您现在的位置是:首页 >其他 >Flink系列-10、Flink DataStream的Transformation网站首页其他
Flink系列-10、Flink DataStream的Transformation
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
官方网址:https://flink.apache.org/
学习资料:https://flink-learning.org.cn/

官网所有的Transformation操作
DataStream包括一系列的Transformation操作:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/index.html
KeyBy

按照指定的key来进行分流,类似于SQL中的groupBy。
示例
自定义数据源, 进行单词的计数
开发步骤
- 获取流处理运行环境
- 设置并行度
- 获取数据源
- 转换操作
(1) 以空白进行分割
(2) 给每个单词计数1
(3) 根据单词分组 - 求和
- 打印到控制台
- 执行任务
package batch.transformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
/**
* @author lwh
* @date 2023/4/25
* @description 演示keyBy方法 也使用了aggregate方法的sum求和
**/
public class KeyByDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置全局并行度为1
env.setParallelism(1);
// Get source
DataStreamSource<Tuple2<String, Integer>> source = env.fromElements(
Tuple2.of("篮球", 1),
Tuple2.of("篮球", 2),
Tuple2.of("篮球", 3),
Tuple2.of("足球", 3),
Tuple2.of("足球", 2),
Tuple2.of("足球", 3)
);
// 分组加聚合计算, 类似SQL的group by 后加聚合函数求每个组的数据
// 有一点要注意的是, SQL中是对分组后的每个组的全量数据做聚合计算, 是批计算
// 在流计算内,是来一条计算一条,也就是每个组的数据,挨个进行计算,求和累加,所以结果中最后一个打印的数据才是最终的求和结果
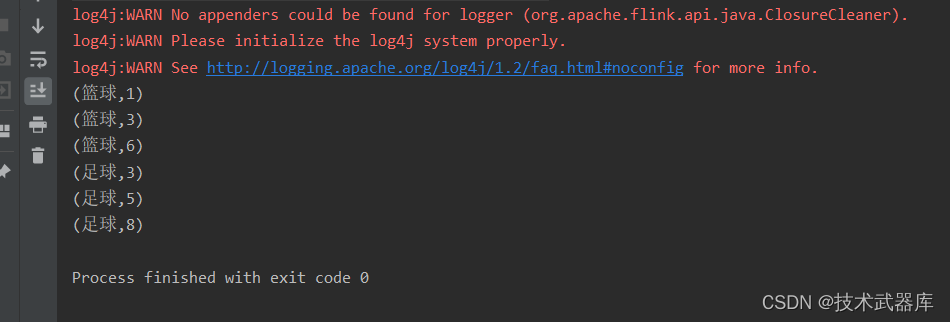
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = source.keyBy(0).sum(1);
// 如果不分组的话, sum的结果是 1+2+3+3+2+3 = 14 分组后是 篮球 6 足球 8
sum.print();
env.execute();
}
}
Reduce

可以对一个datastream或者一个group来进行聚合计算,最终聚合成一个元素
数据源
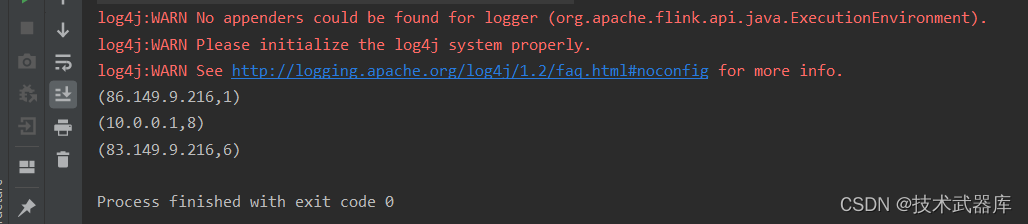
86.149.9.216 10001 17/05/2015:10:05:30 GET /presentations/logstash-monitorama-2013/images/github-contributions.png
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
83.149.9.216 10002 17/05/2015:10:06:53 GET /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:06:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:07:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:08:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:09:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:10:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:16:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
10.0.0.1 10003 17/05/2015:10:26:53 POST /presentations/logstash-monitorama-2013/css/print/paper.css
示例
读取本地文件,根据IP地址统计计数
步骤
- 获取ExecutionEnvironment运行环境
- 使用fromCollection构建数据源
- 使用reduce执行聚合操作
- 打印测试
package batch.transformation;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.MapOperator;
import org.apache.flink.api.java.operators.ReduceOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
/**
* @author lwh
* @date 2023/4/25
* @description
**/
public class ReduceDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> logSource = env.readTextFile("data/input/apache.log");
// 提取IP, 后面都跟上1(作为元组返回)
MapOperator<String, Tuple2<String, Integer>> ipWithOne = logSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String ip = value.split(" ")[0];
return Tuple2.of(ip, 1);
}
});
// 分组 + reduce聚合
UnsortedGrouping<Tuple2<String, Integer>> grouped = ipWithOne.groupBy(0);
// reduce 聚合
ReduceOperator<Tuple2<String, Integer>> result = grouped.reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
result.print();
}
}
Aggregations
按照内置的方式来进行聚合。例如:SUM/MIN/MAX…
示例
请将以下元组数据,使用aggregate操作进行单词统计
("java" , 1) , ("java", 1) ,("scala" , 1)
步骤
- 获取StreamExecutionEnvironment运行环境
- 使用fromCollection构建数据源
- 使用groupBy按照单词进行分组
- 使用aggregate对每个分组进行SUM统计
- 打印测试
package batch.transformation;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Arrays;
/**
* @author lwh
* @date 2023/4/25
* @description 使用内置的方式进行聚合数据 , aggregate只能将数据作用到元组上,例如:sumMaxmin
**/
public class StreamAggregateDemo {
public static void main(String[] args) throws Exception {
//1:获取ExecutionEnvironment运行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2: 使用`fromCollection`构建数据源
DataStreamSource<Tuple2<String, Integer>> tupleDataStream = env.fromCollection(
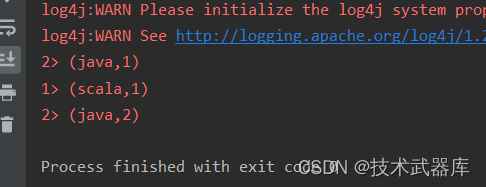
Arrays.asList(Tuple2.of("java", 1), Tuple2.of("java", 1), Tuple2.of("scala", 1)));
//3. 使用groupBy按照单词进行分组
KeyedStream<Tuple2<String, Integer>, Tuple> keyByStream = tupleDataStream.keyBy(0);
//4. 使用aggregate对每个分组进行SUM统计
SingleOutputStreamOperator<Tuple2<String, Integer>> resultDataStream = keyByStream.sum( 1);
resultDataStream.printToErr();
env.execute();
}
}
Union
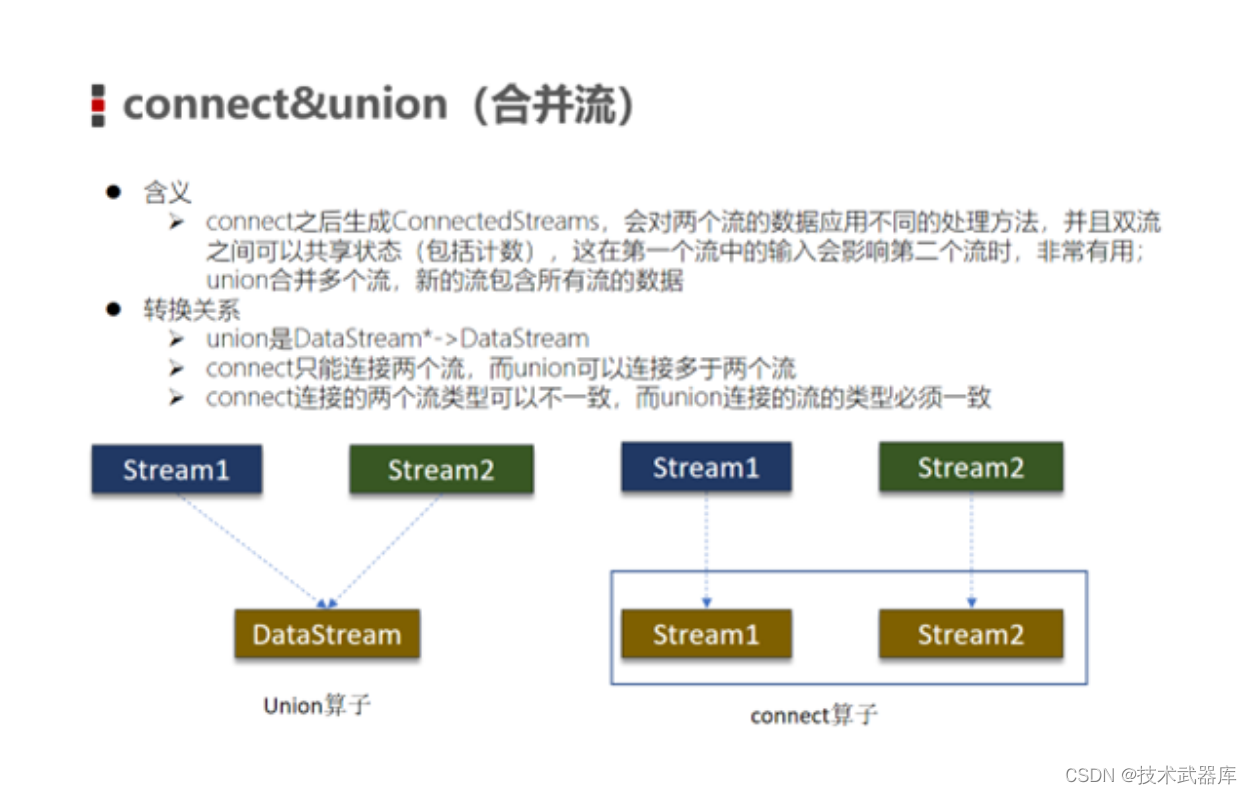
将两个DataStream取并集,不会去重。
两个DS的泛型需要一致
示例
将以下数据进行取并集操作
数据集1
"hadoop", "hive", "flume"
数据集2
"hadoop", "hive", "spark"
步骤
- 构建流处理运行环境
- 使用fromCollection创建两个数据源
- 使用union将两个数据源关联在一起
- 打印测试
package batch.transformation;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
/**
* @author lwh
* @date 2023/4/25
* @description 合并多个流,类型必须要一致
**/
public class UnionDemo {
public static void main(String[] args) throws Exception {
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> source1 = env.fromElements("hadoop", "hive", "flume");
DataSource<String> source2 = env.fromElements("yarn", "hive", "spark");
source1.union(source2).print();
/*
Union算子 会进行合并, 不会进行重复判断
Union算子 必须进行 同类型元素的合并, 哪怕是顶级类Object也不行, 必须是实体类(撇除继承关系)的类型一致才可以
*/
}
}

Connect
DataStream,DataStream → ConnectedStreams:连接两个保持他们类型的数据流,两个数据流被 Connect 之后,只是被放在了一个同一个流中,内部依然保持各自的数据和形式不发生任何变化,两个流相互独立, 作为对比,Union后是真的变成一个流了。
示例
读取两个不同类型的数据源,使用connect进行合并打印。

开发步骤
- 创建流式处理环境
- 添加两个自定义数据源
- 使用connect合并两个数据流,创建ConnectedStreams对象
- 遍历ConnectedStreams对象,转换为DataStream
- 打印输出,设置并行度为1
- 执行任务
package batch.transformation;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Random;
/**
* @author lwh
* @date 2023/4/25
* @description connect连接2个流,流类型可以不一致
**/
public class ConnectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> source1 = env.addSource(new IncreaseByOneSource());
DataStreamSource<Integer> source2 = env.addSource(new IncreaseByOneSource());
ConnectedStreams<Integer, Integer> connectedStreams = source1.connect(source2);
/*
针对connect后的Stream, 所有方法都会传入特殊的处理, 比如:
map方法需要实现CoMapFunction 而非我们前面用的MapFunction
这一类特殊的处理, 比如CoMapFunction, 内就有两个map方法
1个处理连接的第一个Stream
另一个处理连接的另一个Stream
*/
// CoMapFunction的3个泛型: 泛型1: 第一个Stream的输入类型 泛型2: 第二个Stream的输入类型 泛型3: 返回的类型(要求两个map方法的返回值类型一致)
SingleOutputStreamOperator<String> map = connectedStreams.map(new CoMapFunction<Integer, Integer, String>() {
@Override
public String map1(Integer value) throws Exception {
return "map1:" + value;
}
// map1和map2的返回值类型需要一致, 因为类的第三个泛型约束着
@Override
public String map2(Integer value) throws Exception {
return "map2:" + value;
}
});
map.print("》》》》》》");
System.out.println();
env.execute();
}
static class IncreaseByOneSource implements SourceFunction<Integer> {
private boolean isRun = true; // Flag for run
private final Random random = new Random();
@Override
public void run(SourceContext<Integer> ctx) throws Exception {
while (isRun) {
ctx.collect(random.nextInt(999));
Thread.sleep(1000L);
}
}
@Override
public void cancel() {
this.isRun = false;
}
}
}

Split和select
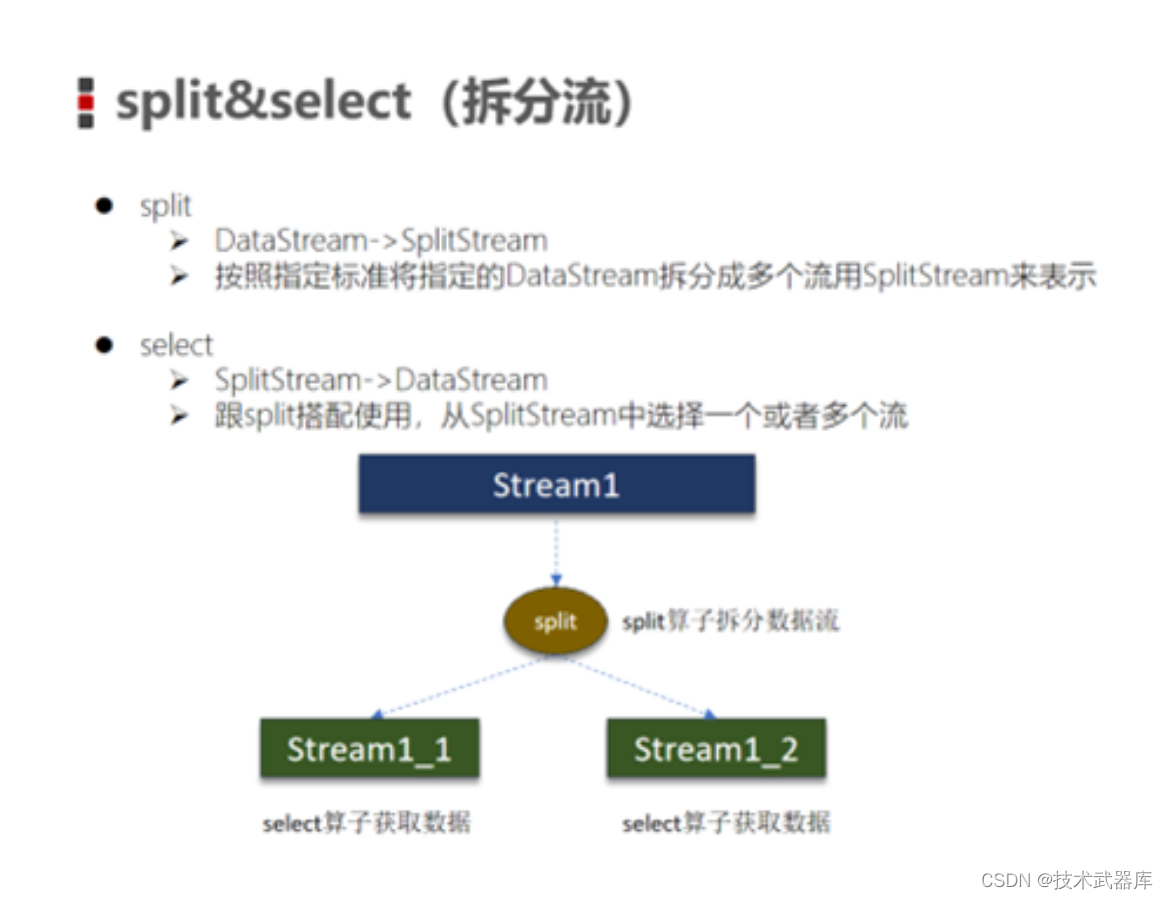
Split就是将一个DataStream分成两个或者多个DataStream
Select就是获取分流后对应的数据
简单认为就是, Split会给数据打上标记
然后通过Select, 选择标记来划分出不同的Stream
效果类似KeyBy分流,但是比KeyBy更自由些,可以自由打标记并进行分流。
示例
加载本地集合(1,2,3,4,5,6), 使用split进行数据分流,分为奇数和偶数. 并打印奇数结果
开发步骤
- 创建流处理环境
- 设置并行度
- 加载本地集合
- 数据分流,分为奇数和偶数
- 获取分流后的数据
- 打印数据
- 执行任务
package batch.transformation;
import org.apache.flink.streaming.api.collector.selector.OutputSelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
/**
* @author lwh
* @date 2023/4/25
* @description 使用split分流打标记,select在根据标记获取分流后的数据
**/
public class SplitSelectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<Integer> source = env.fromElements(1, 2, 3, 4, 5, 6);
// 通过Split + Select的组合, 区分出偶数和奇数
// SplitStream被标记为弃用了, 但是源码中没有相关解释, 可能以后的新版本会有对应的替代对象, 目前先继续使用
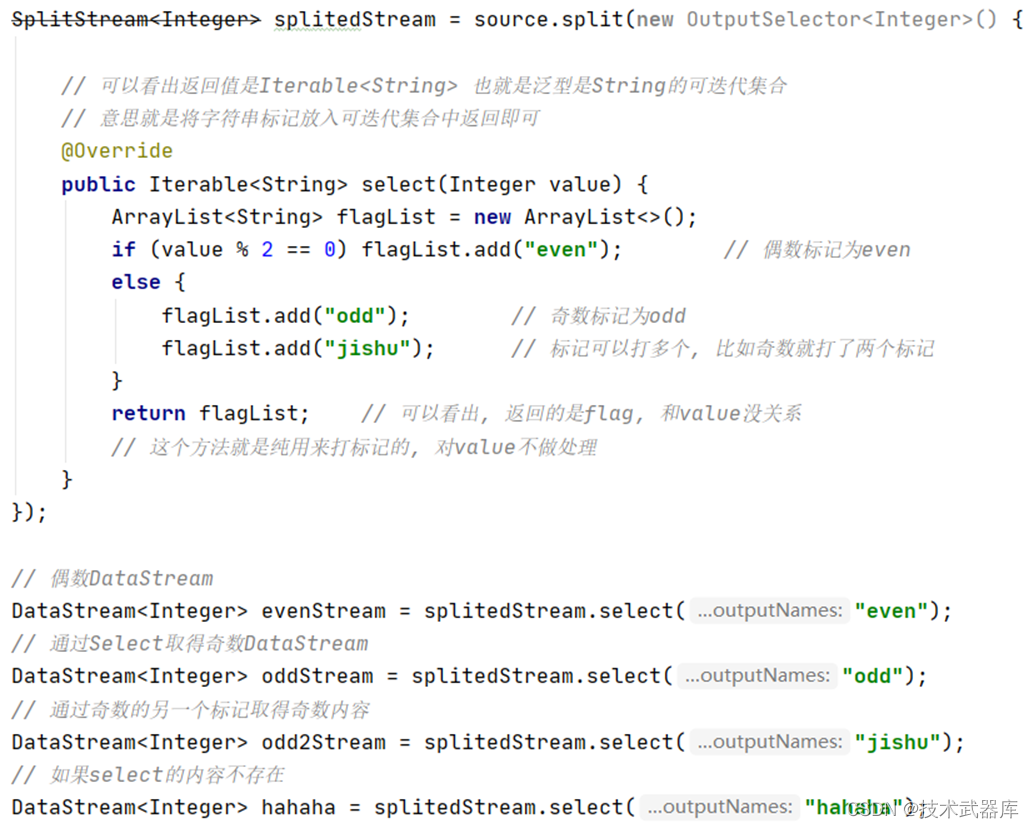
SplitStream<Integer> splitedStream = source.split(new OutputSelector<Integer>() {
// 可以看出返回值是Iterable<String> 也就是泛型是String的可迭代集合
// 意思就是将字符串标记放入可迭代集合中返回即可
@Override
public Iterable<String> select(Integer value) {
ArrayList<String> flagList = new ArrayList<>();
if (value % 2 == 0) {
flagList.add("even"); // 偶数标记为even
} else {
flagList.add("odd"); // 奇数标记为odd
flagList.add("jishu"); // 标记可以打多个, 比如奇数就打了两个标记
}
return flagList; // 可以看出, 返回的是flag, 和value没关系
// 这个方法就是纯用来打标记的, 对value不做处理
}
});
// 偶数DataStream
DataStream<Integer> evenStream = splitedStream.select("even");
// 通过Select取得奇数DataStream
DataStream<Integer> oddStream = splitedStream.select("odd");
// 通过奇数的另一个标记取得奇数内容
DataStream<Integer> odd2Stream = splitedStream.select("jishu");
// 如果select的内容不存在
DataStream<Integer> hahaha = splitedStream.select("hahaha");
evenStream.print("even>>>");
oddStream.print("odd>>>");
odd2Stream.print("odd2>>>");
// hahaha标记不存在, 所以无法得到内容, 这个DataStream是空的
hahaha.print("hahaha>>>");
env.execute();
}
}






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结