您现在的位置是:首页 >技术教程 >C++20协程Coroutine网站首页技术教程
C++20协程Coroutine
1. 学习之路
先看这两篇文章,讲的很好,可以把协程的调用逻辑给理清楚。
上述的两篇文章没有关于 co_yield 的例子,可以结合下边这个代码搞清楚 co_yield 是如何使用的:
#include <coroutine>
#include <iostream>
#include <stdexcept>
#include <thread>
//!coro_ret 协程函数的返回值,内部定义promise_type,承诺对象
template <typename T>
struct coro_ret
{
struct promise_type;
using handle_type = std::coroutine_handle<promise_type>;
//! 协程句柄
handle_type coro_handle_;
coro_ret(handle_type h)
: coro_handle_(h)
{
}
coro_ret(const coro_ret&) = delete;
coro_ret(coro_ret&& s)
: coro_handle_(s.coro_)
{
s.coro_handle_ = nullptr;
}
~coro_ret()
{
//!自行销毁
if (coro_handle_)
coro_handle_.destroy();
}
coro_ret& operator=(const coro_ret&) = delete;
coro_ret& operator=(coro_ret&& s)
{
coro_handle_ = s.coro_handle_;
s.coro_handle_ = nullptr;
return *this;
}
//!恢复协程,返回是否结束
bool move_next()
{
coro_handle_.resume();
return coro_handle_.done();
}
//!通过promise获取数据,返回值
T get()
{
return coro_handle_.promise().return_data_;
}
//!promise_type就是承诺对象,承诺对象用于协程内外交流
struct promise_type
{
promise_type() = default;
~promise_type() = default;
//!生成协程返回值
auto get_return_object()
{
return coro_ret<T>{handle_type::from_promise(*this)};
}
//! 注意这个函数,返回的就是awaiter
//! 如果返回std::suspend_never{},就不挂起,
//! 返回std::suspend_always{} 挂起
//! 当然你也可以返回其它awaiter
auto initial_suspend()
{
//return std::suspend_never{};
return std::suspend_always{};
}
//!co_return 后这个函数会被调用
void return_value(T v)
{
return_data_ = v;
return;
}
//!
auto yield_value(T v)
{
std::cout << "yield_value invoked." << std::endl;
return_data_ = v;
return std::suspend_always{};
}
//! 在协程最后退出后调用的接口。
//! 若 final_suspend 返回 std::suspend_always 则需要用户自行调用
//! handle.destroy() 进行销毁,但注意final_suspend被调用时协程已经结束
//! 返回std::suspend_always并不会挂起协程(实测 VSC++ 2022)
auto final_suspend() noexcept
{
std::cout << "final_suspend invoked." << std::endl;
return std::suspend_always{};
}
//
void unhandled_exception()
{
std::exit(1);
}
//返回值
T return_data_;
};
};
//这就是一个协程函数
coro_ret<int> coroutine_7in7out()
{
//进入协程看initial_suspend,返回std::suspend_always{};会有一次挂起
std::cout << "Coroutine co_await std::suspend_never" << std::endl;
//co_await std::suspend_never{} 不会挂起
co_await std::suspend_never{};
std::cout << "Coroutine co_await std::suspend_always" << std::endl;
co_await std::suspend_always{};
std::cout << "Coroutine stage 1 ,co_yield" << std::endl;
co_yield 101;
std::cout << "Coroutine stage 2 ,co_yield" << std::endl;
co_yield 202;
std::cout << "Coroutine stage 3 ,co_yield" << std::endl;
co_yield 303;
std::cout << "Coroutine stage end, co_return" << std::endl;
co_return 808;
}
int main(int argc, char* argv[])
{
bool done = false;
std::cout << "Start coroutine_7in7out ()
";
//调用协程
auto c_r = coroutine_7in7out();
//第一次停止因为initial_suspend 返回的是suspend_always
//此时没有进入Stage 1
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
done = c_r.move_next();
//此时是,co_await std::suspend_always{}
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
done = c_r.move_next();
//此时打印Stage 1
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
done = c_r.move_next();
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
done = c_r.move_next();
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
done = c_r.move_next();
std::cout << "Coroutine " << (done ? "is done " : "isn't done ")
<< "ret =" << c_r.get() << std::endl;
return 0;
}
至此,协程的基本概念就理清楚了。
另外,这是 cppreference 网站关于协程的介绍,里边即有基本概念,又有示例。了解了基本原理后可以从这个网站系统学习协程知识了。
其它的一些学习资料:
这篇文章讲述了如何把传统的线程池改造成支持协程的线程池。完整代码的 GitHub 地址:coroutine-thread-pool.h。
这是一个协程的其它例子,可以学学思想和方法。
2. 协程的作用
参考资料:
为了最大化利用硬件和系统资源,应该达到这样的目的:(1) 尽可能最大化线程的工作效率,即在 CPU 给线程分配的时间切片内,线程尽可能用在处理业务上,而不是浪费在线程内等待上。(2) 使 CPU 尽可能用在处理业务上,而不是过多浪费在没必要的线程切换上。
目前限制线程执行效率的地方主要有两个:(1)线程切换开销。线程切换需要到内核态,是比较耗时的。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的 CPU 运算能力,这样就造成了本来可以用来处理业务的 CPU 资源和时间反而浪费在了线程切换上,这样就大大降低了效率。(2)线程上有等待操作,例如常见的 IO 等待操作,即,其它与 IO 无关的业务也要等待 IO 响应完成后才能执行。
2.1. 线程模型
在现代计算机结构中,先后提出过两种线程模型:内核级线程(kernel-level threads)和用户级线程(user-level threads)。
内核级线程往往指操作系统提供的线程语义,由于操作系统对指令流有完全的控制能力,甚至可以通过硬件中断来强迫一个进程或线程暂停执行,以便把处理器时间移交给其它的进程或线程,所以内核级线程有可能应用各种算法来分配处理器时间。线程可以有优先级,高优先级的线程被优先执行,它们可以抢占正在执行的低优先级线程。在支持线程语义的操作系统中,处理器的时间通常是按线程而非进程来分配,因此,系统有必要维护一个全局的线程表,在线程表中记录每个线程的寄存器、状态以及其它一些信息。然后,系统在适当的时候挂起一个正在执行的线程,选择一个新的线程在当前处理器上继续执行。
用户级线程是指,应用程序在操作系统提供的单个控制流的基础上,通过在某些控制点(比如系统调用)上分离出一些虚拟的控制流,从而模拟多个控制流的行为。用户级线程模型的优势是线程切换效率高,因为它不涉及系统内核模式和用户模式之间的切换;另一个好处是应用程序可以采用适合自己特点的线程选择算法,可以根据应用程序的逻辑来定义线程的优先级,当线程数量很大时,这一优势尤为明显。但是,这同样会增加应用程序代码的复杂性。用户级线程本身只有一个线程,所以无法实现并行。
2.2. 协程模型
协程(Coroutine)是一种轻量级的用户级线程,实现的是非抢占式的调度,即由当前协程切换到其它协程由当前协程来控制。目前的协程框架一般都是设计成 1:N 模式。所谓 1:N 就是一个线程作为一个容器里面放置多个协程。那么谁来适时的切换这些协程?答案是有协程自己主动让出 CPU,也就是每个协程池里面有一个调度器,这个调度器是被动调度的。意思就是它不会主动调度。而且当一个协程发现自己执行不下去了(比如异步等待网络的数据回来,但是当前还没有数据到),这个时候就可以由这个协程通知调度器,这个时候执行到调度器的代码,调度器根据事先设计好的调度算法找到当前最需要 CPU 的协程。切换这个协程的 CPU 上下文把 CPU 的运行权交个这个协程,直到这个协程出现执行不下去需要等待的情况,或者它调用主动让出 CPU 的 API 之类,触发下一次调度。
2.3. 线程和协程调度优缺点对比
2.4. 线程调度优缺点
在同一个进程中并行运行多个线程,是对在同一台计算机上并行运行多个进程的模拟。因此,线程也被称为轻量级进程。与进程调度类似,CPU 在线程之间快速切换,制造了线程并行运行的假象。
由于各个线程都可以访问进程地址空间的每一个内存地址,所以一个线程可以读、写,甚至清除另一个线程的堆栈。也就是说,线程之间是没有保护的。但要注意的是,每个线程都有自己的堆栈、程序计数器、寄存器等信息,这些不是共享的。
共享地址空间虽然可以方便地共享对象,但这也导致一个问题,那就是任何一个线程出错时,进程中的所有线程会跟着一起崩溃。这也是如 Nginx 等强调稳定性的服务坚持使用多进程模式的原因。事实上,无论基于多进程还是多线程,都难以实现高并发,这由三个原因所致。
2.4.1. 优点
调度灵活,可以抢占。
2.4.2. 缺点
● 线程内存占用过多
单个线程消耗的内存过多,比如 64 位的 Linux 为每个线程的栈分配了 8MB 的内存,通过 ulimit -s 可以查看线程的默认分配的内存,单位 kb。
● 线程竞争
为了解决线程申请堆内存时,互相竞争的问题。每个线程预先在这个空间内申请堆空间还预分配了 64MB 的内存作为堆内存池。所以,我们没有足够的内存去开启几万个线程实现并发。
● 线程切换耗时
线程的切换是由内核控制的,什么时候会切换线程呢?不只时间片用尽,当调用阻塞方法时,内核为了 CPU 充分工作,也会切换到其他线程执行。一次上下文切换的成本在几十纳秒到几微秒间,当线程繁忙且数量众多时,这些切换会消耗绝大部分的 CPU 运算能力。
2.5. 协程调度优缺点
2.5.1. 优点
- 协程更加轻量,创建成本更小,降低了内存消耗;
- 协程有自己的调度器,减少了 CPU 上下文切换的开销,提高了 CPU 缓存命中率;
- 减少同步加锁,整体上提高了性能;
- 可以按照同步思维写异步代码,即用同步的逻辑,写由协程调度的回调。
2.5.2. 缺点
- 在协程执行中不能有阻塞操作,否则整个线程被阻塞;
- 协程可以处理 IO 密集型程序的效率问题,但不适合处理 CPU 密集型问题。
2.5.3. 适用场景
- 高性能计算,牺牲公平性换取吞吐;
- 处理 IO 密集型的任务;
- Generator 式的流式计算。
2.6. 线程池模型到协程的进化
前边我们提到了,目前限制单个线程执行效率的地方主要有两个:(1)线程切换开销。(2)线程上有等待的 IO 操作。
通过线程池模型,可以解决解决问题 1。而把线程池模型进化到协程可以解决问题 2。
先看一个多线程的例子:
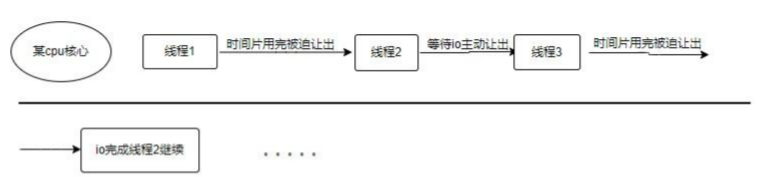
上图简单的表示系统的线程调度。有些地方要注意一下:(1)线程的执行权可以主动让出。在当前线程时间片用完之后,即便没有让出,操作系统也会强行让线程停下来运行别的线程;(2)操作系统会根据需要或者优先级选择让某些线程多执行或先执行;(3)线程一般为目态(可以认为是低权限状态),而操作系统是管态(高权限状态),来回切换需要时间。
想象一下,某个线程收到一个请求然后解析请求,发送数据库请求让出线程执行权等待,收到数据库回复后向某服务发送请求让出线程执行权 ...,这样会有两个很明显的问题:
- CPU 大部分时间浪费在线程的切换上,CPU 利用率低。
- 每一个请求都要创建一个线程,浪费内存。
为了解决这个问题于是就进化出来了线程池:
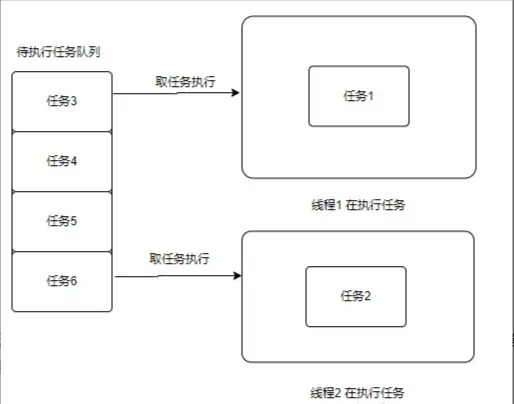
那么通过线程池我们只需把每一个任务封装成一个方法,放到线程池等待队列中,那么线程在执行完一个任务后就会到队列中取下一个任务执行,减少线程让出的次数。
现在这种线程池的解决方案离完美就差一个类似让出线程执行权的操作了。某个任务做到一半,需要等待 IO,先让出任务执行权(不是让出线程)执行下一个任务,等到 IO 结束了再执行另一半的任务。那么这种模型就是协程,而为了做到这些,就需要协程具有可以模仿操作系统保存与恢复 CPU 环境的能力,或保存与恢复当前代码执行状态的能力。
简而言之,协程在行为逻辑上和线程、进程类似,都是实现不同逻辑流的切换和调度。但要明确的是,协程(Coroutine)是在用户态完成的,而进程(Process)和线程(Thread)是在内核态完成的。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结