您现在的位置是:首页 >技术杂谈 >【大数据之Hadoop】十八、MapReduce之压缩网站首页技术杂谈
【大数据之Hadoop】十八、MapReduce之压缩
简介【大数据之Hadoop】十八、MapReduce之压缩
1 概述
优点:减少磁盘IO、减少磁盘存储空间。
缺点:因为压缩解压缩都需要cpu处理,所以增加CPU开销。
原则:运算密集型的Job,少用压缩;IO密集型的Job,多用压缩。
2 压缩算法对比
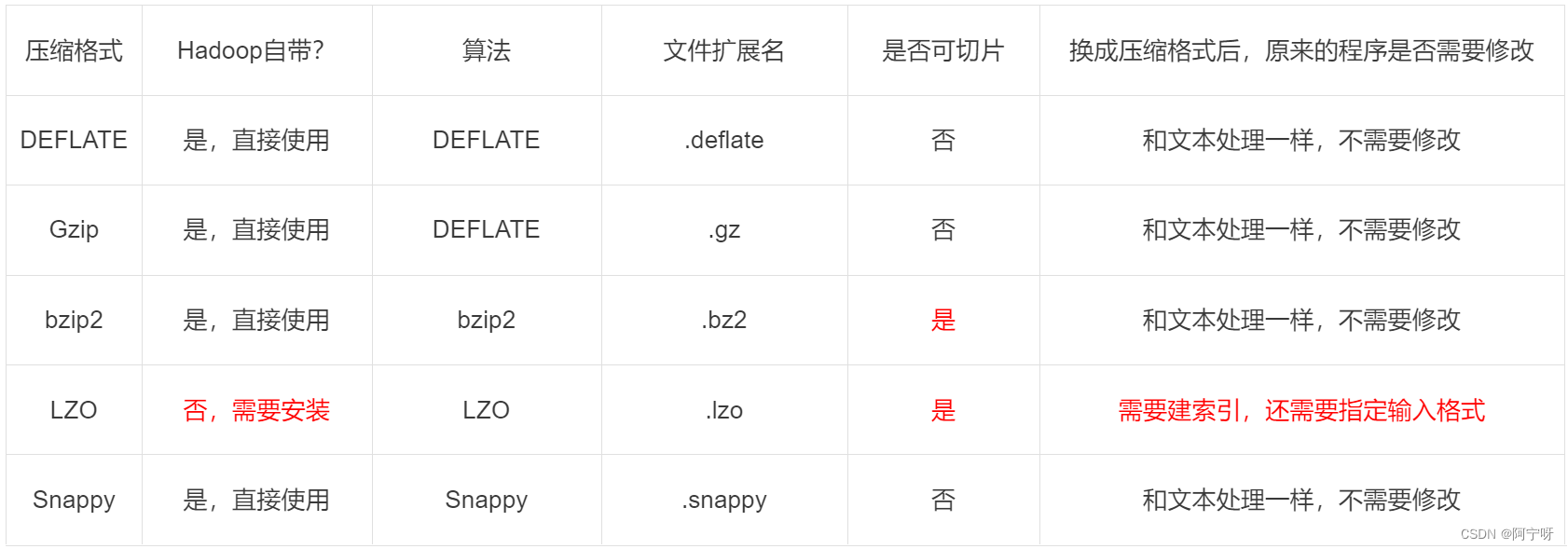
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否可以支持切片。
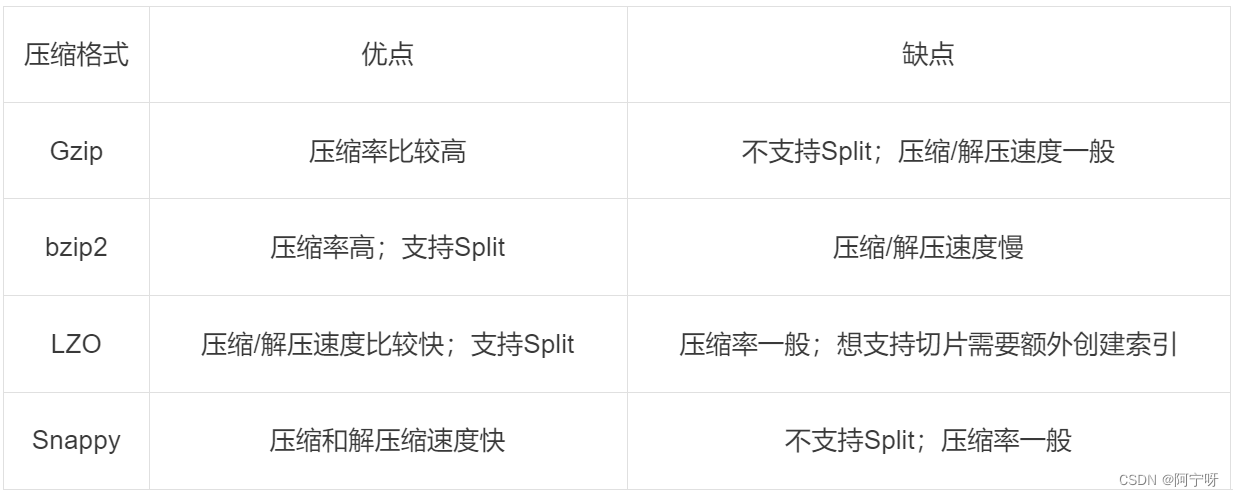
3 压缩位置选择

在集群中使用压缩需要进行配置:

4 压缩例子
4.1 Map端输出采用压缩
对Map任务的中间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,所以对其压缩可以提高性能。
Mapper和Reducer不变,只需要修改Driver端。
package.com.study.mapreduce.compress;
importjava.io.IOException;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.io.compress.BZip2Codec;
importorg.apache.hadoop.io.compress.CompressionCodec;
importorg.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public classWordCountDriver {
public static void main(String[] args)throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = newConfiguration();
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress",true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec",BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, newPath("D:\wordcountinput"));
FileOutputFormat.setOutputPath(job, newPath("D:\wordcountoutput"));
boolean result =job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
此时reduce最终输出的结果并没有压缩。原因:map传输给reduce进行了压缩,但到达reduce时进行了解压缩处理,最终输出的文件是由reduce控制的。
4.2 Reduce端输出采用压缩
Mapper和Reducer不变,只需要修改Driver端。
package.com.study.mapreduce.compress;
importjava.io.IOException;
importorg.apache.hadoop.conf.Configuration;
importorg.apache.hadoop.fs.Path;
importorg.apache.hadoop.io.IntWritable;
importorg.apache.hadoop.io.Text;
importorg.apache.hadoop.io.compress.BZip2Codec;
importorg.apache.hadoop.io.compress.DefaultCodec;
importorg.apache.hadoop.io.compress.GzipCodec;
importorg.apache.hadoop.io.compress.Lz4Codec;
importorg.apache.hadoop.io.compress.SnappyCodec;
importorg.apache.hadoop.mapreduce.Job;
importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;
importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public classWordCountDriver {
public static void main(String[] args)throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = newConfiguration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, newPath("D:\wordcountinput"));
FileOutputFormat.setOutputPath(job, newPath("D:\wordcountoutput"));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job,true);
//设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
// FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
// FileOutputFormat.setOutputCompressorClass(job, DefaultCodec.class);
boolean result =job.waitForCompletion(true);
System.exit(result?0:1);
}
}
Map端输出什么压缩格式不会影响Reduce端的最终输出格式,在Reduce端设置压缩,最终结果输出压缩文件。
风语者!平时喜欢研究各种技术,目前在从事后端开发工作,热爱生活、热爱工作。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结