您现在的位置是:首页 >技术教程 >【多模态语言模型目标检测】A SIMPLE AERIAL DETECTION BASELINE OF MULTIMODAL LANGUAGE MODELS网站首页技术教程
【多模态语言模型目标检测】A SIMPLE AERIAL DETECTION BASELINE OF MULTIMODAL LANGUAGE MODELS
【多模态语言模型目标检测】A SIMPLE AERIAL DETECTION BASELINE OF MULTIMODAL LANGUAGE MODELS
多模态语言模型目标检测
今天来快速阅读并理解一篇论文:A SIMPLE AERIAL DETECTION BASELINE OF MULTIMODAL LANGUAGE MODELS
文章贡献
- 该文首次提出了一种将多模态语言模型应用于航空检测的简单基线方法,名为 LMMRotate。
- 具体而言,首先引入一种归一化方法,将检测输出转换为文本输出,以适配多模态语言模型框架。
- 提出一种评估方法,确保多模态语言模型与传统目标检测模型之间能够进行公平比较。通过微调开源通用多模态语言模型构建了该基线,并取得了与传统检测器相当的出色检测性能。
任务难点
传统检测输出由边界框的数值坐标和物体类别组成,这与语言模型产生的文本输出显著不同。其次,语言生成模型通常是自回归的,生成因果序列,而检测模型通常并行输出所有结果。此外,由于存在许多小而密集的物体,航空检测带来了相当大的挑战,这对视觉输入分辨率和多模态语言模型的输出序列长度都提出了很高的要求。
解决方案
多模态语言模型概述
该文章用图像理解的多模态语言模型范式,该范式如下图所示,通过双模态投影操作将视觉基础模型和语言基础模型连接起来。该文章对现成的预训练多模态语言模型进行微调,以继承从定位任务中学到的定位能力。
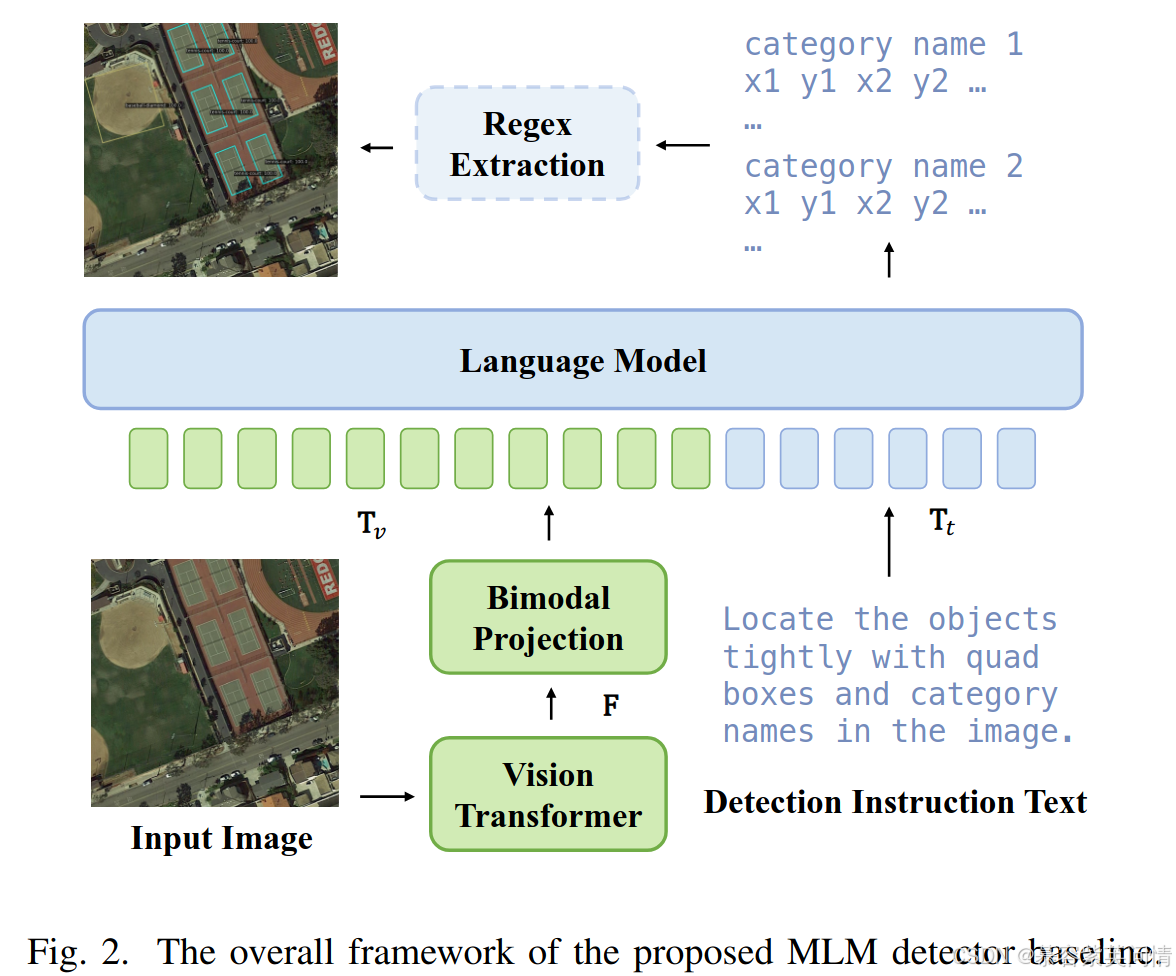
如图所示,输入遥感图像首先通过图像预处理,然后通过ViT得到视觉特征,视觉特征通过双模态投影映射为视觉标记 T v T_v Tv,检测指令的文本提示被标记为 T t T_t Tt, 语言模型的输入为两者的拼接。
I n p u t T = C o n c a t ( T v , T t ) Input T = Concat(T_v, T_t) InputT=Concat(Tv,Tt)
在训练阶段,使用标准的语言建模策略,即带有交叉熵损失的下一个标记预测,来优化模型参数 θ heta θ,
L = − ∑ j = 1 ∣ r ∣ P j ( r , T ) , P j ( r , T ) = l o g P θ ( r j ∣ r < j , T ) L = - sum_{j = 1}^{|r|} P_j(r,T), P_j(r,T) = log P_ heta(r_j|r_{<j}, T) L=−j=1∑∣r∣Pj(r,<






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结