您现在的位置是:首页 >技术教程 >Spring 循环依赖处理之三级缓存设计网站首页技术教程
Spring 循环依赖处理之三级缓存设计
一、思考
1、Spring是如何解决循环依赖问题的?
2、为什么要使用三级缓存?二级缓存能否解决问题?
3、提前暴露对象暴露的是什么?
4、主要源码
二、循环依赖
1、介绍
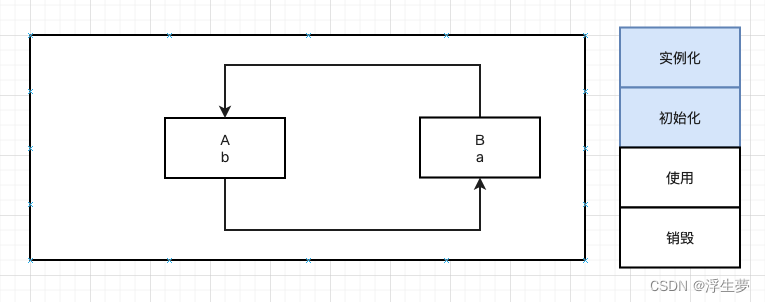
如上图,创建A之前需要先创建B,创建B之前需要先创建A,造成循环依赖。
由于A没创建完成,所以B再创建的时候再容器中获取不到A对象。
如何解决这个问题呢?
我们把创建中的对象叫半成品,创建完了的叫成本。

处于半成品状态的对象能否直接使用?不能使用。如果此时并不是暴露给外部使用,而是内部程序的调用呢?
当需要暴露给外部调用的时候,如果完成了赋值操作就不会有问题了。
如果你持有了某一个对象的引用,能否在后续步骤的时候进行赋值操作?可以。
本质是半成品状态的对象可以在中间过程中使用,实例化和初始化分开执行。
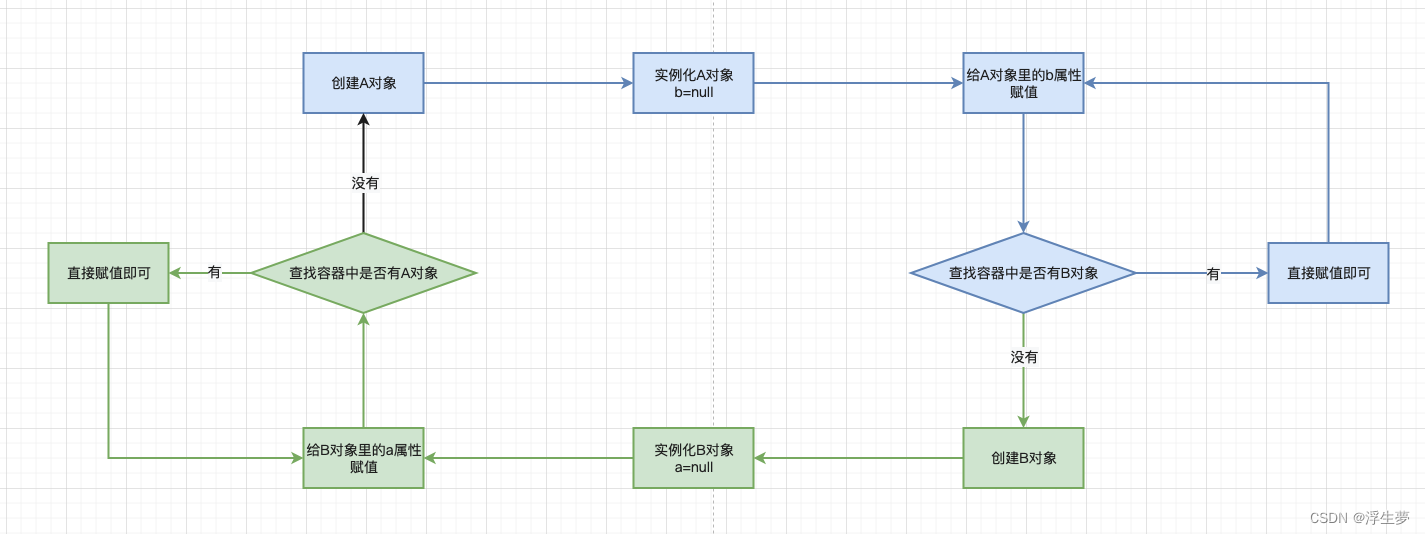
2、关键源码实现
1、创建bean

一级缓存保存BeanName 和创建bean实例之间的关系。
二级缓存保存BeanName 和创建bean实例之间的关系,与singletonFactories的不同之处在于,当一个单例bean被放到这里之后,那就可以通过getBean方法获取到,可以方便进行循环依赖的检测。
三级缓存用于保存BeanName 和创建bean的工厂之间的关系。

ObjectFactory是一个函数式接口,在java中,方法的参数在传递的时候都是值传递,也就是说必须要传入一个具体的数据值才可以,在1.8之后,可以将lambda表达式作为一个参数传递到方法中,而不必是具体的值,那么在方法定义的时候参数的类型可以是函数式接口,在具体的方法调用的时候,lambda表达式并不会立刻执行,而是在方法中调用getObject方法才会去执行。
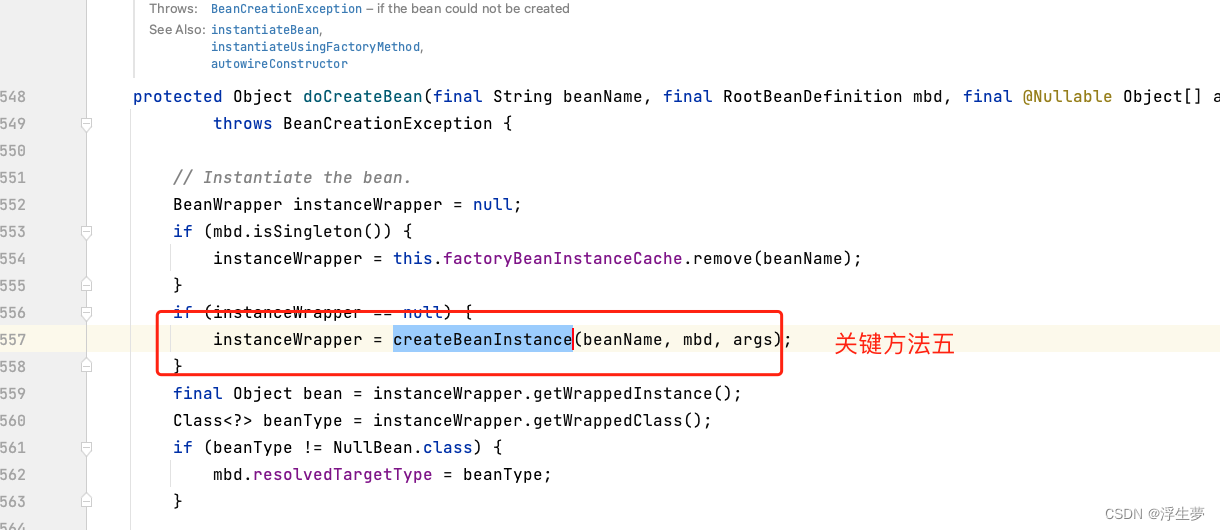
创建bean的关键方法
第五个是创建bean实例,最后一个是给bean实例赋值。

源码跟踪,从spring boot 入口跟进,进入方法有很多,我这里从spring boot 启动跟进去

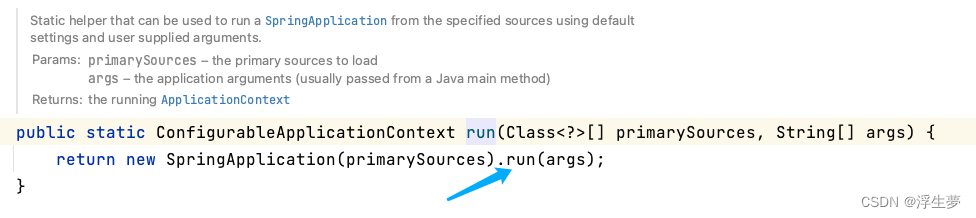




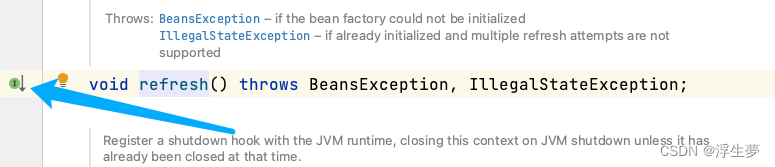
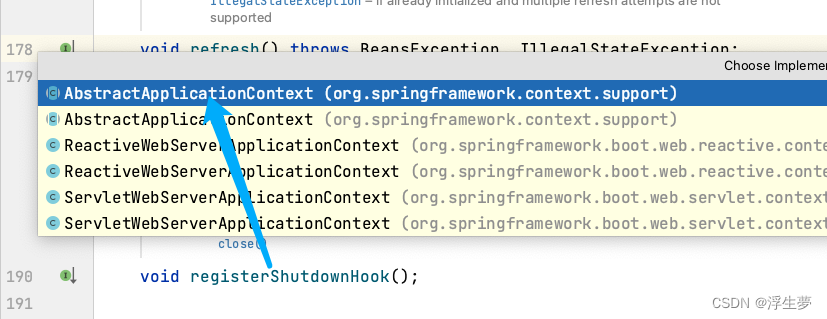
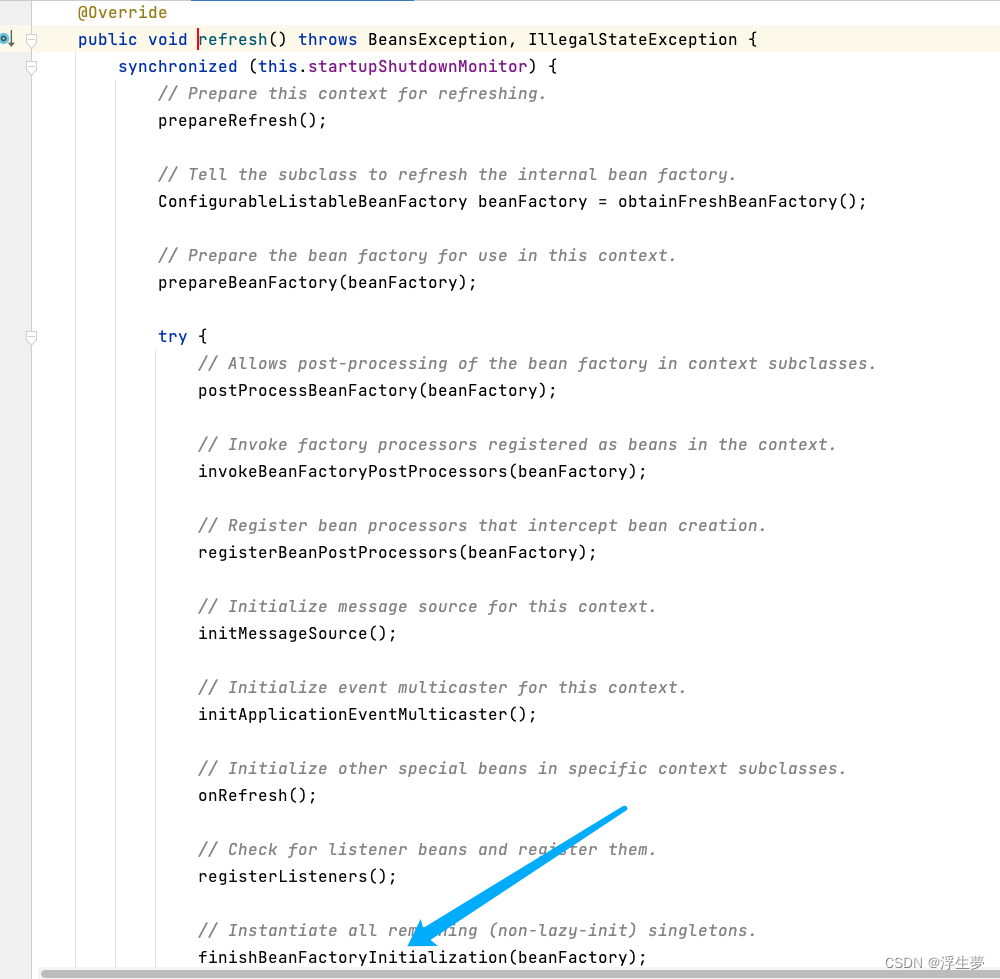

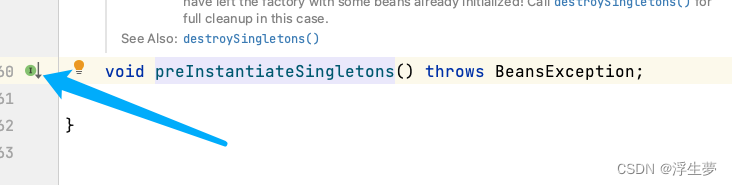

开始获取a实例
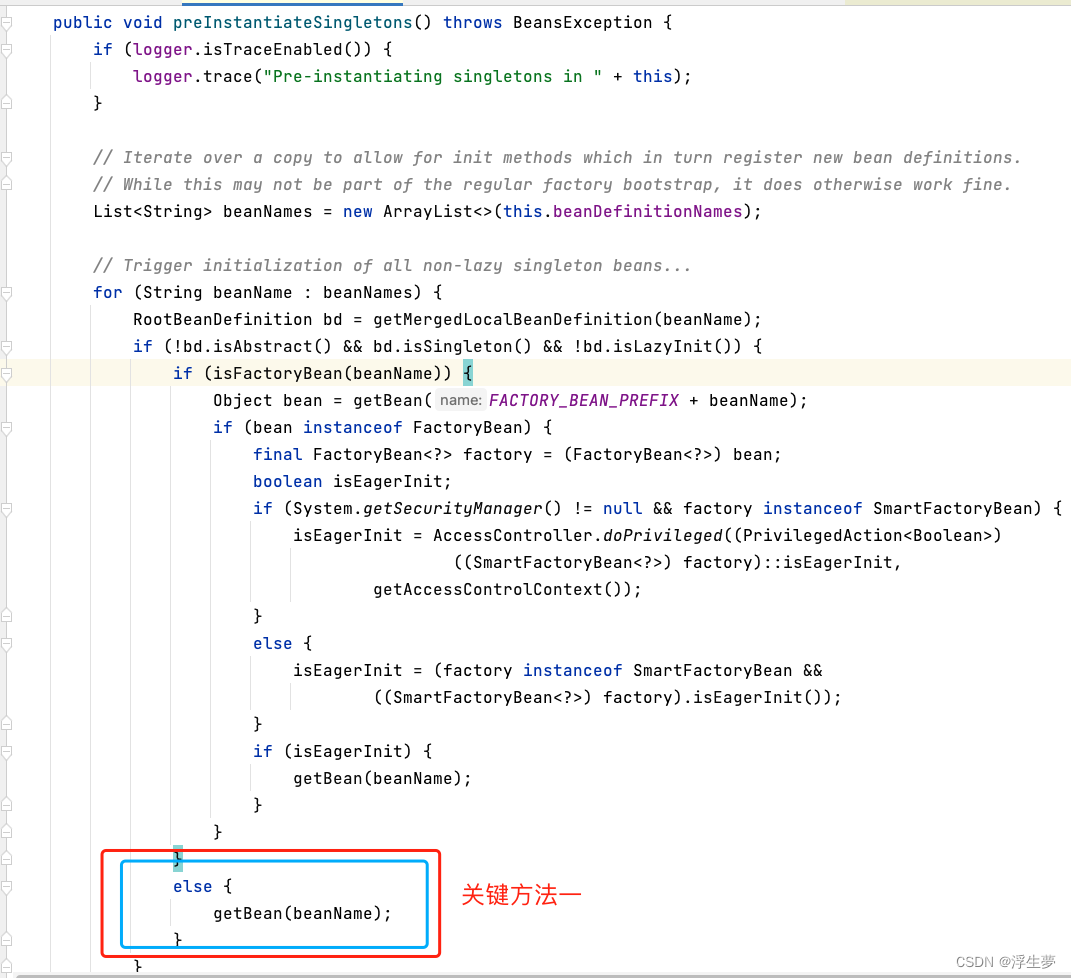

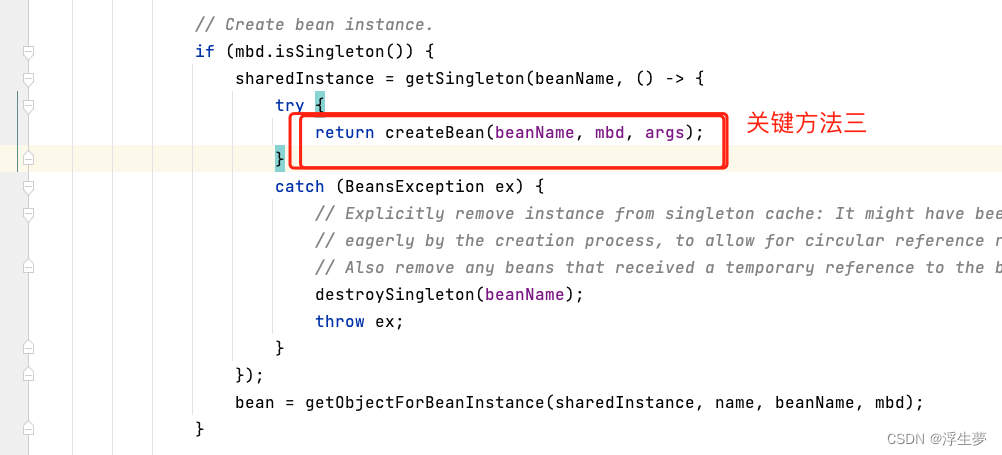


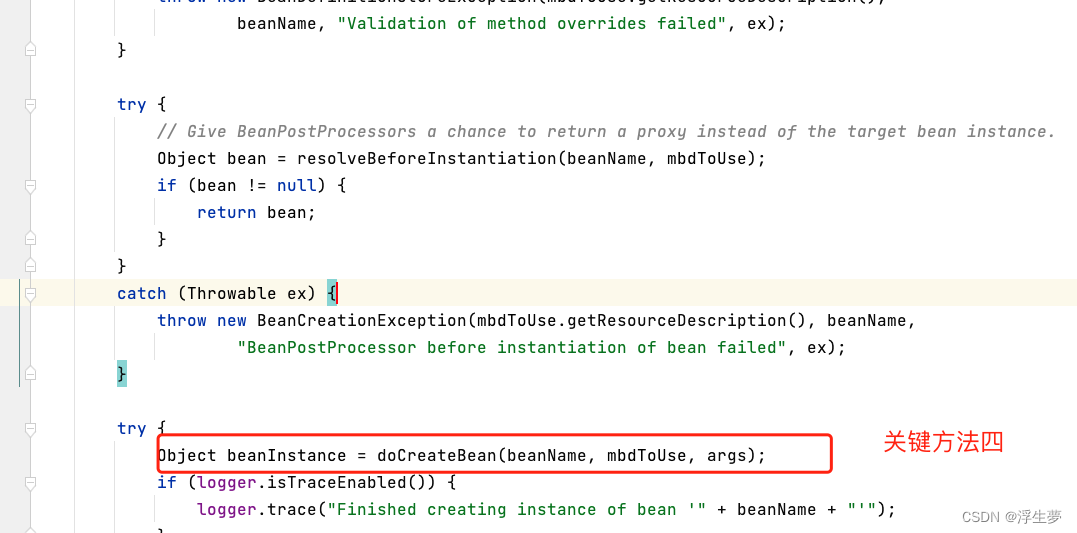
关键方法五执行完成后只是完成了a实例化,还没进行初始化,现在属于半成品,这里面开始进行a的创建
往下走找到此方法
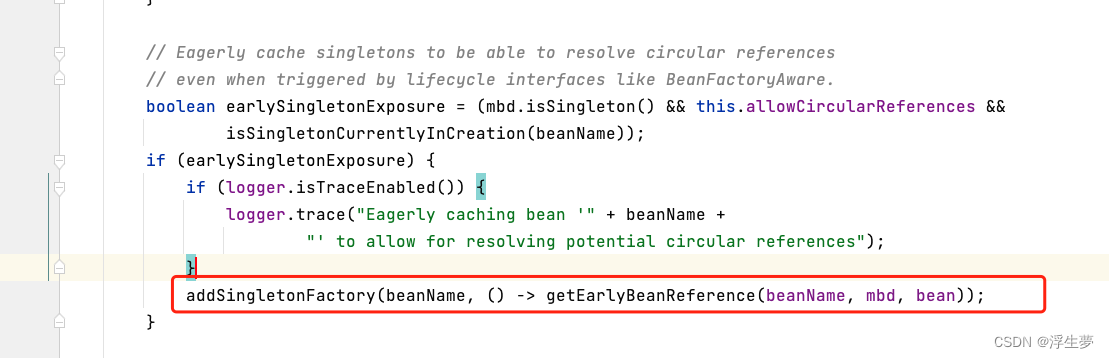
进去此方法完成后三级缓存保存了次bean,此时a再三级缓存中



2、赋值
回到上面继续往下
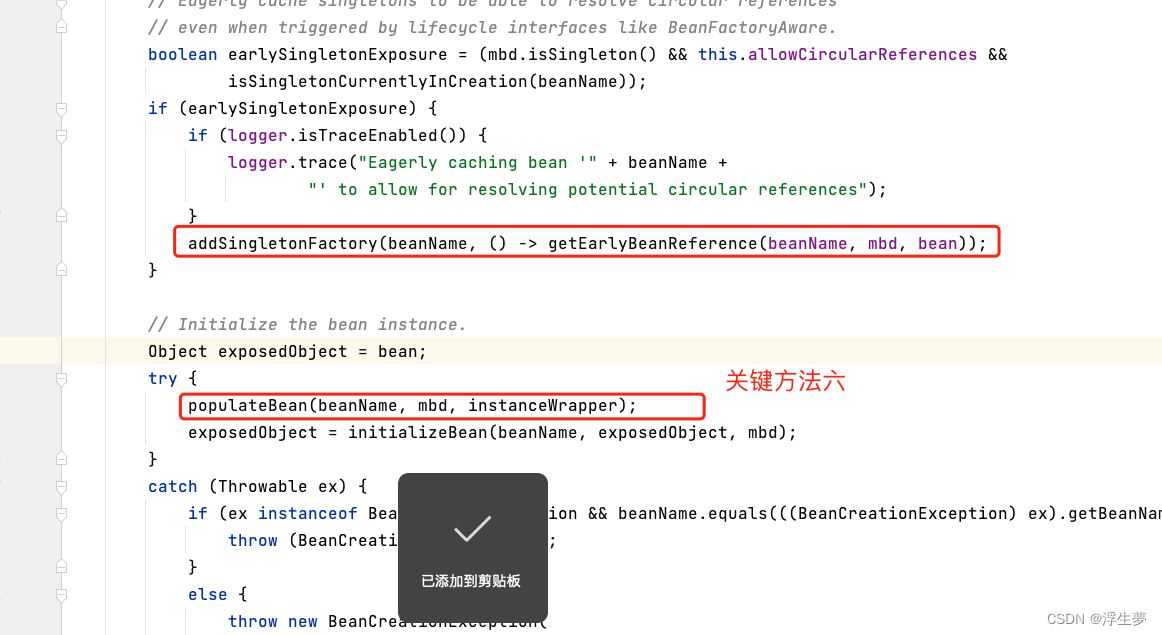
次方法内完成属性赋值(非容器内属性,容器内的 aware 是单独的)
进入populateBean方法,看最后一行
PropertyValues pvs = (mbd.hasPropertyValues() ? mbd.getPropertyValues() : null);
这里面保存b依赖的对象的kv k是b v是b对象【因为此时还没有创建b所以是默认RuntimeBeanReference】
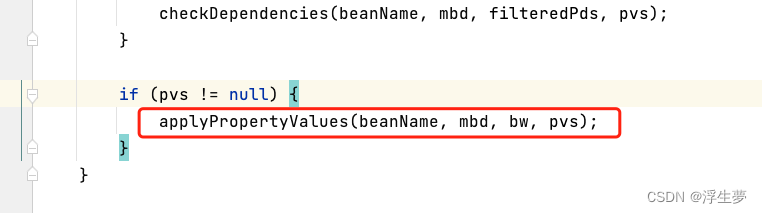
进入applyPropertyValues方法进行值处理
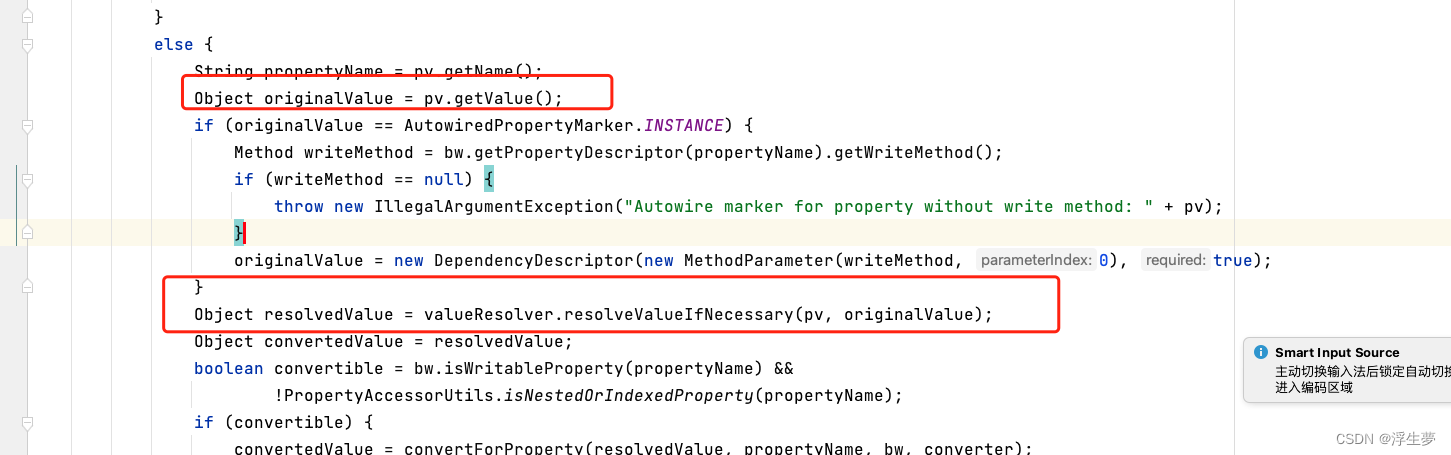
因为此时还没有b所以回尝试去构造b
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);
进入方法内 上面说到没有b默认是RuntimeBeanReference
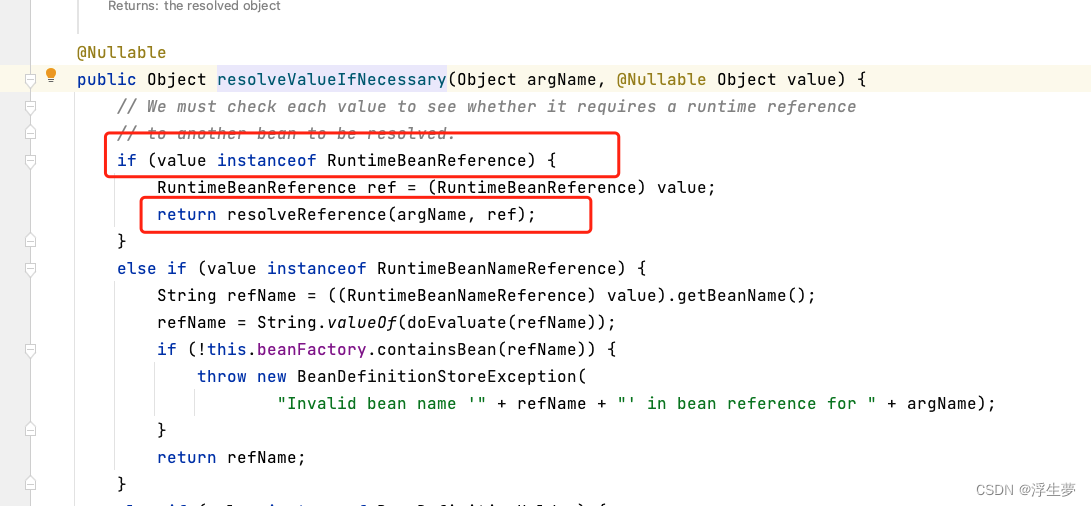
进入方法内
这是一个大递归尝试创建b
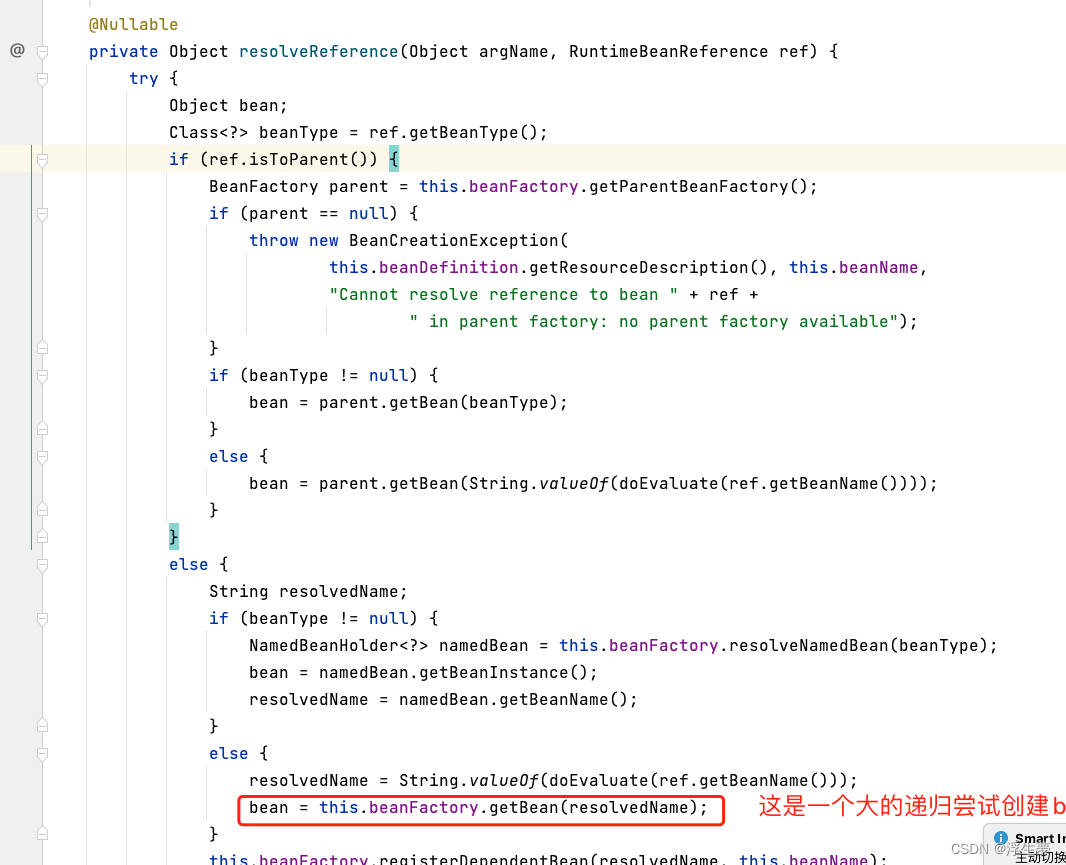
这里又会重复以上步骤,又会执行到关键方法五,不过此时创建的是b对象了,三级缓存中也会添加b进去,此时
需要注意的是这一步走到applyPropertyValues方法拿到的PropertyValues pvs 中的value 仍然是RuntimeBeanReference,
执行到最后进入
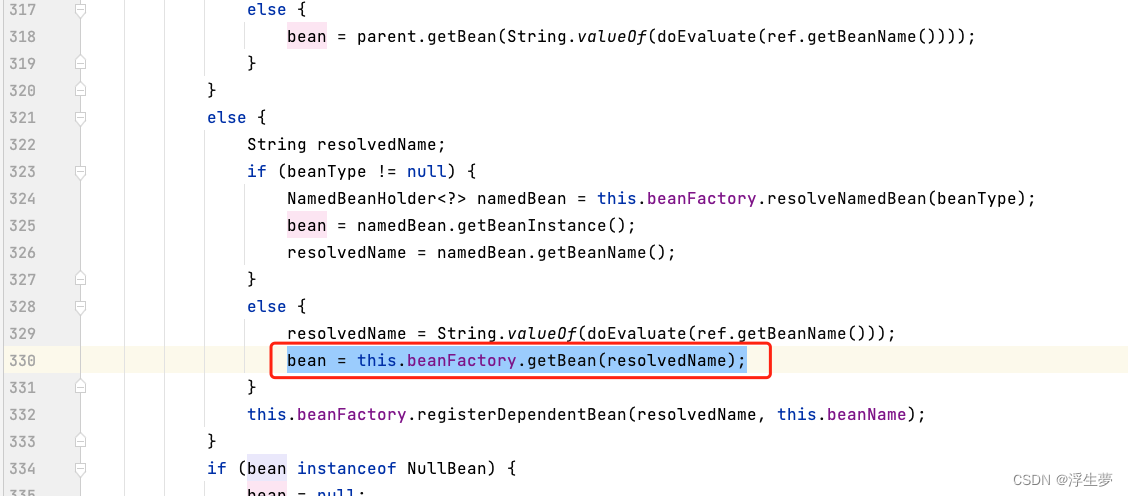
新的一轮再次开始,此时拿到的name是a(b依赖a,给b赋值的是a属性),因为此时a还在三级缓存中,在二级缓存中的半成品才会暴露出来,所以这获取不到a,再次执行到关键方法二,doGetBean();
执行到关键行
//这里会发现a已经在三级缓存中了
Object sharedInstance = getSingleton(beanName);
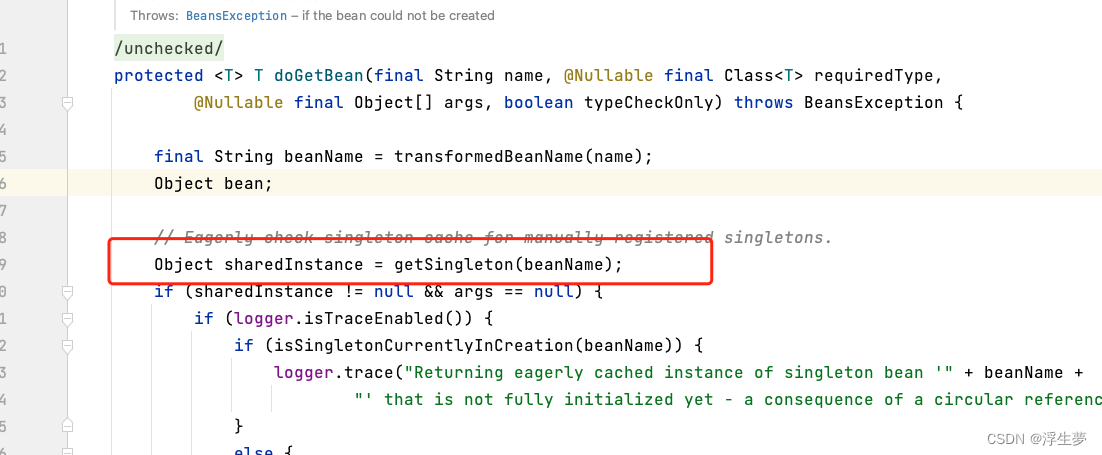
分别从一二三,三级缓存中取
此时因为三级缓存中有了
所以从三级缓存中拿出来,放进二级缓存
singletonObject = singletonFactory.getObject();
这里因为传入的是内部类的实现,调用getObject();才会进行执行

此时的情况如下
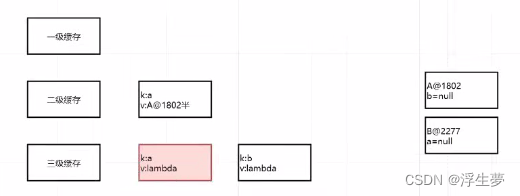
此时由于已经拿到了a对象 doGetBean 就不需要调用 createBean创建对象,
继续执行到这里,就可以直接从二级缓存中获取到a对象了
此时b获取到a对象之后,就可以进行赋值了,由于a已经存在所以这里获取到的不在是RuntimeBeanReference而是a的实例,注意此时是从二级缓存中获取到的,a属于半成品。
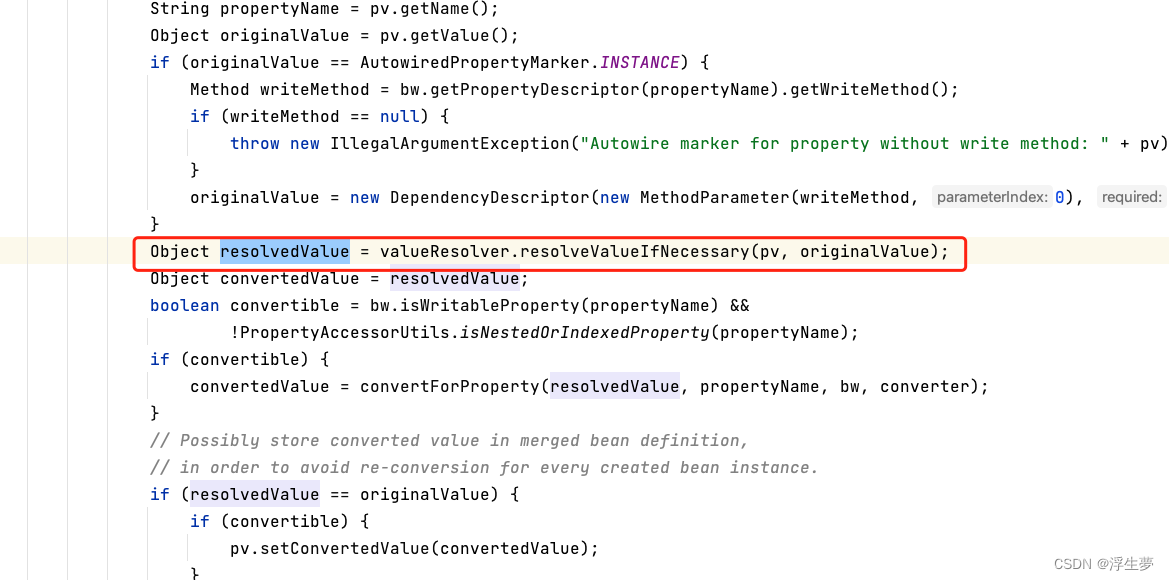
有了a对象之后就可以直接对b进行赋值了 applyPropertyValues方法中赋值
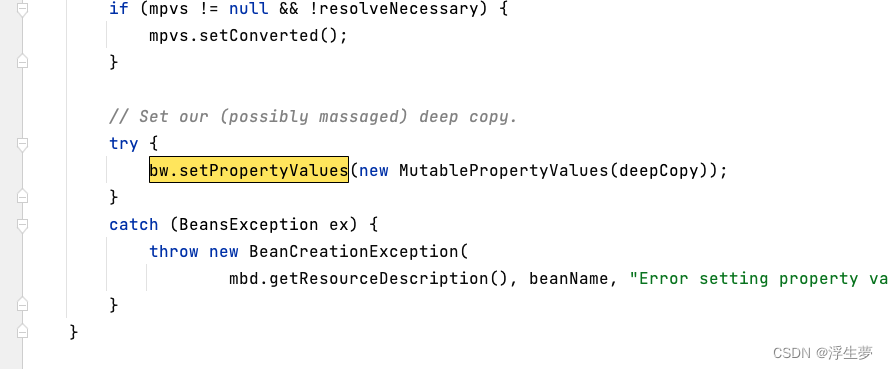
执行完成之后b里面的a属性就有值了 ,此时b是成品如下

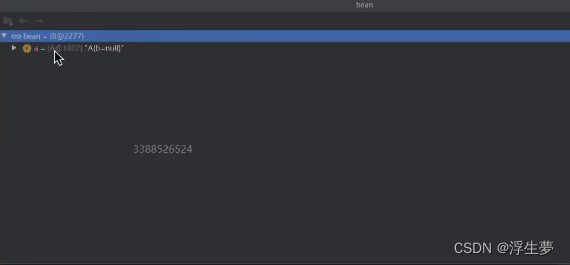
b执行完了之后,需要进行缓存再次进行缓存。因为此时b已经是成品所以直接放进一级缓存。
getSingleton
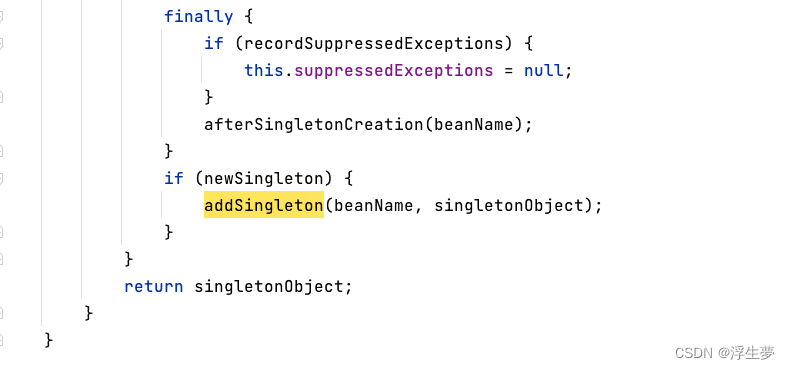
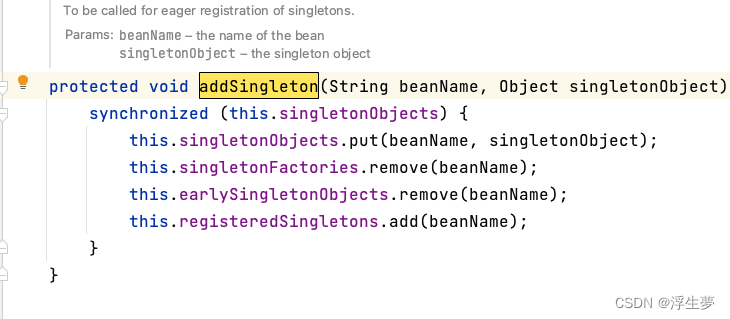
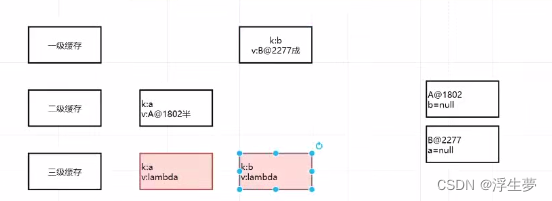
以上创建b对象的原因是为了给a对象赋值,此时b已经变成成品了。
此时给a再次赋值的时候b已经获取到了
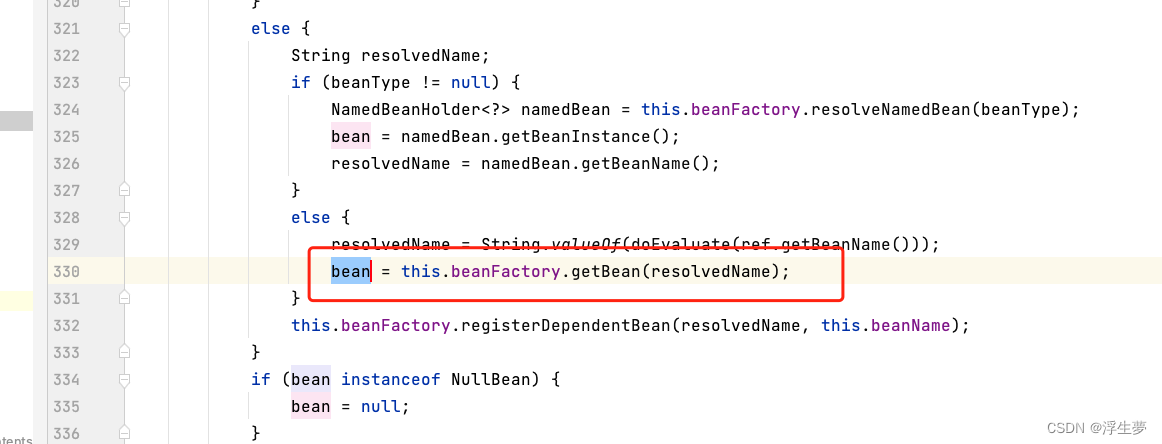
返回
此时resolveValue也有了,是一个b对象
此时就可以给a赋值了
此时 a也创建完了
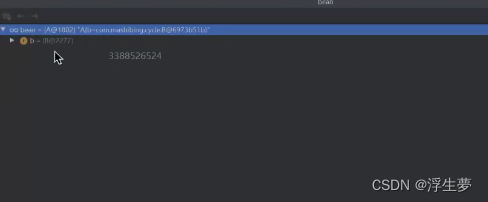
a执行完了之后,需要进行缓存再次进行缓存。因为此时a已经是成品所以直接放进一级缓存。
getSingleton
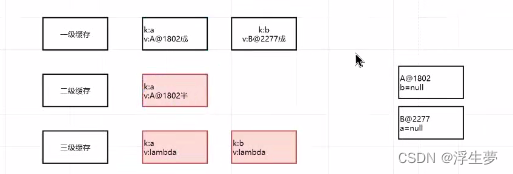
此时a和b都创建完了,但是b是被迫创建的。
再次回到这循环,上面所有的只是循环了a,此时进行b的循环,由于a循环的时候,b已经创建好了,所以本次循环很顺利的完成了。
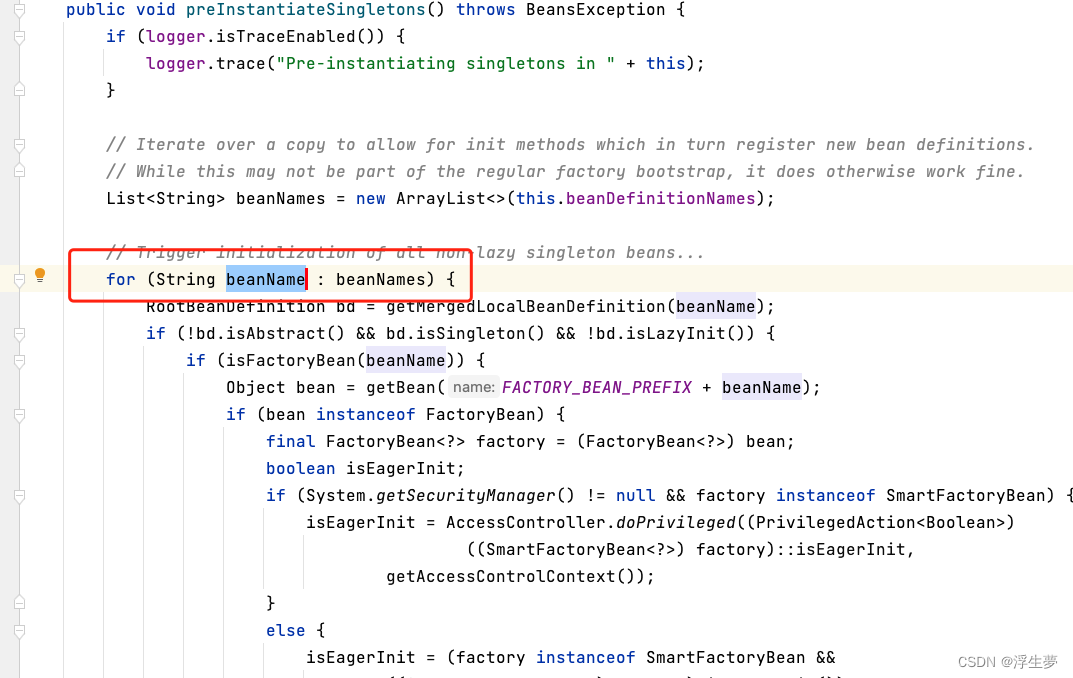
此时正式创建完成。
三、思考
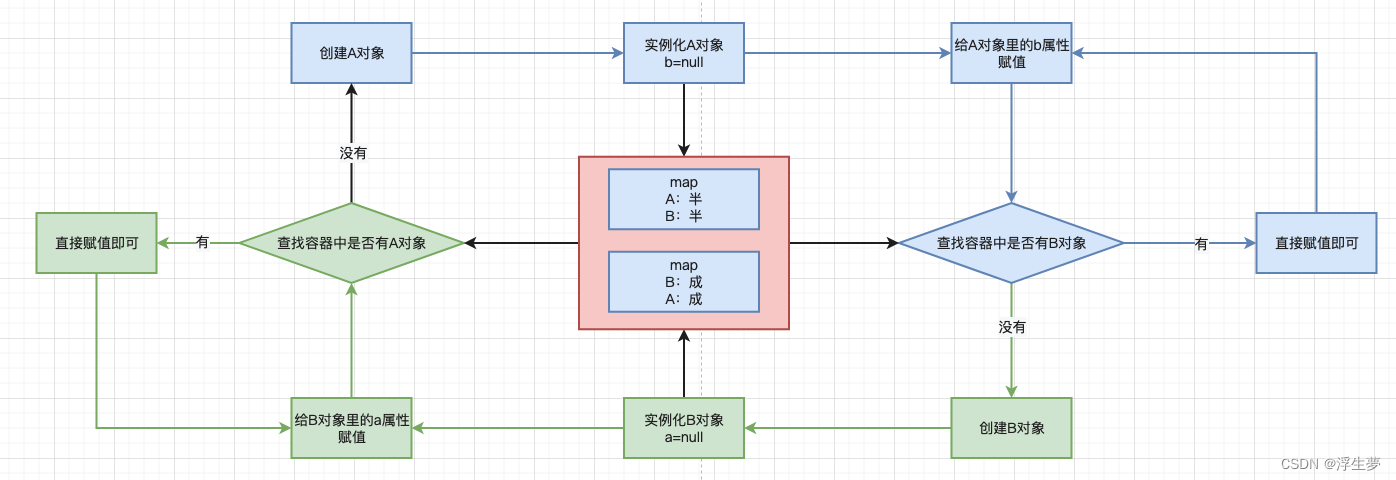
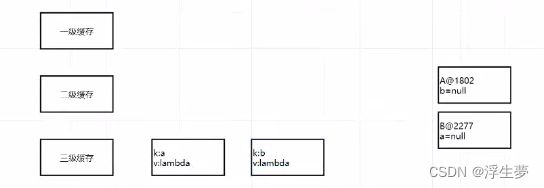
1、三个map结构分别存储什么对象
一级缓存:成品对象
二级缓存:半成品对象
三级缓存:lambda表达式
2、三个map结构在查找对象的时候顺序是什么样的?
1,2,3
3、如果只有一个map结构,能否解决循环依赖的问题?
理论上来说是可以的,但是实际操作的时候会有问题,一级缓存和二级缓存的区分点在于存储的对象类型不一样,当只有一个map的时候,就意味着成品对象和半成品对象放到了一起,半成品对象是不能够直接暴露给外部使用的,因为会有空指针的问题,所以如果非要用一个map存储就意味着要添加标识,来标注是成品对象还是本成品对象,如果按照这样的方式来设计代码,会很不优雅,所以可以直接用两个map解决这个问题,不需要一个。
4、如果只有两个map,可以解决循环依赖问题吗
可以,但是有前提条件:在对象创建过程中不能有代理对象
当存在代理对象的时候,抛出一下异常。
Exception in thread "main"org.springframework.beans.factory.BeanCurrentlylnCreationException:
Error creating bean with name 'a': Bean with name 'a' has been injected into other beans (b] in its rawversion as part of a circular reference, but has eventually been wrapped.
This means that said other beans do not use the final version of the bean.
This is often the result of over-eager type matching - consider using 'getBeanNamesForlype' with the'allowEagerInit' flag turned off for example.
线程“main”org.springframework.beans.factory.BeanCurrentlynCreateException中出现异常:
创建名为“a”的bean时出错:名为“a”的bean已作为循环引用的一部分注入到原始版本中的其他bean(b]中,但最终已被包装。
这意味着所述其他bean不使用bean的最终版本。
这通常是过度渴望类型匹配的结果——例如,考虑在关闭“allowEagleInit”标志的情况下使用“getBeanNamesForlype”。5、为什么必须要使用三级缓存来解决循环依赖问题?为什么三级缓存可以解决带有代理对象的循环依赖问题?
1,同一个容器中,能否出现同名的不同对象?
不能
2,如果出现了同名的不同对象,应该怎么办?刚开始创建出原始对象,后续创建出了代理对象
如果在创建过程中出现了同名的不同对象,那么后面创建的对象要覆盖前面创建的对象
在这里会被覆盖
3,那么为什么要使用lambda表达式这样的方式,为什么要加入三级缓存呢?
对象的属性赋值是在哪个方法里完成的?populateBean方法
代理对象的创建是在哪个方法里完成的?BeanPostProcessor的后置处理方法里完成的
他们两个方法谁先执行,谁后执行呢?先执行populateBean,然后执行后置处理方法
也就是说,在进行对象的属性赋值的时候,代理对象还没有创建出来,那么属性的赋值只能赋原始对象,而在后续的步骤中又创建出了代理对象,此时的代理对象会有赋值的过程吗?不会,所以会出现一个错误
this means that said other beans do not use the final version of the bean
就是说赋值是原始对象,而最终留下来的是代理对象,所以导致没有使用最终版本的bean对象
如何解决?
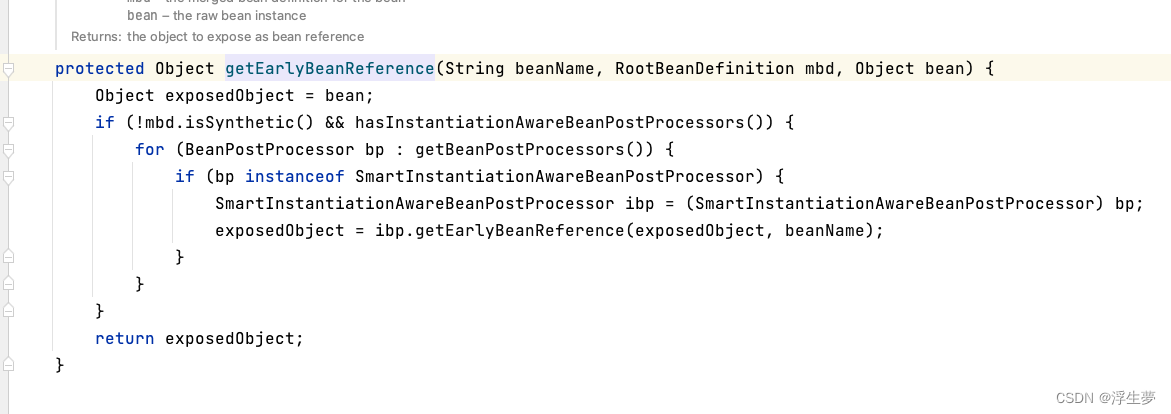
将代理对象的创建过程提前执行,也就是说在进行对象赋值的时候,必须要唯一性的确定出到底是原始对象还是代理对象,这个方法是在getEarlyBeanReference方法里执行的,是在populateBean方法的调用逻辑里操作的
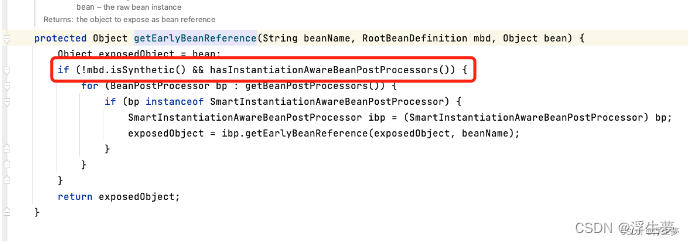
为什么要使用lambda表达式?
lambda表达式相当于是延迟执行,因为此方法并不会在方法调用的时候立刻执行,而是在对象必须要进行赋值的那一刻执行,也就是说在对象赋值的前一刻确定出了最终版本的bean对象。 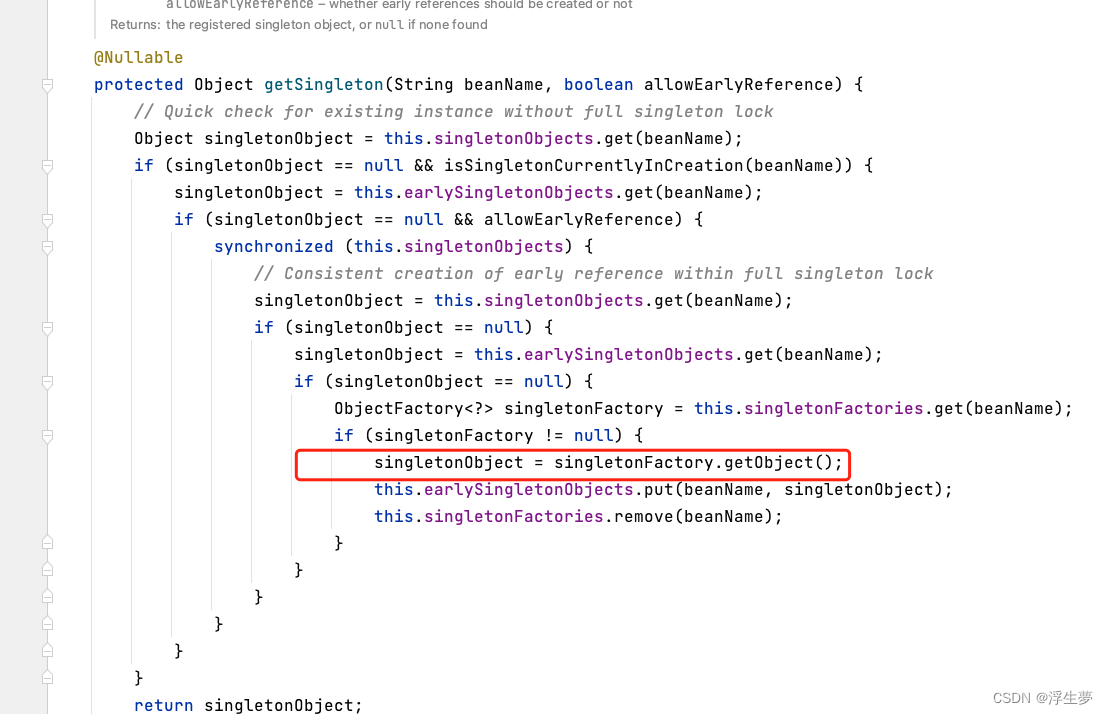






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结