您现在的位置是:首页 >学无止境 >代码随想录算法训练营第六天|242.有效的字母异位词 349. 两个数组的交集 202. 快乐数 1. 两数之和网站首页学无止境
代码随想录算法训练营第六天|242.有效的字母异位词 349. 两个数组的交集 202. 快乐数 1. 两数之和
先了解一下什么是哈希表
哈希表是根据关键码的值而直接进行访问的数据结构
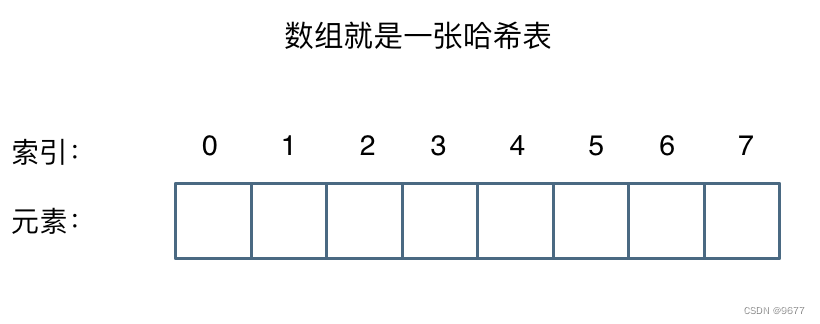
所以数组就是哈希表
盗个卡哥的图
哈希表中关键码就是数组的索引下标,然后通过下标直接访问数组中的元素,如下图所示:
哈希表能解决的问题:
一般哈希表都是用来快速判断一个元素是否出现集合里。
如果要查询一个名字是否在这所学校里,要枚举的话时间复杂度是O(n),但如果使用哈希表的话, 只需要O(1)就可以做到。
实际上我连枚举都没咋用过。。。
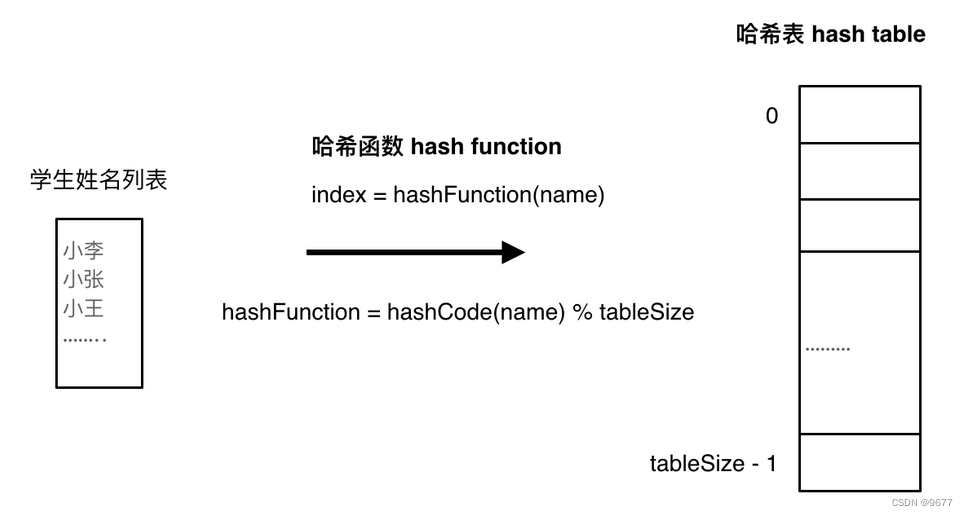
将学生姓名映射到哈希表上就涉及到了hash function ,也就是哈希函数。
哈希函数如下图所示,通过hashCode把名字转化为数值,一般hashcode是通过特定编码方式,可以将其他数据格式转化为不同的数值,这样就把学生名字映射为哈希表上的索引数字了。
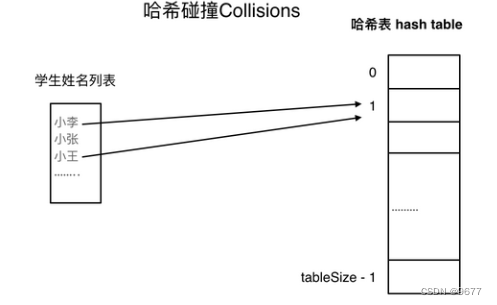
哈希碰撞 数据结构上叫冲突
如果学生的数量大于哈希表的大小怎么办,此时就算哈希函数计算的再均匀,也避免不了会有几位学生的名字同时映射到哈希表 同一个索引下标的位置。
可以用拉链法和线性探测法解决
拉链法,就是在冲突的位置加个链表
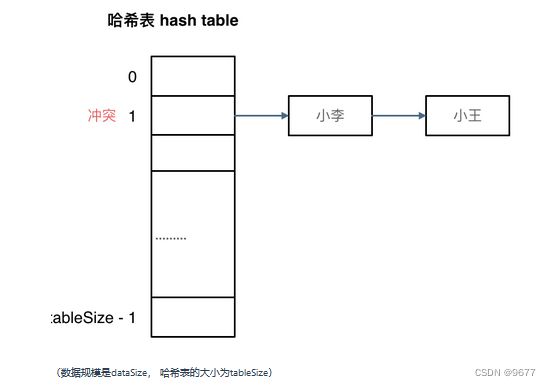 其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间
其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间
而使用线性探测法就是需要有足够的表空间,来存放那些数据
常用的三种哈希结构
数组,
set
map
题目链接
异位词的判断
判断两个字符串组成的字母是否相同,每个字母出现的次数是否一样,但位置可以不一样
比较好的暴力思维
第一种:先排序,用sort函数,然后再逐一对比,这就可以达到O(nlogn)了.
class Solution {
public:
bool isAnagram(string s, string t) {
//暴力解法
//检验所给字符串的长度是否一致,这条你在考试的时候想不到也没事
if(s.size()!=t.size())return false;
//先排序
sort(s.begin(),s.end());
sort(t.begin(),t.end());
for(int i=0;i<=s.size();i++){
if(s[i]!=t[i])return false;
}return true;
}
};
第二种暴力思路,我也不知道这叫啥,枚举?
自己还没学过枚举…
就是建立两个数组,用来记录每个字符串中26个字母里的每个字母的出现次数,就是两个循环.最后再注意对比这两个数组的次数,感觉也是从无序到有序
class Solution {
public:
bool isAnagram(string s, string t) {
//暴力解法2
//检验所给字符串的长度是否一致,这条你在考试的时候想不到也没事
if(s.size()!=t.size())return false;
//先建立两个数组
vector <int> ss(26,0);//容器咋建数组又忘了
vector <int> tt(26,0);
//从头遍历字符串,统计每个字母出现的次数
for(int i=0;i<s.size();i++){
//ASCII码里,先是大写字母,然后是小写字母
ss[s[i]-'a']++;
tt[t[i]-'a']++;
}
for(int i=0;i<ss.size();i++){
if(ss[i]!=tt[i])return false;
}return true;
}
};
有点牺牲空间换时间的意思但是这里的数组是固定的26,不随着字符串的长度儿变化,时间复杂度O(n)。空间复杂度O(1)
要记住时间复杂度不是开辟的空间大小比n大就是O(n)了而是与输入规模n有关的是O(n)否则是个无关常量不管大小为多少都为O(1)
总结这两种暴力思路我认为都是讲字符串先排好队(无序到有序)然后再进行比较
然后就是哈希的方法
看了看,跟第二个暴力也差不多少啊。。。。
就是处理方法不是比对相等,而是比对数组里的元素是否为0
这算是用数组下标来访问数组的元素,我想关键字是字符串的字符的值吧。
把字符映射到数组也就是哈希表的索引下标上
class Solution {
public:
bool isAnagram(string s, string t) {
if(s.size()!=t.size())return false;
vector<int>record(26,0);
for(int i=0;i<s.size();i++){
record[s[i]-'a']++;
record[t[i]-'a']--;
}
for(int i=0;i<record.size();i++){
if(record[i]!=0)return false;
}return true;
}
};
用了上面之前的暴力思想,把第一个数组可能出现的值放在统计数字出现次数的数组里,然后在第二个数组里检验,如果第二个数组中出现的数字在第一个数组里也出现了,那么这个数字就存在与交集, 但要特别注意的是要避免重复,两个数组都会有重复的数字,而在统计 交集的时候重复只能算一个,所以赋值只能是1,在比对第二个数组的时候,遇到了相同的数字就得改变其在记录数组的值,以免重复记录。
这个代码里用到了C++的容器的push_back()函数,将某数或某元素插入到数组末尾。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
//自己的想法就是还是用一个1001个数的数组来记录两个数组的里的值
//有点哈希的思想
vector<int> record(1001,0);
vector<int> result;
for(int i=0;i<nums1.size();i++){
record[nums1[i]]=1;
}
for(int i=0;i<nums2.size();i++){
if(record[nums2[i]]==1)
//别忘了nums2里也会有重复的元素
{ record[nums2[i]]=2;
result.push_back(nums2[i]);}
}return result;
}
};
哈希:容器不能再选数组了
而且如果哈希值比较少、特别分散、跨度非常大,使用数组就造成空间的极大浪费
此时就要使用另一种结构体了,set ,关于set,C++ 给提供了如下三种可用的数据结构:
std::set 元素不能重复 有序集合
std::multiset 有序多重集合 元素可以重复
std::unordered_set 无序非重复集合 查找比set更快
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set。
本题交集结果不用考虑顺序
unordered_set 是 C++ 中的一个容器,它是哈希表的一种实现。与 set 相比,unordered_set 具有更快的查找速度,但是对于元素的顺序没有保证。unordered_set 中的元素是无序的,而且不能有重复的元素。
unordered_set 支持以下操作:
- 插入元素:
insert(key); - 删除元素:
erase(key); - 查找元素:
find(key),如果元素存在,则返回元素的迭代器,否则返回unordered_set::end(); - 判断元素是否存在:
count(key),如果元素存在,则返回 1,否则返回 0; - 清空容器:
clear(); - 获取容器大小:
size(); - 判断容器是否为空:
empty()。
unordered_set 的底层实现是哈希表,因此插入、删除和查找元素的时间复杂度都是常数级别的 O(1),但是需要注意的是,如果哈希表出现冲突,这些操作的时间复杂度可能会退化为 O(n),其中 n 是哈希表中元素的个数。
给第一个数组的元素放入unordered_set里去重,
然后用第二个里的每个值与unordered_set 里的进行对比,如果这个值
if (nums_set.find(num) != nums_set.end()) //这个啥意思啊
这段代码用来判断 nums2 中的元素是否在 nums1 中出现过,具体实现是通过在 nums_set 中查找是否存在该元素来判断。unordered_set 的 find 方法会返回指向存储该元素位置的迭代器,如果元素不存在,会返回一个指向 unordered_set 结尾的迭代器 end(),因此 nums_set.find(num) != nums_set.end() 的意思是:在 nums_set 中查找 num 元素,如果返回的迭代器不等于 end(),说明 num 存在于 nums_set 中,也就是 nums1 中出现过。
for (int num : nums2)这个啥意思啊
这是C++11中的一种for循环语法,称为range-based for循环,也叫foreach循环,它可以用来遍历一个容器(如数组、vector等)中的所有元素。在这个例子中,nums2是一个容器(可能是数组或vector等),for循环会依次取出其中的每一个元素,赋值给变量num。直接把数组里的值取出来赋给num了,而不是下标了。因此,这行代码的意思是依次取出nums2中的每一个元素,对于每一个元素,执行循环体中的语句。
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int>res;
unordered_set<int>num(nums1.begin(),nums1.end());
for(int i:nums2){
if(num.find(i)!=num.end())
res.insert(i);
}return vector<int>(res.begin(),res.end());
}
};
题目链接
主要是有一个数学上的问题,就是他这个会不会无限循环到无穷大
要从最大m位数即每位都是9,那么三位数就是243,4位是81*4.。。。。
这个会进入一个循环
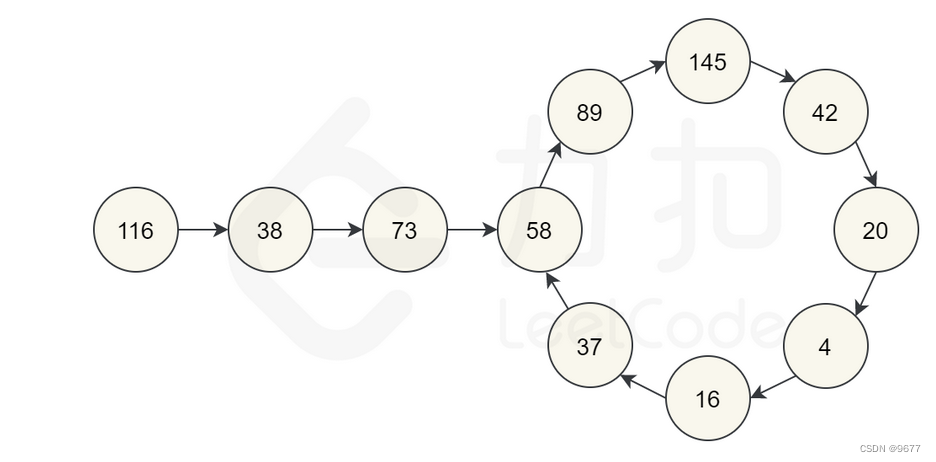 进入循环的就会出不去,这时我们选择用set来收集这些值,若有重复的就说明这个数不是快乐数,应该返回false
进入循环的就会出不去,这时我们选择用set来收集这些值,若有重复的就说明这个数不是快乐数,应该返回false
class Solution {
public:
//如何一个多位数的各位之和
//得用%求各位数的余数
int getsum(int n){
int sum=0;
while(n){
sum+=(n%10)*(n%10);
n/=10;
}return sum;
}
bool isHappy(int n) {
set<int>num;
int m=getsum(n);
while(m!=1){
if(num.find(m)!=num.end())//判断这个数在没在集合里
return false;
else {num.insert(m);
m=getsum(m);//算新求的和的各位数的平方和,一直循环下去
}
}return true;
}
};
题目链接
给你一个数,让你从数组里找出来两个数的和等于所给的这个数
1.这个数组是无序的,数组里允许有重复的值
如果有序还可以用这个前后指针,并且判断和的大小来决定移动哪个指针
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
//sort(nums.begin(),nums.end());
int i=0,j=nums.size()-1;
while(i<j){
if(nums[i]+nums[j]==target)
return {i,j};
else if(nums[i]+nums[j]<target)
i++;
else j--;
}return {i,j};
}
};
无序的话用暴力就只能双重for循环了,这个题不包括用数组里的一个数加两次的情况
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int i,j;
for( i=0;i<nums.size()-1;i++)
for(int j=i+1;j<nums.size();j++)
if(nums[i]+nums[j]==target)return {i,j};
return {i,j};//不return 两次不通过啊,不知道为啥
}
};
时间复杂度O(n^2)
空间复杂度O(1)
1.为什么会想到用哈希表
2.哈希表为什么用map
3.本题map是用来存什么的
4.map中的key和value用来存什么的
当需要查询一个元素是否出现过,或者一个元素是否在集合里的时候
需要用一个集合来存放遍历过的元素,然后在遍历数组的时候去询问这个集合,某元素是否遍历过,也就是 是否出现在这个集合。
key来存元素,value来存下标,那么使用map正合适
map是键值对,一个量保存下标,一个变量保存值
map也和set似的有三种类型
unordered_map为无序的,
所以哈希表的应用在容器里有三种,数组,set,map
map的一些基本用法
map{key 数据元素,value 值(数组元素对应的下标)}
map会自动按键值(key )大括号中的第一部分来排列顺序
其中key用迭代器->first
value 用迭代器->second
C++ STL之映射map的使⽤
map 是键值对,⽐如⼀个⼈名对应⼀个学号,就可以定义⼀个字符串string 类型的⼈名为“键”,学
号int 类型为“值”,如map<string, int> m;
按照数组来说(前面是数组里的元素,下面是数组里的下标)
当然键、值也可以是其它变量类型~
map 会⾃动将所有的键值对按照键从⼩到⼤排序,
map 使⽤时的头⽂件#include <map> 以下是map 中常⽤的⽅法:
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main() {
map<string, int> m; // 定义⼀个空的map m,键是string类型的,值是int类型的
m["hello"] = 2; // 将key为"hello", value为2的键值对(key-value)存⼊map中
cout << m["hello"] << endl; // 访问map中key为"hello"的value, 如果key不存在,则返回0
cout << m["world"] << endl;
m["world"] = 3; // 将"world"键对应的值修改为3
m[","] = 1; // 设⽴⼀组键值对,键为"," 值为1
// ⽤迭代器遍历,输出map中所有的元素,键⽤it->first获取,值⽤it->second获取
for (auto it = m.begin(); it != m.end(); it++) {
cout << it->first << " " << it->second << endl;
}
// 访问map的第⼀个元素,输出它的键和值
cout << m.begin()->first << " " << m.begin()->second << endl;
// 访问map的最后⼀个元素,输出它的键和值
cout << m.rbegin()->first << " " << m.rbegin()->second << endl;
通俗的来讲整个做法就是每从数组里遍历一个数,就看看map里有没有能与之加一起为target的数。
pair<int, int>(nums[i], i):键值对,用pair来表示。<int,int>可以省略
pair是STL库提供的一个模板类,用于将两个值组合在一起,即一个键值对。
其中,pair<int, int>表示键值对中键和值的数据类型都是int,(nums[i], i)表示具体的键值对,
即nums[i]为键,i为值。
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int>map;
for(int i=0;i<nums.size();i++){
auto it=map.find(target-nums[i]);//迭代器,我就把它当成指针。。。
if(it!=map.end()){//返回值,就是位置。
return {it->second,i};
}else map.insert(pair(nums[i],i));
}
return{};
}
};






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结