您现在的位置是:首页 >学无止境 >ctr特征重要性建模:FiBiNet&FiBiNet++模型网站首页学无止境
ctr特征重要性建模:FiBiNet&FiBiNet++模型
FiBiNET(Feature Importance and Bilinear feature Interaction NETwork)为推荐系统的CTR模型提出了一些创新方向:
- 引入一个SENet模块,可以动态学习特征的重要性;
- 引入一个双线性模块(Bilinear-Interaction layer),来改进特征交互方式。
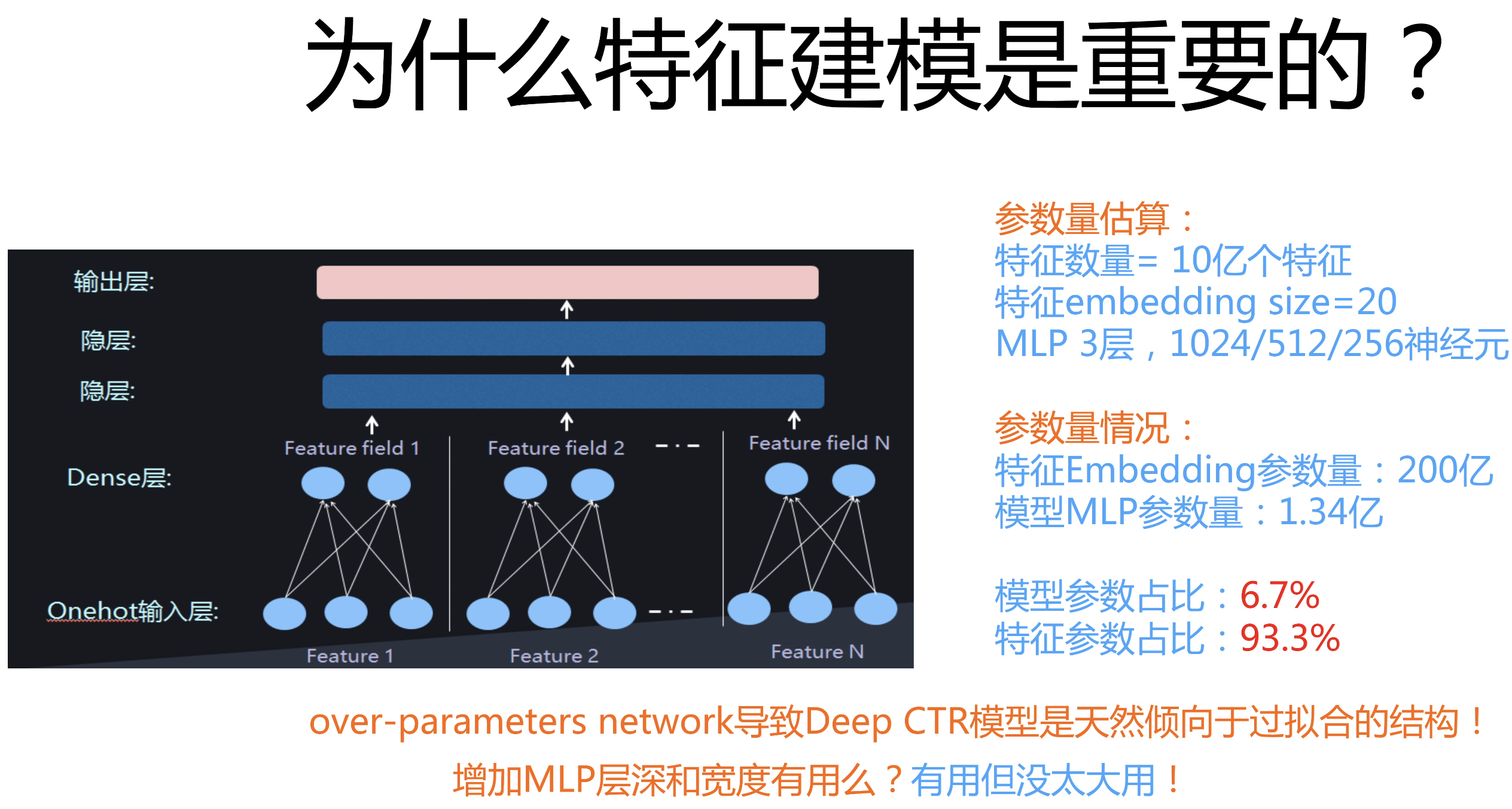
可以看出,FiBiNET模型主要的工作都是在特征建模方向,但论文没有说明为什么特征建模在ctr模型中如此重要?下面我们引用论文作者的一张图:
ctr任务中大部分特征是ID类特征,并且数据是十分稀疏的。ctr模型中的参数绝大部分都为特征Embedding,可见其重要程度,而特征重要性建模则是更好地利用这些特征的方向之一。(PS:另外一个方向是频次相关的变长embedding)
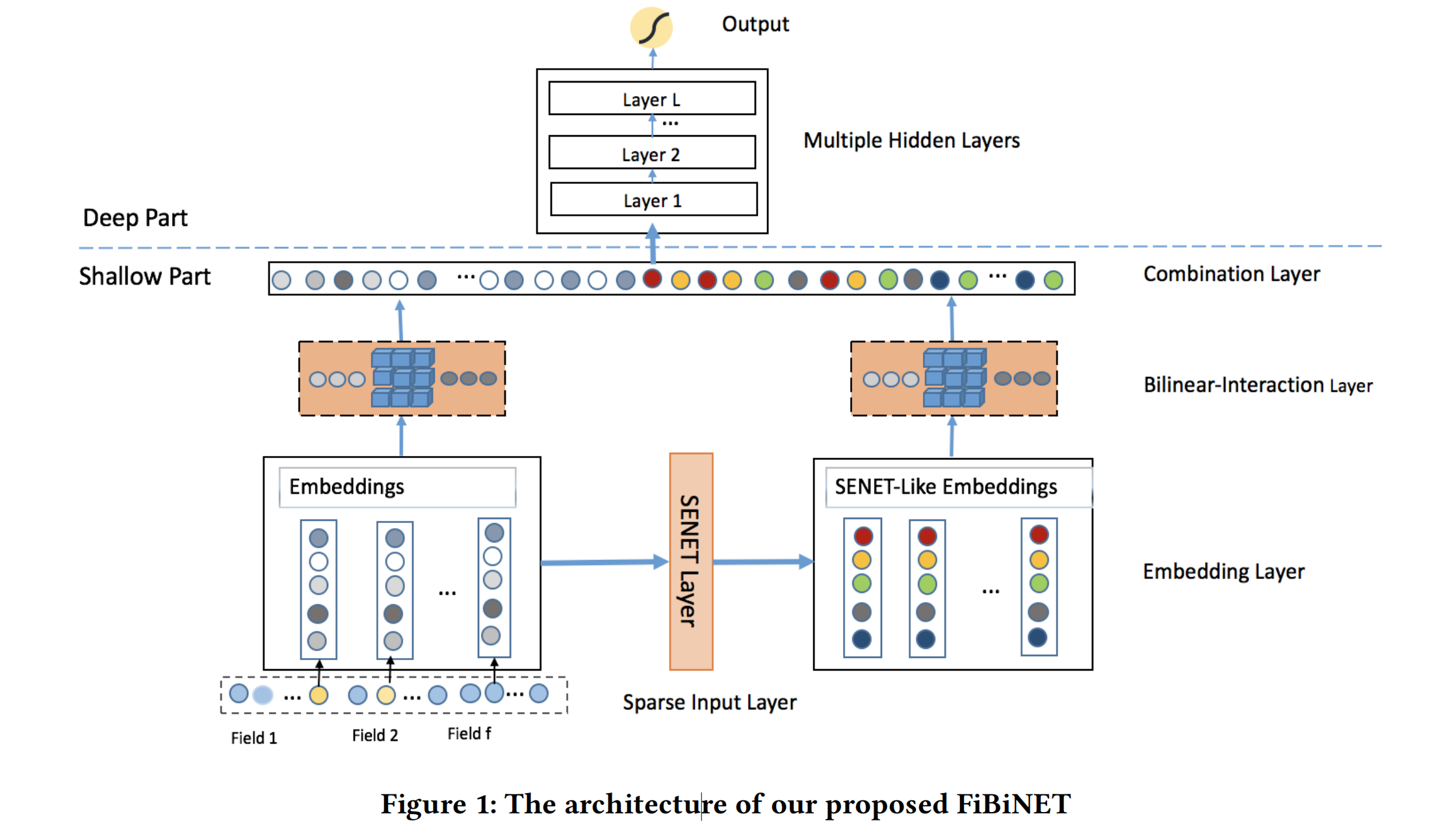
1. FiBiNet
论文:FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction
地址:https://arxiv.org/abs/1905.09433
从下图的网络结构,可以看出FiBiNet模型其实不复杂,主要在深度ctr模型baseline中引入了SENet和Bilinear-Interaction:
- 不同的特征转换为Embeddings E;
- Embeddings输入到SENet Layer,得到SENet-Like Embeddings V;
- Embeddings E和V分别经过双线性特征交互层,得到p和q;
- p和q进行拼接,输入到DNN全连接层,最后使用sigmoid函数得到预测概率。
1.1 Embedding Layer
为了方便表述,在这里稍微讲下field和feature的区别:field是一类特征,而feature则是具体的特征值。比如性别、学历等等都是field,而feature则表示性别为男、学历为本科。
那么,这些ID类输入经过Embedding Layer,并且进行拼接,输出则为: E = [ e 1 , e 2 , . . . , e i , . . . , e f ] , e i ∈ R k E=[e_1,e_2,...,e_i,...,e_f],e_iin R^k E=[e1,e2,...,ei,...,ef],ei∈Rk表示第i个field的embedding,f为fileds的数量,k则为embedding的维度。
1.2 SENet
众所周知,不同的特征在特定的任务中,重要性是不一样的。SENet可以帮助我们对特征重要性进行建模,在ctr任务中,通过SENet可以动态地增加重要特征的权重,和降低无关特征的权重。
SENet接收embedding layer的输出,产出权重向量 A = { a 1 , . . . , a i , . . . , a f } , a i A={a_1,...,a_i,...,a_f},a_i A={a1,...,ai,...,af},ai为标量,代表第i个field embedding的权重。然后把原来的embedding E重新缩放为一个新的embedding(SENet-Like embedding) V = [ v 1 , . . . , v i , . . . , v f ] V=[v_1,...,v_i,...,v_f] V=[v1,...,vi,...,vf]。
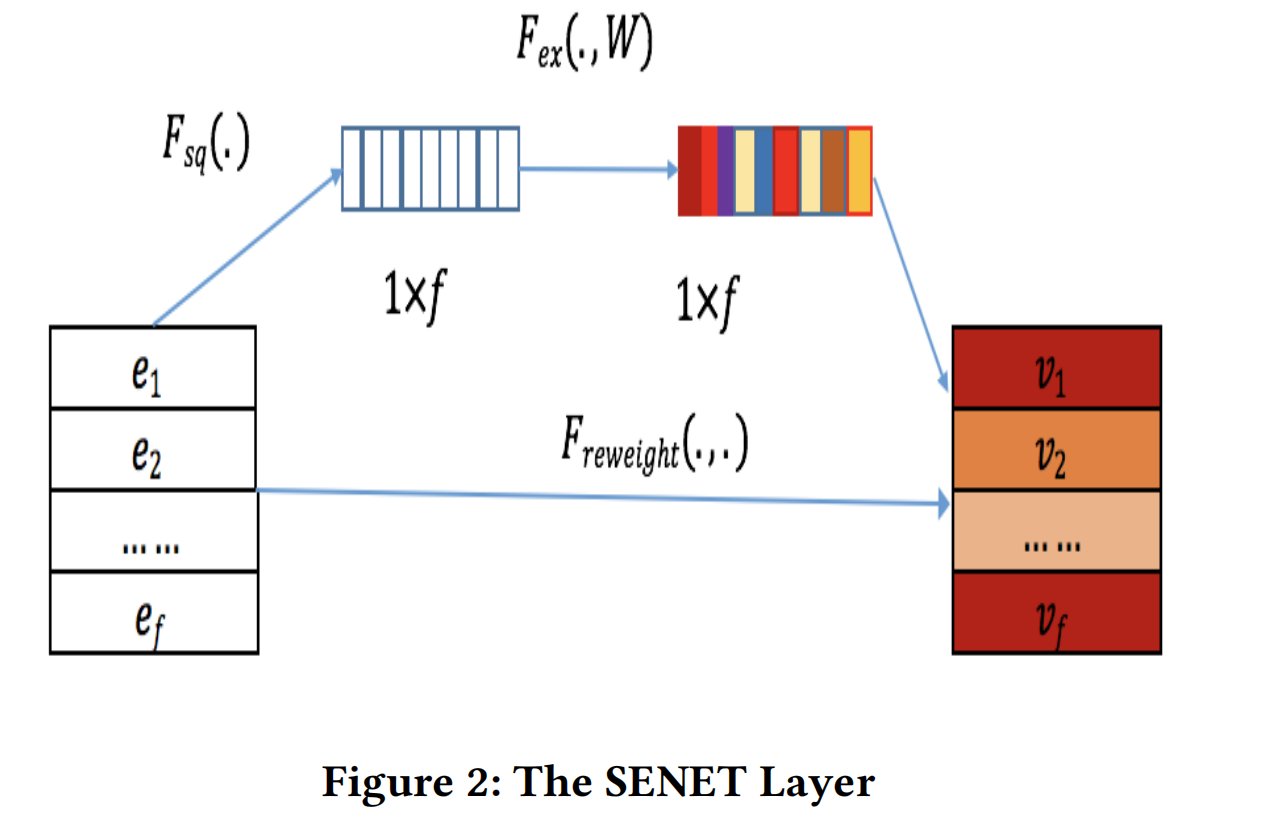
如上图所示,SENet包括三个步骤:squeeze、excitation、re-weight。
Squeeze. 这一个步骤是为了计算每个field embedding的统计信息。使用mean或者max的pooling方法来挤压原来的Embedding E,变成一个统计向量 Z = [ z 1 , . . . , z i , . . . , z f ] , z i Z=[z_1,...,z_i,...,z_f],z_i Z=[z1,...,zi,...,zf],zi是一个标量,表征第i个feature的全局信息。
如下式则为mean pooling,论文实验了mean pooling比max pooling的效果更佳:
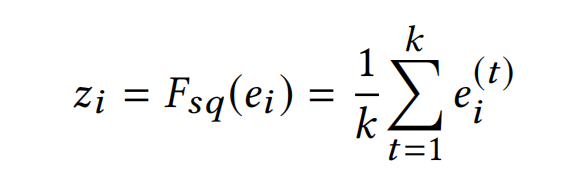
**Excitation. ** 这一个步骤是为了在统计向量Z的基础上,学习到每个field embedding的权重。具体方法也很简单,就是使用带激活函数的两个全连接层:
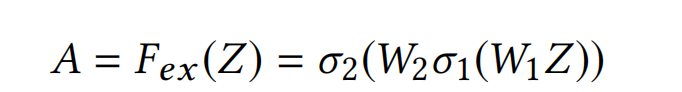
其中, A ∈ R f 是一个向量, σ 1 和 σ 2 Ain R^f是一个向量,sigma_1和sigma_2 A∈Rf是一个向量,σ1和σ2都为激活函数, W 1 ∈ R f × f r 和 W 2 ∈ R f r × f W_1in R^{f imes frac{f}{r}}和W_2in R^{frac{f}{r} imes f} W1∈Rf×rf和W2∈Rrf×f为训练参数,r为缩减比例,是一个超参数。
**Re-Weight. ** 这一个步骤是把权重向量A对原来的Embedding E进行缩放,得到SENet-Like embedding V。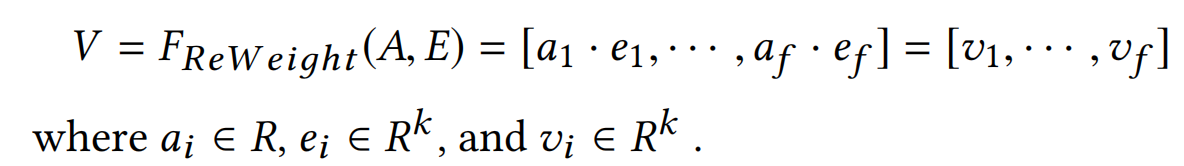
1.3 Bilinear-Interaction
交互网络层的目的是为了计算二阶特征交互,如FM和FFM这些线层模型的特征交互是使用了inner product,如AFM和NFM这些深度模型则是使用Hadamard product。
但是,这两种方法都过于简单,在稀疏数据中难以进行有效的建模。因此,论文结合这两种方法,提出了另外一种交互方式:Bilinear- Interaction。
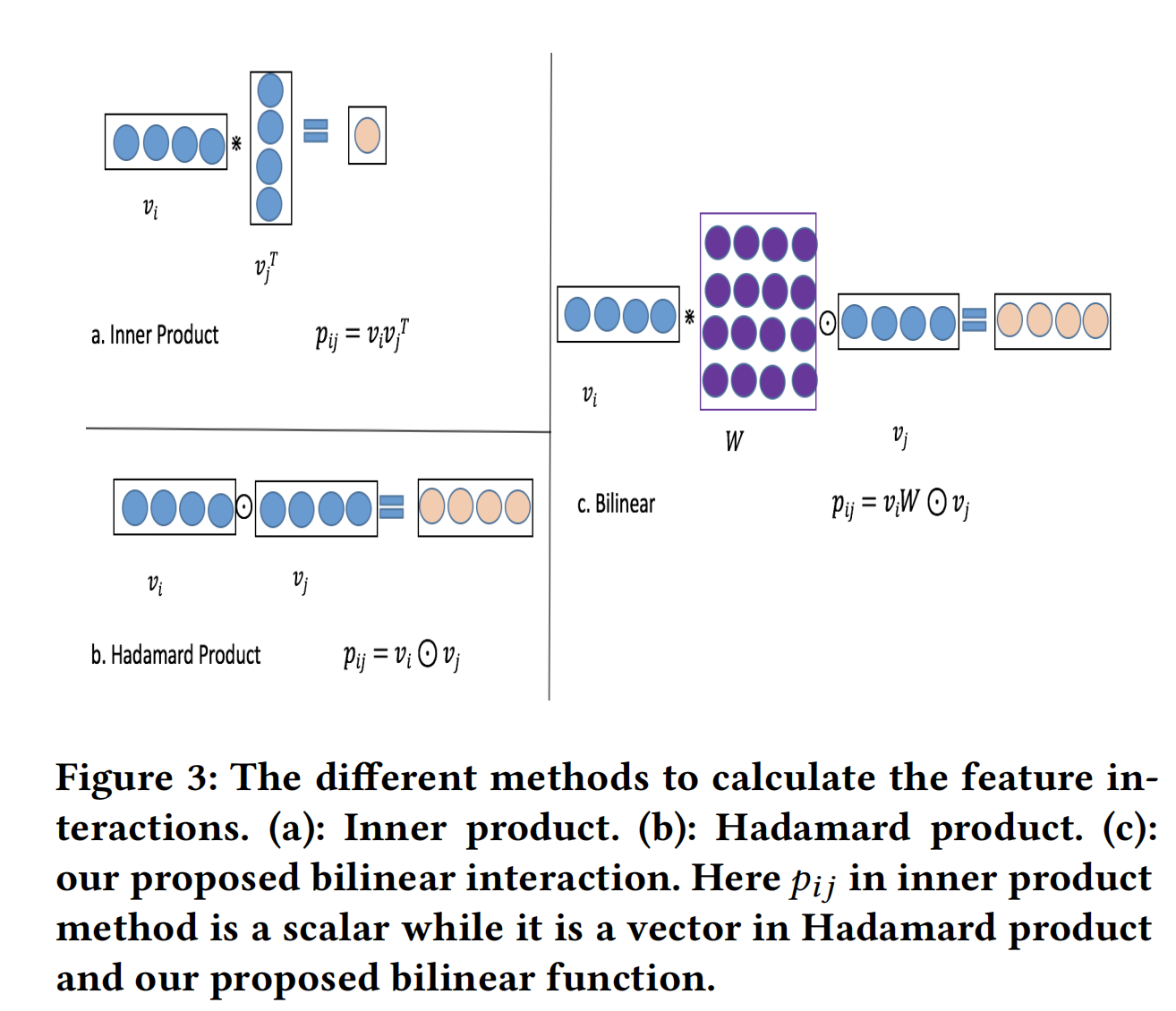
如上图所示,三种交互方式的区别也比较明显了。Inner Product就是内积,而Hadamard Product: [ a 1 , a 2 , a 3 ] ⊙ [ b 1 , b 2 , b 3 ] = [ a 1 b 1 , a 2 b 2 , a 3 b 3 ] [a_1,a_2,a_3]odot [b_1,b_2,b_3]=[a_1b_1,a2_b2,a3_b3] [a1,a2,a3]⊙[b1,b2,b3]=[a1b1,a2b2,a3b3]。而双线性特征交互包括以下三种:
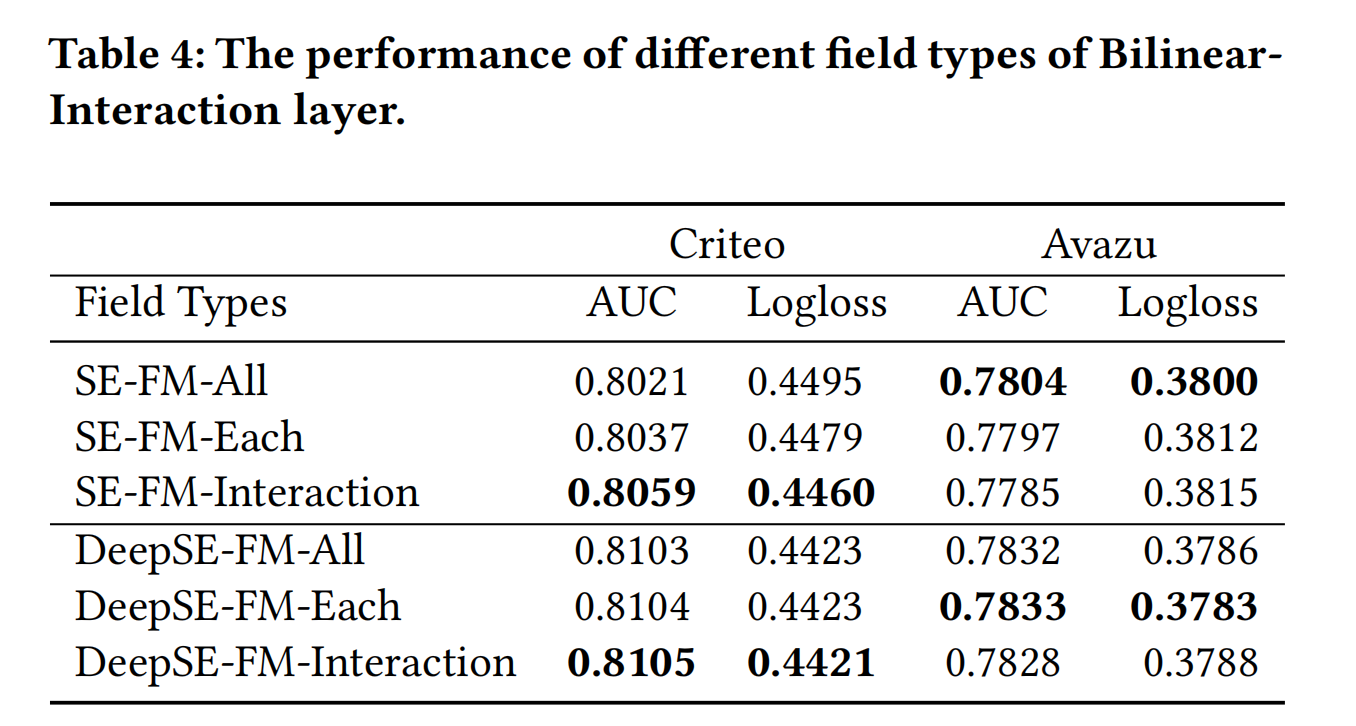
- **Field-All Type: ** p i j = v i ⋅ W ⊙ v j p_{ij}=v_icdot Wodot v_j pij=vi⋅W⊙vj。所有field共享一个隐矩阵 W ∈ R k × k Win R^{k imes k} W∈Rk×k,参数量为k·k;
- **Field-Each Type: ** p i j = v i ⋅ W i ⊙ v j p_{ij}=v_icdot W_iodot v_j pij=vi⋅Wi⊙vj。每一个filed都有自己的隐矩阵 W i ∈ R k × k W_iin R^{k imes k} Wi∈Rk×k,参数量为f·k·k;
- Field-Interaction Type: p i j = v i ⋅ W i j ⊙ v j p_{ij}=v_icdot W_{ij}odot v_j pij=vi⋅Wij⊙vj。不同的field之间的交互都有一个隐矩阵 W i j ∈ R k × k W_{ij}in R^{k imes k} Wij∈Rk×k,参数量为 f ( f − 1 ) 2 × k × k frac{f(f-1)}{2} imes k imes k 2f(f−1)×k×k。
其中, v i , v j v_i,v_j vi,vj分别是第i和j个field的embedding。三种双线性特征交互的区别就是在于交互的粒度不同。(这里的“隐矩阵”可能名称不准确,是为了能够与FM中的隐向量类比理解)
下图为不同双线性特征交互方式的效果对比,结论说明没有哪一种双线性特征交互是最好的,不同的数据集适合的交互方式可能不同:
如上图-[FiBiNet结构]所示,FiBiNet会分别把原来的embedding E和经过SENet之后的SENet-Like embedding V都送入双线性特征交互层,得到 p = [ p 1 , . . . , p i , . . . , p n ] a n d q = [ q 1 , . . . , q i , . . . , q n ] , w h e r e p i , q i ∈ R k p=[p_1,...,p_i,...,p_n] and q=[q_1,...,q_i,...,q_n],where p_i,q_iin R^k p=[p1,...,pi,...,pn] and q=[q1,...,qi,...,qn],wherepi,qi∈Rk,然后将p和q进行拼接,给到DNN连接层中,最后使用sigmoid函数得到预测的点击概率。这与其他的ctr模型并无不同。
我们可以发现,FiBiNet移除SENet模块,其实就会退化为FNN模型;而移除DNN部分,它就可以退化为FM模型。
2. FiBiNet++
论文:FiBiNet++:Improving FiBiNet by Greatly Reducing Model Size for CTR Prediction
地址:https://arxiv.org/pdf/2209.05016.pdf
FiBiNet存在的问题是双线性特征交互层会导致第一层DNN连接层产生巨大参数量,由此提出了FIBiNet的改进版FiBiNet++,模型参数(非embedding参数)降低了12-16倍,并且效果还得到了提升。FiBiNet在bi-linear双线性特征交互层和SENet层都进行改进了。
FiBiNet++结构如下图[FiBiNet++结构]:
- 不同的特征(包括类别特征和数值特征)转换为Embeddings;
- Embeddings经过Bi-Linear+层,得到输出 H C M L H^{CML} HCML;
- Embeddings经过SENet+层,得到输出 V S E N e t + V^{SENet+} VSENet+;
- H C M L H^{CML} HCML和 V S E N e t + V^{SENet+} VSENet+拼接,输入到多层的MLP,最后使用sigmoid函数得到预测概率。
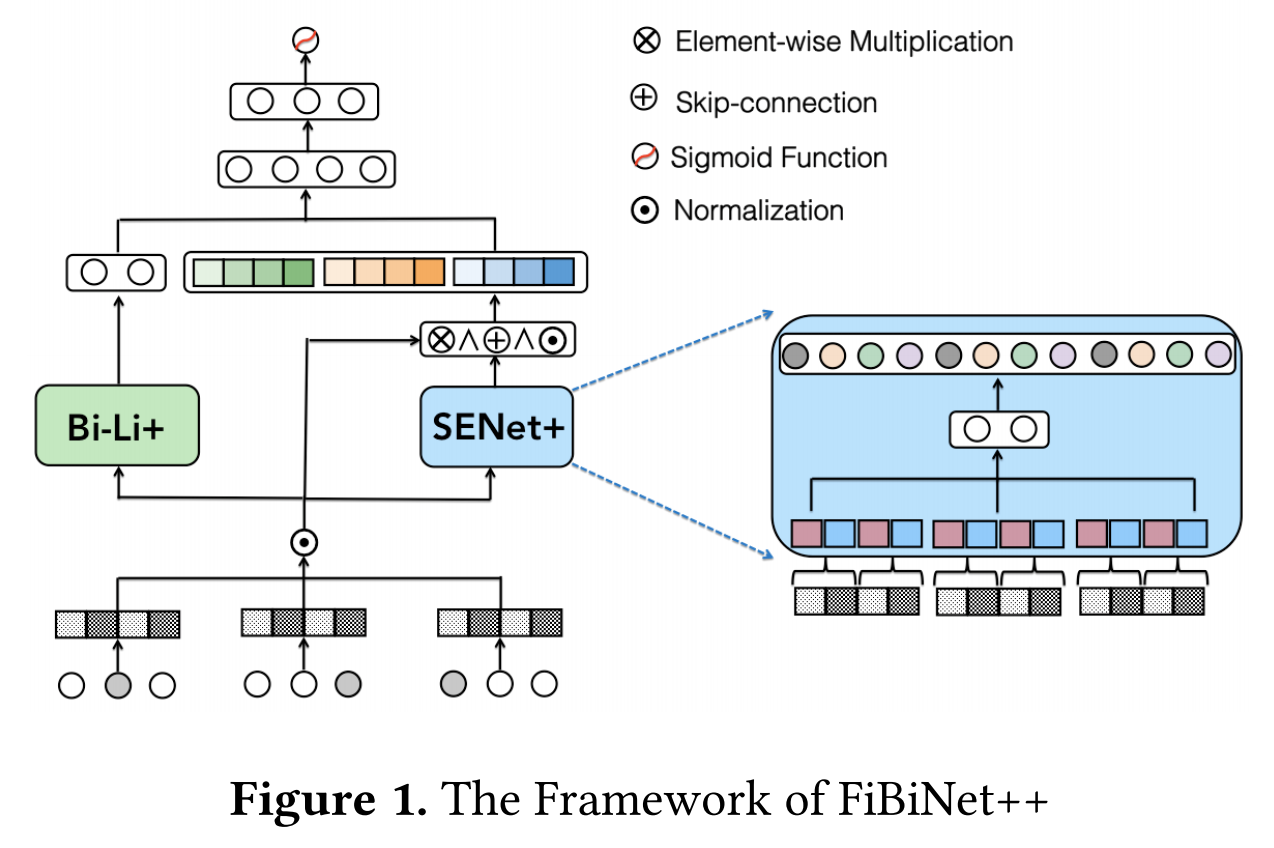
2.1 Bi-Linear+
上述已经介绍过,FiBiNet对特征
x
i
,
x
j
x_i,x_j
xi,xj交互的建模是通过引入可学习参数矩阵W的双线性函数,如下式: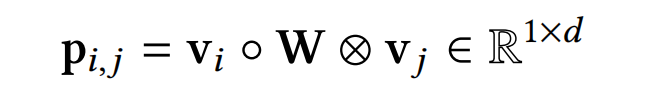
∘ , ⊗ circ,otimes ∘,⊗分别代表内积和哈达玛积( element-wise hadamard product)。W有三种参数形式:field all type、field each type、field interaction type。
但哈达玛积会产生大量的非必要参数,因此,FiBiNet++对双线性函数(bi-linear function)进行优化,提出bi-linear+,大大的减少双线性特征交互层的输出size。对于f个field,有下式:
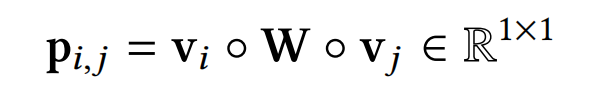

接着,再引入一个MLP层来叠加向量P,如下式:
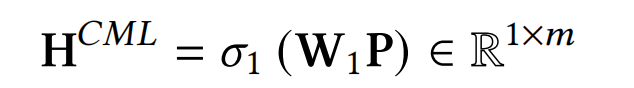
其中, W 1 ∈ R m × f × ( f − 1 ) 2 , σ ( ⋅ ) W_1in mathbb{R}^{m imes frac{f imes(f-1)}{2}},sigma(cdot) W1∈Rm×2f×(f−1),σ(⋅)是一个恒等映射函数,并且是不带非线性激活函数的,论文实验了加上非线性转换反而效果下降了。
2.2 SENet+
在FIBiNet模型中,SENet包括三个步骤:squeeze、excitation、re-weight。为了进一步增强模型表现,论文FiBiNet提出了SENet+,模块,SENet+包括了四个步骤:squeeze、excitation、re-weight、fuse,虽然前三个步骤相同,但每一步其实都经过了改进。
Squeeze. 考虑到更多的输入信息有利于提升模型的效果。因此,不同于SENet对每个feature使用mean pooling得到1-bit的统计信息,SENet+会将每个feature分割为多个组来得到多个1-bit的统计信息。
具体的,首先将每个经过标准化后的feature embedding v i ∈ R 1 × d v_iin mathbb{R}^{1 imes d} vi∈R1×d分割为g个组(g是一个超参数),如该式: v i = c o n c a t [ v i , 1 , v i , 2 , . . . , v i , g ] , w h e r e v i , j ∈ R 1 × d g v_i=concat[v_{i,1},v_{i,2},...,v_{i,g}],where v_{i,j}in mathbb{R}^{1 imes frac{d}{g}} vi=concat[vi,1,vi,2,...,vi,g],where vi,j∈R1×gd,代表着第i个特征中第j个组的信息。然后在 v i , j v_{i,j} vi,j上使用max pooling和mean pooling来表征该组的信息,得到如下结果:
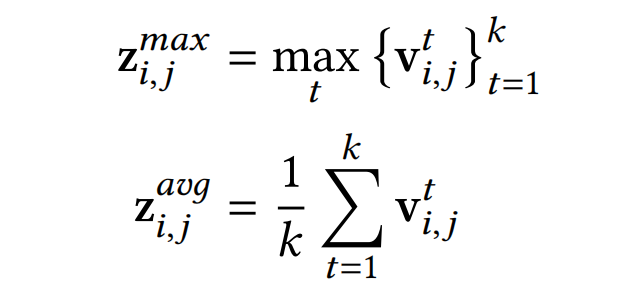
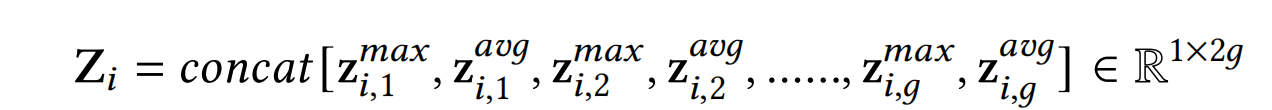
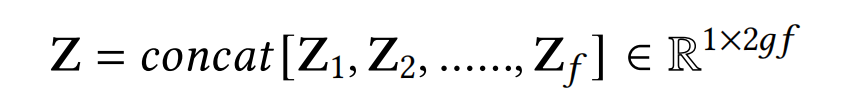
Excitation. 在SENet中,这一步得到的权重向量Z是field级别的,SENet+进一步细化,让权重向量改进为bit级别的,具体如下式: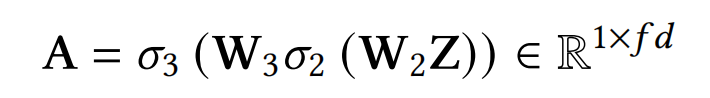
其中, W 2 ∈ R 2 g f r × 2 g f , W 3 ∈ R f d × 2 g f r , σ 2 ( ⋅ ) = R e l u ( ⋅ ) , σ 3 ( ⋅ ) W_2in mathbb{R}^{frac{2gf}{r} imes 2gf},W_3in mathbb{R}^{fd imes frac{2gf}{r}},sigma_2(cdot)=Relu(cdot),sigma_3(cdot) W2∈Rr2gf×2gf,W3∈Rfd×r2gf,σ2(⋅)=Relu(⋅),σ3(⋅)是一个恒等映射函数,r仍然是一个代表缩减比率的超参数。
Re-Weight. 这里就很好理解了,因为上一步Excitation得到的权重向量Z是bit级别的,那么feature embedding也对应每个bit进行缩放:

这里的N(V)为经过normalization之后的embeddings,后续会进一步详细介绍。
Fuse. SENet++增加的这一步骤思想有点像残差网络了,让上一步得到的feature embedding和原来的feature embedding进行bit-wise的相加,再采用layer normalization得到更好的特征表征:
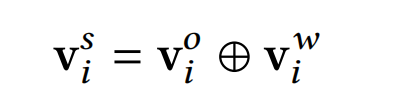
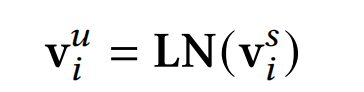
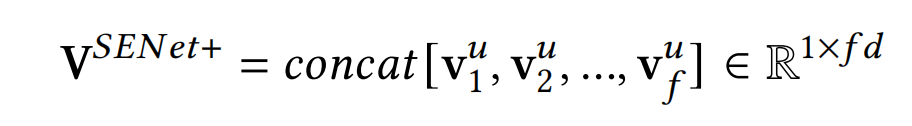
接下来的步骤,与FiBiNet大致相同了,将SENet+和Bi-Linear+的输出进行拼接即 H 0 = c o n c a t [ H C M L , V S E N e t + ] H_0=concat[H^{CML},V^{SENet+}] H0=concat[HCML,VSENet+],然后输入到多层MLP中,最后使用sigmoid函数得到预测概率。
2.3 特征处理
在这里,再介绍下论文使用的特征预处理方法。对于类别特征,使用常规处理,进行one-hot编码,映射到低维的向量。而对于数值类特征,论文会给每个field分配一个embedding,然后让归一化之后的特征值与embedding相乘,具体如下:
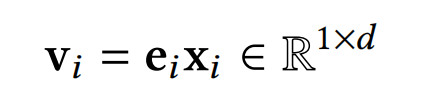
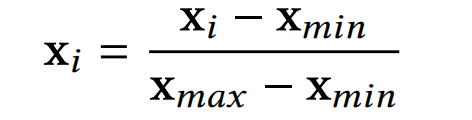
并且,类别特征和数值特征的标准化方法也不同:类别特征使用的是batch normalization,而数值特征使用的是layer normalization:
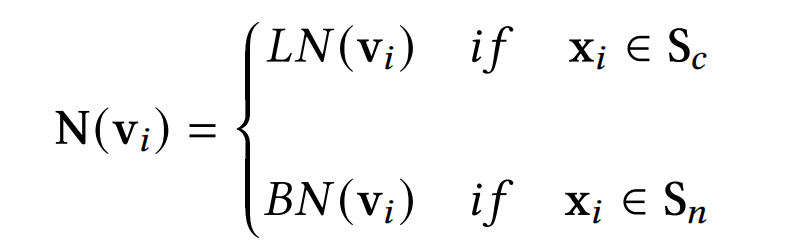
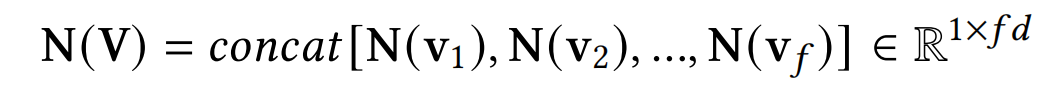
S c 、 S n S_c、S_n Sc、Sn分别代表类别特征和数值特征的集合。
3. 总结
FiBiNet在特征重要性方向发力,提出了两个独立可插拔的模块,分别为动态学习特征重要性的SENet和增强二阶特征交互的Bi-Linear。
FiBiNet++提出了Bi-Linear,大大减少了模型的参数量;还有SENet+,对SENet的每个步骤都进行改进。
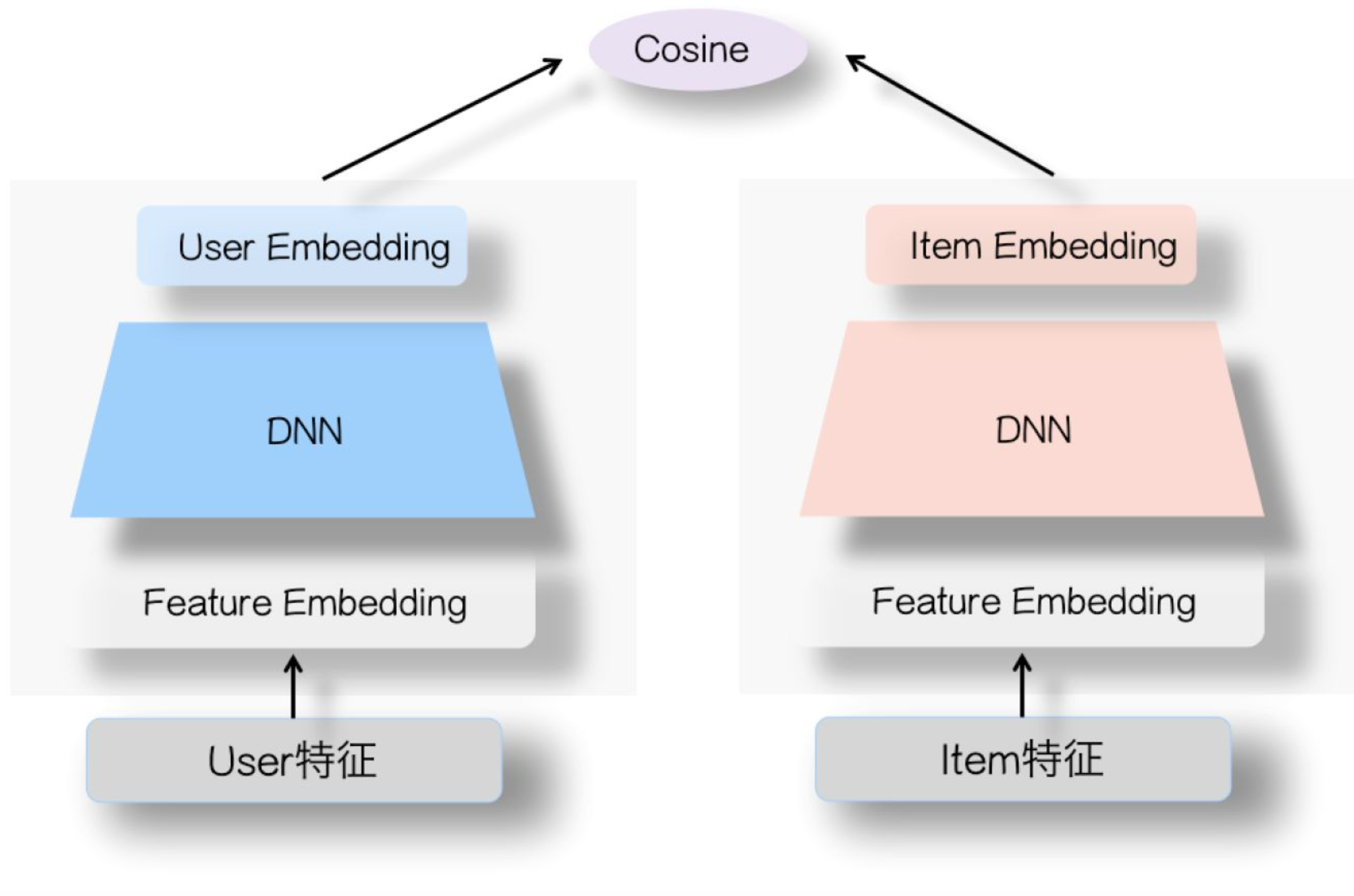
个人觉得FiBiNet系列模型的最大贡献是提出的这两个模块的实用性很高,可以很灵活插入到自己的模型中。比如SENet双塔召回,天猫电商领域推荐中的粗排模型也在item tower加入了这两个模块。
4. 代码实现
虽然论文提供了源码,不过其需要所有field embeddings的size相同。但在实际应用场景下,不同特征的embeddings size往往是会设置不同的,这里提供了支持不同field embeddings的size不等的实现:github






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结