您现在的位置是:首页 >技术交流 >CVPR 2023 | 语义分割新范式:点监督遇上隐式场网站首页技术交流
CVPR 2023 | 语义分割新范式:点监督遇上隐式场
密集预测(dense prediction)网络是解决诸如语义分割和图像本征分解(intrinsic decomposition)等场景理解问题的基本框架。现有工作[1-2] 通常使用像素级标注作为训练密集预测模型的监督。但是像素级别的密集标注非常昂贵, 对一些任务也无法给出精准的像素标注,如在图像本征分解中为野外(in-the-wild)图像标注特定的反射率。这促使我们转而利用廉价的稀疏点监督来训练密集预测网络。
为利用点监督的自身特性,我们提出了一种基于坐标点查询的密集预测网络,它可以预测图像空间中每个连续二维坐标点的对应值,该方法被命名为密集预测场(Dense Prediction Field, DPF)。受最近成功的隐式表示[3-4]的启发,我们使用隐式神经函数来实现 DPF。DPF 为连续的二维空间位置生成可解析的视觉特征,从而允许输出任意分辨率的预测结果。

论文题目:
DPF: Learning Dense Prediction Fields with Weak Supervision
论文链接:
https://arxiv.org/abs/2303.16890
代码链接:https://github.com/cxx226/DPF

一、解决方案
网络架构
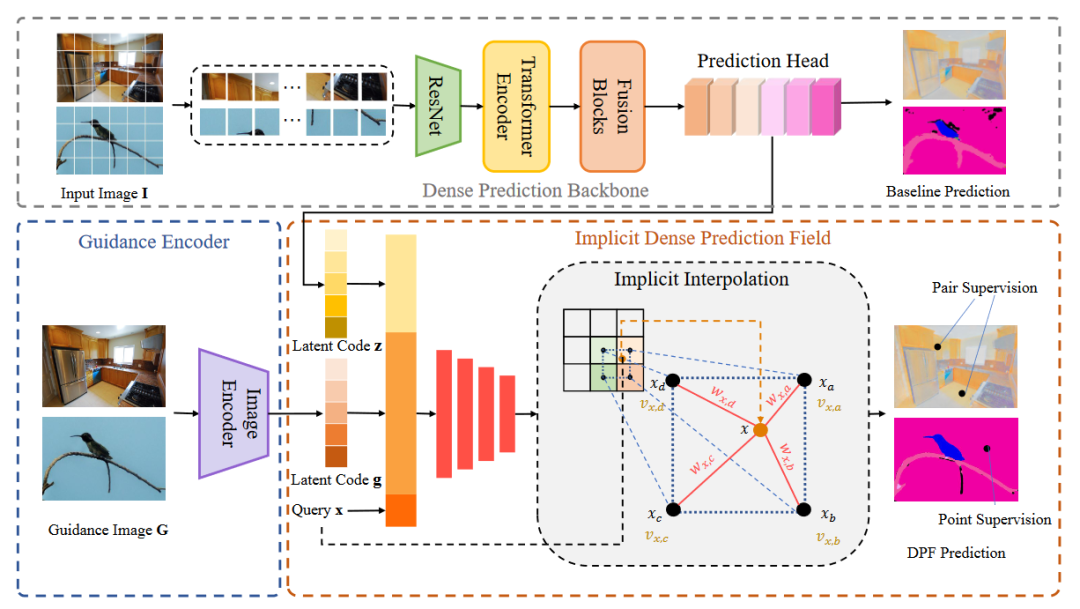
本文所提出的DPF的总体框架如图1所示。我们的网络由三个组件组成:密集预测主干
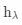
、guidance编码器 和隐式密集预测场 。总体框架可以被公式化为:
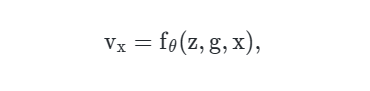
其中 和 分别是从
和 中提取的潜在编码(latent code), 是点查询坐标。
密集预测主干 此前的工作[5]通常将基于图像的隐式场公式化为:
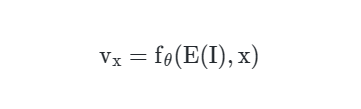
其中 是一个编码器网络,用于提取低级视觉特征作为潜在编码。然而,考虑到在密集预测任务中由专门设计的密集预测网络提取的高级语义信息的重要性,我们提出了一种新的范式,该范式结合了密集预测主干和隐式场。具体地,给定输入图像 ,我们首先将图像馈送到密集预测主干中:
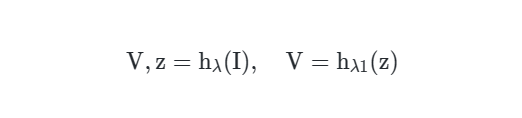
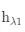
是 的预测头, 是基线密集预测值, 是从 的中间层的输出中提取的高级特征。在训练过程中,我们对 施加损失作为辅助监督,从而对隐式场的预测值提供了约束,并促进潜在编码 学习相应的高级视觉信息。上述范式可以应用于任何即插即用的密集预测模型之上。
guidance编码器受此前的工作启发[6],为了使密集预测的结果更加平滑,我们还引入了一个额外的guidance图像 。我们认为,guidance图像的内容可以有利于密集预测场中插值参数的学习(下一小节中介绍),并使DPF输出更好地与高分辨率guidance图像对齐。我们直接使用不同分辨率的输入图像作为guidance图像,而非引入需要特定预处理的图像(例如,[6]中使用边缘检测结果作为引导)。我们使用EDSR网络作为guidance编码器,并从guidance图像中提取特征:
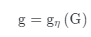
也用作潜在编码,它包含与 互补的低级局部特征。EDSR模型由16个的残差块组成,我们使用最后一个残差块的输出作为g。潜在编码 与 都提供了重要信息来支持DPF的学习。它们的效果和差异将如实验中图3所示。在下一小节中,我们将详细描述我们的隐式密集预测场。
隐式密集预测场
给定图像平面上一个点的坐标 ,我们的目标是在密集预测场中查询其对应的值 。值得注意的是, 可以是从连续空间采样的随机坐标值,因此我们不能直接从离散密集预测图中提取相应的值。获得 的一种简单方法是对相邻像素的密集预测值进行插值,如图1所示(Implicit Interpolation)。具体地,对应的密集预测值 被定义为:
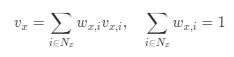
其中 是 的相邻像素集合, 是像素 的密集预测值, 为 和 之间的插值权重。对于具有多个语义类别的场景解析任务,密集预测值是长度 的向量,其中 是类别的数量。对于图像本征分解中的反射率预测,这些值是标量。在实践中,我们以图像中心为原点,将所有坐标归一化为 ,从而使我们能够方便地组合不同分辨率的潜在编码( 和 )。
受隐式表达的影响,我们使用深度神经网络来获得插值权重和密集预测值。给定输入图像特征 和引导特征 ,我们利用MLP来学习坐标 与其相邻像素 之间的插值权重和值:
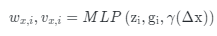
其中 是从 和 中提取的像素 的对应潜码。 是相对坐标, 是像素 的坐标。相对坐标能够表示查询点 与其相邻像素 之间的空间相关性。此外,受[7]启发,我们引入了位置编码
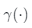
,以利用更高频率的空间信号:
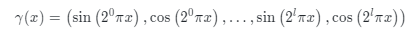
在实践中,我们设置 。在Eq.6之后,插值权重通过softmax层进行归一化:

综合积分插值和权重与值的计算,我们的隐式密集预测场的公式可以表示为:
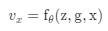
其中
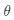
是网络参数。
二、实验结果
我们分别在语义分割数据集PASCALContext、ADE20K和图像本征分解数据集IIW上进行了定量和定性实验,分别如下所示:
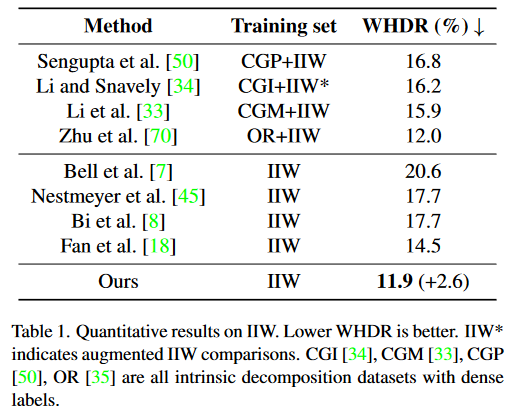
表1 DPF在IIW上的定量结果
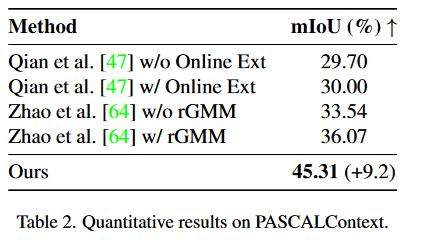
表2 DPF在PASCALContext上的定量结果
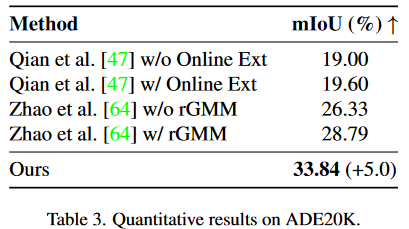
表3 DPF在ADE20K上的定量结果
DPF对不同backbone的影响,包含使用CNN-based网络(FASTFCN[8])与Transformer-based网络(DPT[1])两组baseline,均有大幅提升:

表4 DPF使用不同backbone的定量结果
对PASCALContext(第一行)、ADE20K(第二行)和IIW(最后一行)进行定性比较的结果:
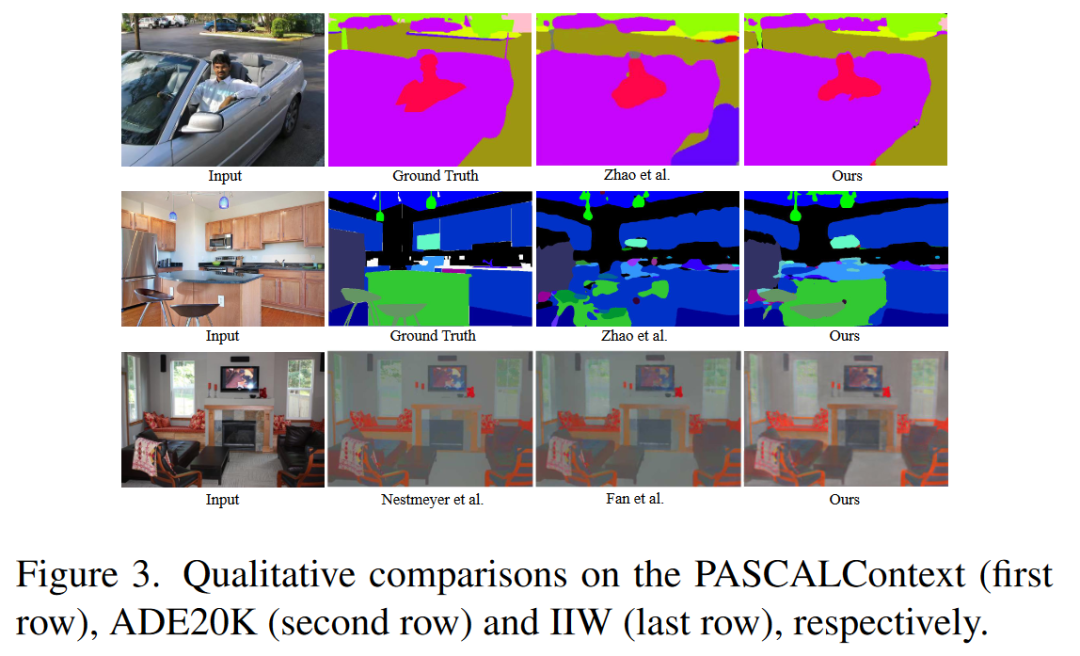
图2 DPF使用不同backbone的定量结果
为探究backbone与guidance encoder的影响,我们还对latent code z与g分别进行了t-SNE可视化:

图3 latent code的t-SNE可视化
三、总结
在本文中,为解决像素级标注的昂贵代价,我们专注于点监督密集预测,并提出了一种针对点坐标查询进行密集值预测的新范式——密集预测场 (DPF)。我们使用隐式神经函数对 DPF 进行建模,从而与点监督进行兼容,并生成更加平滑的预测结果。为在语义分割和图像本征分解任务上验证 DPF 的有效性,我们以三个大型公共数据集PASCALContext、ADE20K和IIW为benchmark,DPF在上述数据集上均达到SOTA的实验结果,相比baseline有显著提升。
参考文献
1. Vision transformers for dense prediction. In ICCV (2021)
2. Cerberus transformer: Joint semantic, affordance and attribute parsing. In CPVR (2022)
3. Deepsdf: Learning continuous signed distance functions for shape representation. In ICCV (2019)
4. LODE: Locally Conditioned Eikonal Implicit Scene Completion from Sparse LiDAR. In ICRA (2023)
5. Joint implicit image function for guided depth super-resolution. In ACMMM (2021)
6. Revisiting deep intrinsic image decompositions. In CVPR (2018)
7. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV (2020)
8. Fastfcn: Rethinking dilated convolution in the backbone for semantic segmentation. In CVPR (2019)
作者:陈小雪
Illustration by IconScout Store from IconScout
-The End-






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结