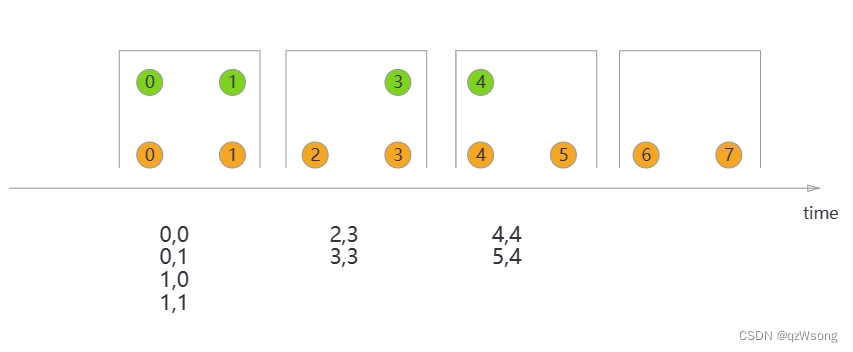
window Join
join
对处于同一窗口的数据进行join
时间类型:processTime、eventTime
问题:1、不在同一窗口的数据无法join,
2、只能inner join
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
...
DataStream<Integer> orangeStream = ...
DataStream<Integer> greenStream = ...
orangeStream.join(greenStream)
.where(<KeySelector>) // 左侧key值
.equalTo(<KeySelector>) // 右侧key值
.window(SlidingEventTimeWindows.of(Time.milliseconds(2) /* size */, Time.milliseconds(1) /* slide */)) // 开窗方式 tumbing/sliding/session
.apply (new JoinFunction<Integer, Integer, String> (){
@Override
public String join(Integer first, Integer second) {
return first + "," + second;
}
});
coGroup
coGroup是join的底层方法,通过coGroup可以实现inner/left/right/full 四种join
时间类型:processTime、eventTime
问题:不在同一窗口的数据无法join
interval Join
为了解决window join的问题:处于不同窗口的数据无法join
时间类型:eventTime
interval join :根据左流的数据的时间点,左右各等待一段右流时间,在此范围内进行join
问题:只能是以左流为时间线,因此只支持inner join
latedata.coGroup(stream)
.where(a->a.getStr("a"))
.equalTo(a->a.getStr("a"))
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new CoGroupFunction<JSONObject, JSONObject, Object>() {
@Override
public void coGroup(Iterable<JSONObject> iterable, Iterable<JSONObject> iterable1, Collector<Object> collector) throws Exception {
}
})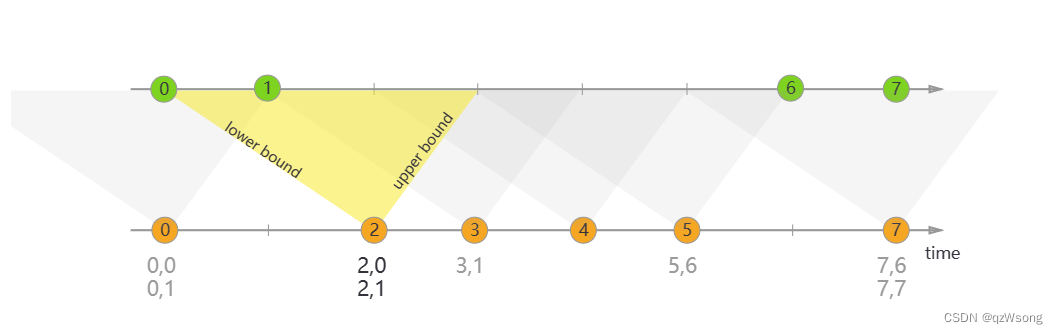
Table API(flink sql)
Reguler Join (常规join)
默认没有时间范围,全局都可以join
可以设置数据过期时间
tableEnv.getConfig().setIdleStateRetention(xx)
设置过期时间后以西四种join 数据过期方式各有不同

inner join
inner join 左流右流,创建后进入过期倒计时
SELECT *
FROM Orders
INNER JOIN Product
ON Orders.product_id = Product.idleft join / right join
left: 左流创建后进入过期倒计时,但是成功join一次后,就会重置过期时间
left: 右流创建后进入过期倒计时,但是成功join一次后,就会重置过期时间
SELECT *
FROM Orders
LEFT JOIN Product
ON Orders.product_id = Product.id
SELECT *
FROM Orders
RIGHT JOIN Product
ON Orders.product_id = Product.idfull join
左、右流创建后进入过期倒计时,但是成功join一次后,就会重置过期时间
SELECT *
FROM Orders
FULL OUTER JOIN Product
ON Orders.product_id = Product.idinterval join
作为DataStreamApi升级版的interval join,sql版本的支持处理时间语义和事件事件语义
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '4' HOUR AND s.ship_timelookup join
效果等同于cdc,但是每次过来一条数据都会去数据库进行一次查询关联、效率很差
但是可以设置缓存机制,如果用过一次后会缓存指定的时间,但是在缓存期间内就不会实时同步mysql的数据了。此时就和regular join 一样了
因此lookup join 试用场景为字典数据需要变化,但是变化的时间不需要实时变化,有点延迟也可以。
应用场景不多
关键语句
FOR SYSTEM_TIME AS OF o.proc_time
| lookup.cache.max-rows | optional | (none) | Integer | The max number of rows of lookup cache, over this value, the oldest rows will be expired. Lookup cache is disabled by default. See the following Lookup Cache section for more details 最多缓存多少条 |
| lookup.cache.ttl | optional | (none) | Duration | The max time to live for each rows in lookup cache, over this time, the oldest rows will be expired. Lookup cache is disabled by default. See the following Lookup Cache section for more details. 缓存数据ttl 1 DAY 1 HOUR |
CREATE TEMPORARY TABLE Orders (
id INT,
order_id INT,
total INT,
proc_time as procetime()
) WITH (
'connector' = 'kafka',
...
);
-- Customers is backed by the JDBC connector and can be used for lookup joins
CREATE TEMPORARY TABLE Customers (
id INT,
name STRING,
country STRING,
zip STRING
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://mysqlhost:3306/customerdb',
'table-name' = 'customers',
'lookup.cache.max-rows' = '10',
'lookup.cache.ttl' = '1 hour'
);
-- enrich each order with customer information
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS o
JOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS c
ON o.customer_id = c.id;Window Join
窗口join,必须对表进行TVF开窗才能使用
table(tumple(table tablegreen,descriptor(rt),interval '5' minutes))
时间类型:processTime、eventTime
INNER/LEFT/RIGHT/FULL OUTER
SELECT ...
FROM L [LEFT|RIGHT|FULL OUTER] JOIN R -- L and R are relations applied windowing TVF
ON L.window_start = R.window_start AND L.window_end = R.window_end AND ...





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结