您现在的位置是:首页 >技术杂谈 >【Hive实战】探索Hive 2.X以及更早版本的MetaStore网站首页技术杂谈
【Hive实战】探索Hive 2.X以及更早版本的MetaStore
探索Hive 2.X以及更早版本的MetaStore
文章目录
概述
Metadata 指的是Hive元数据,元数据包含了由hive创建的库、表相关的元信息。
Metastore 指的是元数据服务。Hive元数据都是通过Hive Metastore访问的。MetaStore会被查询处理器在计划生成过程中使用。元数据服务包含以下部分
-
Metastore Server(元数据服务端) - 这是Thrift服务器(在metastore/if/hive_metastore.if中定义的接口),为客户端的元数据请求提供服务。它将大多数请求委托给底层元数据存储和包含数据的Hadoop文件系统。
-
Object Store(对象存储) - ObjectStore类处理对实际元数据的访问,并存储在SQL存储中。目前的实现使用JPOX ORM解决方案,它是基于JDA规范的。它可以与JPOX支持的任何数据库一起使用。新的元存储(基于文件或基于xml)可以通过实现接口MetaStore来添加。FileStore是一个旧版本的元存储的部分实现,可能很快就会被废弃。
-
Metastore客户端 - 在metastore/src中有python、java、php Thrift客户端。Java生成的客户端被扩展为HiveMetaStoreClient,被查询处理器(ql/metadta)使用。这是所有其他Hive组件的主要接口。
-
db(元数据存储库)- 元数据是通过JPOX ORM解决方案(Data Nucleus)进行持久化的,因此任何被其支持的数据库都可以被Hive使用。支持的数据库矩阵如下:
数据库类型 最小要求版本 对应的参数值 其他 MySQL 5.6.17 mysqlPostgres 9.1.13 postgresOracle 11g oraclehive.metastore.orm.retrieveMapNullsAsEmptyStrings MS SQL Server 2008 R2 mssql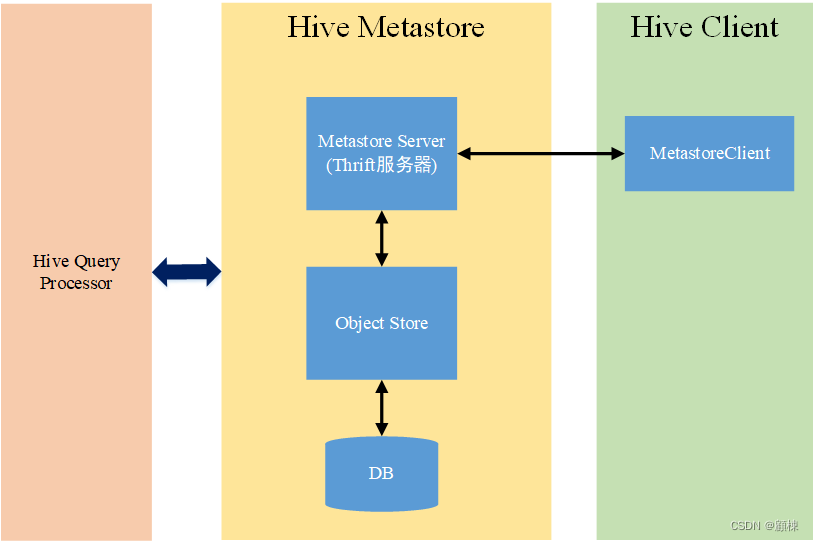
配置元数据服务和元数据存储库
Hive 配置参数,若无特别说明,默认指在hive-site.xml文件中。
元数据服务存在三种模式
-
内嵌模式:使用的是内嵌的Derby数据库来存储元数据,也不需要额外起Metastore服务。数据库和Metastore服务都嵌入在主Hive Server进程中。这个是默认的,配置简单,但是一次只能一个客户端连接,适用于用来实验,不适用于生产环境。
-
本地模式:采用外部数据库来存储元数据,目前支持的数据库有:MySQL、Postgres、Oracle、MS SQL Server.在这里我们使用MySQL。 本地模式不需要单独起metastore服务,用的是跟hive在同一个进程里的metastore服务。也就是说当你启动一个hive 服务,里面默认会帮我们启动一个metastore服务。hive根据
hive.metastore.uris参数值来判断,如果为空,则为本地模式 -
远程模式:需要单独起metastore服务,然后每个客户端都在配置文件里配置连接到该metastore服务。远程模式的metastore服务和hive运行在不同的进程里。
基础配置参数
| Configuration Parameter | Description | 功能 |
|---|---|---|
javax.jdo.option.ConnectionURL | 包含元数据的数据存储的JDBC连接字符串 | Hive Metastore的元数据存储库 |
javax.jdo.option.ConnectionDriverName | 包含元数据的数据存储的JDBC驱动类名称 | Hive Metastore的元数据存储库 |
hive.metastore.uris | Hive连接到这些URI中的一个,以向远程Metastore(以逗号分隔的URI列表)发出元数据请求。默认值为空。 | Hive Metastore的Server |
hive.metastore.local | 本地或远程元存储(从Hive 0.10开始删除: 如果hive.metastore.uris为空,则假定为local模式,否则为remote模式) | Hive Metastore的Server |
hive.metastore.warehouse.dir | 用户hive表的存储默认位置URI | Hive Metastore的Server |
Hive Metastore是无状态的,因此可以有多个Metastore实例来实现高可用性。使用hive.metastore.uris,可以指定多个远程Hive Metastore Server。Hive默认使用列表中的第一个,但在连接失败时将随机选择一个并尝试重新连接。
其他配置参数
除了基础配置参数,剩余的其他配置参数主要在Java文件HiveConf.java中。不同版本之间的参数的默认值存在区别,可以通过阅读源码发现或者查询默认配置文件hive-site.xml与hivemetastore-site.xml中确认。。以下是部分版本的一些配置举例:
| Configuration Parameter | Description | Default Value |
|---|---|---|
hive.metastore.metadb.dir | 文件库元数据基础目录的位置。(该功能在0.4.0版本中随着HIVE-143而被移除)。 | |
hive.metastore.rawstore.impl | 实现org.apache.hadoop.hive.metastore.rawstore接口的类的名称。该类用于存储和检索原始元数据对象,如表、数据库。(Hive 0.8.1及以后版本。) | org.apache.hadoop.hive.metastore.ObjectStore |
org.jpox.autoCreateSchema | 如果不存在schema ,在启动时创建必要的schema 。(schema 包括表、列等。)在创建一次后设置为false。 | |
org.jpox.fixedDatastore | 数据存储Schema是否是固定的。 | |
datanucleus.autoStartMechanism | 是否在启动时进行初始化。 | |
hive.metastore.ds.connection.url.hook | 用于获取JDO连接URL的钩子的名称。如果为空,则使用javax.jdo.option.ConnectionURL中的值作为连接URL。(Hive 0.6及以后的版本。) | |
hive.metastore.ds.retry.attempts | 如果出现连接错误,重试对后备数据存储的调用的次数。(Hive 0.6到0.12;在0.13.0中移除–使用hive.hmshandler.retry.attempts代替。) | 1 |
hive.metastore.ds.retry.interval | 数据存储重试间隔的毫秒数。(Hive 0.6到0.12;在0.13.0中移除–使用hive.hmshandler.retry.interval代替。) | 1000 |
hive.metastore.server.min.threads | Thrift服务器池中的最小工作线程数。 (Hive 0.6及以后版本。) | 200 |
hive.metastore.server.max.threads | Thrift服务器池中的最大工作线程数。 (Hive 0.6及以后版本。) | 100000 since Hive 0.8.1 |
hive.metastore.filter.hook | Metastore钩子类,用于在客户端进一步过滤元数据的读取结果。(Hive 1.1.0及以后的版本。) | org.apache.hadoop.hive.metastore.DefaultMetaStoreFilterHookImpl |
hive.metastore.port | Hive元存储监听器端口。(Hive 1.3.0及以后的版本。) | 9083 |
默认配置
默认配置设置了一个嵌入的元存储数据库,在单元测试中使用。
配置元服务数据库
使用内嵌模式的Derby库
Derby是嵌入式元存储的默认数据库。
| Config Param | Config Value | Comment |
|---|---|---|
javax.jdo.option.ConnectionURL | jdbc:derby:;databaseName=../build/test/junit_metastore_db;create=true | Derby database located at hive/trunk/build… |
javax.jdo.option.ConnectionDriverName | org.apache.derby.jdbc.EmbeddedDriver | Derby embeded JDBC driver class. |
hive.metastore.warehouse.dir | file://${user.dir}/../build/ql/test/data/warehouse | 使用本地的文件系统 |
使用远程数据存储库
使用一个传统的独立RDBMS服务器。下面的例子配置将在MySQL服务器中设置一个元存储。这种元存储数据库的配置被推荐用于任何实际使用。
| Config Param | Config Value | Comment |
|---|---|---|
javax.jdo.option.ConnectionURL | jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=true | 元数据存储库的连接URL |
javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver | MySQL JDBC driver class |
javax.jdo.option.ConnectionUserName | <user name> | MySQL server的用户名 |
javax.jdo.option.ConnectionPassword | <password> | MySQL server的用户密码 |
配置元数据服务
本地/内嵌服务配置
在采用内嵌式元存储配置时,元存储服务组件就像Hive客户端中的一个库一样被使用。每个Hive客户端将打开一个与数据库的连接,并对其进行SQL查询。确保数据库可以从执行Hive查询的机器上访问,因为这是一个本地存储。还要确保JDBC客户端库在Hive客户端的classpath中。这种配置通常与HiveServer2一起使用(要在HiveServer2中使用嵌入式元存储,请在hiveserver2启动命令的命令行参数中添加"–hiveconf hive.metastore.uris=’ '"或者使用hiveserver2-site.xml(在Hive 0.14中可用))。
| Config Param | Config Value | Comment |
|---|---|---|
hive.metastore.uris | Hive连接到这些URI中的一个,以向远程Metastore(以逗号分隔的URI列表)发出元数据请求。默认值为空。 | |
hive.metastore.local | false | 元存储使用本地/内嵌 |
hive.metastore.warehouse.dir | <base hdfs path> | 指向HDFS中的非外部Hive表的默认位置。 |
远程服务配置
在远程元存储设置中,所有的Hive客户端都会与元存储服务建立连接,而元存储服务又会向数据存储(本例中为MySQL)查询元数据。元存储服务器和客户端使用Thrift协议进行通信。从Hive 0.5.0开始,你可以通过执行以下命令来启动Thrift服务器:
hive --service metastore
# 制定元数据服务的服务端口
hive --service metastore -p <port_num>
In versions of Hive earlier than 0.5.0, it’s instead necessary to run the Thrift server via direct execution of Java:
在0.5.0之前的Hive版本中,反而需要通过直接执行Java来运行Thrift服务器:
$JAVA_HOME/bin/java -Xmx1024m -Dlog4j.configuration=file://$HIVE_HOME/conf/hms-log4j.properties -Djava.library.path=$HADOOP_HOME/lib/native/Linux-amd64-64/ -cp $CLASSPATH org.apache.hadoop.hive.metastore.HiveMetaStore
如果你直接执行Java,那么JAVA_HOME、HIVE_HOME、HADOOP_HOME必须正确设置;CLASSPATH应该包含Hadoop、Hive(lib和auxlib)和Java jars。
元数据服务配置举例
采用远程元存储(数据库采用Mysql)+元服务远程模式。
在启动Hive客户端或HiveMetastore服务器之前,将MySQL jdbc库放在HIVE_HOME/lib中。
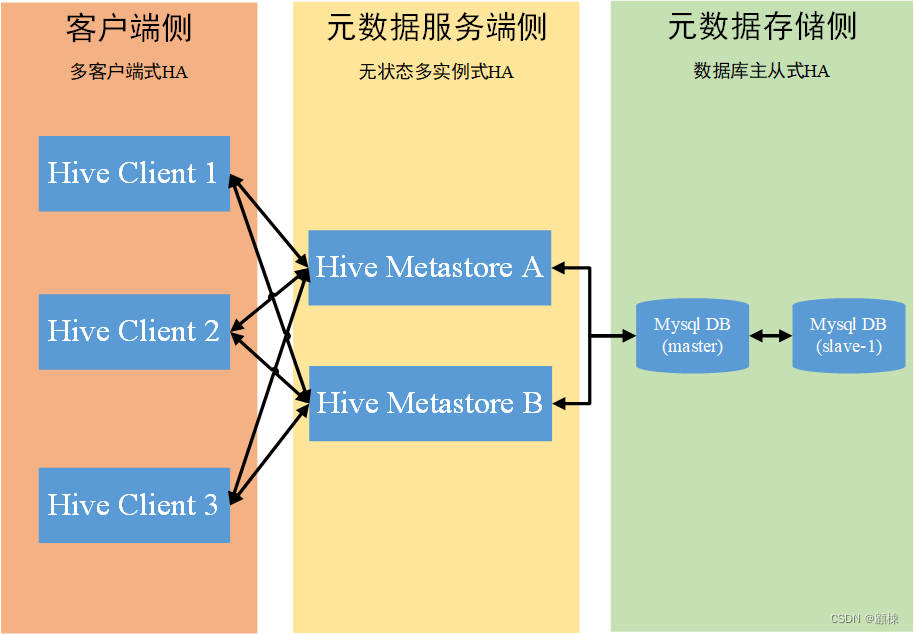
元服务的服务端配置
| Config Param | Config Value | Comment |
|---|---|---|
javax.jdo.option.ConnectionURL | jdbc:mysql://<host name>/<database name>?createDatabaseIfNotExist=true | 数据库连接的URL |
javax.jdo.option.ConnectionDriverName | com.mysql.jdbc.Driver | MySQL JDBC 驱动类 |
javax.jdo.option.ConnectionUserName | <user name> | MySQL server用户名 |
javax.jdo.option.ConnectionPassword | <password> | MySQL server用户密码 |
hive.metastore.warehouse.dir | <base hdfs path> | hive表的存储路径 |
从Hive 3.0.0(HIVE-16452)开始,元存储数据库存储了一个GUID,元存储客户端可以使用Thrift API get_metastore_db_uuid进行查询,以识别后端数据库实例。HiveMetaStoreClient可以通过getMetastoreDbUuid()方法访问该API。
元数据服务的客户端配置
即hive客户端配置
| Config Param | Config Value | Comment |
|---|---|---|
hive.metastore.uris | thrift://<host_name>:<port> | Thrift元存储服务器的主机和端口。如果指定了hive.metastore.thrift.bind.host,主机应该与该配置相同。请阅读动态服务发现配置参数中的更多内容。 |
hive.metastore.local | false | 元数据服务远程模式 |
hive.metastore.warehouse.dir | <base hdfs path> | hive表的存储路径 |
元存储Schema 的一致性与升级
Version
Introduced in Hive 0.12.0. See HIVE-3764.
Hive现在会在元存储数据库中记录schema版本,并验证元存储schema版本是否与将要访问元存储的Hive二进制文件兼容。请注意,默认情况下,Hive的隐式创建或改变现有schema的属性是禁用的。Hive不会试图以隐式方式改变元存储模式。当你针对一个旧的schema执行Hive查询时,它将无法访问元存储。
要禁止schema检查并允许元存储隐式修改模式,你需要在hive-site.xml中设置配置属性hive.metastore.schema.verification为false。
Hive Schema Tool
从0.12版开始,Hive发行版现在包括一个用于Hive元存储schema操作的离线工具。该工具可以用来为当前的Hive版本初始化元存储schema。它还可以处理将模式从旧版本升级到当前版本。它会尝试从元存储中找到当前的schema,如果它是可用的。这将适用于未来的升级,如0.12.0到0.13.0。如果是从0.7.0或0.10.0这样的旧版本升级,可以指定现有元存储的schema版本作为工具的命令行选项。
Metastore Schema Verification
Hive现在会在元存储数据库中记录Schema版本,并验证元存储Schema版本是否与将要访问元存储的Hive二进制文件兼容。请注意,默认情况下,Hive的隐式创建或改变现有Schema的属性是禁用的。Hive不会试图以隐式方式改变元存储Schema。当你针对一个旧模式执行Hive查询时,它将无法访问元存储:
$ build/dist/bin/hive -e "show tables"
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
日志中会出现以下错误信息
...
Caused by: MetaException(message:Version information not found in metastore. )
...
默认情况下,配置属性hive.metastore.schema.verification为false,如果模式不匹配,metastore会隐式写入Schema版本。要启用严格的模式验证,你需要在hive-site.xml中把这个属性设置为true。
schematool会找到初始化或升级schema所需的SQL脚本,然后针对后端数据库执行这些脚本。元存储数据库的连接信息,如JDBC URL、JDBC驱动和数据库凭证都是从Hive配置中提取的。如果需要,你可以提供其他的数据库凭证。
The schematool Command
schematool会找到初始化或升级schema所需的SQL脚本,然后针对后端数据库执行这些脚本。元存储数据库的连接信息,如JDBC URL、JDBC驱动和数据库凭证都是从Hive配置中提取的。
schematool 命令用以下选项调用Hive模式工具:
$ schematool -help
usage: schemaTool
-dbType <databaseType> Metastore database type
-driver <driver> Driver name for connection
-dryRun List SQL scripts (no execute)
-help Print this message
-info Show config and schema details
-initSchema Schema initialization
-initSchemaTo <initTo> Schema initialization to a version
-metaDbType <metaDatabaseType> Used only if upgrading the system catalog for hive
-passWord <password> Override config file password
-upgradeSchema Schema upgrade
-upgradeSchemaFrom <upgradeFrom> Schema upgrade from a version
-url <url> Connection url to the database
-userName <user> Override config file user name
-verbose Only print SQL statements
(Additional catalog related options added in Hive 3.0.0 (HIVE-19135] release are below.
-createCatalog <catalog> Create catalog with given name
-catalogLocation <location> Location of new catalog, required when adding a catalog
-catalogDescription <description> Description of new catalog
-ifNotExists If passed then it is not an error to create an existing catalog
-moveDatabase <database> Move a database between catalogs. All tables under it would still be under it as part of new catalog. Argument is the database name. Requires --fromCatalog and --toCatalog parameters as well
-moveTable <table> Move a table to a different database. Argument is the table name. Requires --fromCatalog, --toCatalog, --fromDatabase, and --toDatabase
-toCatalog <catalog> Catalog a moving database or table is going to. This is required if you are moving a database or table.
-fromCatalog <catalog> Catalog a moving database or table is coming from. This is required if you are moving a database or table.
-toDatabase <database> Database a moving table is going to. This is required if you are moving a table.
-fromDatabase <database> Database a moving table is coming from. This is required if you are moving a table.
dbType的取值以下一种:
derby|mysql|postgres|oracle|mssql
示例
-
为新的Hive设置初始化为当前schema :schematool -dbType mysql -initSchema
$ schematool -dbType derby -initSchema Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting metastore schema initialization to 0.13.0 Initialization script hive-schema-0.13.0.derby.sql Initialization script completed schemaTool completed -
获取schema 的信息:
$ schematool -dbType derby -info Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Hive distribution version: 0.13.0 Metastore schema version: 0.13.0 schemaTool completed -
试图用较早的元存储获取schema信息:
$ schematool -dbType derby -info Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Hive distribution version: 0.13.0 org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version. *** schemaTool failed ***由于旧的元存储没有存储版本信息,该工具报告了一个检索错误。
-
通过指定’from’版本,从0.10.0版本升级schema :
$ schematool -dbType derby -upgradeSchemaFrom 0.10.0 Metastore connection URL: jdbc:derby:;databaseName=metastore_db;create=true Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting upgrade metastore schema from version 0.10.0 to 0.13.0 Upgrade script upgrade-0.10.0-to-0.11.0.derby.sql Completed upgrade-0.10.0-to-0.11.0.derby.sql Upgrade script upgrade-0.11.0-to-0.12.0.derby.sql Completed upgrade-0.11.0-to-0.12.0.derby.sql Upgrade script upgrade-0.12.0-to-0.13.0.derby.sql Completed upgrade-0.12.0-to-0.13.0.derby.sql schemaTool completed
-
升级试运行可以用来列出给定升级所需的脚本
$ build/dist/bin/schematool -dbType derby -upgradeSchemaFrom 0.7.0 -dryRun Metastore Connection Driver : org.apache.derby.jdbc.EmbeddedDriver Metastore connection User: APP Starting upgrade metastore schema from version 0.7.0 to 0.13.0 Upgrade script upgrade-0.7.0-to-0.8.0.derby.sql Upgrade script upgrade-0.8.0-to-0.9.0.derby.sql Upgrade script upgrade-0.9.0-to-0.10.0.derby.sql Upgrade script upgrade-0.10.0-to-0.11.0.derby.sql Upgrade script upgrade-0.11.0-to-0.12.0.derby.sql Upgrade script upgrade-0.12.0-to-0.13.0.derby.sql schemaTool completed如果你只是想找出模式升级所需的所有脚本,这很有用。
-
将一个数据库及其下的表从默认的Hive目录移到自定义的spark目录中
build/dist/bin/schematool -moveDatabase db1 -fromCatalog hive -toCatalog spark -
将表从Hive目录移至Spark目录
# Create the desired target database in spark catalog if it doesn't already exist. beeline ... -e "create database if not exists newdb"; schematool -moveDatabase newdb -fromCatalog hive -toCatalog spark # Now move the table to target db under the spark catalog. schematool -moveTable table1 -fromCatalog hive -toCatalog spark -fromDatabase db1 -toDatabase newdb
元存储数据库
2.X的元数据服务采用Mysql作为元存储数据库表结构如下:
| Hive Metastore 2.X 表结构 Mysql | |||
|---|---|---|---|
| 序号 | 表名 | 备注 | 关联 |
| 1 | dbs | 记录Hive数据库的信息 | |
| 2 | database_params | 记录DB的一些扩展信息,便于进行特殊属性的扩展 | |
| 3 | db_privs | 记录该DB下的权限记录信息 | |
| 4 | funcs | 记录hive中函数的信息 | |
| 5 | tbls | 记录Hive数据表的信息 | |
| 6 | partitions | 记录Hive表的DDL分区的信息 | |
| 7 | idxs | 记录Hive表的索引信息 | |
| 8 | partition_keys | 记录Hive表的分区字段 | |
| 9 | tab_col_stats | 记录Hive表的列信息的统计 | |
| 10 | table_params | 记录Hive表的一些扩展信息,便于进行特殊属性的扩展 | |
| 11 | tbl_col_privs | 记录hive表的列权限认证信息 | |
| 12 | tbl_privs | 记录hive表的表权限认证信息 | |
| 13 | sds | 记录Hive表的存储信息,计算引擎运行时需要的input与output 、location路径以及序列化的class信息 | |
| 14 | bucketing_cols | 记录Hive表bucket信息 | |
| 15 | sd_params | 记录Hive表的存储信息的扩展信息 | |
| 16 | skewed_col_names | 数据倾斜相关 | |
| 17 | skewed_col_value_loc_map | 数据倾斜相关 | |
| 18 | skewed_values | 数据倾斜相关 | |
| 19 | sort_cols | 记录要进行排序的列 | |
| 20 | cds | 记录字段的编号 | |
| 21 | serdes | 记录序列化和反序列化信息 | |
| 22 | index_params | 记录hive表索引的扩展信息 | |
| 23 | global_privs | 记录全局权限信息 | |
| 24 | part_col_privs | 记录分区字段的权限信息 | |
| 25 | part_privs | 记录分区的权限信息 | |
| 26 | roles | 用户角色 | |
| 27 | role_map | 记录角色权限 | |
| 28 | func_ru | 用于存储该udf的类型及指向的路径。 | |
| 29 | part_col_stats | 记录分区的字段的统计信息 | |
| 30 | skewed_string_list | 数据倾斜相关 | |
| 31 | skewed_string_list_values | 数据倾斜相关 | |
| 32 | compaction_queue | 压缩相关 | |
| 33 | completed_compactions | 压缩相关 | |
| 34 | next_compaction_queue_id | 压缩相关 | |
| 35 | completed_txn_components | 事务管理? | |
| 36 | txn_components | 事务管理? | |
| 37 | txns | 事务管理? | |
| 38 | next_txn_id | 事务管理? | |
| 39 | version | 记录Hive的版本 | |
| 40 | sequence_table | 记录Hive元数据mode的下一个序列值 | |
| 41 | columns_v2 | 记录列的基本信息 | |
| 42 | delegation_tokens | ??? | |
| 43 | aux_table | ? | |
| 44 | hive_locks | 锁? | |
| 45 | next_lock_id | 锁? | |
| 46 | key_constraints | 表约束? | |
| 47 | type_fields | 类型字段?? | |
| 48 | types | 类型?? | |
| 49 | nucleus_tables | 这些表是被管理的由DataNucleus ORM层创建 | |
| 50 | notification_sequence | 通知序列 ? | |
| 51 | notification_log | 通知日志 ? | |
| 52 | master_keys | 管理主键? | |
| 53 | write_set | ? | |
| 54 | partition_events | 分区上的事件 | |
| 55 | partition_key_vals | 分区键的值 | |
| 56 | partition_params | 分区上的扩展信息 | |
| 57 | serde_params | 序列化相关扩展信息 | |
常用表中文支持
alter table hive_metastore.dbs modify column `DESC` varchar(4000) character set utf8;
alter table hive_metastore.database_params modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive_metastore.COLUMNS_V2 modify column `COMMENT` varchar(256) character set utf8;
alter table hive_metastore.TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive_metastore.PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table hive_metastore.PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table hive_metastore.INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
常用表说明
DAM业务使用表
DBS
| 字段 | 注释 |
|---|---|
| DB_ID | 数据库的编号,默认的数据库编号为1,如果创建其他数据库的时候,这个字段会自增,主键 |
| DESC | 对数据库进行一个简单的介绍 |
| DB_LOCATION_URI | 数据库的存放位置,default库是存放在hdfs://ip:9000/user/hive/warehouse,如果是其他数据库,就在后面添加目录,默认位置可以通过参数hive.metastore.warehouse.dir来设置 |
| NAME | 数据库的名称 |
| OWNER_NAME | 数据库拥有主体的名称 |
| OWNER_TYPE | 数据库拥有主体的类型,USER:代表OWNER_NAME存放的是用户名;ROLE:代表OWNER_NAME存放的是角色名 |
DATABASE_PARAMS
| 字段 | 注释 |
|---|---|
| DB_ID | 数据库编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数值 |
DB_PRIVS
新建的库时,无需对本用户进行授权(无默认新增记录)
| 字段 | 注释 |
|---|---|
| DB_GRANT_ID | 数据库授权编号 |
| CREATE_TIME | 授权时间 |
| DB_ID | 被授权的数据库ID |
| GRANT_OPTION | 授权操作 |
| GRANTOR | 授权账户 |
| GRANTOR_TYPE | 授权类型 |
| PRINCIPAL_NAME | 被授权主体名称 |
| PRINCIPAL_TYPE | 被授权主体类型 |
| DB_PRIV | 数据库权限 |
TBLS
| 字段 | 注释 |
|---|---|
| TBL_ID | 在hive中创建表的时候自动生成的一个id,用来表示,主键 |
| CREATE_TIME | 创建的数据表的时间,使用的是时间戳 |
| DB_ID | 数据库编号,表所属的数据库 |
| LAST_ACCESS_TIME | 最后一次访问的时间戳 |
| OWNER | 数据表的所有者 |
| RETENTION | 保留时间 |
| SD_ID | 标记物理存储信息的id |
| TBL_NAME | 数据表的名称 |
| TBL_TYPE | 数据表的类型,MANAGED_TABLE, EXTERNAL_TABLE, VIRTUAL_VIEW, INDEX_TABLE |
| VIEW_EXPANDED_TEXT | 展开视图文本,非视图为null |
| VIEW_ORIGINAL_TEXT | 原始视图文本,非视图为null |
TBL_PRIVS
苏宁内部改造(在新建表之后,会向此表中插入一条授权记录 bigdata拥有此表所有权限)
| 字段 | 注释 |
|---|---|
| TBL_GRANT_ID | 表授权编号 |
| CREATE_TIME | 授权时间 |
| GRANT_OPTION | 授权操作 |
| GRANTOR | 授权者 |
| GRANTOR_TYPE | 授权类型 USER ROLE GROUP |
| PRINCIPAL_NAME | 被授权主体名称 |
| PRINCIPAL_TYPE | 被授权主体类型 USER ROLE GROUP |
| TBL_PRIV | 表权限类别 |
| TBL_ID | 表的编号 |
TABLE_PARAMS
| 字段 | 注释 |
|---|---|
| TBL_ID | 数据的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
COLUMNS_V2
所有Hive表中的字段都存于此表。用于描述列的信息
| 字段 | 注释 |
|---|---|
| CD_ID | 表的编号 |
| COMMENT | 字段注释说明 |
| COLUMN_NAME | 列的名称 |
| TYPE_NAME | 列的类型 |
BUCKETING_COLS
桶表字段
| 字段 | 注释 |
|---|---|
| SD_ID | 表的编号 |
| BUCKET_COL_NAME | 作为分桶的列名称 |
| INTEGER_IDX | 列的索引 |
SORT_COLS
记录要进行排序的列
| 字段 | 注释 |
|---|---|
| SD_ID | 数据表物理信息描述的编号 |
| COLUMN_NAME | 用来列的名称 |
| ORDER | 排序方式 |
PARTITIONS
| 字段 | 注释 |
|---|---|
| PART_ID | 分区的编号 |
| CREATE_TIME | 创建分区的时间 |
| LAST_ACCESS_TIME | 最近一次访问时间 |
| PART_NAME | 分区的名字 |
| SD_ID | 存储描述的id |
| TBL_ID | 数据表的id |
PARTITION_KEYS
| 字段 | 注释 |
|---|---|
| TBL_ID | 数据表的编号 |
| PKEY_COMMENT | 分区字段的描述 |
| PKEY_NAME | 分区字段的名称 |
| PKEY_TYPE | 分区字段的类型 |
PARTITION_PARAMS
| 字段 | 注释 |
|---|---|
| PART_ID | 分区的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
SDS
| 字段 | 注释 |
|---|---|
| SD_ID | 主键 |
| CD_ID | 数据表ID |
| INPUT_FORMAT | 数据输入格式 |
| IS_COMPRESSED | 是否对数据进行了压缩 |
| IS_STOREDASSUBDIRECTORIES | 是否进行存储在子目录 |
| LOCATION | 数据存放位置 |
| NUM_BUCKETS | 分桶的数量 |
| OUTPUT_FORMAT | 数据的输出格式 |
| SERDE_ID | 序列和反序列的信息 |
SD_PARAMS
| 字段 | 注释 |
|---|---|
| SD_ID | 主键,记录序列化的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
SERDE_PARAMS
| 字段 | 注释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| PARAM_KEY | 参数的key值 |
| PARAM_VALUE | 参数的值 |
SERDES
记录序列化和反序列化信息
| 字段 | 注释 |
|---|---|
| SERDE_ID | 主键,记录序列化的编号 |
| NAME | 序列化和反序列化名称,默认为表名 |
| SLIB | 使用的是哪种序列化方式 |
新增Hive库,表与元数据存储库的关系
新建Hive库会向元数据库写入数据,
- 一个库,dbs表中新增一条记录
- 库用有几个扩展参数,database_params表新增几条记录
新建非分区表会向元数据库中以下表写入数据:
- 一张表,表中有几个字段columns_v2表中就新增几条记录
- 一张表, tbls中新增一条记录
- table_params表新增几条记录???(comment,last_modified_by, last_modified_time,numFiles,totalSize,transient_lastDdlTime)
- 一张表, cds中新增一条记录
- 一张表, sds中新增一条记录
- 一张表,有几个序列扩展字段sds_params就新增几条记录
- sds中新增几条记录serder, serder_params就新增几条记录
- tbl_privs与授权数相关
分区层级
- 在非分区表的基础上 新建一个分区就会 sds中新增一条记录
- 一个分区,PARTITIONS表中就增加一条记录,与 sds表的记录应该是一对一
- sds中新增几条记录serder, serder_params就新增几条记录
- PARTITIONS_params表新增几条记录???(last_modified_by, last_modified_time,numFiles,totalSize,transient_lastDdlTime)
- 表有几个分区字段,partition_keys就增加几条记录
- partition_key_vals,按照分区层级,每增加一个分区就增加与层级数相同的记录
分桶表
与分区表取并集
- 有几个分桶字段,bucketing_cols就增加几条记录,
- 粒度与sds表相关,sds表一条记录可以对应bucketing_cols表几条记录
排序表
与分桶表取并集
- 有几个排序字段,sort_cols表就增加几条记录
- 粒度与sds表相关,sds表一条记录可以对应sort_cols表几条记录






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结