您现在的位置是:首页 >学无止境 >分布式事务网站首页学无止境
分布式事务
数据库事务
Atomicity 原子性
某个操作,要么全部执行完毕,要么全部回滚
Consistency 一致性
数据库中的数据全都符合现实世界的约束,则这些数据就符合一致性。
比如性别约束男or女,人名币面值不能为负数;出生地址不能为null;参与转账的账户总余额不变;等等。
Isolation 隔离性
多个事务访问相同数据时,对该数据不同状态的转换对应的数据库操作的执行顺序有一定的规律,彼此不干涉
Burability 持久性
现实中的状态转换映射到数据库中,意味着对数据所做的修改都应该在磁盘中保存
事务的状态有哪些?
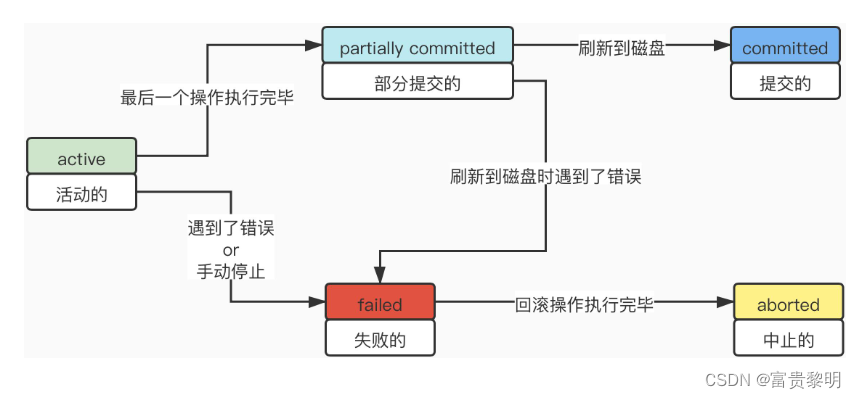 事务并发执行时数据一致性问题有哪些?
事务并发执行时数据一致性问题有哪些?
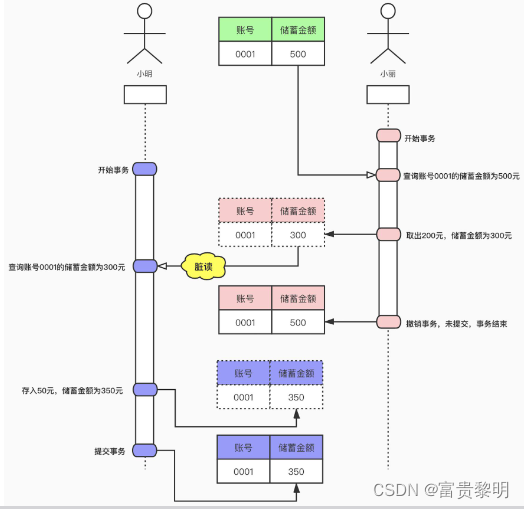
脏读
如果一个事务提取到了另一个未提交事务(小丽)修改过的数据。就意味着发生了脏读现象
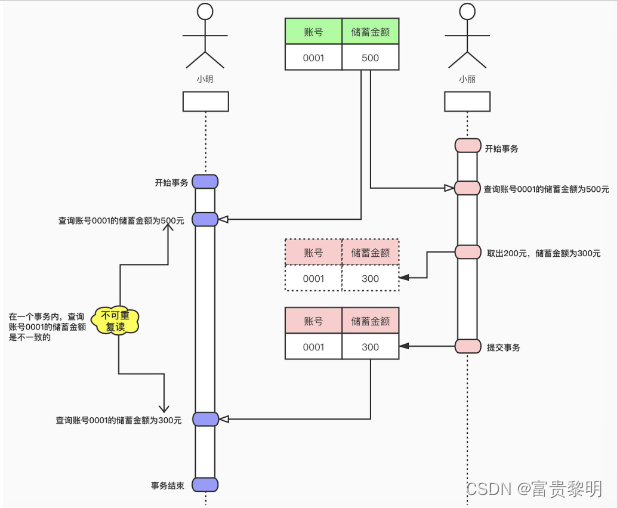
不可重复读
如果一个事务修改了另一个未提交事务读取的数据,就意味着发生了不可重复读现象,或者叫模糊读FuzzyRead
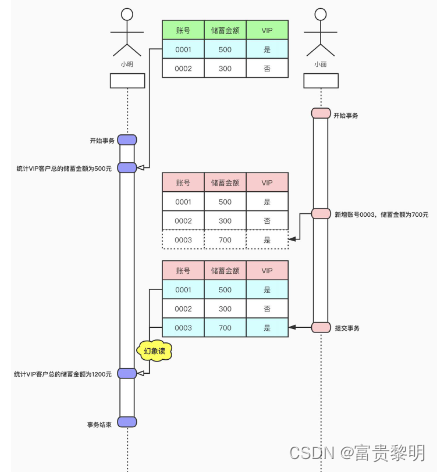
幻读
如果一个事务先根据某些搜索条件(select … where vip=‘是’)查询到了一些记录,但是在该事务并未提交时,另一个事务(小丽)写入了一些符合上面搜索条件的记录(这里的写入可以值insert、delete、update操作。例如:insert into … values(‘0003’,700,‘是’),就意味着发生了幻读现象。
SQL事务隔离级别
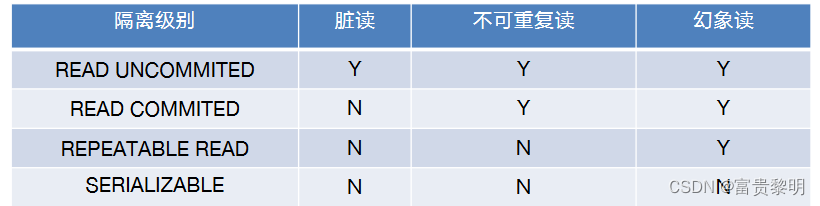 无论哪种隔离级别,都不允许脏写的情况发生,所以没有列入表格内
无论哪种隔离级别,都不允许脏写的情况发生,所以没有列入表格内
分布式场景下事务及数据一致性问题
在系统开发过程中,我们据大部分时间使用的是关系型数据库,那么当数据量不大的时候,我们通过单库单表就可以保证某个业务数据的存储能力了,并且通过数据库对事务的支持,可以很好的解决数据一致性问题。
但是,当数据量增大了之后,不仅仅是单表查询效率Bianca低下,而且数据所占用空间的限制,都会促使着我们采用分库分表的解决方案。但是当涉及到分库的时候,却打破了我们依赖数据库控制事务一致性的便捷方式,只能物品们采用其他方案来进行事务的控制,因此分布式场景下数据一致性问题就显著的凸显了出来。
既然谈到分库,我们来看一下常见的两种分库方式,即:水平分库和垂直分库。
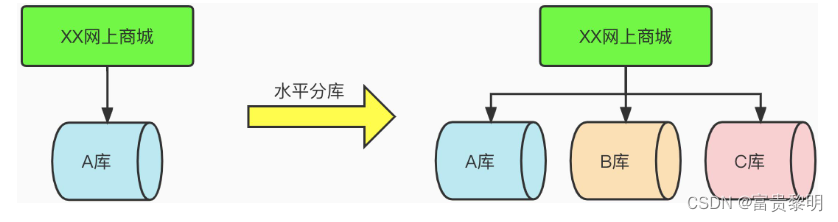
- 水平分库
当公司在创业初期,业务刚刚起步,我们的订单表每天能产生5W条数据,那么放到一张表中完全可以应对现在的业务需求。
但是随着公司的发展,业务逐一的在推进,订单量一年后,突增为100W,那为了应对公司业务的发展和高速增长的订单量,就会将数据库扩展为A,B,C这三个库,并且在每个数据库中按照相同的表结构复制出多份,来平均分摊每天产生的订单。那么这种分库的方式,就是水平分库。
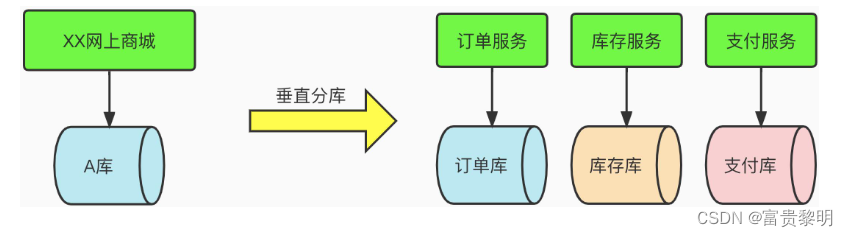
- 垂直分库
随着公司发展,我们都无法避免要从创业初期的单体架构拆分成微服务架构,那么针对不同的业务域会进行服务的拆分,那么面对着代码曾念的解耦解决了之后,面对数据库层面的解耦如何处理呢?
那么,很容易我们就会想到,要将A库按照不同的业务域进行拆分,比如:拆分成订单库,删评库存库,支付库等等。那么面对着这种数据库的拆分方式,就是垂直分库了,如下图所示:
分布式事务解决方案
分布式服务购物逻辑伪代码实现
我们以快捷支付的方式在商城购买商品为例(即:下完订单自动支付),看一下分布式事务在实现上与非分布式的区别。前提是我们针对订单服务、库存服务和支付服务这三个服务都有对应的三个数据库,分别是订单库、库存库和支付库。
如果我们平时以声明式事务来编码,那么他与本地事务在编码上没有区别,都是标注一个@Transaction注解而已,但是如果以编程式事务来实现的话,就能在写法上看出差异了,伪代码如下所示:

由于订单,库存和支付是三个服务和数据库,所以,我们需要分别开启这三个数据库事务,并且执行完毕后,分别执行三次commit操作
如果在调用payTransaction.commit()方法时,出现了异常,那么由于order和stock已经成功的调用了commit,所以,无法执行rollback操作了。而只有pay服务可以正常回滚。那么,就造成了分布式事务的不一致性。
分布式事务解决方案概述
-
刚性事务(强一致性事务)
XA
2PC
3PC -
柔性事务
可靠时间队列
TCC
SAGA
基于数据补偿
刚性事务 - XA
为了解决分布式事务一致性问题,X/Open组织提出了一套名为X/Open XA的处理事务架构,其核心内容是定义了全局的事务管理器和局部的资源管理器之间的通信接口。XA接口是双向的,能在一个事务管理器和多个资源管理器之前形成通信桥梁,通过协调多个数据源的一致动作,实现全局事务的统一提交或者统一回滚。
XA并不是Java的技术规范,二十一套跟语言无关的通用规范,所以Java中专门定义了JSR 907 Java Transaction API, 基于XA模式在Java语言中实现了全局事务处理的标准,这也就是我们现在熟知的JTA。
JTA最主要的两个接口如下:
- 事务管理器接口
- 满足XA规范的资源定义接口
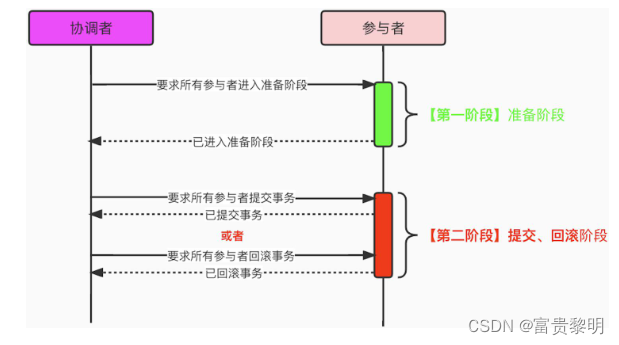
- 刚性事务(2PC)
为了保证整个事务的一致性,XA将事务提交拆分成两阶段,即:二段式提交协议,交互时序示意图如下所示:
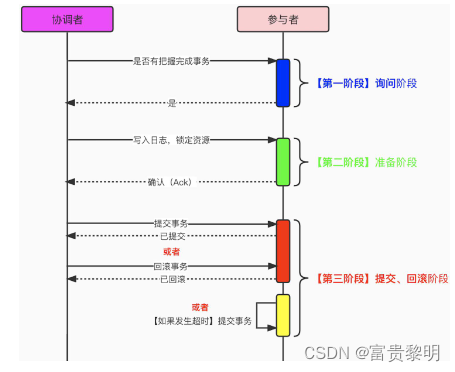
- 刚性事务(3PC)
为了缓解2PC中协调者的单点问题和准备阶段的性能问题,后续发展出了“三段式提交”,即: 3PC协议,交互时序示意图如下所示:
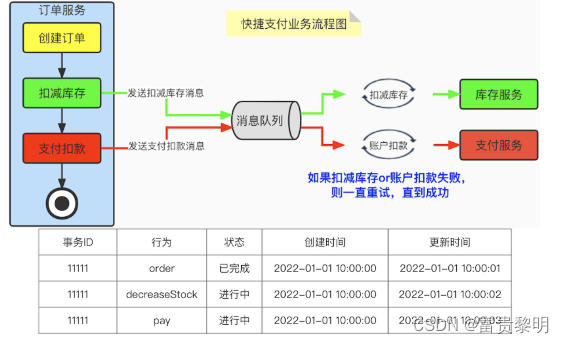
柔性事务(可靠事务队列)
以快捷支付为例,当用户下单的时候,自动就进行了支付扣款操作。那么创建订单、扣减库存和支付扣款这三个操作就应该是一个原子性的操作。那么如果我们采取可靠时间队列的方式,则流程如下图所示:
- 柔性事务(TCC)
TCC 是 Try-Confirm-Cancel的缩写,是常见的分布式事务机制
在具体实现上,TCC较为繁琐,他是一种业务侵入式较强的事务方案,要求业务处理过程必须拆分成“预留业务资源”和“确认/释放消费资源”两个子过程。
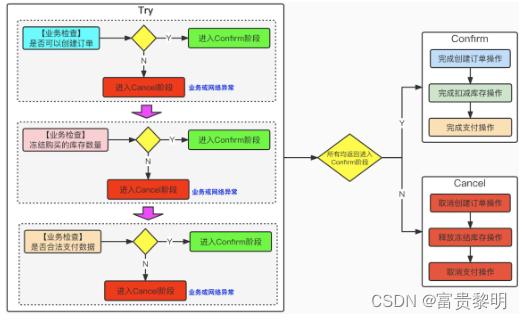
Try(尝试执行阶段)
完成所有业务可执行性的检查(保障一致性),并且预留好全部需要用到的业务资源(保障隔离性)。
Confirm(确认执行阶段)
不进行任何业务检查,直接使用Try阶段准备的资源来完成业务处理。
Confirm阶段可能会重复执行,因此本阶段执行的操作需要具备幂等性。
Cancel(取消执行阶段)
释放Try阶段预留的业务资源
Cancel阶段可能会重复执行,因此本阶段执行的操作需要具备幂等性。
- 柔性事务(SAGA)
SAGA事务:把一个大事务分解为可以交错运行的一系列子事务集合。原本SAGA的目的是避免大事务长时间锁定数据库资源,后来才发展成将一个分布式环境中的大事务分解成一系列本地事务的设计模式。
与TCC相比,SAGA不需要为资源设计冻结状态和撤销冻结的操作,补偿操作往往要比冻结操作容易实现的多。
SAGA必须保证所有子事务都得以提交或者补偿,但SAGA系统本身也有可能会崩溃,所以他必须设计成与数据库类似的日志机制(被称为SAGA log),以保证系统恢复后可以追踪到子事务的执行情况,比如执行到哪一步或者补偿到哪一步了。
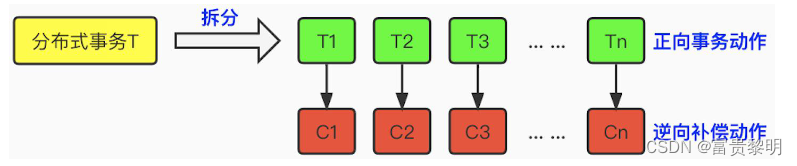 - 柔性事务(基于数据补偿)
- 柔性事务(基于数据补偿)
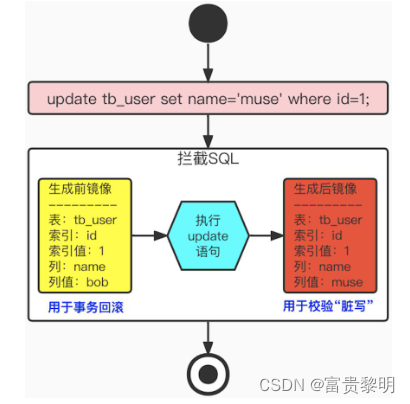
Seata的AT模式就是基于数据补偿来代替回滚思路的
AT事务是参照了XA两段提交协议实现的,但是AT并不需要等待所有数据源都返回成功采取执行全局提交,而是通过了拦截SQL的方式,生成前后镜像,生成行锁,通过本地事务一起提交到操作的数据源中,相当于自己记录了重做和回滚日志。
如果分布式事务成功提交,那后续清理每个数据源中对应的日志数据即可;如果分布式事务需要回滚,就根据日志数据自动产生同用于补偿的"逆向SQL“。
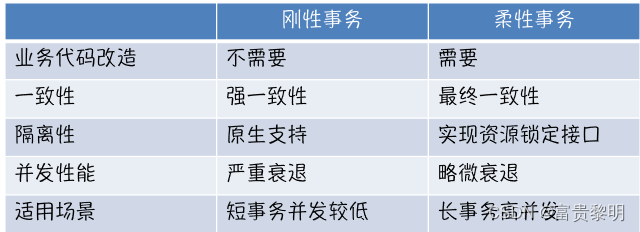
刚性事务和柔性事务对比
 一致性保障:XA > TCC = SAGA > 事务消息
一致性保障:XA > TCC = SAGA > 事务消息
业务友好性:XA > 事务消息 > SAGA > TCC
性能损耗:XA > TCC = SAGA = 事务消息






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结