您现在的位置是:首页 >其他 >HBase进阶——文件的合并、 MemStore Flush、StoreFile Compaction、 Region Split、高可用与预分区介绍网站首页其他
HBase进阶——文件的合并、 MemStore Flush、StoreFile Compaction、 Region Split、高可用与预分区介绍
系列文章目录
centos7虚拟机在集群zookeeper上面配置hbase的具体操作步骤
文章目录
2.在 conf 目录下创建 backup-masters 文件
3.在 backup-masters 文件中配置高可用 HMaster 节点
前言
本文主要介绍HBase如何进行分区与数据处理等等操作,下面的案例经供参考。
一、HBase的架构原理
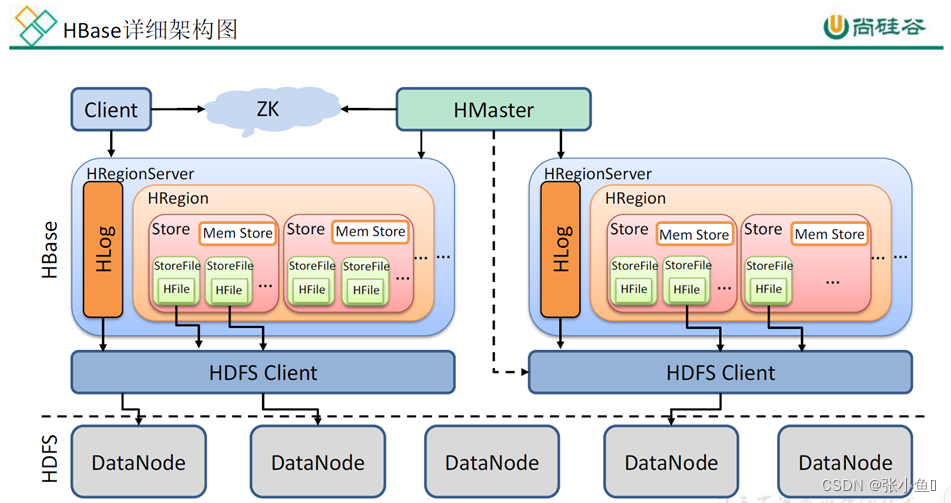
1、StoreFile
保存实际数据的物理文件,StoreFile 以 HFile 的形式存储在 HDFS 上。每个 Store 会有一个或多个 StoreFile(HFile),数据在每个 StoreFile 中都是有序的。
2、MemStore
写缓存,由于 HFile 中的数据要求是有序的,所以数据是先存储在 MemStore 中,排好序后,等到达刷写时机才会刷写到 HFile,每次刷写都会形成一个新的 HFile。
3、WAL
由于数据要经 MemStore 排序后才能刷写到 HFile,但把数据保存在内存中会有很高的概率导致数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入 MemStore 中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
二、HBase的shell操作
进入HBase的shell里面进行操作以便理解regionserver如何实现数据的存取等等操作
2.1、创建表与写入数据
创建表stu
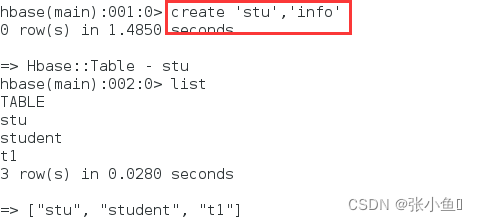
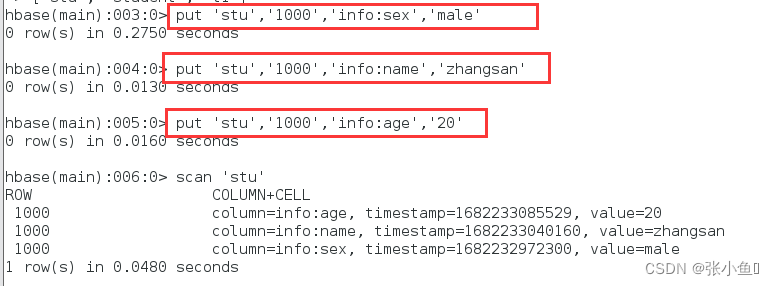
插入数据
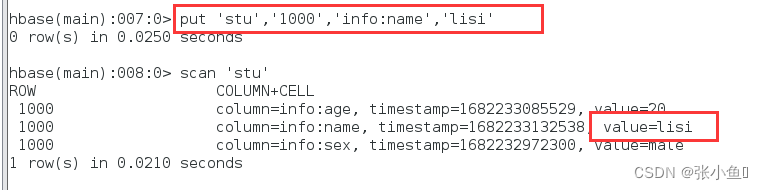
插入数据李四这个数据,scan查看时最新的数据
可以直接写scan查看其操作的说明
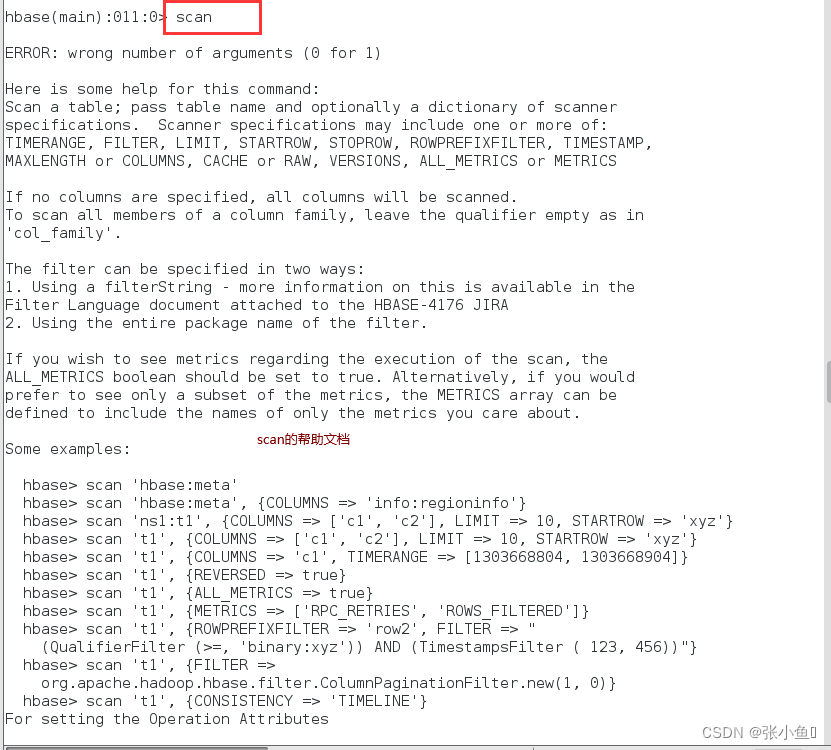
查看所有的数据内容
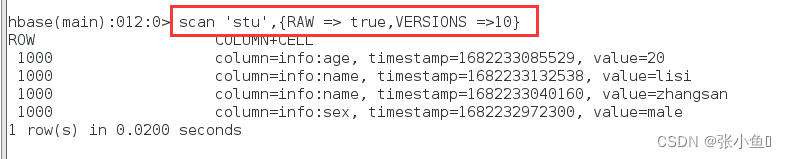
2.2、对数据进行刷洗与上传到web页面
Flush写入内存里面
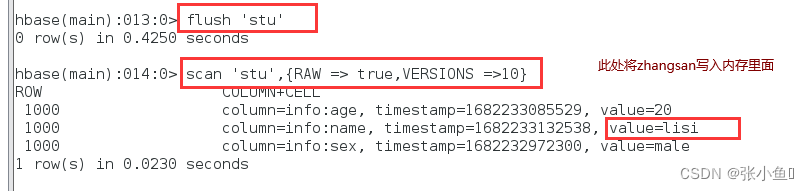
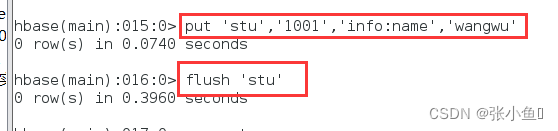
再次插入1001里面的wangwu数据,此处flush上传到内存里面,此时web端应该有两个小文件
刷洗之后只有最新更新的最新数据
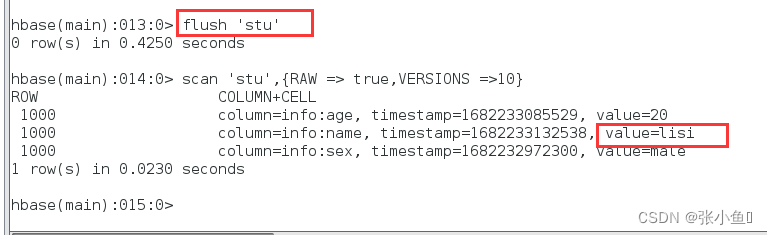
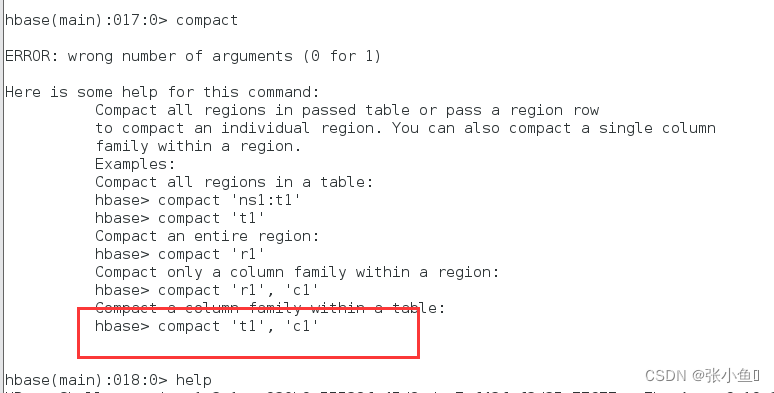
2.3、Compact合并文件
Compact合并文件的帮助文档
再次插入小王和小赵的数据,上传合并一下
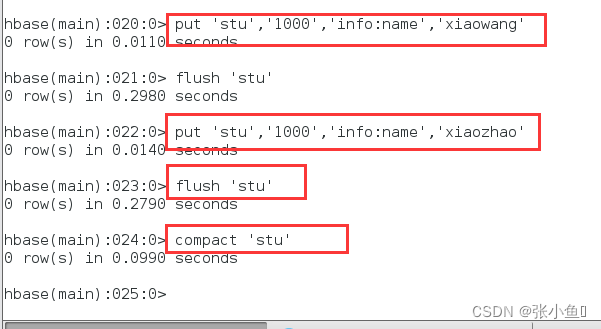
刷洗一遍最后只有一个文件了。里面只有最新的1000小赵和1001的王五数据
Ps:此处会删除过时的数据,保存最新的数据到大文件里面
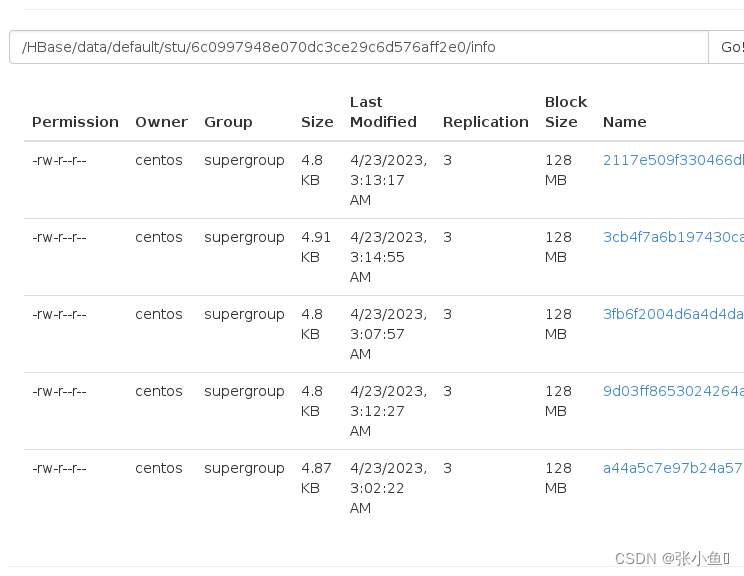
最终的页面结果
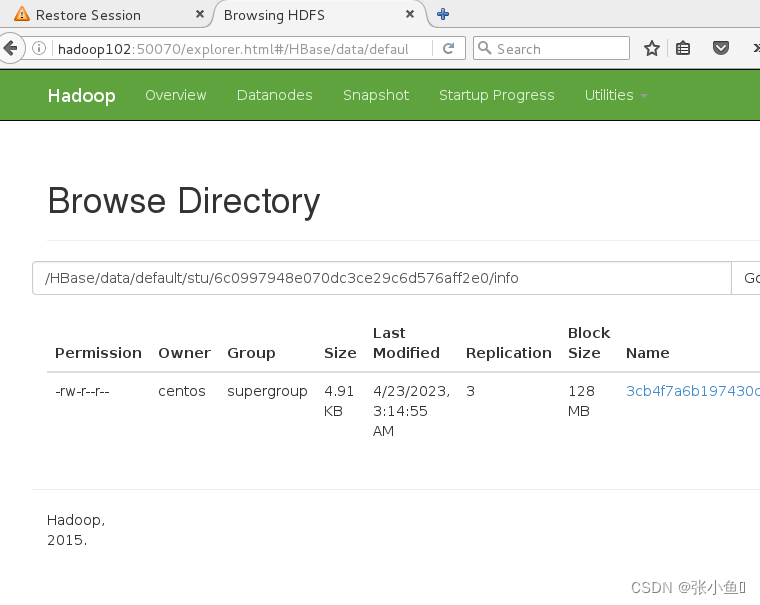
2.4、再次插入数据验证
再次插入1005:小红
刷洗一遍:flush
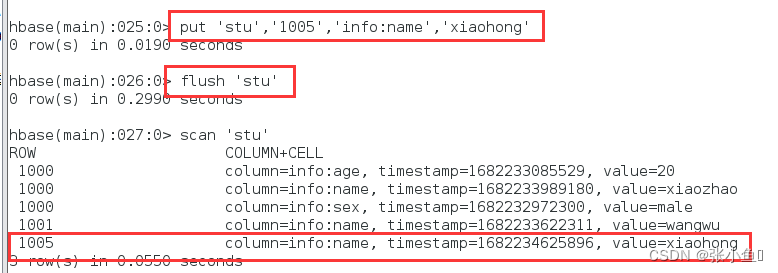
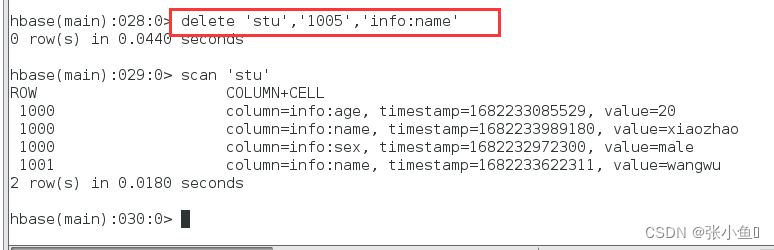
再次删除小红
使用Scan命令使其显示所有版本信息
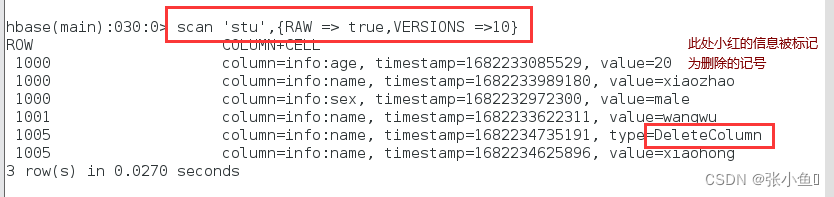
在终端可以查看最新的文件信息【此处的最新文件是一个小文件】
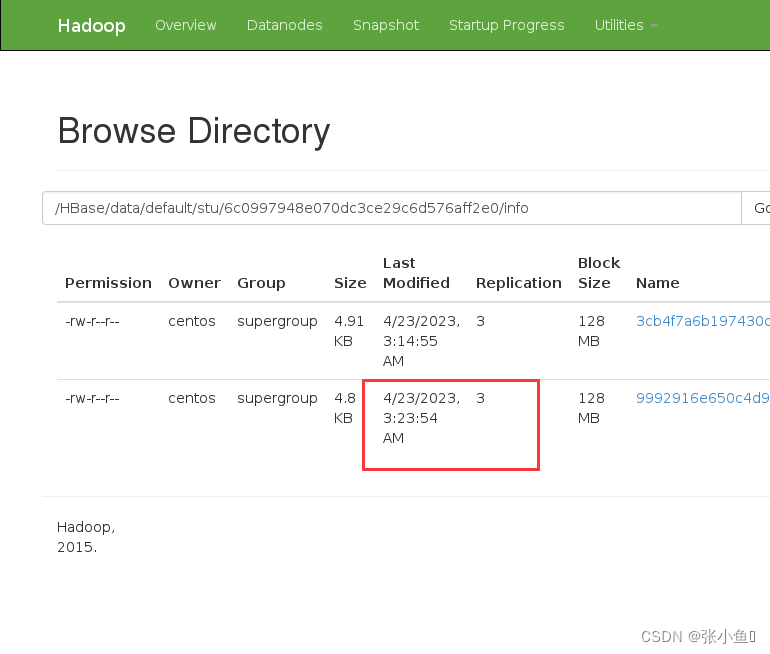
2.5、插入新的数据进行实验
插入一行1006
删除1006
再次查看1006
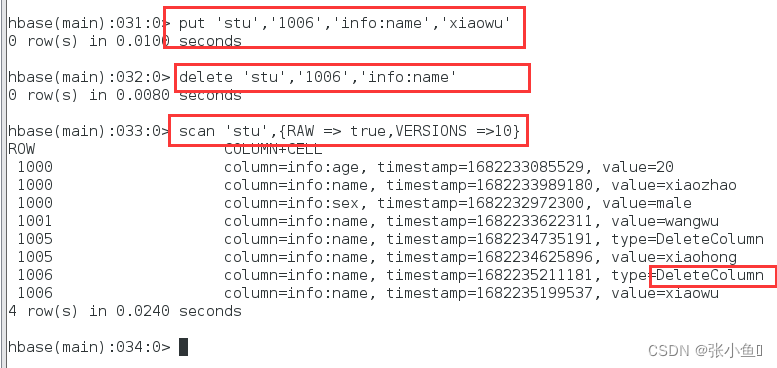
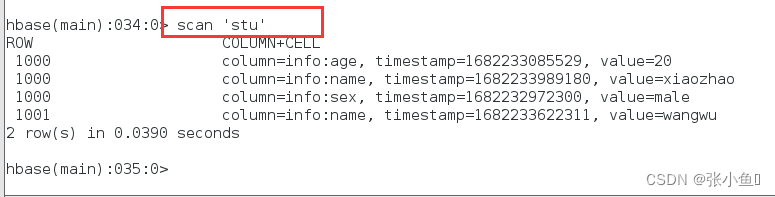
刷洗之后,会保留删除的标记
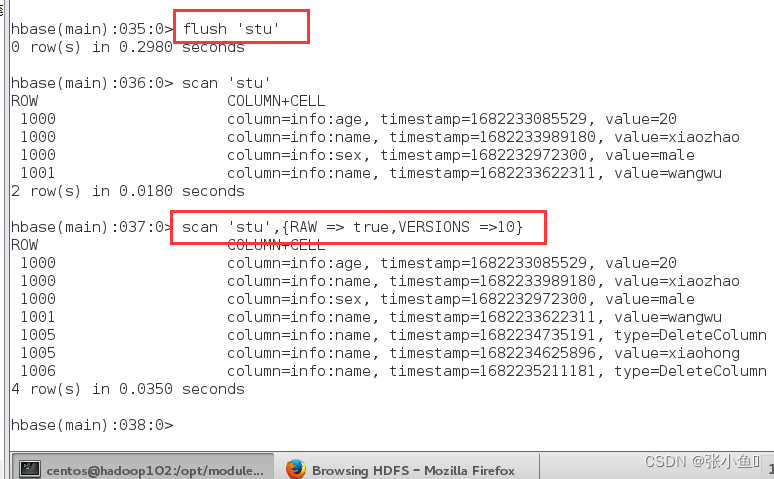
compact上传合并一下
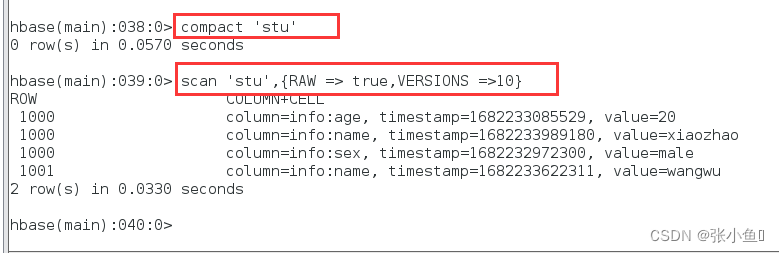
终端查看
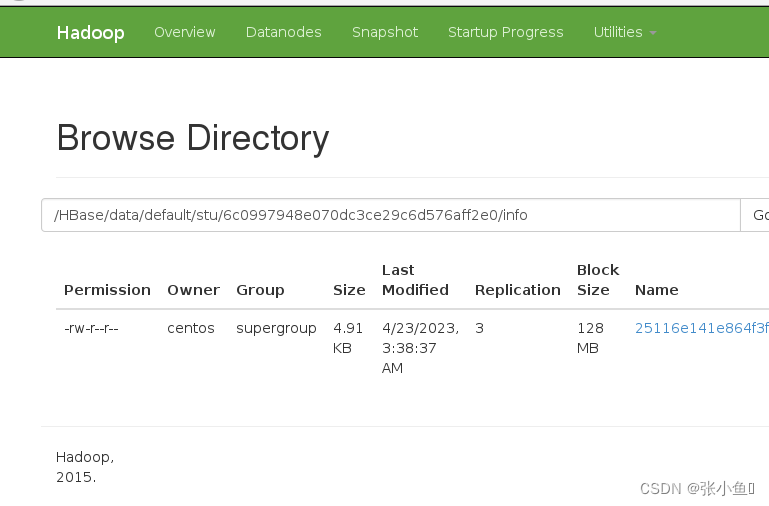
此处的文件就只有一个合并的最终版本了。
三、对regionserver的一些解释说明
3.1、 MemStore Flush
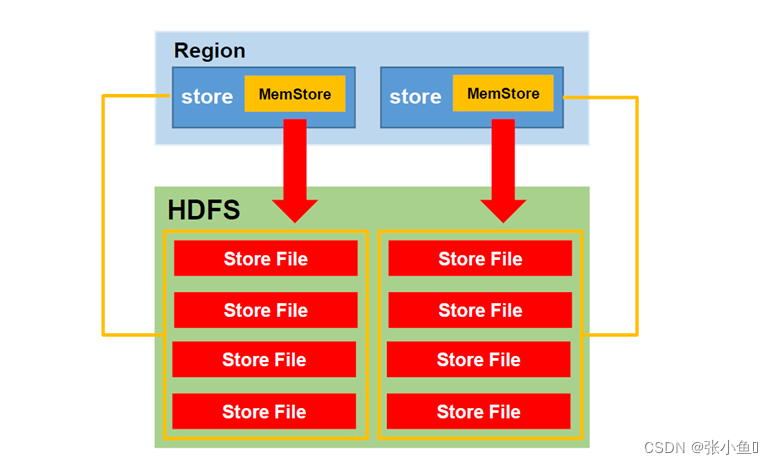
MemStore 刷写时机:
1.当某个memstroe 的大小达到了hbase.hregion.memstore.flush.size(默认值128M),
其所在region 的所有memstore 都会刷写。
当memstore 的大小达到了
hbase.hregion.memstore.flush.size(默认值128M)
* hbase.hregion.memstore.block.multplier(默认值4)
时,会阻止继续往该memstore 写数据
2.当 region server 中 memstore 的总大小达到
java_heapsize
*hbase.regionserver.global.memstore.size(默认值 0.4)
*hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95),
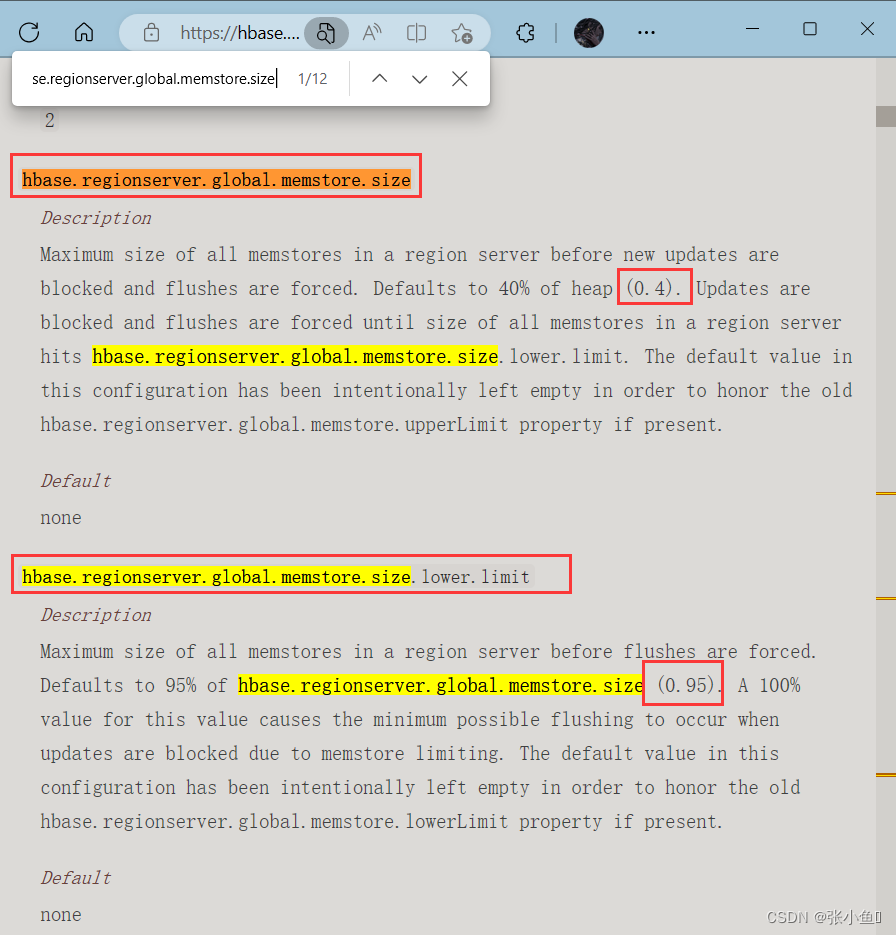
region 会按照其所有 memstore 的大小顺序(由大到小)依次进行刷写。直到 region server
中所有 memstore 的总大小减小到上述值以下。【0.38(=0.4*0.95)】
当 region server 中 memstore 的总大小达到
java_heapsize*hbase.regionserver.global.memstore.size(默认值 0.4)
时,会阻止继续往所有的 memstore 写数据。
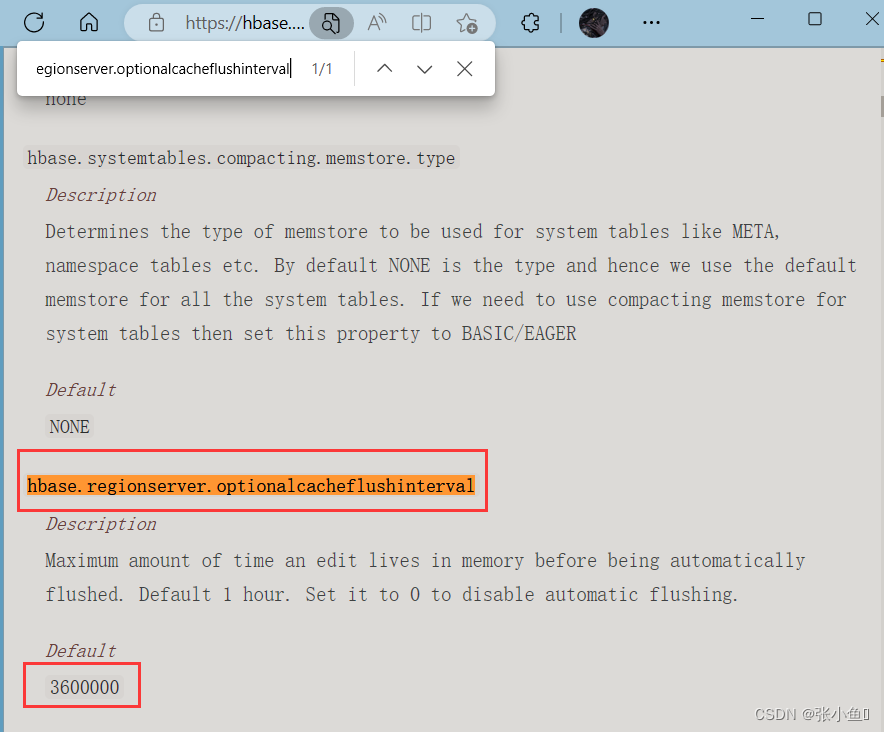
3. 到达自动刷写的时间,也会触发 memstore flush。自动刷新的时间间隔由该属性进行
配置 hbase.regionserver.optionalcacheflushinterval(默认 1 小时)。
尚硅谷大数据技术之 Hbase —————————————————————————————
4.当 WAL 文件的数量超过 hbase.regionserver.max.logs,region 会按照时间顺序依次进
行刷写,直到 WAL 文件数量减小到 hbase.regionserver.max.log 以下(该属性名已经废弃,
现无需手动设置,最大值为 32)。
ps:Ctrl+f调出本地的官方文档进行查看上述内容
3.2、StoreFile Compaction
由于 memstore 每次刷写都会生成一个新的 HFile,且同一个字段的不同版本(timestamp)
和不同类型(Put/Delete)有可能会分布在不同的 HFile 中,因此查询时需要遍历所有的 HFile。
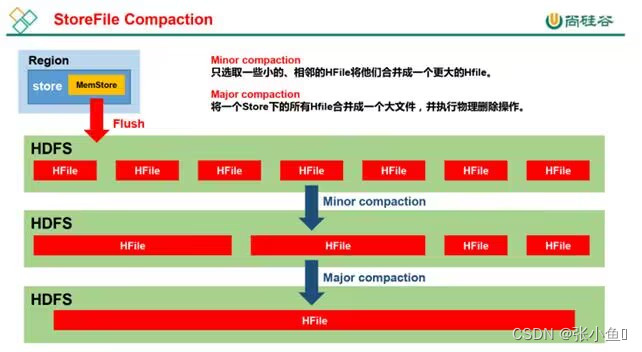
为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction
会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期
和删除的数据。
 Hile
Hile
3.3、 Region Split
默认情况下,每个 Table 起初只有一个 Region,随着数据的不断写入,Region 会自动进
行拆分。刚拆分时,两个子 Region 都位于当前的 Region Server,但处于负载均衡的考虑,
HMaster 有可能会将某个 Region 转移给其他的 Region Server。
Region Split 时机:
1.当1 个region 中的某个Store 下所有StoreFile 的总大小超过hbase.hregion.max.filesize,
该 Region 就会进行拆分(0.94 版本之前)。
2. 当 1 个 region 中 的 某 个 Store 下 所 有 StoreFile 的 总 大 小 超 过 Min(R^2 *
"hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其
中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
四、HBase的优化——高可用与预分区操作
4.1、高可用HA(High Availability)
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,
如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并
不会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
1.关闭 HBase 集群(如果没有开启则跳过此步)
[hadoop@hadoop102 hbase]$ bin/stop-hbase.sh
2.在 conf 目录下创建 backup-masters 文件
[hadoop@hadoop102 hbase]$ touch conf/backup-masters

3.在 backup-masters 文件中配置高可用 HMaster 节点
>指的追加
[hadoop@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters

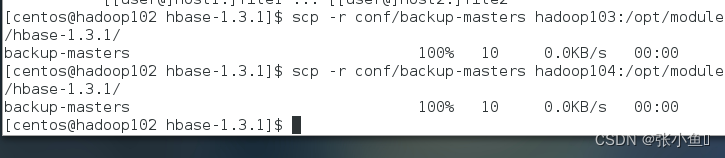
4.将整个 conf 目录 scp 到其他节点
[hadoop@hadoop102 hbase]$ scp -r conf/
hadoop103:/opt/module/hbase/
[hadoop@hadoop102 hbase]$ scp -r conf/
hadoop104:/opt/module/hbase/
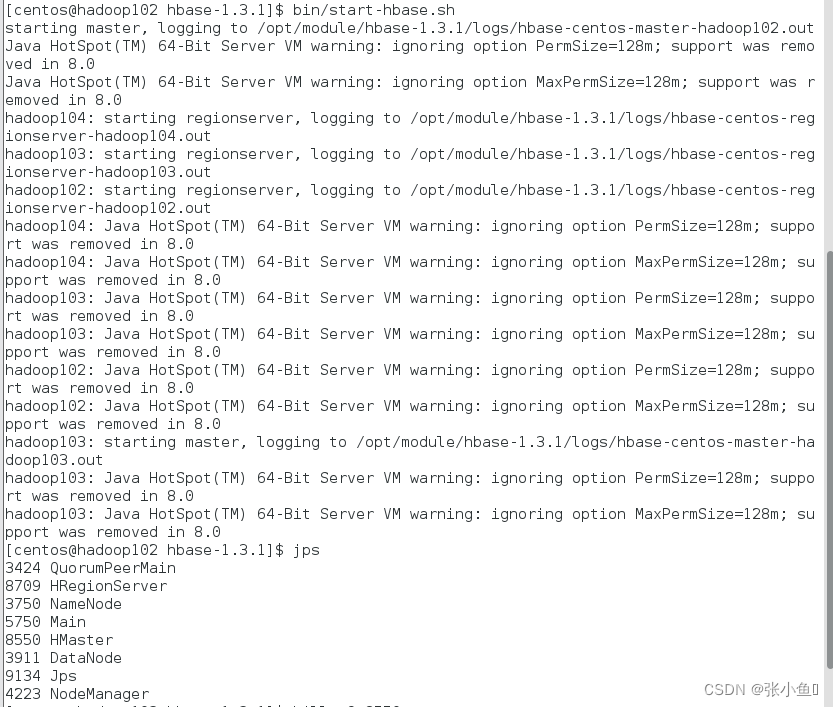
5.打开页面测试查看
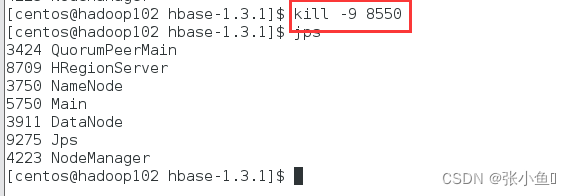
杀死Hadoop102的master进程
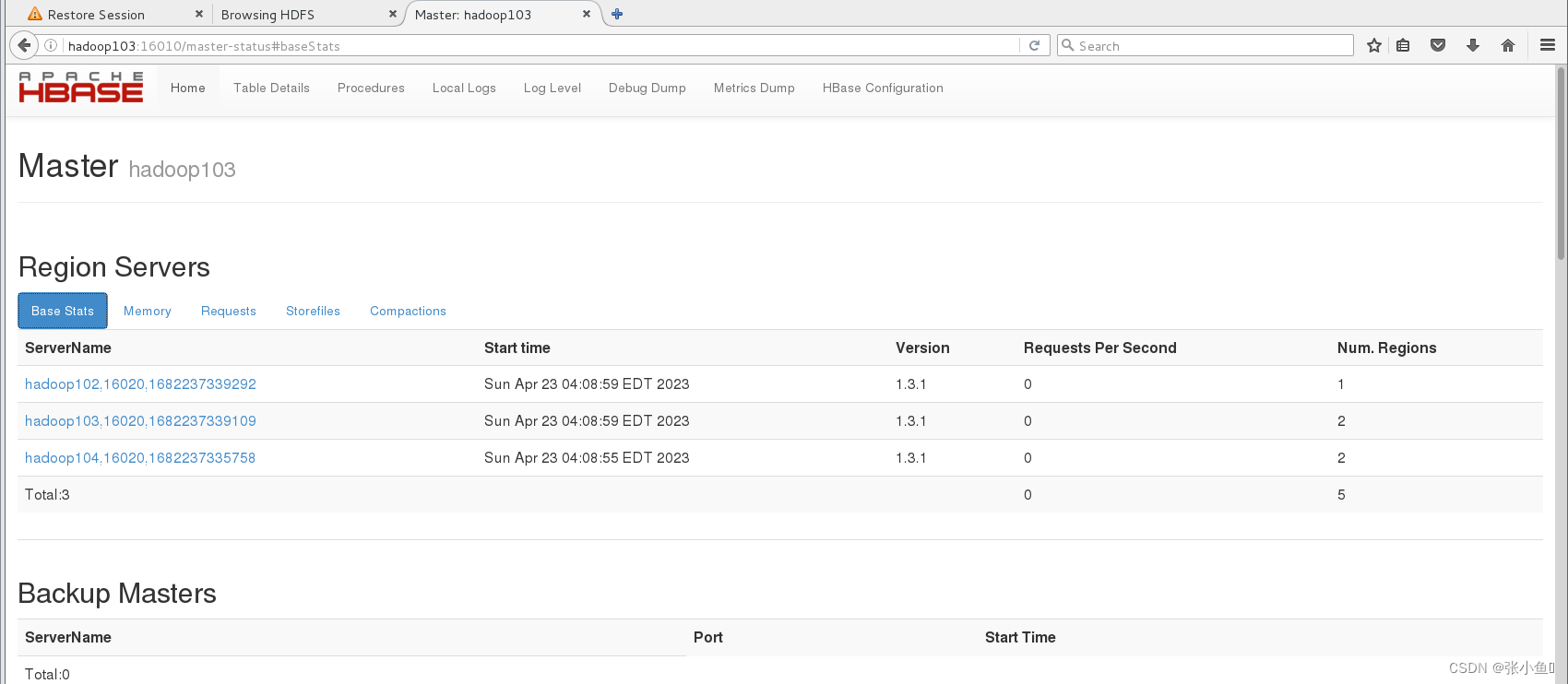
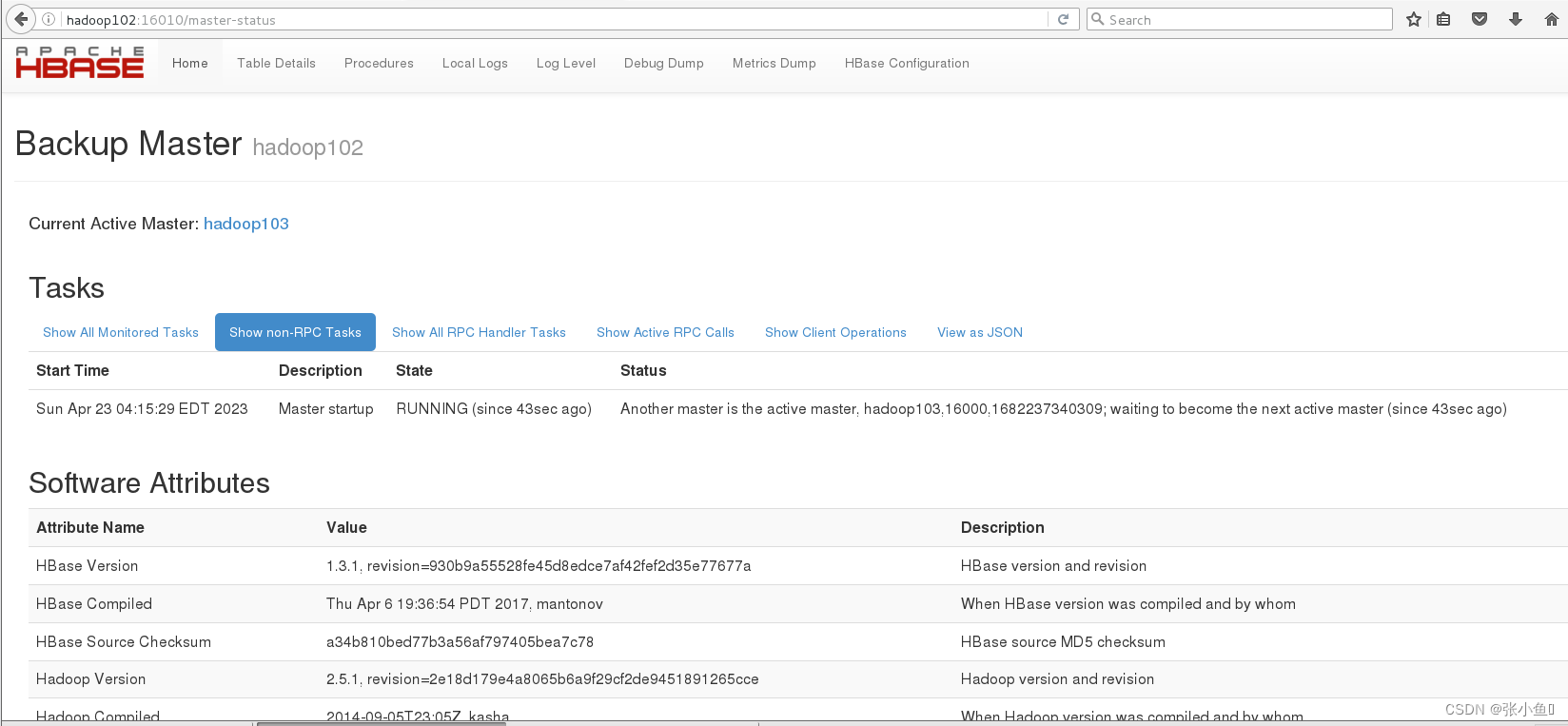
查看Hadoop103节点的master进程

此处可以看到Hadoop103作为master节点
再次启动Hadoop102的进程
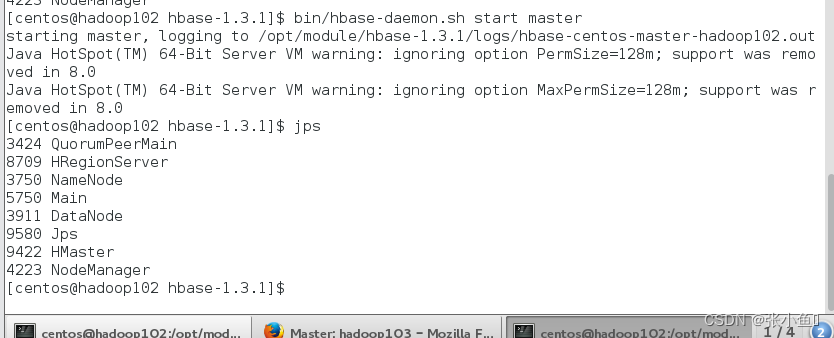
此时还是103节点为master节点
原因:此时的Hadoop102节点只能当作是Hadoop03的“小弟”,不能作为主节点【“大哥”】
4.2、预分区
每一个 region 维护着 StartRow 与 EndRow,如果加入的数据符合某个 Region 维护的
RowKey 范围,则该数据交给这个 Region 维护。那么依照这个原则,我们可以将数据所要
投放的分区提前大致的规划好,以提高 HBase 性能。
1.手动设定预分区
Hbase> create 'staff1','info','partition1',SPLITS =>
['1000','2000','3000','4000']

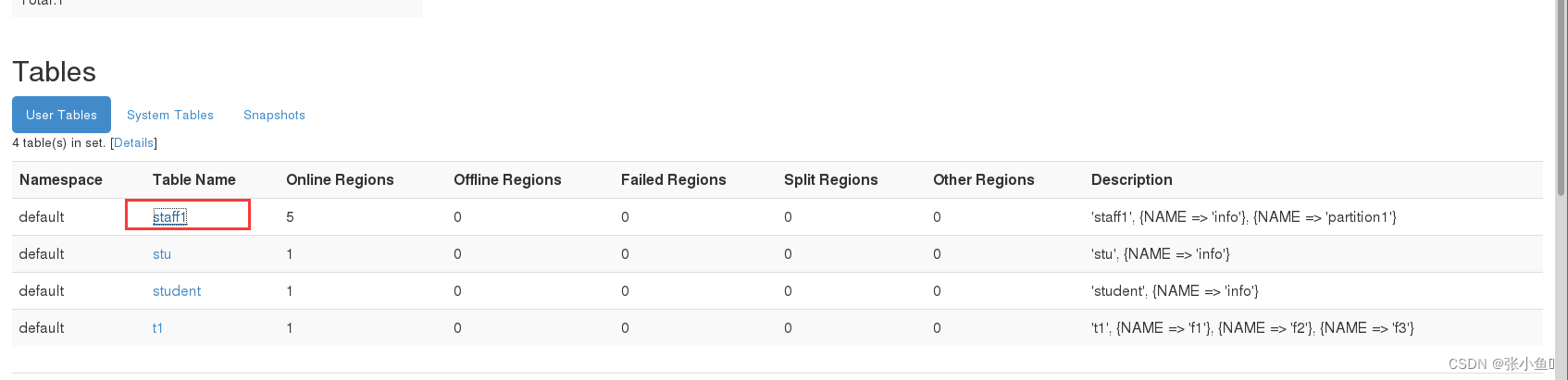

2.生成 16 进制序列预分区
create 'staff2','info','partition2',{NUMREGIONS => 15, SPLITALGO =>
'HexStringSplit'}
3.按照文件中设置的规则预分区
创建 splits.txt 文件内容如下:
aaaa
bbbb cccc dddd
然后执行:
create 'staff3','partition3',SPLITS_FILE => 'splits.txt'
4.使用 JavaAPI 创建预分区
//自定义算法,产生一系列 hash散列值存储在二维数组中
byte[][] splitKeys = 某个散列值函数
//创建 HbaseAdmin实例
HBaseAdmin hAdmin = new HBaseAdmin(HbaseConfiguration.create()); //创建 HTableDescriptor实例
HTableDescriptor tableDesc = new HTableDescriptor(tableName);
//通过 HTableDescriptor实例和散列值二维数组创建带有预分区的 Hbase表
hAdmin.createTable(tableDesc, splitKeys);
补充一些小知识
在集群启动之后使用kill -9 +端口号杀死进程,此时如果进入到shell里面会显示无法实现对数据的基本操作。
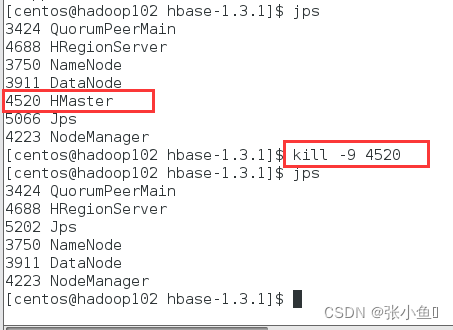
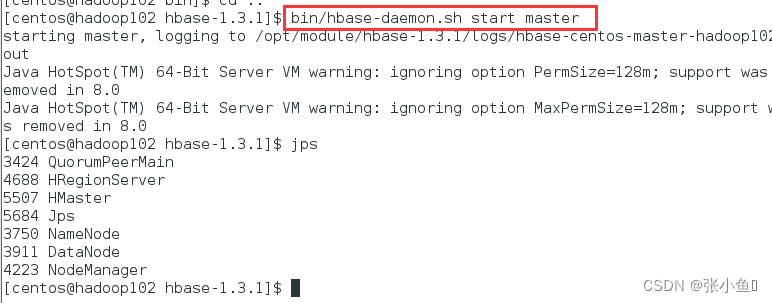
单点启动hbase的master节点
总结
以上就是对HBase的进阶内容的介绍,希望对初学者有所帮助。
最后欢迎大家点赞👍,收藏⭐,转发🚀,
如有问题、建议,请您在评论区留言💬哦。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结