您现在的位置是:首页 >其他 >Transformer的原理及应用分析网站首页其他
Transformer的原理及应用分析
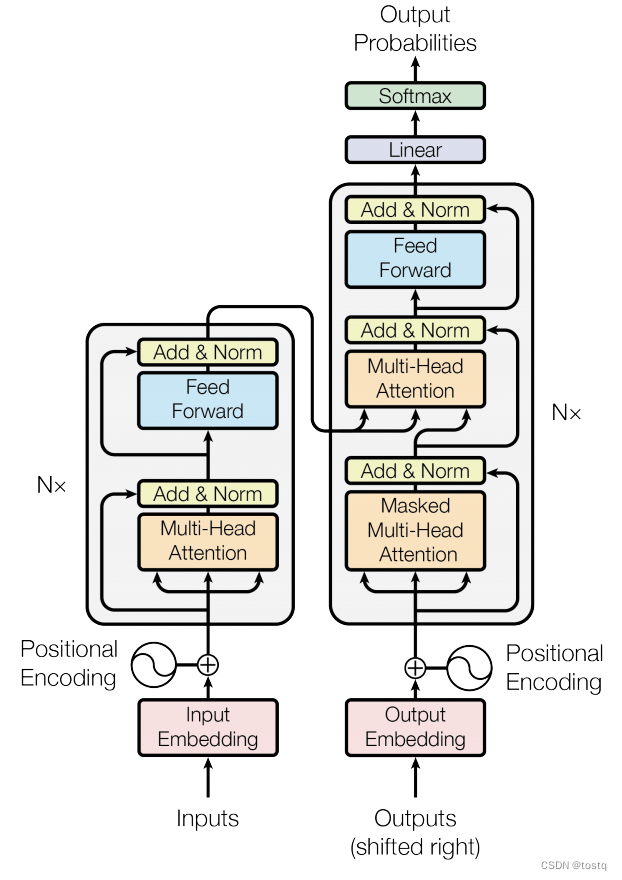
上一篇博文重点介绍了Transformer的核心组件MultiHeadAttention多头注意力机制,本篇继续介绍transformer的原理。下图为transformer的结构图,其主要由位置编码、多组编码器和多组解码器。以下将重点介绍三个部分。
1. 位置编码 Positional Encoding
Attention存在的一个问题是没有保留序列中各词的位置信息,或者说序列中各词间调换顺序后,对于最终输出几乎没有影响,因此必须要将位置编码作为Attention的输入部分,在Transformer中给出位置编码方法,是在原有词向量上叠加位置编码向量:
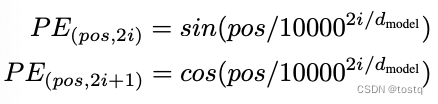
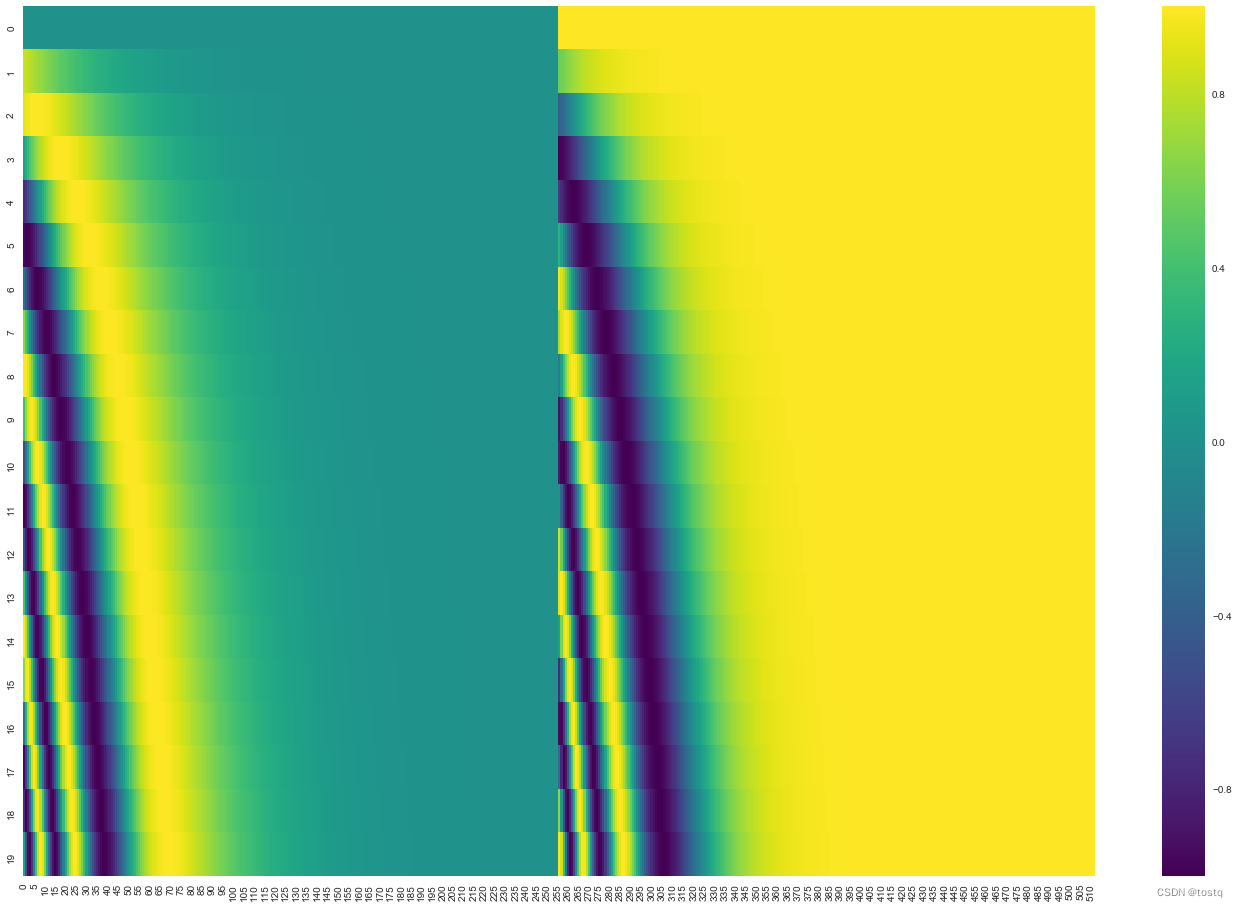
上式用于计算位置编码向量,pos表示词在序列中的位置[1,2,3,4...],i表示位置编码向量中位置,下图的纵轴表示位置从0~19下的512维位置编码向量,该位置编码向量会同输入embeding向量叠加作为attention的输入。
2. 编码器
编码器组件中,经过多头注意力模块后,还有两个残差和layerNorm操作,这两个模块是用于提升模型收敛的常见举措,此外在Attention中在用点积来计算query、key间的相似度得分时,要求都必须满足零均值和单位方差,因此LayerNorm也起到了保证作用。
另一个组件是前向网络Position-wise Feed-Forward Networks,其实际上是两层的全连接网络:
但不同之处其是Position-wise,意思是针对于序列中各词向量单独经过两层全连接网络,因此序列中各位置的词向量是共有一个前向网络,所以FFN网络本质上是增加词向量本身表达,还不是学习词向量间相关信息,这部分是由Attention来完成的。
3. 解码器
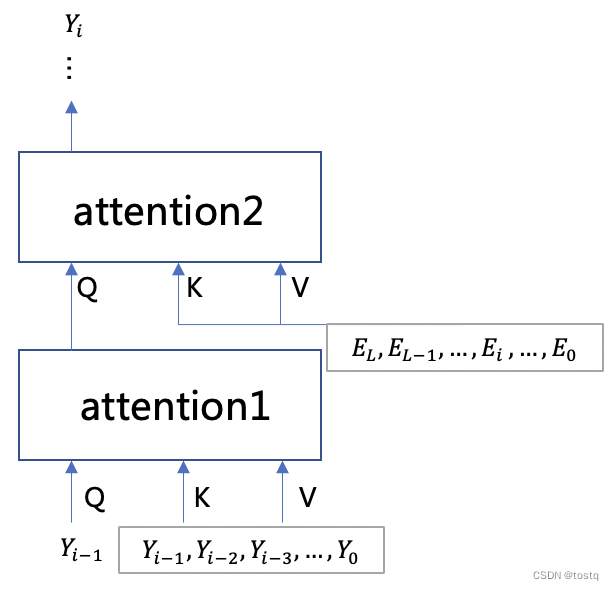
解码器同编码器唯一的不同之处,在于其多了一组自注意力组件,下图描述了解码器的两组自注意力组件的输入,其中第一组自注意力组件的query是前一词,其key和values是当前已经产出的词序列,其主要用于建立输出序列本身的关系,其输出在第二组注意力组件中,同编码器的输出建立了关系,整体的结构同RNN有相仿的地方。
4. 应用
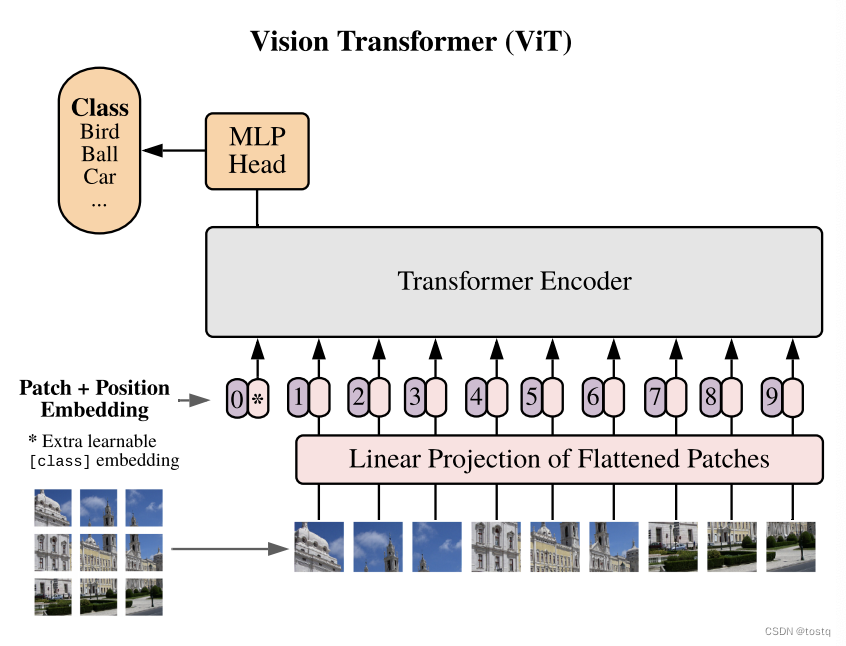
Transformer主要是用于序列转换,比如机器翻译、文本生成、生成对话等等,一些情感分析等序列分类任务可以通过应用Encoder模块+线性层来完成。此外,近年来一些图像处理领域也有大量工作是基于Transformer的结构的,比如这篇论文中将Transformer应用于图像分类,其原理是将图片划分为16x16的patch,然后将patch转换为向量,然后带上位置编码特征进入transformer的Encoder层,经过多层encoder后,最后通过一个线性层得到分类估计。





站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结