您现在的位置是:首页 >其他 >leetcode重点题目分类别记录(四)图论深入网站首页其他
leetcode重点题目分类别记录(四)图论深入
文章目录
入度出度
最大网络秩
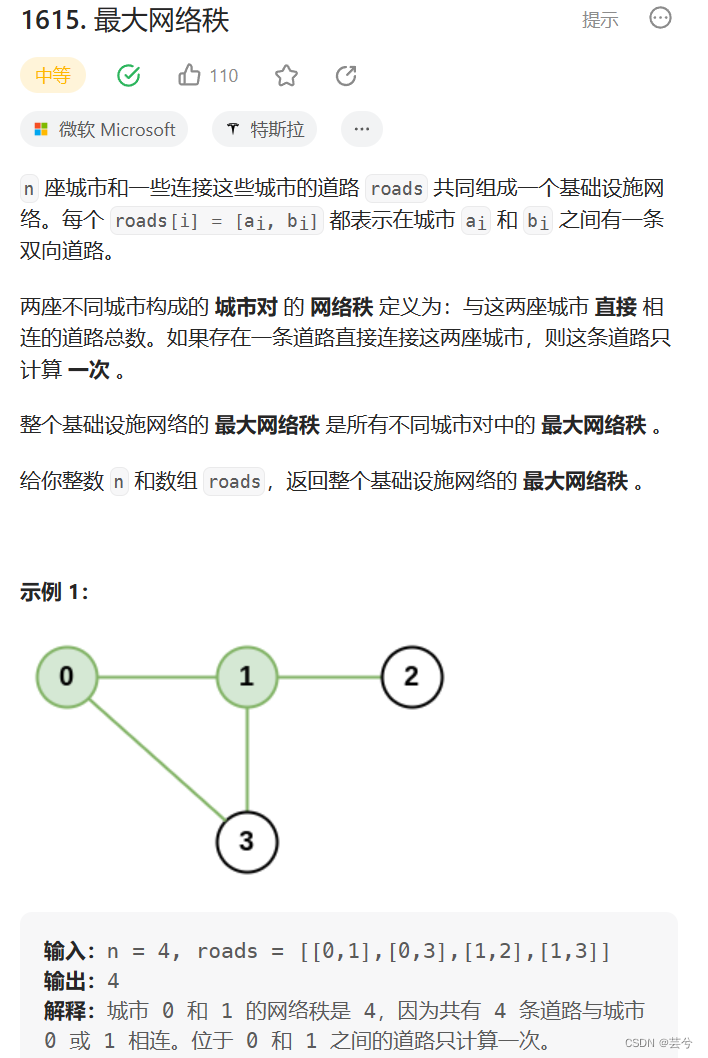
直接相连的道路即为节点的度,如果两个节点是相连的,那么度将会重复计算,因此,统计每个节点的度,和节点相连的情况,每个每一对城市,计算最大网络秩。
int maximalNetworkRank(int n, vector<vector<int>>& roads) {
vector<vector<bool>> connect(n, vector<bool>(n, false));
vector<int> degree(n, 0);
for (vector<int> &r : roads) {
connect[r[0]][r[1]] = true;
connect[r[1]][r[0]] = true;
++degree[r[0]];
++degree[r[1]];
}
int ans = 0, cur = 0;
for (int i = 0; i < n; ++i) {
for (int j = i + 1; j < n; ++j) {
cur = degree[i] + degree[j] + (connect[i][j] ? -1 : 0);
ans = max(ans, cur);
}
}
return ans;
}
可以到达所有点的最少点数目
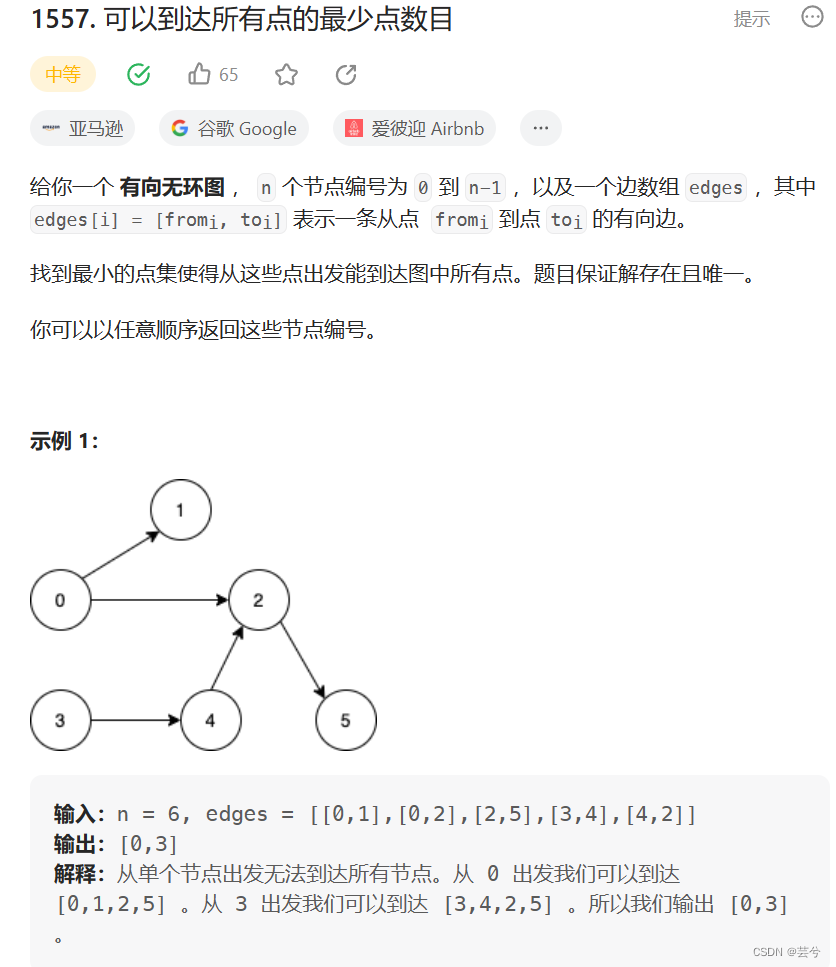
理解题意发现,每个入度为0的节点必须作为出发点。
因此统计入度为0的节点个数即可。
vector<int> findSmallestSetOfVertices(int n, vector<vector<int>>& edges) {
// 统计入度为0的节点数
vector<int> ins(n);
for (auto e : edges) ++ins[e[1]];
vector<int> ans;
for (int i = 0; i < n; ++i) {
if (ins[i] == 0) ans.push_back(i);
}
return ans;
}
并查集
并查集用于求解连通分量,两个关键词,连通和分量,分量就是一个集合,连通,代表集合之间可以合并。
省份数量
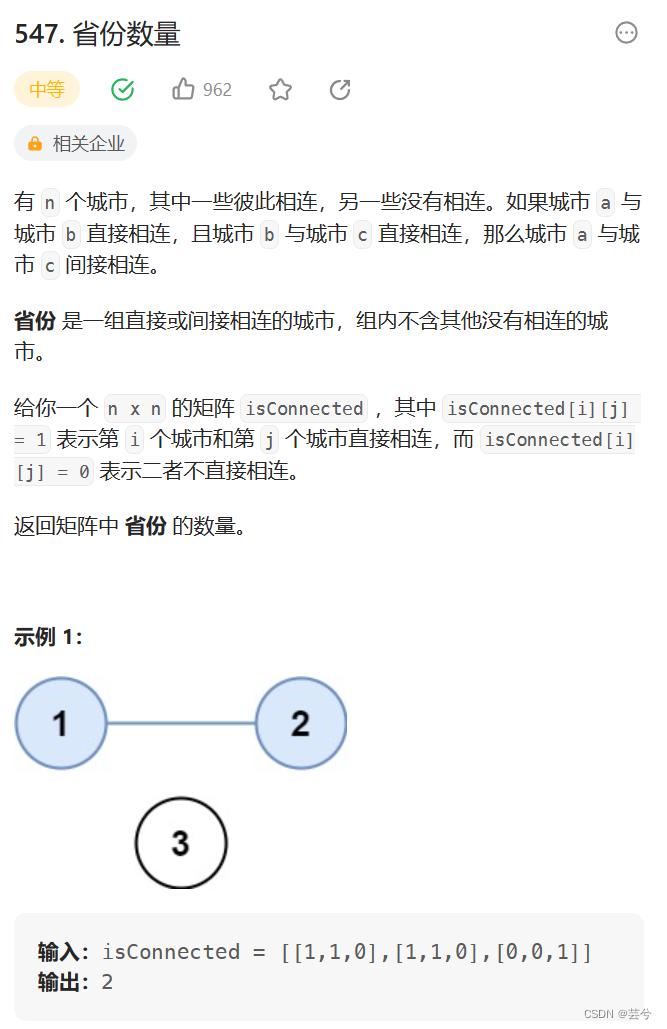
省份地图是连通量问题标准题目:
class Solution {
public:
class UF {
private:
// 一个数组,用来指定每个成员的根节点是谁
int *parent;
// 当前的连通量数/集合数
int cnt;
public:
UF(int val) {
// 传递成员数 初始时每个成员的根节点指向为自身
parent = new int[val];
for (int i = 0; i < val; ++i) parent[i] = i;
cnt = val;
}
int find(int val) {
if (val != parent[val]) {
// 路径压缩:递归的将当前成员的父节点指向为根成员
parent[val] = find(parent[val]);
}
return parent[val];
}
// 判断是否连通,只需判断是否同父节点
bool connected (int p, int q) {
return find(p) == find(q);
}
// 连通两个分量,判断是否是非连接的,将一个成员的根挂在另一个成员父节点的根上,注意将连通分量数减一
void unite(int p, int q) {
if (!connected(p, q)) {
parent[find(p)] = find(q);
--cnt;
}
}
int count() {
return cnt;
}
};
int findCircleNum(vector<vector<int>>& isConnected) {
int n = isConnected.size();
UF uf(n);
for (int i = 1; i < n; ++i) {
for (int j = 0; j < i; ++j) {
if (isConnected[i][j] == 1) {
uf.unite(i, j);
}
}
}
return uf.count();
}
};
等式方程的可满足性
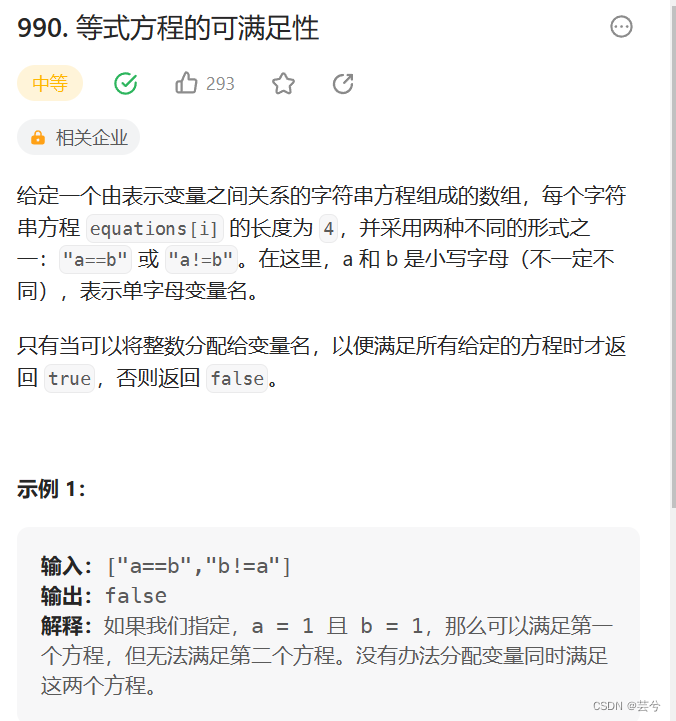
多个变量之间等或者不等的关系,就类似连通分量问题中,多个成员属于同一个连通量或者不属于。因此也可以使用并查集来做,这里仅仅关心等式是否有违背,那么我们根据所有的等式建立连通关系,建立后,查看每个不等式是否有违背,即不等式中是否有属于同一分量的。
class Solution {
public:
class UF {
private:
int* parent;
public:
UF() {
parent = new int[26];
for (int i = 0; i < 26; ++i) parent[i] = i;
}
int find (int val) {
if (parent[val] != val) {
parent[val] = find(parent[parent[val]]);
}
return parent[val];
}
bool connected(int p, int q) {
return find(p) == find(q);
}
void unite(int p, int q) {
if (!connected(p, q)) {
parent[find(p)] = find(q);
}
}
};
bool equationsPossible(vector<string>& equations) {
UF uf;
for (const string& e : equations) {
int a = e[0] - 'a', b = e[3] - 'a';
if (e[1] == '=') uf.unite(a, b);
}
for (const string& e : equations) {
int a = e[0] - 'a', b = e[3] - 'a';
if (e[1] == '!') {
if (uf.connected(a, b)) return false;
}
}
return true;
}
};
按字典序排列最小的等效字符串

前边的例子中,我们先连通两个分量时的做法为:
默认是把p的根接在了q的根上边
void unite(int p, int q) {
if (!connected(p, q)) {
parent[find(p)] = find(q);
}
}
这题要求按照字典序排列最小,那么我们当然希望的时每个字符是最小的,因此可以在连通时,选择小的那个作为根:
void unite(int p, int q) {
if (!connected(p, q)) {
int rootp = find(p), rootq = find(q);
if (rootp < rootq) {
parent[rootq] = rootp;
} else {
parent[rootp] = rootq;
}
}
}
这样就保证了,每个等价关系中,根节点是最小的那个字符。
那么我们只需要根据并查集建立等号连通关系,将字符替换为并查集中的根即可。
string smallestEquivalentString(string s1, string s2, string baseStr) {
UF uf;
for (int i = 0; i < s1.size(); ++i) uf.unite(s1[i] - 'a', s2[i] - 'a');
for (int i = 0; i < baseStr.size(); ++i) {
int cur = baseStr[i] - 'a';
int p = uf.find(cur);
baseStr[i] = 'a' + p;
}
return baseStr;
}
以图判树
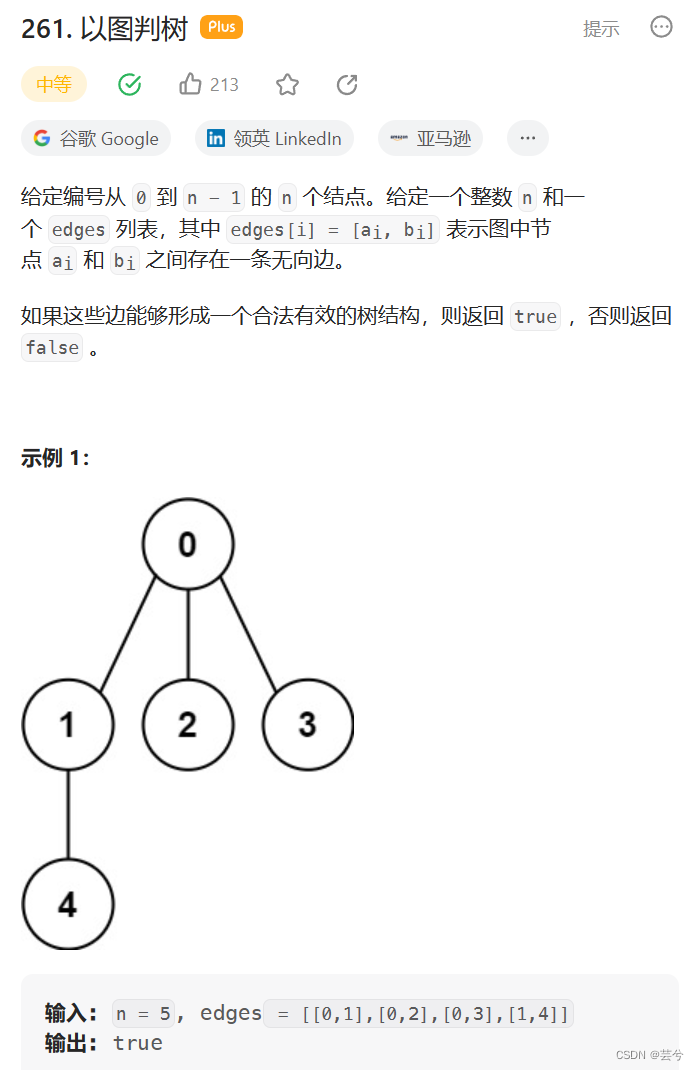
一个合法的树,所有节点都相连,且无环,节点数等于边数 + 1;
根据这个思路,先判断边与节点数关系。
如果节点数等于边数+1,那么只需要判断图是否只有一个部分即可。
使用visited记录遍历情况.
bool validTree(int n, vector<vector<int>>& edges) {
if (n - 1 != edges.size()) return false; // 判断节点数与边数是否符合
// 构图
vector<vector<int>> graph(n);
for (auto& e : edges) {
graph[e[0]].push_back(e[1]);
graph[e[1]].push_back(e[0]);
}
// dfs遍历,注意跳过遍历过的节点
vector<bool> visited(n, false);
function<void(int)> dfs = [&](int cur) {
visited[cur] = true;
for (auto e : graph[cur]) {
if (visited[e]) continue;
dfs(e);
}
};
// 从任意节点遍历
dfs(0);
// 检测是否能够遍历每一个节点
for (int i = 0; i < n; ++i) if (!visited[i]) return false;
return true;
}
考虑另外一种思路:并查集。
如果满足边数等于节点数减一,且整个图只有一个连通量,那么其实就类似上边达到了判断图只有一个完整的部分。
class UF {
private:
int* parent;
int cnt;
public:
UF(int val) {
parent = new int[val];
for (int i = 0; i < val; ++i) parent[i] = i;
cnt = val;
}
int find(int val) {
if (parent[val] != val) {
parent[val] = find(parent[val]);
}
return parent[val];
}
bool connected(int p, int q) {
return find(p) == find(q);
}
void unite(int p, int q) {
if (!connected(p, q)) {
parent[find(p)] = find(q);
--cnt;
}
}
int count(){
return cnt;
}
};
bool validTree(int n, vector<vector<int>>& edges) {
if (n - 1 != edges.size()) return false;
UF uf(n);
for (auto e : edges) {
uf.unite(e[0], e[1]);
}
return uf.count() == 1;
}
二分图
判断二分图


二分染色法:
一个visited数组记录遍历情况,一个color数组记录染色情况,遍历每个节点,如果相邻节点未被染色,则将它染成与当前节点相反颜色,否则如果已经染色,检查相邻节点是否同色,如果同色说明不可二分。
bool isBipartite(vector<vector<int>>& graph) {
int n = graph.size();
vector<int> visited(n, false), color(n, false);
bool ans = true;
function<void(int)> dfs = [&](int cur) {
if (!ans || visited[cur]) return;
visited[cur] = true;
for (int c : graph[cur]) {
if (!visited[c]) {
// 没遍历过的节点是未染色的,染成与cur相反的颜色
color[c] = !color[cur];
dfs(c);
} else {
// 遍历过的节点是染色的,检查是否符合
// 如果不符合,将全局的ans设置为false,返回
if (color[cur] == color[c]) {
ans = false;
return;
}
}
}
};
// 可能存在多个子图,需要遍历每个节点
for (int i = 0; i < n; ++i) {
dfs(i);
if (!ans) return false;
}
return ans;
}
深度优先搜索
封闭岛屿数量

int closedIsland(vector<vector<int>>& grid) {
// 把与相连边的0(陆地)全部赋值为1
// 统计0的区域数
int m = grid.size(), n = grid[0].size();
int dx[4] = {0, 0, -1, 1}, dy[4] = {1, -1, 0, 0};
function<void(int, int)> dfs = [&](int x, int y) {
grid[x][y] = 1;
for (int i = 0; i < 4; ++i) {
int cx = x + dx[i], cy = y + dy[i];
if (cx >= 0 && cx < m && cy >= 0 && cy < n && grid[cx][cy] == 0) dfs(cx, cy);
}
};
for (int i = 0; i < m; ++i) {
if (grid[i][0] == 0) dfs(i, 0);
if (grid[i][n - 1] == 0) dfs(i, n - 1);
}
for (int j = 0; j < n; ++j) {
if (grid[0][j] == 0) dfs(0, j);
if (grid[m - 1][j] == 0) dfs(m - 1, j);
}
int ans = 0;
for (int i = 1; i < m - 1; ++i) {
for (int j = 1; j < n - 1; ++j) {
if (grid[i][j] == 0) {
++ans;
dfs(i, j);
}
}
}
return ans;
}
太平洋大西洋水流问题
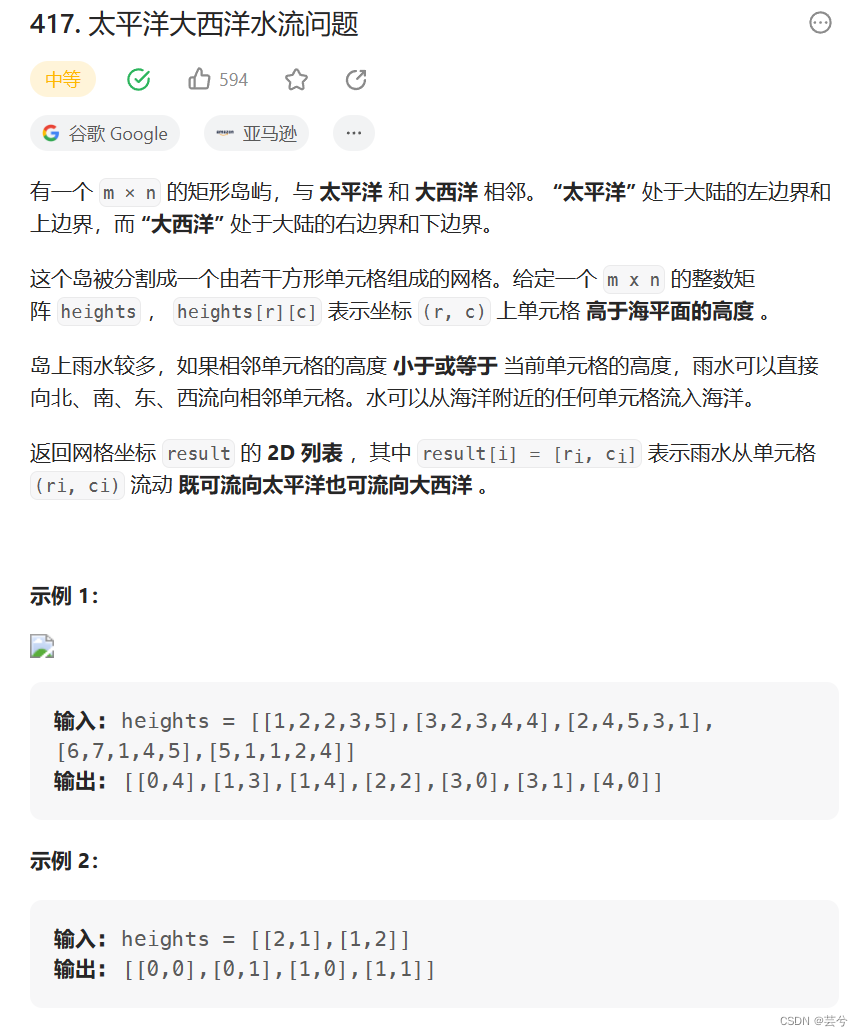
寻找可以到达太平洋,也可到达大西洋的坐标。
我们可以反向考虑水流,从边界出发,向周围更高的地方搜索能够到达海岸的位置。
pacific和atlantic数组分别表示i,j位置是否可以达到太平洋和大西洋。
在边界上执行dfs后,搜索pacific和atlantic都为true的位置。
vector<vector<int>> pacificAtlantic(vector<vector<int>>& heights) {
int m = heights.size(), n = heights[0].size();
vector<vector<int>> ans;
vector<vector<bool>> pacific(m, vector<bool>(n, false));
vector<vector<bool>> atlantic(m, vector<bool>(n, false));
int dx[4] = {1, -1, 0, 0}, dy[4] = {0, 0, 1, -1};
function<void(int, int, vector<vector<bool>>&)> dfs = [&](int x, int y, vector<vector<bool>> &ocean) {
if (ocean[x][y]) return;
ocean[x][y] = true;
for (int k = 0; k < 4; ++k) {
int cx = x + dx[k], cy = y + dy[k];
if (cx >= 0 && cx < m && cy >= 0 && cy < n && heights[cx][cy] >= heights[x][y]) dfs(cx, cy, ocean);
}
};
for (int i = 0; i < m; ++i) dfs(i, 0, pacific);
for (int i = 0; i < m; ++i) dfs(i, n - 1, atlantic);
for (int j = 0; j < n; ++j) dfs(0, j, pacific);
for (int j = 0; j < n; ++j) dfs(m - 1, j, atlantic);
for (int i = 0; i < m; ++i) {
for (int j = 0; j < n; ++j) {
if (pacific[i][j] && atlantic[i][j]) ans.push_back({i, j});
}
}
return ans;
}
广度优先搜索
树上逃逸最短路径


这题树是以图的形式给出的,而且没有指定方向所以是无向图
为了保证遍历时是一直向前了,我们遍历时带上了父节点,避免了走回头路。
使用bfs找叶子节点,叶子节点是除了根节点外,另外一种只有一个相邻节点的节点
最短路径在我们遍历过的路径中,根据叶子节点和父节点,逆向找到起始点。
随后构建出题目要求的路径。
void question2() {
// 树上找最短路径:bfs
int n;
cin >> n;
int edge;
cin >> edge;
// 构图
vector<vector<int>> g(n);
for (int i = 0; i < edge; ++i) {
int x, y;
cin >> x >> y;
g[x].push_back(y);
g[y].push_back(x);
}
// 标记阻塞点
int bolck;
cin >> bolck;
vector<bool> isblock(n, false);
for (int i = 0; i < bolck; ++i) {
int index;
cin >> index;
isblock[index] = true;
}
// 找到叶子节点说明有路,为了标记路径,需要记录每个节点的父节点,pair: 当前节点,当前节点的父节点
vector<pair<int, int>> path;
queue<pair<int, int>> que;
que.push({0, -1}); // 初始节点的父节点设置为-1
isblock[0] = true;
int endIndex = -1;
// bfs搜索
while (!que.empty()) {
path.push_back(que.front());
int cur = que.front().first, fa = que.front().second;
que.pop();
// 除根节点外,又遍历到只有一个相邻节点的节点, 说明是叶子节点,记录位置,退出
if (cur != 0 && g[cur].size() == 1) {
endIndex = cur;
break;
}
for (int e : g[cur]) {
if (isblock[e]) continue;
que.push({e, cur});
isblock[e] = true;
}
}
// path中记录了所有宽度优先遍历的结果,需从中找到路径,根据末尾节点位置和每个节点的父节点往上找
string ans;
vector<int> res;
if (endIndex != -1) {
int t = endIndex;
for (int i = path.size() - 1; i >= 0; --i) {
if (path[i].first == t) {
res.push_back(t);
t = path[i].second;
if (t == -1) break;
}
}
}
// 根据路径打印结果
for (int i = res.size() - 1; i >= 0; --i) {
ans += to_string(res[i]);
if (i != 0) ans += "->";
}
cout << ans << endl;
}
多源最短路径

要求A到C的距离最短的路径之和。
由于不确定A离那个C最近,我们可以从C反向BFS搜索A。每遍历一轮,将ans加上当前的轮次(即当前走的step),然后把A所在的地方再加入到队列。
void ques() {
int n;
cin >> n;
vector<vector<char>> maze(n, vector<char>(n));
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
cin >> maze[i][j];
}
}
int ans = 0;
int dx[4] = {0, 0, 1, -1}, dy[4] = {1, -1, 0, 0};
queue<pair<int, int>> que;
for (int i = 0; i < n; ++i) {
for (int j = 0; j < n; ++j) {
if(maze[i][j] == 'C') {
que.emplace(i, j);
maze[i][j] = 'B';
}
}
}
int epoch = 1;
while (!que.empty())
{
int sz = que.size();
for (int i = 0; i < sz; ++i) {
int x = que.front().first, y = que.front().second;
que.pop();
for (int j = 0; j < 4; ++j) {
int cx = x + dx[j], cy = y + dy[j];
if (cx >= 0 && cx < n && cy >= 0 && cy < n && maze[cx][cy] == 'A') {
ans += epoch;
maze[cx][cy] = 'B';
que.emplace(cx, cy);
}
}
}
++epoch;
}
cout << ans << endl;
}
拓扑排序
DFS解决拓扑排序
dfs求解时,我们根据依赖关系构图,然后获取后序遍历结果,反向后序遍历结果,即为所求。
因为我们在构图时,是先修课程指向了后修课程。
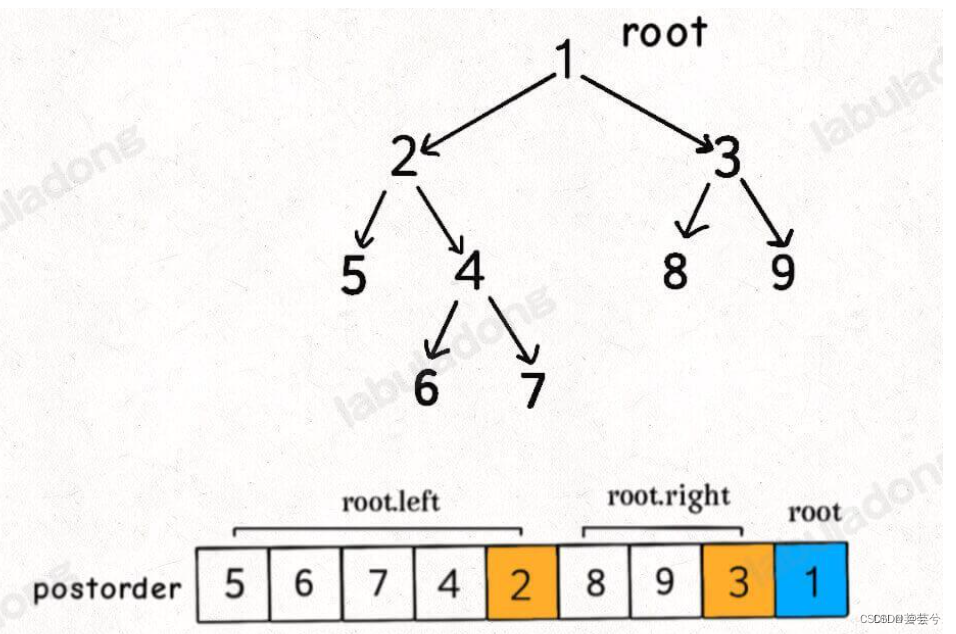
后序遍历结果保证了,先有孩子节点后有父节点,而我们的拓扑排序要求与此相反,我们需要先有父节点(先修),再由孩子节点(后序),因此需要反向post。
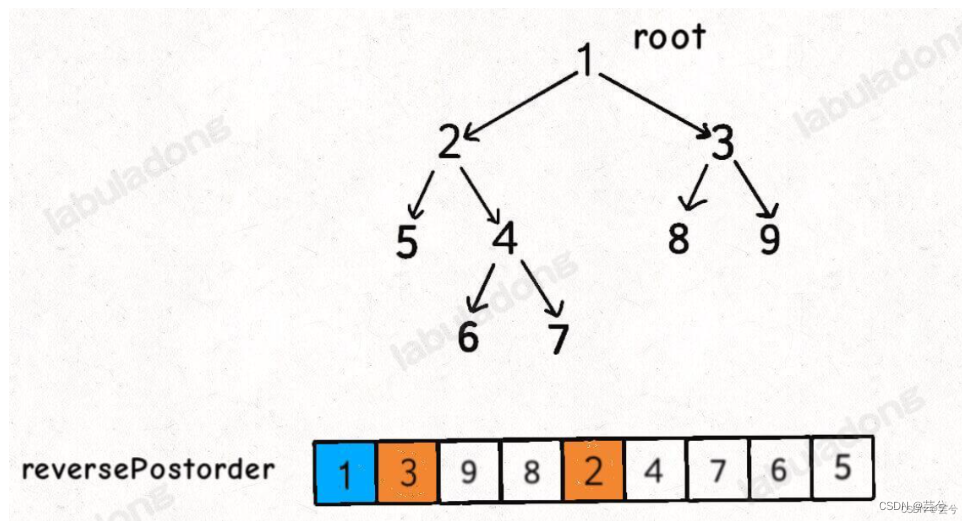
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> g(numCourses);
for (auto p : prerequisites) {
g[p[1]].push_back(p[0]);
}
bool hasCircle = false;
vector<bool> visited(numCourses, false), onPath(numCourses, false);
vector<int> post;
function<void(int)> dfs = [&](int cur) {
if (hasCircle) return;
if (onPath[cur]) {
hasCircle = true;
return;
}
if (visited[cur]) return;
visited[cur] = true;
onPath[cur] = true;
for (auto e : g[cur]) {
dfs(e);
}
post.push_back(cur);
onPath[cur] = false;
};
for (int i = 0; i < numCourses; ++i) {
dfs(i);
if (hasCircle) return vector<int>{};
}
reverse(post.begin(), post.end());
return post;
}
BFS解决拓扑排序
bfs解决拓扑排序依赖于对入度的计算,首先入度为0的节点表示这个节点不依赖任何其他节点,所以可以学习,把他们加入队列,并将与它们相邻的阶段入度减一(表示这个依赖已经解决),如果新产生了入度为0的节点,说明又有新的不依赖节点,加入队列。如果这个过程接收后,所有节点都入队一次,说明无环且构建好了拓扑排序。
vector<int> findOrder(int numCourses, vector<vector<int>>& prerequisites) {
vector<vector<int>> g(numCourses);
vector<int> ins(numCourses);
for (auto p : prerequisites) {
g[p[1]].push_back(p[0]);
++ins[p[0]];
}
queue<int> que;
for(int i = 0; i < numCourses; ++i) if (ins[i] == 0) que.push(i);
vector<int> ans;
while (!que.empty()) {
int cur = que.front();
que.pop();
ans.push_back(cur);
for (auto e : g[cur]) {
--ins[e];
if (ins[e] == 0) que.push(e);
}
}
return ans.size() == numCourses ? ans : vector<int>{};
}






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结