您现在的位置是:首页 >技术交流 >【经验与Bug】tensorflow草记网站首页技术交流
【经验与Bug】tensorflow草记
文章目录
1 常用小知识
-
conda activate tf在anaconda prompt使用,进入名为tf的虚拟环境。
-
pip install <包名>==可以查看指定包能被找到的所有版本。
-
pip install <包名> -i https://pypi.org/simple从官方源下载包。
-
绘制多图 :
plt.figure(figsize=(10,10)) plt.subplot(5,5,1) -
Colab挂载谷歌云端硬盘 。
from google.colab import drive import os # 挂载网盘 drive.mount('/content/drive/') # 切换路径 os.chdir('/content/drive/MyDrive/rnn') # 查看目录下文件 !ls -ll # 和linux终端用法差不多 但是!(感叹号)不能少 -
python连接列表 。
a = [1, 2, 3] b = [4, 5, 6] c = a + b print(c) ''' [1, 2, 3, 4, 5, 6] '''同样的,元组也可以使用 “+” 进行连接运算。
2 Learn
-
Max Pooling 增强特征,减少数据。
-
卷积神经网络理论与算法 https://bit.ly/2UGa7uH (Youtube)
-
卷积层中,每个filter对应有一个bia
-
tensorflow的自动参数搜索功能,真的有点小期待。
有点失望,刚刚搜索出来的模型效果并不好。层数是预先固定的,搜索了卷积核数、卷积核的尺寸、全连接层的神经元数。虽然预先少了两层卷积,但准确率差距着实有点大。而且搜索得到模型的大小不好控制,比如刚刚搜索出模型的尺寸是原代码中模型的30倍。
-
原代码提供的模型,5层卷积,验证集准确率可在多个epoch保持100%。
-
搜索出模型,3层卷积,验证集准确率只到84%。
不知道能不能搜索learning_rate、batch_size。
-
1) 疑惑未解
1、卷积或池化的边界问题是如何处理的,不同的处理方式又各有什么影响?例如(5,5)的特征图被进行(2,2)的kernel池化或卷积。
2、进行了卷积中特征图的可视化,但是中间为什么会出现一些黑格呢?是特征图真的黑,还是显示的逻辑问题(比如有一步特征图后处理裁剪到[0,255])。

2) 为何要有"bias"?
我们知道,对于一元线性函数,仅仅 y = w x y=wx y=wx 的表达能力是不够的,为了表达二维平面内的任意一条直线,我们使用了 y = w x + b y=wx+b y=wx+b 。但是这个b能否被一个wx所替代?或者说:
y = w x + b y=wx+b y=wx+b 是 y = w 1 x 1 + w 2 x 2 y=w_1x_1+w_2x_2 y=w1x1+w2x2 的一个子集吗?
答案应该是不能。虽然对于任意的b,都可以找到某组(w, x),使得 w x = b wx=b wx=b 。但是我们要的,就是固定,就是不受输入x的影响。
3 问题处理
1) jupyter的环境
如何在conda的不同虚拟环境中使用jupyter notebook?我使用了conda install nb_conda_kernels 后,仍然无法切换想要的环境。
在jupyter notebook的Conda选项卡中,只有两个打勾的环境能被使用。
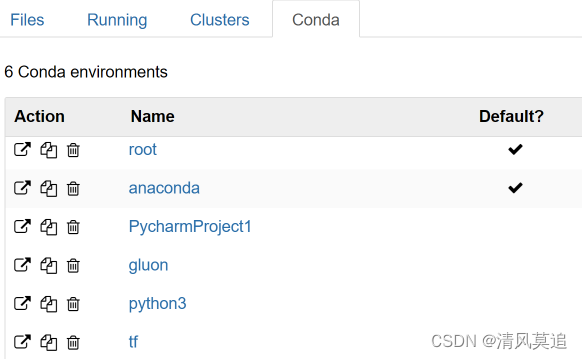
打算暂时放弃jupyter notebook,毕竟也不是必需,我可以继续使用我的pycharm。
好像,jupyter notebook还是挺有用的,特别是我现在还没有学会保存模型的情况下,每次运行代码都要重新训练一次。
关于在指定虚拟环境中运行jupyter notebook,这篇教程是可以跑通的: 在Anaconda虚拟环境下打开jupyter notebook 。
指定目录运行jupyter
分为以下几步:
- 在目标目录启动cmd;
conda activate <env_name>,激活你安装了jupyter notebook的环境;jupyter notebook,启动notebook。
2) Keras版本
运行下面这段代码时报错了,
import keras
import numpy as np
# 构建模型
model = keras.Sequential([keras.layers.Dense(units=1, input_shape=[1])])
model.compile(optimizer='sgd', loss='mean_squared_error')
# 准备训练数据
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
# 训练模型
model.fit(xs, ys, epochs=500)
# 使用模型
print(model.predict([10.0]))
安装keras时,我直接pip install keras,然而tensorflow与keras的版本之前其实是有对应关系的,卸载keras重新下载对应的版本即可。版本关系参见:亲测解决导入Keras报错 。
3) 为什么accuracy为100%,迭代时参数还在更新?
这个问题可以回看一下交叉熵损失函数的公式(如何你是用的它的话)。
关键在于, l o s s = S u m ( − 1 ∗ l o g ( 被 正 确 分 类 的 样 本 的 预 测 概 率 ) ) loss=Sum(-1*log(被正确分类的样本的预测概率)) loss=Sum(−1∗log(被正确分类的样本的预测概率)) 只要模型输出的预测概率还没有变成100%,参数就会继续更新。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结