您现在的位置是:首页 >技术教程 >uie-base使用记录(paddlenlp)网站首页技术教程
uie-base使用记录(paddlenlp)
参考文章:https://aistudio.baidu.com/aistudio/modelsdetail?modelId=22
参考文章:https://paddlenlp.readthedocs.io/zh/latest/FAQ.html
参考文章:https://developer.aliyun.com/article/1066857
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
参考文章: https://github.com/PaddlePaddle/PaddleNLP/discussions/3316
官方网址:https://www.paddlepaddle.org.cn/
python版本:3.8.10
相关包的版本
scipy==1.7.3
numpy==1.21.6
pandas==1.2.4
SQLAlchemy==1.4.18
cuda-python==11.7.1
系统:win10
显卡:GTX1060
nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 531.68 Driver Version: 531.68 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name TCC/WDDM | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1060 6GB WDDM | 00000000:01:00.0 On | N/A |
| 47% 63C P2 122W / 120W| 4767MiB / 6144MiB | 96% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Tue_May__3_19:00:59_Pacific_Daylight_Time_2022
Cuda compilation tools, release 11.7, V11.7.64
Build cuda_11.7.r11.7/compiler.31294372_0
CUDA:11.7
安装
首先,先安装paddlepaddle-gpu版,具体安装逻辑可以在官网查找到
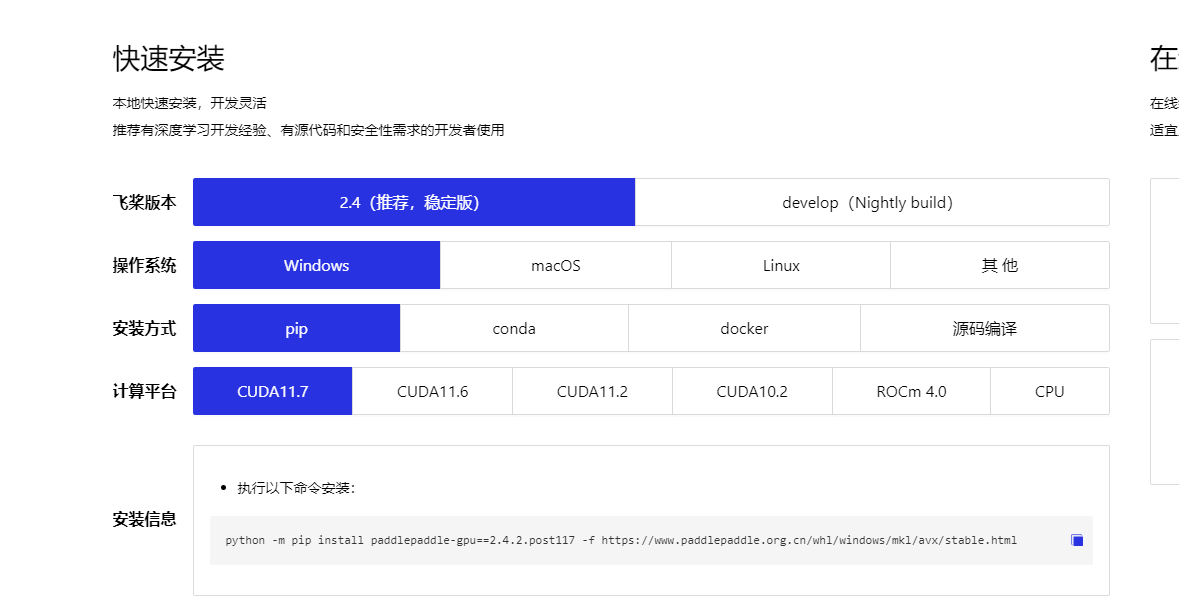
这里,我使用的gpu安装版本,下面是复制语句
python -m pip install paddlepaddle-gpu==2.4.2.post117 -f https://www.paddlepaddle.org.cn/whl/windows/mkl/avx/stable.html -i https://pypi.tuna.tsinghua.edu.cn/simple
安装好后用下面语句测试一下是否安装成功
import paddle
paddle.utils.run_check()
正常反馈信息
Running verify PaddlePaddle program ...
W0424 12:49:36.235811 1876 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 6.1, Driver API Version: 12.1, Runtime API Version: 11.7
W0424 12:49:36.240806 1876 gpu_resources.cc:91] device: 0, cuDNN Version: 8.8.
PaddlePaddle works well on 1 GPU.
PaddlePaddle works well on 1 GPUs.
PaddlePaddle is installed successfully! Let's start deep learning with PaddlePaddle now.
然后安装paddlenlp
pip install paddlenlp -i https://pypi.tuna.tsinghua.edu.cn/simple
使用
参考文章:https://paddlenlp.readthedocs.io/zh/latest/FAQ.html
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
直接使用预训练模型
from pprint import pprint
from paddlenlp import Taskflow
# os.environ['PPNLP_HOME'] = 'test_path'# 修改环境变量中的默认路径-不需要手动创建根目录-不知道是不是中文路径问题,导致无效
# os.environ['HUB_HOME'] = 'test_path'
ie = Taskflow('information_extraction', model='uie-base') # 下载到默认路径
# 设置
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie.set_schema(schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint
打印结果
[{'时间': [{'end': 6,
'probability': 0.9857378532924486,
'start': 0,
'text': '2月8日上午'}],
'赛事名称': [{'end': 23,
'probability': 0.8503087726820695,
'start': 6,
'text': '北京冬奥会自由式滑雪女子大跳台决赛'}],
'选手': [{'end': 31,
'probability': 0.8981548639781138,
'start': 28,
'text': '谷爱凌'}]}]
自行构造数据进行微调
构造数据
首先,使用doccano进行数据标注,具体可以参考这篇文章或者PaddleNLP中doccano文章的来进行数据标注。
其次,准备utils.py,finetune.py,doccano.py这三份代码。在命令行模式下,先将刚刚导出的doccano数据转化成需要的数据格式。
python doccano.py --doccano_file ./data/doccano_ext.json --task_type "ext" --save_dir ./data --negative_ratio 5
这里使用的是【抽取式任务数据转换】,其他模式请自行参考文章。
配置参数说明
- doccano_file: 从doccano导出的数据标注文件。
- save_dir: 训练数据的保存目录,默认存储在data目录下。
- negative_ratio: 最大负例比例,该参数只对抽取类型任务有效,适当构造负例可提升模型效果。负例数量和实际的标签数量有关,最大负例数量 = negative_ratio * 正例数量。该参数只对训练集有效,默认为5。为了保证评估指标的准确性,验证集和测试集默认构造全负例。
- splits: 划分数据集时训练集、验证集所占的比例。默认为[0.8, 0.1, 0.1]表示按照8:1:1的比例将数据划分为训练集、验证集和测试集。
- task_type: 选择任务类型,可选有抽取和分类两种类型的任务。
- options: 指定分类任务的类别标签,该参数只对分类类型任务有效。默认为[“正向”, “负向”]。
- prompt_prefix: 声明分类任务的prompt前缀信息,该参数只对分类类型任务有效。默认为"情感倾向"。
- is_shuffle: 是否对数据集进行随机打散,默认为True。
- seed: 随机种子,默认为1000.
- separator: 实体类别/评价维度与分类标签的分隔符,该参数只对实体/评价维度级分类任务有效。默认为"##"。
备注: - 默认情况下 doccano.py 脚本会按照比例将数据划分为 train/dev/test 数据集
- 每次执行 doccano.py 脚本,将会覆盖已有的同名数据文件
- 在模型训练阶段我们推荐构造一些负例以提升模型效果,在数据转换阶段我们内置了这一功能。可通过negative_ratio控制自动构造的负样本比例;负样本数量 = negative_ratio * 正样本数量。
- 对于从doccano导出的文件,默认文件中的每条数据都是经过人工正确标注的。
进行微调训练
参考文章:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie#%E8%AE%AD%E7%BB%83%E5%AE%9A%E5%88%B6
使用下面的代码进行训练
python finetune.py --device "gpu" --logging_steps 100 --save_steps 100 --eval_steps 100 --seed 42 --model_name_or_path uie-base --output_dir model/paddlepaddle/model_best --train_path data/train.txt --dev_path data/dev.txt --max_seq_length 256 --per_device_eval_batch_size 8 --per_device_train_batch_size 8 --num_train_epochs 20 --learning_rate 1e-5 --label_names "start_positions" "end_positions" --do_train --do_eval --do_export --export_model_dir model/paddlepaddle/model_best --overwrite_output_dir --metric_for_best_model eval_f1 --load_best_model_at_end True --save_total_limit 1
参数说明
- model_name_or_path:必须,进行 few shot 训练使用的预训练模型。可选择的有 “uie-base”、 “uie-medium”, “uie-mini”, “uie-micro”, “uie-nano”, “uie-m-base”, “uie-m-large”。
- multilingual:是否是跨语言模型,用 “uie-m-base”, “uie-m-large” 等模型进微调得到的模型也是多语言模型,需要设置为 True;默认为 False。
- output_dir:必须,模型训练或压缩后保存的模型目录;默认为 None 。
- device: 训练设备,可选择 ‘cpu’、‘gpu’ 、'npu’其中的一种;默认为 GPU 训练。
- per_device_train_batch_size:训练集训练过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。
- per_device_eval_batch_size:开发集评测过程批处理大小,请结合显存情况进行调整,若出现显存不足,请适当调低这一参数;默认为 32。
- learning_rate:训练最大学习率,UIE 推荐设置为 1e-5;默认值为3e-5。
- num_train_epochs: 训练轮次,使用早停法时可以选择 100;默认为10。
- logging_steps: 训练过程中日志打印的间隔 steps 数,默认100。
- save_steps: 训练过程中保存模型 checkpoint 的间隔 steps 数,默认100。
- seed:全局随机种子,默认为 42。
- weight_decay:除了所有 bias 和 LayerNorm 权重之外,应用于所有层的权重衰减数值。可选;默认为 0.0;
- do_train:是否进行微调训练,设置该参数表示进行微调训练,默认不设置。
- do_eval:是否进行评估,设置该参数表示进行评估。
正常训练开始
[2023-04-24 14:37:21,978] [ INFO] - ***** Running training *****
[2023-04-24 14:37:21,978] [ INFO] - Num examples = 282
[2023-04-24 14:37:21,978] [ INFO] - Num Epochs = 20
[2023-04-24 14:37:21,978] [ INFO] - Instantaneous batch size per device = 8
[2023-04-24 14:37:21,978] [ INFO] - Total train batch size (w. parallel, distributed & accumulation) = 8
[2023-04-24 14:37:21,978] [ INFO] - Gradient Accumulation steps = 1
[2023-04-24 14:37:21,978] [ INFO] - Total optimization steps = 720.0
[2023-04-24 14:37:21,979] [ INFO] - Total num train samples = 5640.0
[2023-04-24 14:37:21,990] [ INFO] - Number of trainable parameters = 117946370
1%|█▏ | 10/720 [00:04<05:05, 2.33it/s
2%|█▏ | 11/720 [00:05<05:04, 2.33it/s
2%|█▎ | 12/720 [00:05<05:04, 2.33it/s
2%|█▍ | 13/720 [00:05<05:03, 2.33it/s
2%|█▌ | 14/720 [00:06<05:03, 2.33it/s
正常训练结束
100%|█████████████████████████████████████████████████████████
100%|█████████████████████████████████████████████████████████ ███████████████████████| 720/720 [05:55<00:00, 2.03it/s]
[2023-04-24 14:32:25,955] [ INFO] - Saving model checkpoint to model/paddlepaddle/model_best
[2023-04-24 14:32:25,958] [ INFO] - Configuration saved in model/paddlepaddle/model_bestconfig.json
[2023-04-24 14:32:28,291] [ INFO] - tokenizer config file saved in model/paddlepaddle/model_best okenizer_config.json
[2023-04-24 14:32:28,292] [ INFO] - Special tokens file saved in model/paddlepaddle/model_bestspecial_tokens_map.json
[2023-04-24 14:32:28,294] [ INFO] - ***** train metrics *****
[2023-04-24 14:32:28,294] [ INFO] - epoch = 20.0
[2023-04-24 14:32:28,295] [ INFO] - train_loss = 0.0004
[2023-04-24 14:32:28,295] [ INFO] - train_runtime = 0:05:55.21
[2023-04-24 14:32:28,295] [ INFO] - train_samples_per_second = 15.878
[2023-04-24 14:32:28,295] [ INFO] - train_steps_per_second = 2.027
[2023-04-24 14:32:28,297] [ INFO] - ***** Running Evaluation *****
[2023-04-24 14:32:28,297] [ INFO] - Num examples = 28
[2023-04-24 14:32:28,298] [ INFO] - Total prediction steps = 4
[2023-04-24 14:32:28,298] [ INFO] - Pre device batch size = 8
[2023-04-24 14:32:28,298] [ INFO] - Total Batch size = 8
50%|██████████████████████████████████████████
100%|█████████████████████████████████████████████████████████
100%|█████████████████████████████████████████████████████████ ███████████████████████████| 4/4 [00:00<00:00, 9.79it/s]
[2023-04-24 14:32:28,997] [ INFO] - ***** eval metrics *****
[2023-04-24 14:32:28,997] [ INFO] - epoch = 20.0
[2023-04-24 14:32:28,997] [ INFO] - eval_f1 = 1.0
[2023-04-24 14:32:28,997] [ INFO] - eval_loss = 0.0003
[2023-04-24 14:32:28,997] [ INFO] - eval_precision = 1.0
[2023-04-24 14:32:28,998] [ INFO] - eval_recall = 1.0
[2023-04-24 14:32:28,998] [ INFO] - eval_runtime = 0:00:00.69
[2023-04-24 14:32:28,998] [ INFO] - eval_samples_per_second = 40.097
[2023-04-24 14:32:28,998] [ INFO] - eval_steps_per_second = 5.728
[2023-04-24 14:32:29,041] [ INFO] - Exporting inference model to model/paddlepaddle/model_bestmodel
[2023-04-24 14:32:44,238] [ INFO] - Inference model exported.
[2023-04-24 14:32:44,239] [ INFO] - tokenizer config file saved in model/paddlepaddle/model_best okenizer_config.json
[2023-04-24 14:32:44,240] [ INFO] - Special tokens file saved in model/paddlepaddle/model_bestspecial_tokens_map.json
错误记录
参考文章:https://github.com/PaddlePaddle/PaddleNLP/issues/2608
只有运行日志vdlrecords.1677479107.log,没有模型信息
这里会存在一种情况,程序运行到Number of trainable parameters = 117946370处稍微等待了一下就自动跳出,没有训练的信息反馈。同时在输出目录中,只有运行日志vdlrecords.1677479107.log,没有模型信息。
这种是由于GPU的现存不足导致程序出错的,只要调低per_device_train_batch_size ,per_device_eval_batch_size ,max_seq_length 三者的数值即可。
ps:在pytorch中跟tf中都是会弹出错误信息的。这样很好找问题。而paddle中根本不提示信息,像我这种刚开始使用的新人来说,根本不知道哪里出了问题,排查问题排查了3天。
使用微调后的模型
from pprint import pprint
from paddlenlp import Taskflow
local_path = os.path.dirname(os.path.abspath(__file__))
model_path = os.path.abspath(os.path.join(local_path, 'model/paddlepaddle/gup_success_20230424'))
# 加载模型
ie = Taskflow('information_extraction', task_path=model_path)
# 设置
schema = ['时间', '选手', '赛事名称'] # Define the schema for entity extraction
ie.set_schema(schema)
pprint(ie("2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!")) # Better print results using pprint






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结