您现在的位置是:首页 >技术杂谈 >【学习资源】终身机器学习之增量学习网站首页技术杂谈
【学习资源】终身机器学习之增量学习
从机器学习存在的问题谈起,介绍增量学习可以解决怎样的问题,增量学习的类别,实现增量学习的方法,增量学习的评价指标和常用数据集,类别增量学习典型方法和代码库以及参考资源,希望能帮助大家用增量学习提高图像分类、对象检测、语义分割、行为识别、对象重识别、三维点云处理等工作的质量。
1目前机器学习存在什么问题?
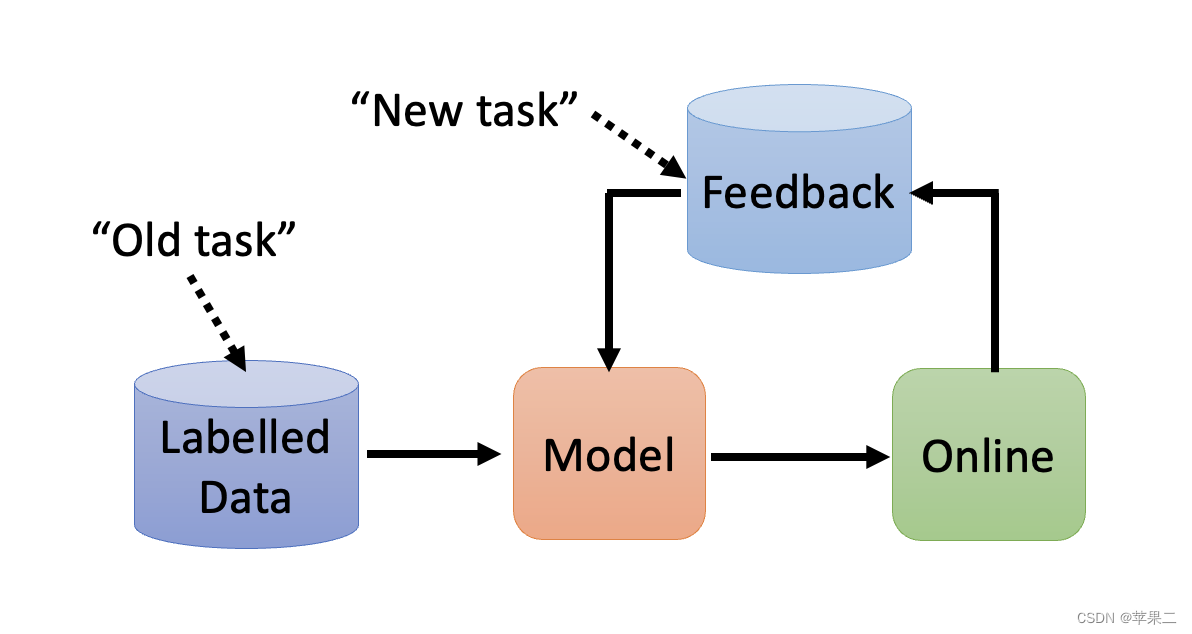
图片来源:https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/life_v2.pdf
目前机器学习存在以下问题:
已有的领域信息如果包含有噪声和没有噪声信息的内容,如何让模型在两种情况上都能有较好的表现?
包含参数的神经网络模型能较好地完成任务一,但不能完成任务二。和人类比,也就是只能完成一种任务。或者说,参数不能适应新的任务。如何获得能够同时较好地完成任务一和任务二的模型?
在图像分类的任务中,初次训练分类器时很难收集全所有可能类别的训练样本,应用中遇到新类别时需要进行类别增量训练,如何训练?
对象检测和语义分割模型如何利用背景信息挖掘有利于后续类别增量学习的特征表示?
2 增量学习解决了什么问题?
既能不断更新学习新类别或者任务,又能较好地保持在已学习类别或任务的性能。
持续学习(Continual Learning)或者增量学习(Incremental Learning)试图帮助神经网络实现像人们一样学习大量不同的任务,不出现任何负面的相互干扰, 并解决灾难性的遗忘问题。增量学习算法的重点不是如何利用在以前任务中学到的知识来帮助更好地学习新任务,而是解决灾难性遗忘的问题。
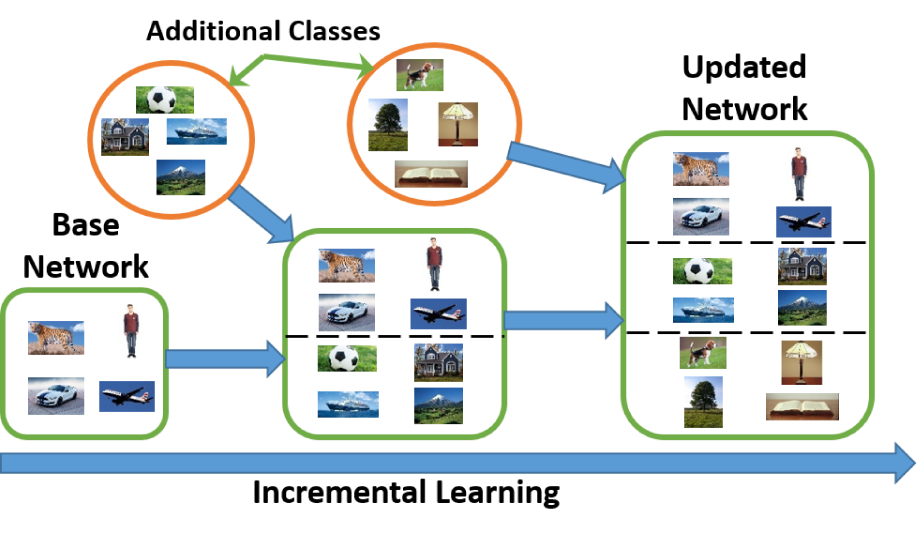
3增量学习有哪些类别?
下表中的分类层指深度神经网络的最后一层,特征提取器指深度神经网络除去分类层的前面层次。
| 种类 | 原理 | 类别集特征 | 遗忘现象发生的结构 | 测试阶段要求 |
| 数据增量 | 类别集不变,数据以在线形式动态增加。 | 不变 | NA | NA |
| 任务增量 | 不同的任务共享相同的特征提取器,每学习一个任务,模型需要增加一个输出分类层。 | 变化,在各自任务内部分类。 | 在特征提取器,因为不同任务的分类层之间互不影响。 | 模型需要事先已知当前测试样本所属的任务编号,在该任务所对应的分类层内部分类。 |
| 类别增量 | 所有类别共享一个分类层,该分类层的类别节点会随着学习类别的增加而增加。在现实中有很多实际需求 。 | 变化在所有已学习类别上分类。 | 特征提取器和分类层都存在遗忘现象。因为不同类别之间会相互影响。 | 不需要预先指定测试样本所属类别就可以对所有已知类别进行分类。 |
4实现增量学习的方法有哪些?
介绍两种不同的分类方法。
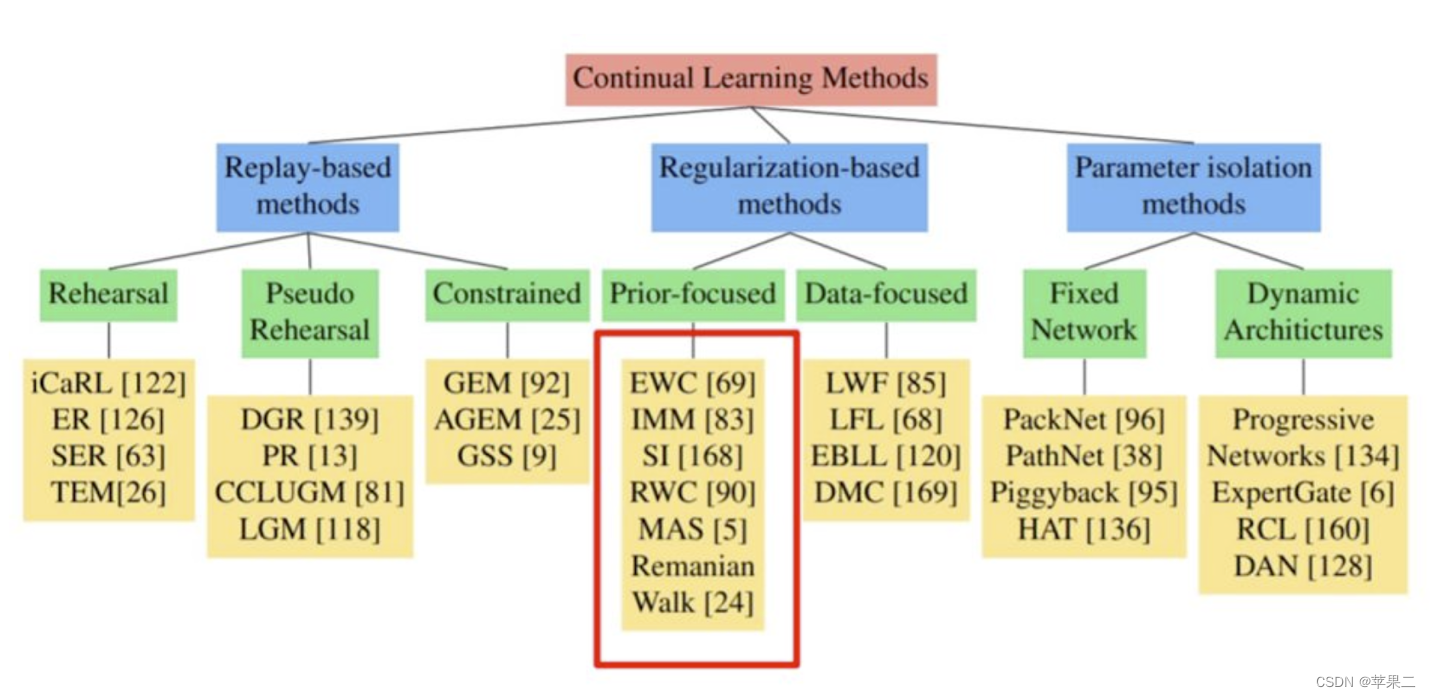
图片来源:
https://github.com/virginiakm1988/ML2022-Spring/blob/main/HW14/HW14.pdf
李宏毅教授在https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/life_v2.pdf介绍了以下三种类型。
- Selective Synaptic Plasticity
- Additional Neural Resource Allocation
- Memory Reply
Selective Synaptic Plasticity 用梯度方法可以找到哪些参数对某一个任务重要。通过改变那些对第一个任务影响不大或者不重要的参数,让模型可以同时完成第一个任务和第二个任务。这个方法主要是改变模型的参数,称为参数正则化。如EWC、SI、MAS以及LwF-MC等方法。参数正则化方法适用于解决任务增量学习。
Additional Neural Resource Allocation 介绍了Progressive Neural Network,PackNet和CPG。Progressive Neural Network渐进式神经网络保留大量的预训练模型,也即保留旧任务的模型参数,当有新任务时,使用旧任务之间的横向链接来适应。当然其缺点是随着任务数量的增加,参数的数量会爆炸式增长。PackNet则是先设置一个很大的网络,当有新的任务时,只使用大网络中的一部分。这样参数量不会随着任务的增加而增加。Progressive Neural Network和PackNet相结合,可以既增加新的参数,也可以保留完成每一次任务的 参数。
Memory Reply是指使用先前任务的生成模型生成伪数据。
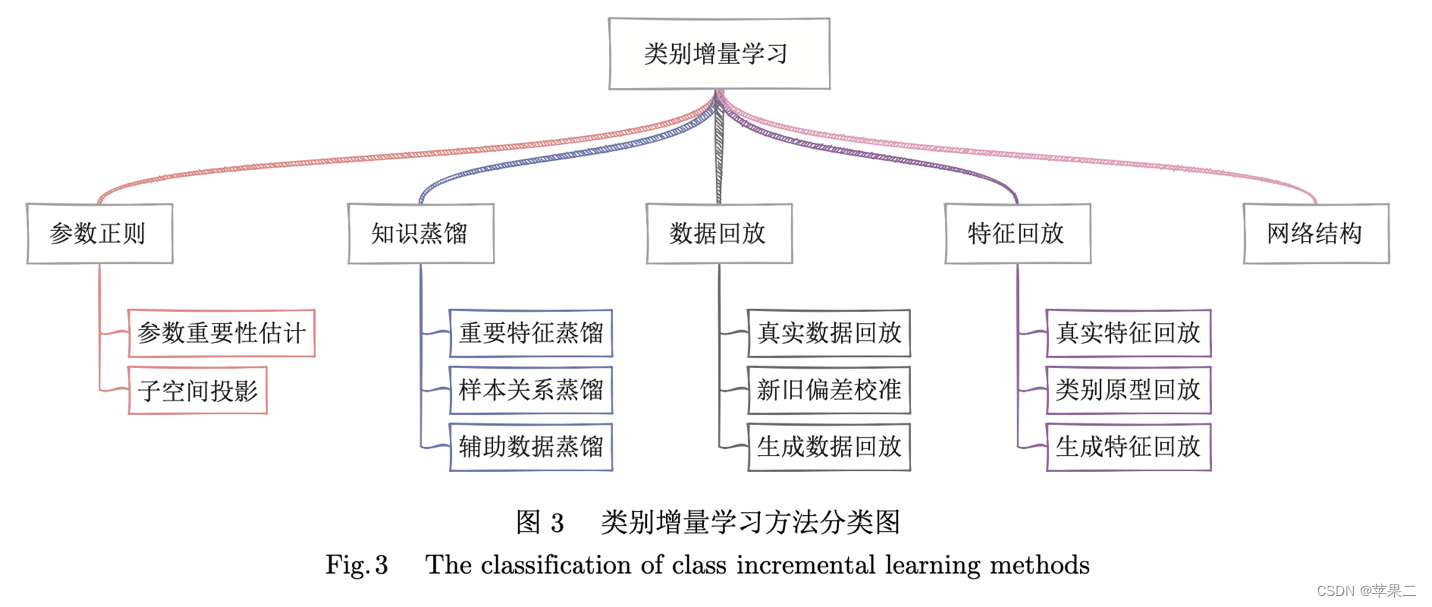
图片来源:朱飞,张煦尧,刘成林.类别增量学习研究进展和性能评价[J].自动化学报,2023,49(03):635-660.DOI:10.16383/j.aas.c220588.
在《类别增量学习研究进展和性能评价》这篇文章里,朱飞等介绍了基于克服遗忘的技术思路的五种方法:基于参数正则化、基于知识蒸馏、基于数据回放、基于特征回放和基于网络结构,总结了每种方法的优缺点。作者们在常用数据集上用实验评估代表性方法, 并根据实验结果比较分析了现有算法的性能,也展望了类别增量学习的研究趋势,是一个非常好的参考资料。我就不赘述了。
基于知识蒸馏的方法是在学习新任务的同时,保持新旧模型对给定数据的输出一致性,也即“输入-输出”不变形,避免遗忘旧知识。可以通过保持重要特征、样本关系和辅助数据来实现。如TPCIL、PODnet、DDE以及GeoDL等方法。
数据回放是指模型在学习新任务的时候,可以将旧任务的类别数据和新任务的类别数据一起更新模型,可以通过回放真实数据、回放生成数据以及校准新旧偏差实现。如等方法。
大部分基于数据回放的方法会使用知识蒸馏策略,从而可以更好地利用保存的旧类别样本。如iCaRL,BiC,UCIR,WA等方法。
特征回放是指模型在学习新任务的时候,可以将旧任务的样本特征和新任务的样本特征一起更新模型,可以通过回放真实特征、类别原型和生成特征实现。如PASS、SSRE、Fusion方法。
基于网络结构的方法是在增量学习的过程中动态扩展网络结构。如AANets、DER、ReduNet方法。
5增量学习的评价指标和常用数据集

图片来源:朱飞,张煦尧,刘成林.类别增量学习研究进展和性能评价[J].自动化学报,2023,49(03):635-660.DOI:10.16383/j.aas.c220588.
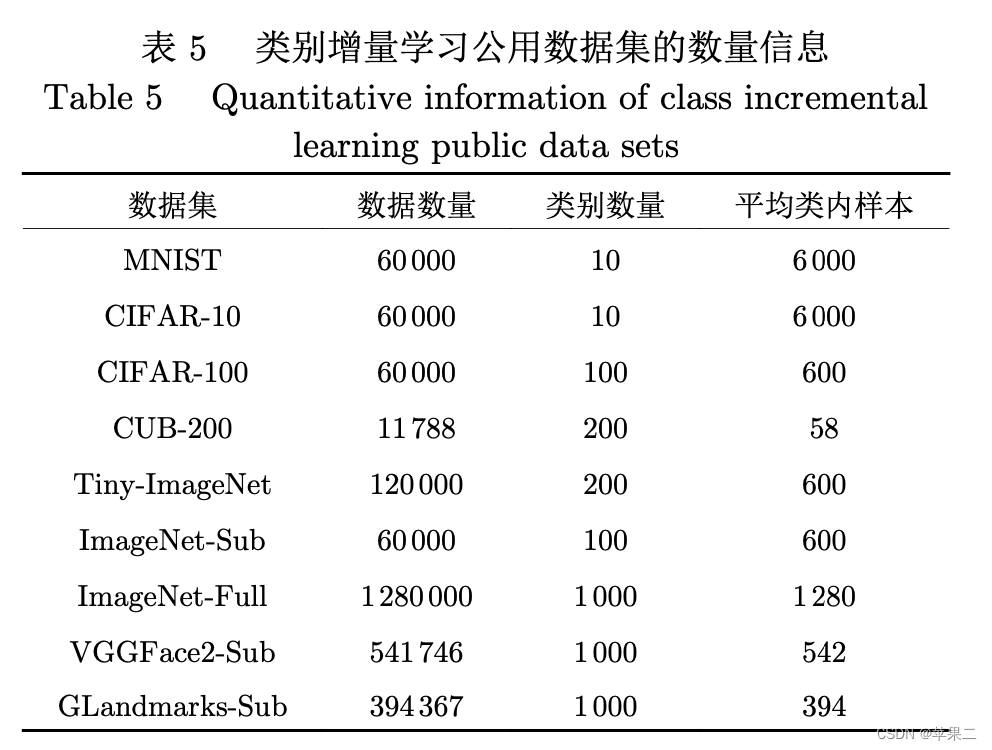
图片来源:朱飞,张煦尧,刘成林.类别增量学习研究进展和性能评价[J].自动化学报,2023,49(03):635-660.DOI:10.16383/j.aas.c220588.
6类别增量学习典型方法和代码库
类别增量学习的目标是模型在动态、开放的环境下, 能够在较好地保持已有知识的基础上, 持续地学习新类别知识。
iCaRL(Incremental Classifer and Representation Learning)是一种非常基础的方法,其用于在类增量设定下同时学习分类器和特征表示。在高层次上,iCaRL为每个观察的类维护一个范例样本集。对于每个类,范例集是该类所有样本的一个子集,目的是包含该类的最具代表性的信息。新样本的分类是通过选择一个与之最相似的范例集所在的类来完成的。当一个新类出现时,iCaRL为此新类创建一个范例集,同时修剪现有/以前类的范例集。这个方法包括增量训练、更新特征表示和为新类构建范例集。
PyCIL: A Python Toolbox for Class-Incremental Learning GitHub - G-U-N/PyCIL: PyCIL: A Python Toolbox for Class-Incremental Learning
,这个工具箱几乎实现了所有的类别增量学习方法。包括EWC、iCaRL经典算法以及SSRE、Coil、FOSTER、FeTRIL等最新的增量学习方法。其他库可参考Incremental Learning | Papers With Code
下图是增量学习的过程
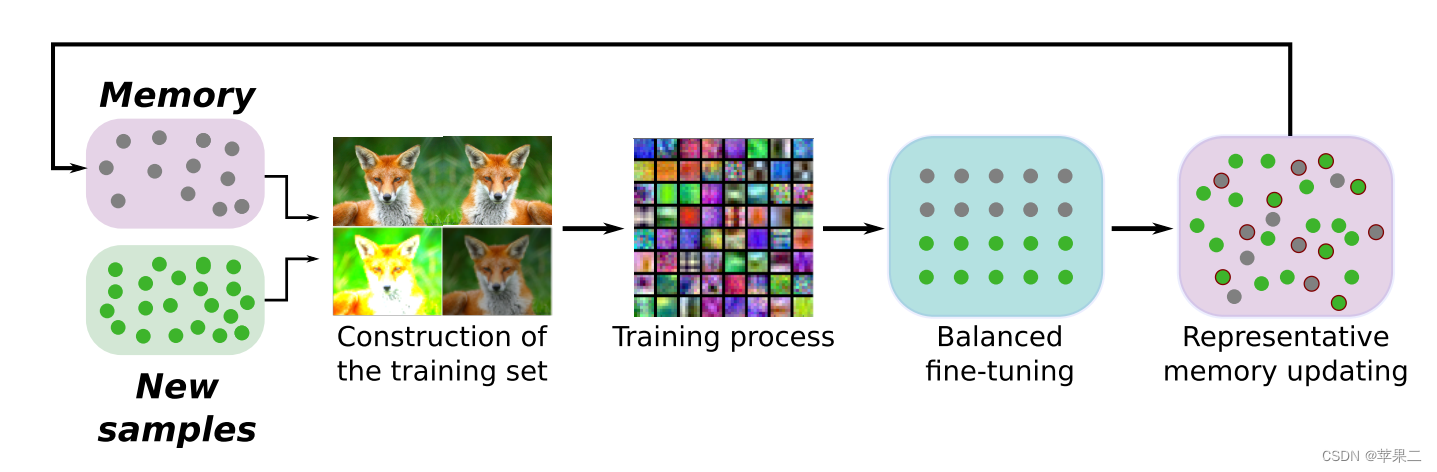
图片来源:Knowledge Distillation and Incremental Learning - Deepan Das
7参考资源
以下资源供参考。
- 台湾大学李宏毅终身学习课程
第十四节 2021 - 机器终身学习 (一) - 为什么今日的人工智能无法成为天网?灾难性遗忘(Catastrophic Forgetting)_哔哩哔哩_bilibili
2021 - 机器終身学习 (二) - 灾难性遗忘(Catastrophic Forgetting)_哔哩哔哩_bilibili
课件https://speech.ee.ntu.edu.tw/~hylee/ml/ml2021-course-data/life_v2.pdf
- 最新综述 | 类别增量学习研究进展和性能评价 全文链接类别增量学习研究进展和性能评价 朱飞,张煦尧,刘成林.类别增量学习研究进展和性能评价[J].自动化学报,2023,49(03):635-660.DOI:10.16383/j.aas.c220588.
- 让模型实现“终生学习”,佐治亚理工学院提出Data-Free的增量学习
- 万文长字总结「类别增量学习」的前世今生、开源工具包
- 增量学习论文和代码汇总: Incremental Learning | Papers With Code
- 陈志源,刘兵. 终身机器学习(原书第2版) (智能科学与技术丛书) (Chinese Edition) (Kindle Locations 1381-1385). Kindle Edition.
- https://deepandas11.github.io/deep-learning,/computer-vision,/detection,/incremental-learning/Incremental-Learning/
总之,类别增量学习可以助力于图像分类、对象检测、语义分割、行为识别、对象重识别、三维点云处理等工作。欢迎大家留言,我们一起讨论交流。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结