您现在的位置是:首页 >学无止境 >【Python 协程详解】网站首页学无止境
【Python 协程详解】
0.前言
前面讲了线程和进程,其实python还有一个特殊的线程就是协程。
协程不是计算机提供的,计算机只提供:进程、线程。协程是人工创造的一种用户态切换的微进程,使用一个线程去来回切换多个进程。
为什么需要协程?
导致Python不能充分利用多线程来实现高并发,在某些情况下使用多线程可能比单线程效率更低。
由于进程和线程的切换都要消耗时间,保存线程进程当前状态以便下次继续执行。在不怎么需要cpu的程序中,即相对于IO密集型的程序,协程相对于线程进程资源消耗更小,切换更快,更适用于IO密集型。所以Python中出现了协程
协程也是单线程的,没法利用cpu的多核,想利用cpu多核可以通过,进程+协程的方式,又或者进程+线程+协程。
因为协程中获取状态或将状态传递给协程。进程和线程都是通过CPU的调度实现不同任务的有序执行,而协程是由用户程序自己控制调度的,也没有线程切换的开销,所以执行效率极高。
1.实现方式
1.1yield关键字实现协程
通过生成器实现
import time
def producer():
while True:
time.sleep(1)
print("生产了1个包子", time.strftime("%X"))
yield
def consumer():
while True:
next(prd)
print("消费了1个包子", time.strftime("%X"))
if __name__ == "__main__":
prd = producer()#第一次执行会返回一个生成器对象,而不会真正的执行该函数
consumer()
执行步骤解析:
1.prd = producer()#第一次执行会返回一个生成器对象,而不会真正的执行该函数
2.consumer(),调用并运行该函数,死循环,然后执行next(prd)执行第一步的生成器对象
3.执行producer,死循环,输出生产包子语句,遇到yield择执行挂起并返回到consumer中继续执行上次next()后的代码,然后次循环再次来到next()
4.程序又返回到上次yield挂起的地方继续执行,依次循环执行,达到并发效果。
所以在遇到需要cpu等待的操作主动让出cpu,记住函数执行的位置,下次切换回来继续执行才能算是并发的运行,提高程序的并发效果。
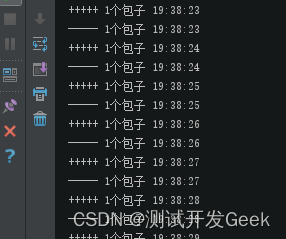
如果是仅仅用两哥循环来实现,这样并不能保留函数的执行的位置,只是简单的一个函数执行结束换到另一个函数而已
import time
def producer():
time.sleep(1)
print("生产了1个包子", time.strftime("%X"))
def consumer():
print("消费了1个包子", time.strftime("%X"))
if __name__ == "__main__":
while True:
producer()
consumer()
# 1.2greenlet模块
如果有上百个任务,要想实现在多个任务之间切换,使用yield生成器的方式就过于麻烦,而greenlet模块可以很轻易的实现
greenlet模块需要安装,pip install greenlet。greenlet原理是对生成器的封装。greenlet类提供了一个方法,switch:在需要进行切换的时候切换到指定的协程。
旨在提供可⾃⾏调度的"微线程",也就是协程。在greenlet模块中,通过target.switch()可以切换到指定的协程,可以更简单的进行切换任务。
import time
from greenlet import greenlet
def producer():
while True:
time.sleep(1)
print('生产了一个包子',time.strftime("%X"))
grep2.switch()
def consumer():
while True:
print('消费了一个包子',time.strftime("%X"))
grep1.switch()
if __name__ == '__main__':
grep1 = greenlet(producer)
grep2 = greenlet(consumer)
grep1.switch() # 先去执行producer
1.3gevent
虽然greenlet模块实现了协程并且可以方便的切换任务,但是仍需要人工切换,而不是自动进行任务的切换,当一个任务执行时如果遇到IO(⽐如⽹络、⽂件操作等),就会阻塞,没有解决遇到IO自动切换来提升效率的问题
gevent模块也需要安装,pip install gevent,gevent是对greenlet的再次封装,不用程序员自己编程切换。注意gevent遇到耗时操作才会切换协程运行,没有遇到耗时操作是不会主动切换的。
gevent.spawn(*args, **kwargs) 不定长参数中的第一个参数为协程执行的方法fn,其余的依次为 fn 的参数。开启了协程后要调用join方法。
gevent模块中识别耗时的操作有两种方式,① 使用gevent模块中重写的类。如,gevent.socket gevent.sleep ② 打补丁的方式,在所有的代码前。from gevent import monkey 导入这个模块,monkey.patch_all()调用这个方法。
推荐使用第二种方式,这样就不用更改已经写好的代码
正常情况下gevent并不会识别耗时操作
import gevent
import time
def work1():
for i in range(5):
print("work1开始执行...", gevent.getcurrent())
time.sleep(0.5)
def work2():
for i in range(5):
print("work2开始执行...", gevent.getcurrent())
time.sleep(0.5)
if __name__ == "__main__":
g1 = gevent.spawn(work1)
g2 = gevent.spawn(work2)
# 等待协程执⾏完成再关闭主线程
g1.join()
g2.join()
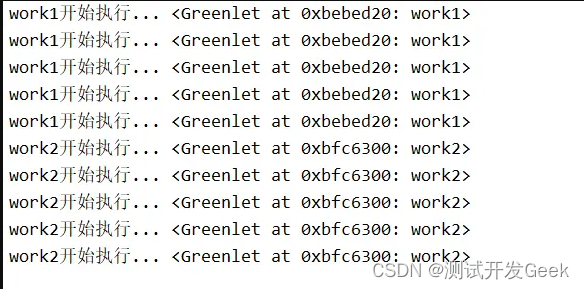
我们希望的是gevent模块帮我们⾃动切换协程,以达到work1和work2交替执⾏的⽬的,但并没有达到效果,原因是因为我们使用time.sleep(0.5)来模拟IO耗时操作,但是这样并没有被gevent正确识别为IO操作,所以要使⽤下⾯的gvent.sleep()来实现耗时
① 使用gevent模块中重写的类。如,gevent.socket gevent.sleep
import gevent
import time
def work1():
for i in range(5):
print("work1开始执行...", gevent.getcurrent())
gevent.sleep(0.5)
def work2():
for i in range(5):
print("work2开始执行...", gevent.getcurrent())
gevent.sleep(0.5)
if __name__ == "__main__":
g1 = gevent.spawn(work1)
g2 = gevent.spawn(work2)
# 等待协程执⾏完成再关闭主线程
g1.join()
g2.join()
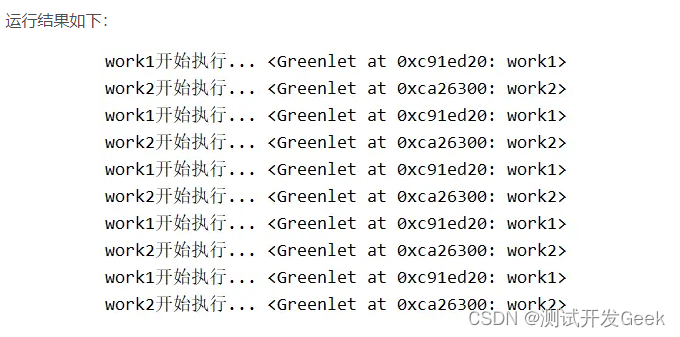
上面把time.sleep()改写成gevent.sleep()后,work1和work2能够交替执⾏
给程序打猴子补丁就可以不用改写源代码
② from gevent import monkey 导入这个模块,monkey.patch_all()调用这个方法。
猴⼦补丁主要有以下⼏个⽤处:
- 在运⾏时替换⽅法、属性等
- 在不修改第三⽅代码的情况下增加原来不⽀持的功能
- 在运⾏时为内存中的对象增加patch⽽不是在磁盘的源代码中增加
-
import gevent # 打补丁,让gevent识别⾃⼰提供或者⽹络请求的耗时操作 from gevent import monkey monkey.patch_all() import time def work1(): for i in range(5): print("work1开始执行...", gevent.getcurrent()) time.sleep(0.5) def work2(): for i in range(5): print("work2开始执行...", gevent.getcurrent()) time.sleep(0.5) if __name__ == "__main__": g1 = gevent.spawn(work1) g2 = gevent.spawn(work2) # 等待协程执⾏完成再关闭主线程 g1.join() g2.join()给程序打上猴子补丁后,使用time.sleep(),gevent也能识别到,可以自动切换任务
-
当开启的协程很多的时候,一个个的调用join方法就有点麻烦,所以gevent提供了一个方法joinall(),可以一次join所有的协程。joinall() 方法传参一个列表,列表包含了所有的协程。
-
import time import gevent from gevent import monkey monkey.patch_all() def producer(name): for i in range(3): time.sleep(1) print("+++++ 1个包子", name, time.strftime("%X")) def consumer(name): for i in range(3): time.sleep(1) print("----- 1个包子", name, time.strftime("%X")) if __name__ == "__main__": gevent.joinall([gevent.spawn(producer, "zhangsan"), gevent.spawn(consumer, "lisi")]) #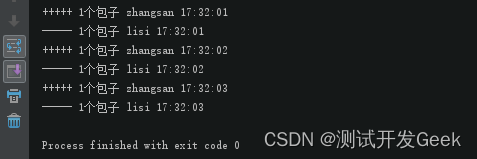
1.4asyncio异步协程
在python2以及python3.3之前,使用协程要基于greenlet或者gevent这种第三方库来实现,由于不是Python原生封装的,使用起来可能会有一些性能上的流失。但是在python3.4中,引入了标准库asyncio,直接内置了对异步IO的支持,可以很好的支持协程。可以使用asyncio库提供的@asyncio.coroutine把一个生成器函数标记为coroutine类型,然后在coroutine内部用yield from调用另一个coroutine实现异步操作。
而后为了简化并更好地标识异步IO,从Python3.5开始引入了新的语法async和await,把asyncio库的@asyncio.coroutine替换为async,把yield from替换为await,可以让coroutine的代码更简洁易读。
其中async关键字用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件消失后再回来继续执行。
await关键字用来实现任务挂起操作,比如某一异步任务执行到某一步时需要较长时间的耗时操作,就将此挂起,去执行其他的异步程序。注意:await后面只能跟异步程序或有__await__属性的对象。
假设有两个异步函数async work1和async work2,work1中的某一步有await,当程序碰到关键字await work2()后,异步程序挂起后去执行另一个异步work2函数,当挂起条件消失后,不管work2是否执行完毕,都要马上从work2函数中回到原work1函数中继续执行原来的操作。
await就是等待对象的值得到结果后再继续向下执行
import asyncio
import datetime
async def work1(i):
print("work1'{}'执行中......".format(i))
res = await work2(i)
print("work1'{}'执行完成......".format(i), datetime.datetime.now())
print("接收来自work2'{}'的:", res)
async def work2(i):
print("work2'{}'执行中......".format(i))
await asyncio.sleep(1.5)
print("work2'{}'执行完成......".format(i), datetime.datetime.now())
return "work2'{}'返回".format(i)
loop = asyncio.get_event_loop() # 创建事件循环
task = [asyncio.ensure_future(work1(i)) for i in range(5)] # 创建一个task列表
time1 = datetime.datetime.now()
# 将任务注册到事件循环中
loop.run_until_complete(asyncio.wait(task))
time2 = datetime.datetime.now()
print("总耗时:", time2 - time1)
loop.close()
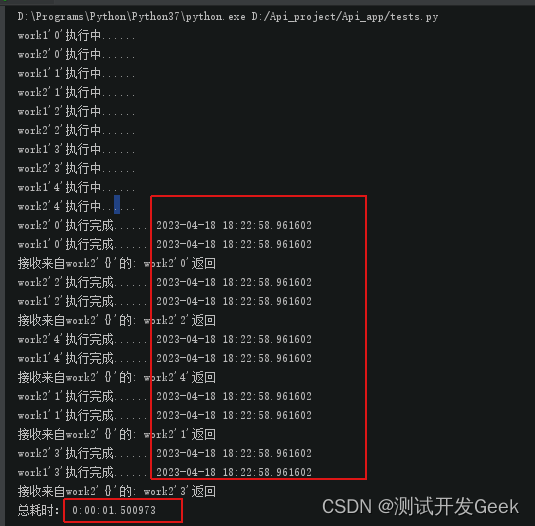
从結果可以看出,所有任务差不多是在同一时间执行结束的,所以总耗时为1.5s,证明程序是异步执行的






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结