您现在的位置是:首页 >技术教程 >Flink Oracle CDC Connector源码解读网站首页技术教程
Flink Oracle CDC Connector源码解读
Flink Oracle CDC简介
flink cdc是在flink的基础上对oracle的数据进行实时采集,底层使用的是debezium框架来实现,debezium使用oracle自带的logminer技术来实现。logminer的采集需要对数据库和采集表添加补充日志,由于oracle18c不支持对数据添加补充日志,所以目前支持的oracle11、12、19三个版本。
Flink Oracle CDC使用
flink oracle cdc 支持sql和api两种方式。oracle需要开启归档日志和补充日志才能完成采集,同时需要提供一个有权限的账号去连接oracle数据库完成实时采集。
归档日志开启方式
# 连接oracle
ORACLE_SID=SID
export ORACLE_SID
sqlplus /nolog
CONNECT sys/password AS SYSDBA
# 开启归档日志
alter system set db_recovery_file_dest_size = 10G;
alter system set db_recovery_file_dest = '/opt/oracle/oradata/recovery_area' scope=spfile;
shutdown immediate;
startup mount;
alter database archivelog;
alter database open;
对数据库和表开启补充日志
-- 开启指定表的所有字段补充日志: 补充日志支持ALL、PRIMARY KEY方式
ALTER TABLE inventory.customers ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
-- 开启数据库的补充日志
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
提供一个有权限的用户
sqlplus sys/password@host:port/SID AS SYSDBA;
CREATE TABLESPACE logminer_tbs DATAFILE '/opt/oracle/oradata/SID/logminer_tbs.dbf' SIZE 25M REUSE AUTOEXTEND ON MAXSIZE UNLIMITED;
CREATE USER flinkuser IDENTIFIED BY flinkpw DEFAULT TABLESPACE LOGMINER_TBS QUOTA UNLIMITED ON LOGMINER_TBS;
GRANT CREATE SESSION TO flinkuser;
GRANT SET CONTAINER TO flinkuser;
GRANT SELECT ON V_$DATABASE to flinkuser;
GRANT FLASHBACK ANY TABLE TO flinkuser;
GRANT SELECT ANY TABLE TO flinkuser;
GRANT SELECT_CATALOG_ROLE TO flinkuser;
GRANT EXECUTE_CATALOG_ROLE TO flinkuser;
GRANT SELECT ANY TRANSACTION TO flinkuser;
GRANT LOGMINING TO flinkuser;
GRANT CREATE TABLE TO flinkuser;
-- need not to execute if set scan.incremental.snapshot.enabled=true(default)
GRANT LOCK ANY TABLE TO flinkuser;
GRANT ALTER ANY TABLE TO flinkuser;
GRANT CREATE SEQUENCE TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR TO flinkuser;
GRANT EXECUTE ON DBMS_LOGMNR_D TO flinkuser;
GRANT SELECT ON V_$LOG TO flinkuser;
GRANT SELECT ON V_$LOG_HISTORY TO flinkuser;
GRANT SELECT ON V_$LOGMNR_LOGS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_CONTENTS TO flinkuser;
GRANT SELECT ON V_$LOGMNR_PARAMETERS TO flinkuser;
GRANT SELECT ON V_$LOGFILE TO flinkuser;
GRANT SELECT ON V_$ARCHIVED_LOG TO flinkuser;
GRANT SELECT ON V_$ARCHIVE_DEST_STATUS TO flinkuser;
exit;
flink的详细使用请参考官网地址
源码解读
由于源码解读是基于api方式使用的,先要准备源码环境,通过maven引入jar包,并将相关的源码下载下来,就可以在idea里面愉快的阅读和调试源代码。
引入maven包
官网最新的版本是2.4,发布版本是2.3.0,我调试的环境是2.2.0。下面的代码都是基于2.2.0来介绍。
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-connector-oracle-cdc</artifactId>
<!-- The dependency is available only for stable releases, SNAPSHOT dependency need build by yourself. -->
<version>2.2.0</version>
</dependency>
基于api方式使用oracle cdc
Properties properties = new Properties();
properties.put("decimal.handling.mode", "double");
properties.put("database.url","jdbc:oracle:thin:@127.0.0.1:1521:orcl");
SourceFunction<String> sourceFunction = OracleSource.<String>builder()
.hostname("localhost")
.port(1521)
.database("orcl") // monitor XE database
.schemaList("flinkuser") // monitor inventory schema
.tableList("flinkuser.test") // monitor products table
.username("flinkuser")
.password("flinkpw")
.startupOptions(StartupOptions.latest())
.debeziumProperties(properties)
.deserializer(new JsonDebeziumDeserializationSchema()) // converts SourceRecord to JSON String
.build();
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
env.addSOurce(sourceFunction).print();
env.execute();
以OracleSource作为一个工具类方法调用build()会返回一个DebeziumSourceFunction对象,在返回这个对象之前会设置build之前的参数。
public DebeziumSourceFunction<T> build() {
Properties props = new Properties();
props.setProperty("connector.class", OracleConnector.class.getCanonicalName());
// Logical name that identifies and provides a namespace for the particular Oracle
// database server being
// monitored. The logical name should be unique across all other connectors, since it is
// used as a prefix
// for all Kafka topic names emanating from this connector. Only alphanumeric characters
// and
// underscores should be used.
props.setProperty("database.server.name", DATABASE_SERVER_NAME);
props.setProperty("database.hostname", checkNotNull(hostname));
props.setProperty("database.user", checkNotNull(username));
props.setProperty("database.password", checkNotNull(password));
props.setProperty("database.port", String.valueOf(port));
props.setProperty("database.history.skip.unparseable.ddl", String.valueOf(true));
props.setProperty("database.dbname", checkNotNull(database));
if (schemaList != null) {
props.setProperty("schema.whitelist", String.join(",", schemaList));
}
if (tableList != null) {
props.setProperty("table.include.list", String.join(",", tableList));
}
DebeziumOffset specificOffset = null;
switch (startupOptions.startupMode) {
case INITIAL:
props.setProperty("snapshot.mode", "initial");
break;
case LATEST_OFFSET:
props.setProperty("snapshot.mode", "schema_only");
break;
default:
throw new UnsupportedOperationException();
}
if (dbzProperties != null) {
props.putAll(dbzProperties);
}
return new DebeziumSourceFunction<>(
deserializer, props, specificOffset, new OracleValidator(props));
}
跟进DebeziumSourceFunction源代码的run()方法里面提交解析oracle实时日志请求
// create the engine with this configuration ...
this.engine =
DebeziumEngine.create(Connect.class)
.using(properties)
.notifying(changeConsumer)
.using(OffsetCommitPolicy.always())
.using(
(success, message, error) -> {
if (success) {
// Close the handover and prepare to exit.
handover.close();
} else {
handover.reportError(error);
}
})
.build();
// run the engine asynchronously
executor.execute(engine);
debeziumStarted = true;
DebeziumEngine.build()的实现类是io.debezium.embedded.EmbeddedEngine.BuilderImpl#build这个方法,返回一个EmbeddedEngine对象,这是一个线程类。在run方法里面完成整个数据采集链路。方法调用栈
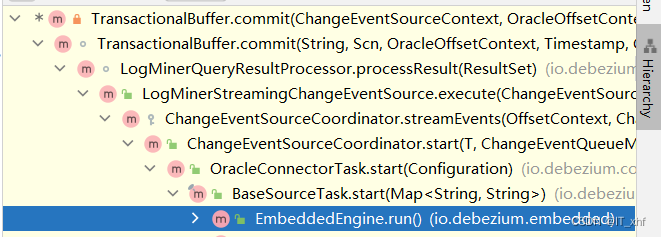
@Override
public void run() {
if (runningThread.compareAndSet(null, Thread.currentThread())) {
....
// Instantiate the connector ...
SourceConnector connector = null;
try {
@SuppressWarnings("unchecked")
Class<? extends SourceConnector> connectorClass = (Class<SourceConnector>) classLoader.loadClass(connectorClassName);
connector = connectorClass.getDeclaredConstructor().newInstance();
}
// Instantiate the offset store ...
final String offsetStoreClassName = config.getString(OFFSET_STORAGE);
OffsetBackingStore offsetStore = null;
try {
@SuppressWarnings("unchecked")
Class<? extends OffsetBackingStore> offsetStoreClass = (Class<OffsetBackingStore>) classLoader.loadClass(offsetStoreClassName);
offsetStore = offsetStoreClass.getDeclaredConstructor().newInstance();
}
....
// Initialize the offset store ...
try {
offsetStore.configure(workerConfig);
offsetStore.start();
}
....
// Set up the offset commit policy ...
if (offsetCommitPolicy == null) {
offsetCommitPolicy = Instantiator.getInstanceWithProperties(config.getString(EmbeddedEngine.OFFSET_COMMIT_POLICY),
() -> getClass().getClassLoader(), config.asProperties());
}
// Initialize the connector using a context that does NOT respond to requests to reconfigure tasks ...
ConnectorContext context = new ConnectorContext() ;
....
connector.initialize(context);
OffsetStorageWriter offsetWriter = new OffsetStorageWriter(offsetStore, engineName,
keyConverter, valueConverter);
OffsetStorageReader offsetReader = new OffsetStorageReaderImpl(offsetStore, engineName,
keyConverter, valueConverter);
Duration commitTimeout = Duration.ofMillis(config.getLong(OFFSET_COMMIT_TIMEOUT_MS));
try {
// Start the connector with the given properties and get the task configurations ...
connector.start(config.asMap());
connectorCallback.ifPresent(DebeziumEngine.ConnectorCallback::connectorStarted);
List<Map<String, String>> taskConfigs = connector.taskConfigs(1);
Class<? extends Task> taskClass = connector.taskClass();
if (taskConfigs.isEmpty()) {
String msg = "Unable to start connector's task class '" + taskClass.getName() + "' with no task configuration";
fail(msg);
return;
}
task = null;
try {
task = (SourceTask) taskClass.getDeclaredConstructor().newInstance();
}
catch (IllegalAccessException | InstantiationException t) {
fail("Unable to instantiate connector's task class '" + taskClass.getName() + "'", t);
return;
}
try {
SourceTaskContext taskContext = new SourceTaskContext() ;
......
task.initialize(taskContext);
task.start(taskConfigs.get(0));
connectorCallback.ifPresent(DebeziumEngine.ConnectorCallback::taskStarted);
}
......
recordsSinceLastCommit = 0;
Throwable handlerError = null;
try {
timeOfLastCommitMillis = clock.currentTimeInMillis();
RecordCommitter committer = buildRecordCommitter(offsetWriter, task, commitTimeout);
while (runningThread.get() != null) {
List<SourceRecord> changeRecords = null;
try {
LOGGER.debug("Embedded engine is polling task for records on thread {}", runningThread.get());
changeRecords = task.poll(); // blocks until there are values ...
LOGGER.debug("Embedded engine returned from polling task for records");
}
catch (InterruptedException e) {
// Interrupted while polling ...
LOGGER.debug("Embedded engine interrupted on thread {} while polling the task for records", runningThread.get());
if (this.runningThread.get() == Thread.currentThread()) {
// this thread is still set as the running thread -> we were not interrupted
// due the stop() call -> probably someone else called the interrupt on us ->
// -> we should raise the interrupt flag
Thread.currentThread().interrupt();
}
break;
}
catch (RetriableException e) {
LOGGER.info("Retrieable exception thrown, connector will be restarted", e);
// Retriable exception should be ignored by the engine
// and no change records delivered.
// The retry is handled in io.debezium.connector.common.BaseSourceTask.poll()
}
try {
if (changeRecords != null && !changeRecords.isEmpty()) {
LOGGER.debug("Received {} records from the task", changeRecords.size());
changeRecords = changeRecords.stream()
.map(transformations::transform)
.filter(x -> x != null)
.collect(Collectors.toList());
}
if (changeRecords != null && !changeRecords.isEmpty()) {
LOGGER.debug("Received {} transformed records from the task", changeRecords.size());
try {
handler.handleBatch(changeRecords, committer);
}
catch (StopConnectorException e) {
break;
}
}
else {
LOGGER.debug("Received no records from the task");
}
}
catch (Throwable t) {
// There was some sort of unexpected exception, so we should stop work
handlerError = t;
break;
}
}
}
...
}
}
}
- 通过反射方式初始化connector获取
OracleConnector对象 - 初始化offset的存储对象
- 设置offset提交策略
- 通过
connector.start(config.asMap());将配置属性设置给Connector对象 - 通过反射方式从connector获取SourceTask,在这里获取的是
OracleConnectorTask对象 - 通过调用
task.start(taskConfigs.get(0));启动任务去获取oracle的变更数据,具体方法路径io.debezium.connector.oracle.OracleConnectorTask#start,具体实现代码如下:
@Override
public ChangeEventSourceCoordinator start(Configuration config) {
OracleConnectorConfig connectorConfig = new OracleConnectorConfig(config);
TopicSelector<TableId> topicSelector = OracleTopicSelector.defaultSelector(connectorConfig);
SchemaNameAdjuster schemaNameAdjuster = SchemaNameAdjuster.create();
Configuration jdbcConfig = connectorConfig.jdbcConfig();
jdbcConnection = new OracleConnection(jdbcConfig, () -> getClass().getClassLoader());
this.schema = new OracleDatabaseSchema(connectorConfig, schemaNameAdjuster, topicSelector, jdbcConnection);
this.schema.initializeStorage();
String adapterString = config.getString(OracleConnectorConfig.CONNECTOR_ADAPTER);
OracleConnectorConfig.ConnectorAdapter adapter = OracleConnectorConfig.ConnectorAdapter.parse(adapterString);
OffsetContext previousOffset = getPreviousOffset(new OracleOffsetContext.Loader(connectorConfig, adapter));
if (previousOffset != null) {
schema.recover(previousOffset);
}
taskContext = new OracleTaskContext(connectorConfig, schema);
Clock clock = Clock.system();
// Set up the task record queue ...
this.queue = new ChangeEventQueue.Builder<DataChangeEvent>()
.pollInterval(connectorConfig.getPollInterval())
.maxBatchSize(connectorConfig.getMaxBatchSize())
.maxQueueSize(connectorConfig.getMaxQueueSize())
.loggingContextSupplier(() -> taskContext.configureLoggingContext(CONTEXT_NAME))
.build();
errorHandler = new OracleErrorHandler(connectorConfig.getLogicalName(), queue);
final OracleEventMetadataProvider metadataProvider = new OracleEventMetadataProvider();
EventDispatcher<TableId> dispatcher = new EventDispatcher<>(
connectorConfig,
topicSelector,
schema,
queue,
connectorConfig.getTableFilters().dataCollectionFilter(),
DataChangeEvent::new,
metadataProvider,
schemaNameAdjuster);
final OracleStreamingChangeEventSourceMetrics streamingMetrics = new OracleStreamingChangeEventSourceMetrics(taskContext, queue, metadataProvider,
connectorConfig);
ChangeEventSourceCoordinator coordinator = new ChangeEventSourceCoordinator(
previousOffset,
errorHandler,
OracleConnector.class,
connectorConfig,
new OracleChangeEventSourceFactory(connectorConfig, jdbcConnection, errorHandler, dispatcher, clock, schema, jdbcConfig, taskContext, streamingMetrics),
new OracleChangeEventSourceMetricsFactory(streamingMetrics),
dispatcher,
schema);
coordinator.start(taskContext, this.queue, metadataProvider);
return coordinator;
}
- 创建一个任务上下文对象
taskContext,改对象用来保存任务的参数和schema属性 - 设置一个消息队列
queue,用来保存解析后的消息 - 创建事件分发器对象
dispatcher,该对象用来下发解析后的数据到队列中 - 创建
io.debezium.pipeline.ChangeEventSourceCoordinator对象,调用io.debezium.pipeline.ChangeEventSourceCoordinator#start,
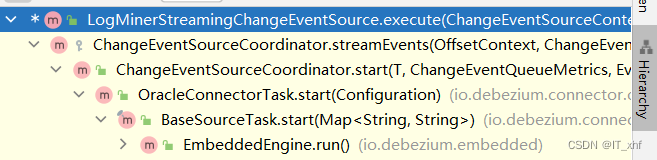
方法中的会调用streamEvents,streamEvents最后调用io.debezium.connector.oracle.logminer.LogMinerStreamingChangeEventSource#execute方法,该方法就是解析oracle日志的最终实现方法
public void execute(ChangeEventSourceContext context) {
try (TransactionalBuffer transactionalBuffer = new TransactionalBuffer(schema, clock, errorHandler, streamingMetrics)) {
try {
startScn = offsetContext.getScn();
createFlushTable(jdbcConnection);
if (!isContinuousMining && startScn.compareTo(getFirstOnlineLogScn(jdbcConnection, archiveLogRetention)) < 0) {
throw new DebeziumException(
"Online REDO LOG files or archive log files do not contain the offset scn " + startScn + ". Please perform a new snapshot.");
}
setNlsSessionParameters(jdbcConnection);
checkSupplementalLogging(jdbcConnection, connectorConfig.getPdbName(), schema);
initializeRedoLogsForMining(jdbcConnection, false, archiveLogRetention);
HistoryRecorder historyRecorder = connectorConfig.getLogMiningHistoryRecorder();
try {
// todo: why can't OracleConnection be used rather than a Factory+JdbcConfiguration?
historyRecorder.prepare(streamingMetrics, jdbcConfiguration, connectorConfig.getLogMinerHistoryRetentionHours());
final LogMinerQueryResultProcessor processor = new LogMinerQueryResultProcessor(context, jdbcConnection,
connectorConfig, streamingMetrics, transactionalBuffer, offsetContext, schema, dispatcher,
clock, historyRecorder);
final String query = SqlUtils.logMinerContentsQuery(connectorConfig, jdbcConnection.username());
try (PreparedStatement miningView = jdbcConnection.connection().prepareStatement(query, ResultSet.TYPE_FORWARD_ONLY,
ResultSet.CONCUR_READ_ONLY, ResultSet.HOLD_CURSORS_OVER_COMMIT)) {
currentRedoLogSequences = getCurrentRedoLogSequences();
Stopwatch stopwatch = Stopwatch.reusable();
while (context.isRunning()) {
// Calculate time difference before each mining session to detect time zone offset changes (e.g. DST) on database server
streamingMetrics.calculateTimeDifference(getSystime(jdbcConnection));
Instant start = Instant.now();
endScn = getEndScn(jdbcConnection, startScn, streamingMetrics, connectorConfig.getLogMiningBatchSizeDefault());
flushLogWriter(jdbcConnection, jdbcConfiguration, isRac, racHosts);
if (hasLogSwitchOccurred()) {
// This is the way to mitigate PGA leaks.
// With one mining session, it grows and maybe there is another way to flush PGA.
// At this point we use a new mining session
LOGGER.trace("Ending log mining startScn={}, endScn={}, offsetContext.getScn={}, strategy={}, continuous={}",
startScn, endScn, offsetContext.getScn(), strategy, isContinuousMining);
endMining(jdbcConnection);
initializeRedoLogsForMining(jdbcConnection, true, archiveLogRetention);
abandonOldTransactionsIfExist(jdbcConnection, transactionalBuffer);
// This needs to be re-calculated because building the data dictionary will force the
// current redo log sequence to be advanced due to a complete log switch of all logs.
currentRedoLogSequences = getCurrentRedoLogSequences();
}
startLogMining(jdbcConnection, startScn, endScn, strategy, isContinuousMining, streamingMetrics);
stopwatch.start();
miningView.setFetchSize(connectorConfig.getMaxQueueSize());
miningView.setFetchDirection(ResultSet.FETCH_FORWARD);
miningView.setString(1, startScn.toString());
miningView.setString(2, endScn.toString());
try (ResultSet rs = miningView.executeQuery()) {
Duration lastDurationOfBatchCapturing = stopwatch.stop().durations().statistics().getTotal();
streamingMetrics.setLastDurationOfBatchCapturing(lastDurationOfBatchCapturing);
processor.processResult(rs);
startScn = endScn;
if (transactionalBuffer.isEmpty()) {
LOGGER.debug("Transactional buffer empty, updating offset's SCN {}", startScn);
offsetContext.setScn(startScn);
}
}
streamingMetrics.setCurrentBatchProcessingTime(Duration.between(start, Instant.now()));
pauseBetweenMiningSessions();
}
}
}
finally {
historyRecorder.close();
}
}
catch (Throwable t) {
logError(streamingMetrics, "Mining session stopped due to the {}", t);
errorHandler.setProducerThrowable(t);
}
finally {
LOGGER.info("startScn={}, endScn={}, offsetContext.getScn()={}", startScn, endScn, offsetContext.getScn());
LOGGER.info("Transactional buffer dump: {}", transactionalBuffer.toString());
LOGGER.info("Streaming metrics dump: {}", streamingMetrics.toString());
}
}
}
- 创建一张临时表,保存最后一次解析的SCN,用来下一次解析的数据位置
CREATE TABLE LOGMNR_FLUSH_TABLE (LAST_SCN NUMBER(19,0));
- 检查数据库和表有没有开启归档日志
checkSupplementalLogging(jdbcConnection, connectorConfig.getPdbName(), schema);
- 调用数据库的数据字典构建存储过程,并数据库的归档日志和在线日志添加到logminer中
private void initializeRedoLogsForMining(OracleConnection connection, boolean postEndMiningSession, Duration archiveLogRetention) throws SQLException {
if (!postEndMiningSession) {
if (OracleConnectorConfig.LogMiningStrategy.CATALOG_IN_REDO.equals(strategy)) {
buildDataDictionary(connection);
}
if (!isContinuousMining) {
setRedoLogFilesForMining(connection, startScn, archiveLogRetention);
}
}
else {
if (!isContinuousMining) {
if (OracleConnectorConfig.LogMiningStrategy.CATALOG_IN_REDO.equals(strategy)) {
buildDataDictionary(connection);
}
setRedoLogFilesForMining(connection, startScn, archiveLogRetention);
}
}
}
以上代码在数据库中会执行如下语句:
BEGIN DBMS_LOGMNR_D.BUILD (options => DBMS_LOGMNR_D.STORE_IN_REDO_LOGS); END;
# 查看在线日志列表
SELECT MIN(F.MEMBER) AS FILE_NAME, L.NEXT_CHANGE# AS NEXT_CHANGE, F.GROUP#, L.FIRST_CHANGE# AS FIRST_CHANGE, L.STATUS
FROM V$LOG L, V$LOGFILE F
WHERE F.GROUP# = L.GROUP# AND L.NEXT_CHANGE# > 0
GROUP BY F.GROUP#, L.NEXT_CHANGE#, L.FIRST_CHANGE#, L.STATUS ORDER BY 3;
# 查看归档日志列表
SELECT NAME AS FILE_NAME, NEXT_CHANGE# AS NEXT_CHANGE, FIRST_CHANGE# AS FIRST_CHANGE
FROM V$ARCHIVED_LOG
WHERE NAME IS NOT NULL
AND ARCHIVED = 'YES'
AND STATUS = 'A'
AND NEXT_CHANGE# '?' --上一次爬取的scn
AND DEST_ID IN (SELECT DEST_ID FROM V$ARCHIVE_DEST_STATUS WHERE STATUS='VALID' AND TYPE='LOCAL' AND ROWNUM=1)) ORDER BY 2;
将归档日志合并到在线日志中,将合并的列表添加到logminer中用来解析
EGIN sys.dbms_logmnr.add_logfile(LOGFILENAME => '" + fileName + "', OPTIONS => "DBMS_LOGMNR.ADDFILE");END;
- 调用
sys.dbms_logmnr.start_logmnr开始解析归档日志,并将解析的结果写入V$LOGMNR_CONTENTS
static String startLogMinerStatement(Scn startScn, Scn endScn, OracleConnectorConfig.LogMiningStrategy strategy, boolean isContinuousMining) {
String miningStrategy;
if (strategy.equals(OracleConnectorConfig.LogMiningStrategy.CATALOG_IN_REDO)) {
miningStrategy = "DBMS_LOGMNR.DICT_FROM_REDO_LOGS + DBMS_LOGMNR.DDL_DICT_TRACKING ";
}
else {
miningStrategy = "DBMS_LOGMNR.DICT_FROM_ONLINE_CATALOG ";
}
if (isContinuousMining) {
miningStrategy += " + DBMS_LOGMNR.CONTINUOUS_MINE ";
}
return "BEGIN sys.dbms_logmnr.start_logmnr(" +
"startScn => '" + startScn + "', " +
"endScn => '" + endScn + "', " +
"OPTIONS => " + miningStrategy +
" + DBMS_LOGMNR.NO_ROWID_IN_STMT);" +
"END;";
}
最终查询结果的语句
SELECT SCN, SQL_REDO, OPERATION_CODE, TIMESTAMP, XID, CSF, TABLE_NAME, SEG_OWNER, OPERATION, USERNAME, ROW_ID, ROLLBACK FROM V$LOGMNR_CONTENTS WHERE SCN > '2468014' AND SCN <= '2468297' AND ((OPERATION_CODE IN (5,34) AND USERNAME NOT IN ('SYS','SYSTEM','FLINKUSER')) OR (OPERATION_CODE IN (7,36)) OR (OPERATION_CODE IN (1,2,3) AND TABLE_NAME != 'LOG_MINING_FLUSH' AND SEG_OWNER NOT IN ('APPQOSSYS','AUDSYS','CTXSYS','DVSYS','DBSFWUSER','DBSNMP','GSMADMIN_INTERNAL','LBACSYS','MDSYS','OJVMSYS','OLAPSYS','ORDDATA','ORDSYS','OUTLN','SYS','SYSTEM','WMSYS','XDB') AND (REGEXP_LIKE(SEG_OWNER,'^flinkuser$','i')) AND (REGEXP_LIKE(SEG_OWNER || '.' || TABLE_NAME,'^flinkuser.test$','i')) ))
解析查询的结果
miningView.setFetchSize(connectorConfig.getMaxQueueSize());
miningView.setFetchDirection(ResultSet.FETCH_FORWARD);
miningView.setString(1, startScn.toString());
miningView.setString(2, endScn.toString());
try (ResultSet rs = miningView.executeQuery()) {
Duration lastDurationOfBatchCapturing = stopwatch.stop().durations().statistics().getTotal();
streamingMetrics.setLastDurationOfBatchCapturing(lastDurationOfBatchCapturing);
processor.processResult(rs);
startScn = endScn;
if (transactionalBuffer.isEmpty()) {
LOGGER.debug("Transactional buffer empty, updating offset's SCN {}", startScn);
offsetContext.setScn(startScn);
}
}
解析的具体类和方法io.debezium.connector.oracle.logminer.LogMinerQueryResultProcessor#processResult,这个类就是完成sql语句的解析,将sql语句中的字段和字段所对应的值解析到两个数组中,包装成一个Entry对象传递给converter去解析,这个的具体解析过程后面再补充。
使用中遇到的问题
如果oracle的dbName配置的是SID会出现链接不上的问题。
如果oracle的dbName配置的是SID,而不是service_name,就会出现链接不上的问题,出现这个问题的原因是犹豫oracle的默认链接是一jdbc:oracle:thin@localhost:1521/service_name方式拼接,如果要链接SID需要改成jdbc:oracle:thin:@localhost:1521:sid方式。在oracle cdc中可以手动指定oracle链接字符串,这样就会根据你指定的url方式去链接。
基于api的方式指定
properties.put("database.url","jdbc:oracle:thin:@localhost:1521:sid");
基于flink sql方式指定
基于sql设置属性需要加一个debezium.前缀
CREATE TABLE GSP_PURCHASE_ORDER(
ORDER_ID STRING NOT NULL,
EBELN STRING,
BSTYP STRING,
PRIMARY KEY(ORDER_ID) NOT ENFORCED
) WITH (
'connector' = 'oracle-cdc',
'debezium.database.url' = 'jdbc:oracle:thin:@localhost:1521:RACTEST1',
'debezium.database.tablename.case.insensitive' = 'false',
'hostname' = 'localhost',
'port' = '1521',
'username' = '****',
'password' = '****',
'database-name' = 'RACTEST1',
'schema-name' = 'GSP_MODULE_UAT',
'table-name' = 'GSP_PURCHASE_ORDER');
oracle11g大小写敏感问题
oracle在查询表的状态的时候默认是会将表名转换为小写,这样查询的表补充日志的时候认为是没有,所以需要指定database.tablename.case.insensitive属性改成false,这样就不会自动将表名转换为小写去校验表,这样就能成功的校验出表是否有添加补充日志,对于oracle11g,表名和schema一定要大写。
基于api的修改方式
properties.put("database.tablename.case.insensitive","false");
基于sql的修改方式
修改方式参考第一个问题的修改方式。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结