您现在的位置是:首页 >技术交流 >【计算机网络】为什么 TCP 每次建立连接时,初始化序列号都要不一样呢?网站首页技术交流
【计算机网络】为什么 TCP 每次建立连接时,初始化序列号都要不一样呢?
【计算机网络】为什么 TCP 每次建立连接时,初始化序列号都要不一样呢?
为什么 TCP 每次建立连接时,初始化序列号都要不一样呢?
主要原因是为了防止历史报文被下一个相同四元组的连接接收。
TCP 四次挥手中的 TIME_WAIT 状态不是会持续 2 MSL 时长,历史报文不是早就在网络中消失了吗?
是的,如果能正常四次挥手,由于 TIME_WAIT 状态会持续 2 MSL 时长,历史报文会在下一个连接之前就会自然消失。
但是来了,我们并不能保证每次连接都能通过四次挥手来正常关闭连接。
假设每次建立连接,客户端和服务端的初始化序列号都是从 0 开始:
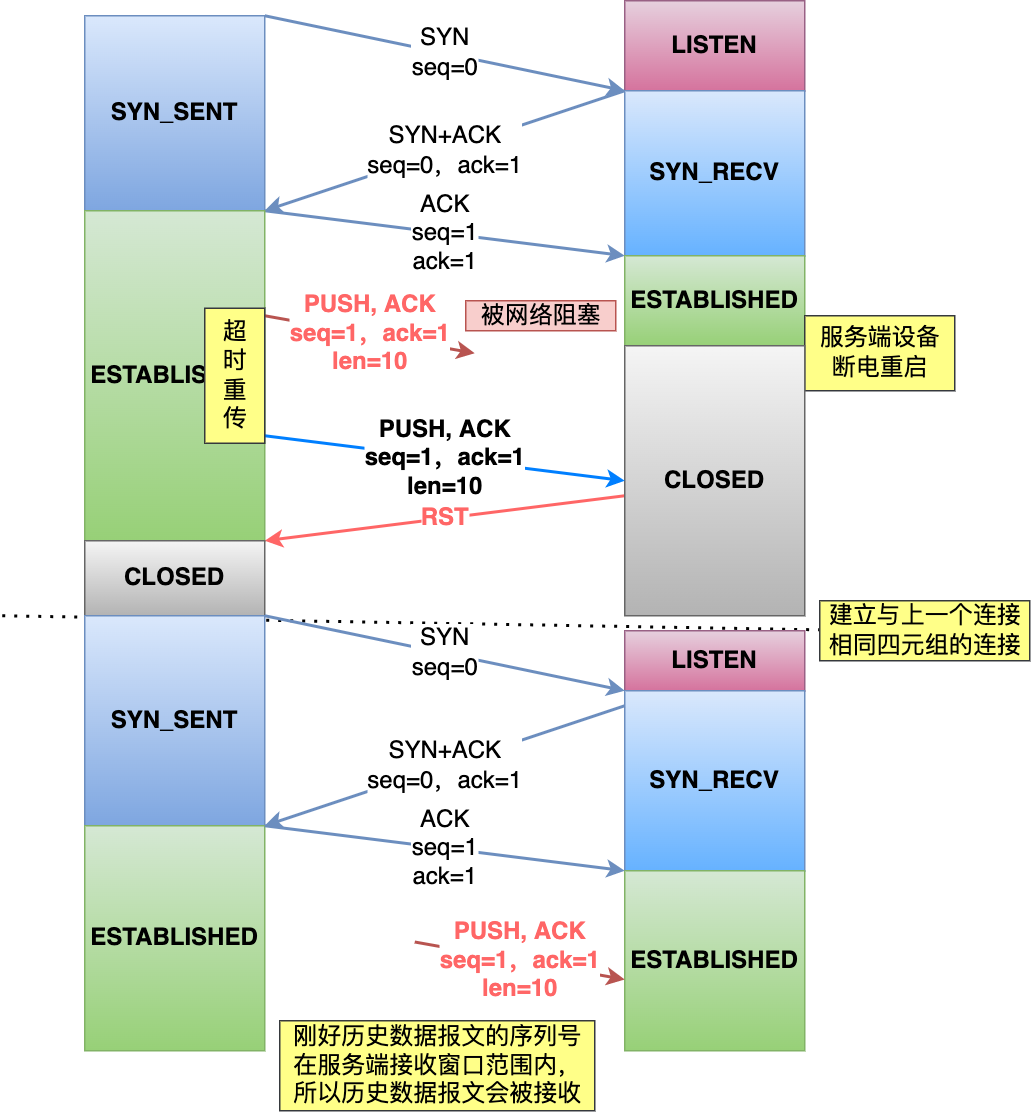
过程如下:
- 客户端和服务端建立一个 TCP 连接,在客户端发送数据包被网络阻塞了,然后超时重传了这个数据包,而此时服务端设备断电重启了,之前与客户端建立的连接就消失了,于是在收到客户端的数据包的时候就会发送 RST 报文。
- 紧接着,客户端又与服务端建立了与上一个连接相同四元组的连接;
- 在新连接建立完成后,上一个连接中被网络阻塞的数据包正好抵达了服务端,刚好该数据包的序列号正好是在服务端的接收窗口内,所以该数据包会被服务端正常接收,就会造成数据错乱。
可以看到,如果每次建立连接,客户端和服务端的初始化序列号都是一样的话,很容易出现历史报文被下一个相同四元组的连接接收的问题。
客户端和服务端的初始化序列号不一样不是也会发生这样的事情吗?
是的,即使客户端和服务端的初始化序列号不一样,也会存在收到历史报文的可能。
但是我们要清楚一点,历史报文能否被对方接收,还要看该历史报文的序列号是否正好在对方接收窗口内,如果不在就会丢弃,如果在才会接收。
如果每次建立连接客户端和服务端的初始化序列号都「不一样」,就有大概率因为历史报文的序列号「不在」对方接收窗口,从而很大程度上避免了历史报文,比如下图:
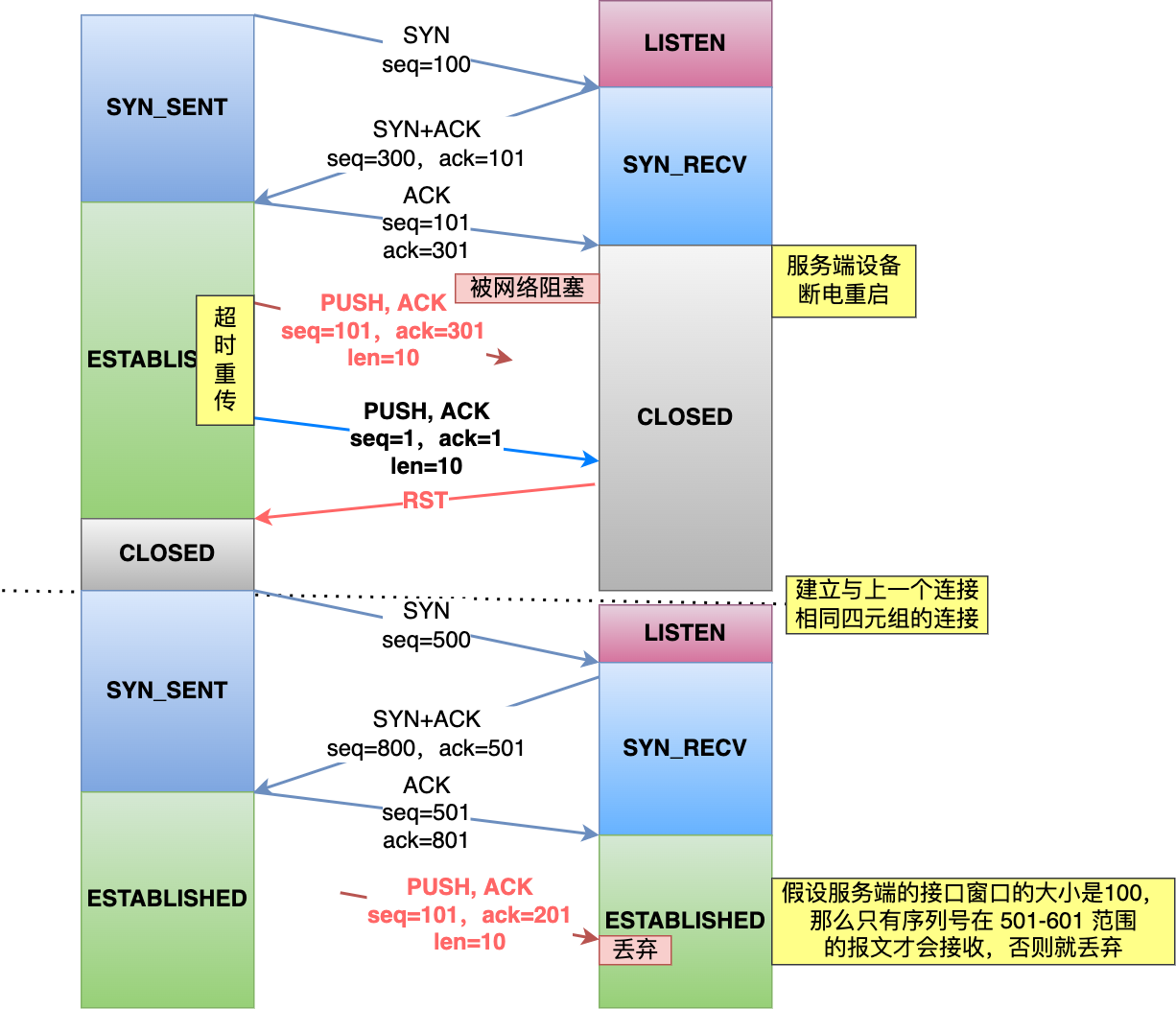
相反,如果每次建立连接客户端和服务端的初始化序列号都「一样」,就有大概率遇到历史报文的序列号刚「好在」对方的接收窗口内,从而导致历史报文被新连接成功接收。
所以,每次初始化序列号不一样能够很大程度上避免历史报文被下一个相同四元组的连接接收,注意是很大程度上,并不是完全避免了。
那客户端和服务端的初始化序列号都是随机的,那还是有可能随机成一样的呀?
RFC793 提到初始化序列号 ISN 随机生成算法:ISN = M + F(localhost, localport, remotehost, remoteport)。
- M是一个计时器,这个计时器每隔 4 微秒加1。
- F 是一个 Hash 算法,根据源IP、目的IP、源端口、目的端口生成一个随机数值,要保证 hash 算法不能被外部轻易推算得出。
可以看到,随机数是会基于时钟计时器递增的,基本不可能会随机成一样的初始化序列号。
懂了,客户端和服务端初始化序列号都是随机生成的话,就能避免连接接收历史报文了。
是的,但是也不是完全避免了。
为了能更好的理解这个原因,我们先来了解序列号(SEQ)和初始序列号(ISN)。
- 序列号,是 TCP 一个头部字段,标识了 TCP 发送端到 TCP 接收端的数据流的一个字节,因为 TCP 是面向字节流的可靠协议,为了保证消息的顺序性和可靠性,TCP 为每个传输方向上的每个字节都赋予了一个编号,以便于传输成功后确认、丢失后重传以及在接收端保证不会乱序。序列号是一个 32 位的无符号数,因此在到达 4G 之后再循环回到 0。
- 初始序列号,在 TCP 建立连接的时候,客户端和服务端都会各自生成一个初始序列号,它是基于时钟生成的一个随机数,来保证每个连接都拥有不同的初始序列号。初始化序列号可被视为一个 32 位的计数器,该计数器的数值每 4 微秒加 1,循环一次需要 4.55 小时。
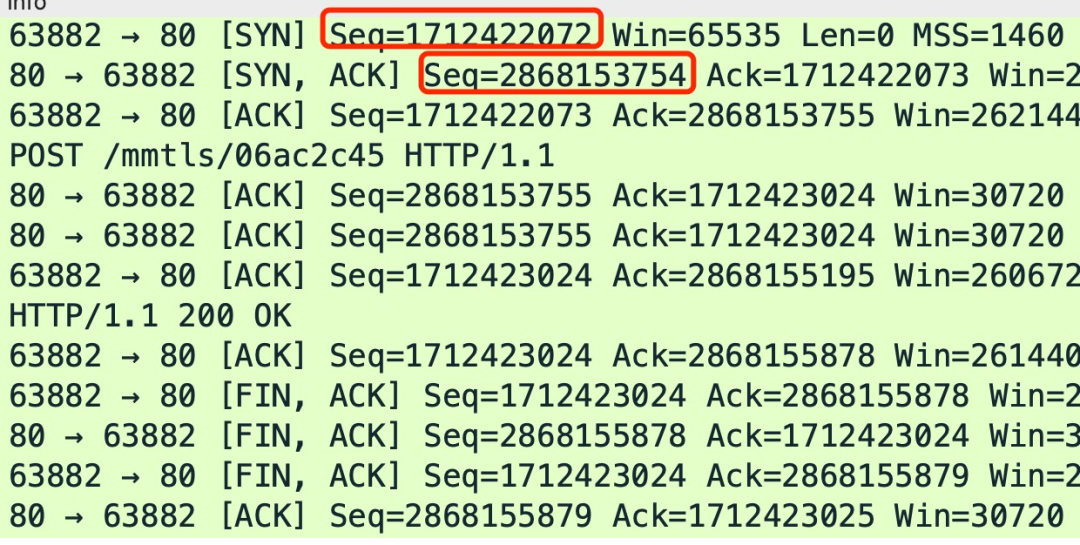
给大家抓了一个包,下图中的 Seq 就是序列号,其中红色框住的分别是客户端和服务端各自生成的初始序列号。
通过前面我们知道,序列号和初始化序列号并不是无限递增的,会发生回绕为初始值的情况,这意味着无法根据序列号来判断新老数据。
不要以为序列号的上限值是 4GB,就以为很大,很难发生回绕。在一个速度足够快的网络中传输大量数据时,序列号的回绕时间就会变短。如果序列号回绕的时间极短,我们就会再次面临之前延迟的报文抵达后序列号依然有效的问题。
为了解决这个问题,就需要有 TCP 时间戳。tcp_timestamps 参数是默认开启的,开启了 tcp_timestamps 参数,TCP 头部就会使用时间戳选项,它有两个好处,一个是便于精确计算 RTT ,另一个是能防止序列号回绕(PAWS)。
试看下面的示例,假设 TCP 的发送窗口是 1 GB,并且使用了时间戳选项,发送方会为每个 TCP 报文分配时间戳数值,我们假设每个报文时间加 1,然后使用这个连接传输一个 6GB 大小的数据流。

32 位的序列号在时刻 D 和 E 之间回绕。假设在时刻B有一个报文丢失并被重传,又假设这个报文段在网络上绕了远路并在时刻 F 重新出现。如果 TCP 无法识别这个绕回的报文,那么数据完整性就会遭到破坏。
使用时间戳选项能够有效的防止上述问题,如果丢失的报文会在时刻 F 重新出现,由于它的时间戳为 2,小于最近的有效时间戳(5 或 6),因此防回绕序列号算法(PAWS)会将其丢弃。
防回绕序列号算法要求连接双方维护最近一次收到的数据包的时间戳(Recent TSval),每收到一个新数据包都会读取数据包中的时间戳值跟 Recent TSval 值做比较,如果发现收到的数据包中时间戳不是递增的,则表示该数据包是过期的,就会直接丢弃这个数据包。
懂了,客户端和服务端的初始化序列号都是随机生成,能很大程度上避免历史报文被下一个相同四元组的连接接收,然后又引入时间戳的机制,从而完全避免了历史报文被接收的问题。
嗯嗯,没错。
如果时间戳也回绕了怎么办?
时间戳的大小是 32 bit,所以理论上也是有回绕的可能性的。
时间戳回绕的速度只与对端主机时钟频率有关。
Linux 以本地时钟计数(jiffies)作为时间戳的值,不同的增长时间会有不同的问题:
- 如果时钟计数加 1 需要1ms,则需要约 24.8 天才能回绕一半,只要报文的生存时间小于这个值的话判断新旧数据就不会出错。
- 如果时钟计数提高到 1us 加1,则回绕需要约71.58分钟才能回绕,这时问题也不大,因为网络中旧报文几乎不可能生存超过70分钟,只是如果70分钟没有报文收发则会有一个包越过PAWS(这种情况会比较多见,相比之下 24 天没有数据传输的TCP连接少之又少),但除非这个包碰巧是序列号回绕的旧数据包而被放入接收队列(太巧了吧),否则也不会有问题;
- 如果时钟计数提高到 0.1 us 加 1 回绕需要 7 分钟多一点,这时就可能会有问题了,连接如果 7 分钟没有数据收发就会有一个报文越过 PAWS,对于TCP连接而言这么短的时间内没有数据交互太常见了吧!这样的话会频繁有包越过 PAWS 检查,从而使得旧包混入数据中的概率大大增加;
Linux 在 PAWS 检查做了一个特殊处理,如果一个 TCP 连接连续 24 天不收发数据则在接收第一个包时基于时间戳的 PAWS 会失效,也就是可以 PAWS 函数会放过这个特殊的情况,认为是合法的,可以接收该数据包。
// tcp_paws_check 函数如果返回 true 则 PAWS 通过:
static inline bool tcp_paws_check(const struct tcp_options_received *rx_opt, int paws_win)
{
......
//从上次收到包到现在经历的时间多于24天,返回true
if (unlikely(get_seconds() >= rx_opt->ts_recent_stamp + TCP_PAWS_24DAYS))
return true;
.....
return false;
}
要解决时间戳回绕的问题,可以考虑以下解决方案:
1)增加时间戳的大小,由32 bit扩大到64bit
这样虽然可以在能够预见的未来解决时间戳回绕的问题,但会导致新旧协议兼容性问题,像现在的IPv4与IPv6一样
2)将一个与时钟频率无关的值作为时间戳,时钟频率可以增加但时间戳的增速不变
随着时钟频率的提高,TCP在相同时间内能够收发的包也会越来越多。如果时间戳的增速不变,则会有越来越多的报文使用相同的时间戳。这种趋势到达一定程度则时间戳就会失去意义,除非在可预见的未来这种情况不会发生。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结