您现在的位置是:首页 >学无止境 >研读Rust圣经解析——Rust learn-12(智能指针)网站首页学无止境
研读Rust圣经解析——Rust learn-12(智能指针)
研读Rust圣经解析——Rust learn-12(智能指针)
智能指针
指针 (pointer)是一个包含内存地址的变量的通用概念。这个地址引用,或 “指向”(points at)一些其他数据
前面说的引用就是指针
智能指针(smart pointers)是一类数据结构,他们的表现类似指针,但是也拥有额外的元数据和功能。智能指针的概念并不为 Rust 所独有;
智能指针选择
Rc<T>允许相同数据有多个所有者;Box<T>和RefCell<T>有单一所有者。Box<T>允许在编译时执行不可变或可变借用检查;Rc<T>仅允许在编译时执行不可变借用检查;RefCell<T>允许在运行时执行不可变或可变借用检查。- 因为
RefCell<T>允许在运行时执行可变借用检查,所以我们可以在即便RefCell<T>自身是不可变的情况下修改其内部的值。
Box<T>
是最简单最直接的智能指针,数据会被存储到堆上,且没有任何性能损失,但也没什么额为功能
使用场景
- 当有一个在编译时未知大小的类型,而又想要在需要确切大小的上下文中使用这个类型值的时候
- 当有大量数据并希望在确保数据不被拷贝的情况下转移所有权的时候
- 当希望拥有一个值并只关心它的类型是否实现了特定 trait 而不是其具体类型的时候
创建Box
如其他的方式一样都是直接new出来的
fn main() {
let a = Box::new("nihao");
println!("{}",a)
}
使用Box在堆上存储递归类型数据
首先我们先创建一个enum List
#[derive(Debug)]
enum List {
Next(i32, List),
OFF,
}
这是个递归的List,下一个节点依然可以装List
接下来使用它创建一个变量
#[derive(Debug)]
enum List {
Next(i32, List),
OFF,
}
use List::{Next, OFF};
fn main() {
let list = Next(1, Next(2, OFF));
println!("{:?}",list);
}
编译之后我们会发现报错,原因是:编译器认为这个类型 “有无限的大小”,所以它不知道要用多少空间存储它,或它认为这个玩意就没办法存
同时他也提供了解决方法:
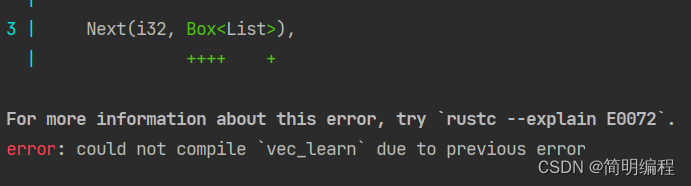 从这里可以看出,编译器希望我们使用Box来解决
从这里可以看出,编译器希望我们使用Box来解决
解决
#[derive(Debug)]
enum List {
Next(i32, Box<List>),
OFF,
}
use List::{Next, OFF};
fn main() {
let list = Next(1, Box::new(Next(2, Box::new(OFF))));
println!("{:?}", list);
}
我们来解释一下为什么用Box就可以了,首先Box是将值存到了堆上,会尝试使用一个尽可能大的空间进行存储,因为 Box<T> 是一个指针,我们总是知道它需要多少空间:指针的大小并不会根据其指向的数据量而改变。因为OFF这个字段不存任何东西,自然它的大小要比Next要小,所以进行了区分,当编译器发现了一个需要空间小于正常递归空间大小的节点的时候就认为这是终止节点(其实我更喜欢叫他叶子节点,因为我常常把递归看作一个树结构)
通过 Deref trait 将智能指针当作常规引用处理
实现 Deref trait 允许我们重载 解引用运算符(dereference operator)*。通过这种方式实现 Deref trait 的智能指针可以被当作常规引用来对待,可以编写操作引用的代码并用于智能指针。
追踪指针的值
这里我加了一个打印y这个变量的内存地址,或许我应该说打印y这个指针的内存地址
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
println!("{:p}",y);
}
y在这里是引用了x的值,所以y相当于一个指针,指针实际就是一个地址,要找到地址中真实的内容就需要使用解引用*
这段程序相当于
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
println!("{:p}",y);
}
智能指针也是指针这很好理解
创建自定义的智能指针(*)
我们也可以自己去写一个Box<T>其实这并不难,首先我们需要为结构体实现new方法,这很简单,传入一个泛型返回带泛型的结构体即可
use std::ops::Deref;
fn main() {
let x = 5;
let y = Smarter::new(5);
assert_eq!(5, x);
assert_eq!(5, *y);
}
struct Smarter<T>(T);
impl<T> Smarter<T> {
fn new(x: T) -> Smarter<T> {
Smarter(x)
}
}
impl<T> Deref for Smarter<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
然而,若只是到实现new你是无法实现解引用的,因为它需要实现Deref这个trait,看名字就知道了ref是引用,de反义词前缀,在这个实现中需要我们实现两个东西:
- type:你看作一个类型代指(想想TypeScript中的type)后面会讲
- deref方法:需要返回引用自身的target,也就是我们上面的类型代指,其实就是返回本身的self中的实际内容(想想unwrap系列的解构)
此时我们自己定义的智能指针就可以使用*进行解引用了
Deref隐式转换
隐式转换是指如:&String会转化为&str,这很常见
let a = String::from("newWord");
let b = &a
正常应该b的类型是&String,但实际上b则是&str,因为 String 实现了 Deref trait 因此可以返回 &str
Deref 强制转换(deref coercions)将实现了 Deref trait 的类型的引用转换为另一种类型的引用
Deref 强制转换是 Rust 在函数或方法传参上的一种便利操作,并且只能作用于实现了 Deref trait 的类型。当这种特定类型的引用作为实参传递给和形参类型不同的函数或方法时将自动进行。这时会有一系列的 deref 方法被调用,把我们提供的类型转换成了参数所需的类型。
Deref 强制转换的加入使得 Rust 程序员编写函数和方法调用时无需增加过多显式使用 & 和 * 的引用和解引用。这个功能也使得我们可以编写更多同时作用于引用或智能指针的代码
Deref 强制转换如何与可变性交互
Rust 提供了 DerefMut trait 用于重载可变引用的 * 运算符。
Rust 在发现类型和 trait 实现满足三种情况时会进行 Deref 强制转换:
- 当
T: Deref<Target=U>时从&T到&U。 - 当
T: DerefMut<Target=U>时从&mut T到&mut U。 - 当
T: Deref<Target=U>时从&mut T到&U。
Drop Trait 运行清理代码
对于智能指针模式来说第二个重要的 trait 是 Drop,其允许我们在值要离开作用域时执行一些代码。可以为任何类型提供 Drop trait 的实现,同时所指定的代码被用于释放类似于文件或网络连接的资源。
Rust其实没有全自动GC的概念,但是通过实现Drop,编译器会在该回收的时候自动插入回收代码以进行回收,我个人认为这是种半自动GC
相当于,我们手动调用drop函数
实现Drop
如下,我们定义一个结构体,然后让他实现Drop这个trait,在离开作用域之后自动调用drop(当然这是编译器帮我们干的所以我们称为自动,实际上就是编译器帮我们写了drop函数)
struct Smarter {
data: String,
}
impl Drop for Smarter {
fn drop(&mut self) {
println!("drop->{}", self.data);
}
}
fn main() {
let a = Smarter {
data: String::from("1"),
};
let b = Smarter {
data: String::from("2"),
};
}
我们执行一下
drop->2
drop->1
你看到的应该是先2后1,为什么?原因很简单啊,因为栈是后进先出的
提早drop
通过 std::mem::drop我们可以实现提早清理,就是手动drop
fn main() {
let a = Smarter {
data: String::from("1"),
};
drop(a);
}
这里给出一个其他博主的例子:
fn main() {
let mut list = A { children: None };
for _ in 0..1_000_000 { list = A { children: Some(Box::new(list)) }; }
println!("for complete, list is going to drop");
drop(list);
println!("program complete");
}
struct A {
children: Option<Box<A>>,
}
impl Drop for A {
fn drop(&mut self) {
if let Some(mut child) = self.children.take() {
while let Some(next) = child.children.take() {
child = next;
}
}
}
}
Rc 引用计数智能指针
大部分情况下所有权是非常明确的:可以准确地知道哪个变量拥有某个值。然而,有些情况单个值可能会有多个所有者。例如,在图数据结构中,多个边可能指向相同的节点,而这个节点从概念上讲为所有指向它的边所拥有。节点直到没有任何边指向它之前都不应该被清理因此也没有所有者。
为了启用多所有权需要显式地使用 Rust 类型Rc<T>,其为 引用计数(reference counting)的缩写。引用计数意味着记录一个值引用的数量来知晓这个值是否仍在被使用。如果某个值有零个引用,就代表没有任何有效引用并可以被清理。
那么Rc实际是一个计数器,当计数器清0的时候那么这个就能被drop了
Rc<T> 用于当我们希望在堆上分配一些内存供程序的多个部分读取,而且无法在编译时确定程序的哪一部分会最后结束使用它的时候。如果确实知道哪部分是最后一个结束使用的话,就可以令其成为数据的所有者,正常的所有权规则就可以在编译时生效。
注意点
Rc<T> 只能用于单线程场景
RC保证数据共享
现在我们有一个场景,我们有三个链表,a链表的尾部节点是b链表,c链表的尾部节点是b链表
我们首先来写出这个程序(不用Rc):
#[derive(Debug,Clone)]
enum List{
Next( i32,Box<List>),
OFF
}
use crate::List::{Next,OFF};
fn main() {
let b = Next(1,Box::new(Next(2,Box::new(OFF))));
let a = Next(4,Box::new(b.clone()));
let c = Next(8,Box::new(b.clone()));
println!("{:#?}",a);
println!("{:#?}",b);
println!("{:#?}",c);
}
测试之后没有任何问题
接下来我们使用Rc改写
#[derive(Debug)]
enum List{
Next( i32,Rc<List>),
OFF
}
use std::rc::Rc;
use crate::List::{Next, OFF};
fn main() {
let b = Rc::new(Next(1,Rc::new(Next(2,Rc::new(OFF)))));
let a = Next(4,Rc::clone(&b));
let c = Next(8,Rc::clone(&b));
println!("{:#?}",a);
println!("{:#?}",b);
println!("{:#?}",c);
}
我们看到使用Rc改写之后:
- 去除了原来的Box,改用Rc
- 去除Clone标注,通过Rc::clone代替
主要产生以上两种改变,其实想法都是clone出b,不获取b的所有权这会将引用计数从 1 增加到 2 并允许 a 和 c 共享 Rc<List>中数据的所有权,每次调用 Rc::clone,Rc<List> 中数据的引用计数都会增加,直到有零个引用之前其数据都不会被清理
RefCell<T> 和内部可变性模式
内部可变性(Interior mutability)是 Rust 中的一个设计模式,它允许你即使在有不可变引用时也可以改变数据,这通常是借用规则所不允许的。为了改变数据,该模式在数据结构中使用 unsafe 代码来模糊 Rust 通常的可变性和借用规则。不安全代码表明我们在手动检查这些规则而不是让编译器替我们检查
当可以确保代码在运行时会遵守借用规则,即使编译器不能保证的情况,可以选择使用那些运用内部可变性模式的类型。所涉及的 unsafe 代码将被封装进安全的 API 中,而外部类型仍然是不可变的。
通过 RefCell<T> 在运行时检查借用规则
RefCell<T> 代表其数据的唯一的所有权
对于引用和 Box<T>,借用规则的不可变性作用于编译时。对于 RefCell<T>,这些不可变性作用于 运行时。对于引用,如果违反这些规则,会得到一个编译错误。而对于 RefCell<T>,如果违反这些规则程序会 panic 并退出。
在运行时检查借用规则的好处则是允许出现特定内存安全的场景,而它们在编译时检查中是不允许的。
要记住Rust是保守的,安全的,这句话就是整个Rust的核心,所有特性都是围绕这句话来的
注意点
RefCell<T> 只能用于单线程场景
内部可变性
指的是可变的借用不可变的值
如下的程序是有问题的,因为本身x是不可变的,但是y取了x的可变引用,这本身是不允许的
fn main() {
let x = 5;
let y = &mut x;
}
使用RefCell
我们看这个例子,虽然arr是不可变的,但是我们通过包装RefCell之后获取了其所有权,使用borrow_mut方法获取了内部可变性,使其变成可变的,进行了操作,官方的例子很长,或许你没有耐心看完,我想我这样写应该能让你快速的了解
use std::borrow::BorrowMut;
use std::cell::RefCell;
fn do_change(arr: RefCell<Vec<i32>>)->Vec<i32>{
return arr.borrow_mut().to_vec().iter().map(|x|x+30).collect();
}
fn main() {
let arr = RefCell::new(vec![1, 2, 3]);
let new_arr = do_change(arr);
println!("{:?}", new_arr);
}
原理
使用RefCell<T>在运行时记录借用信息
RefCell<T>会记录当前存在多少个活跃的Ref<T>和 RefMut<T>智能指针:
- 每次调用borrow:不可变借用计数加1
- 任何一个
Ref<T>的值离开作用域被释放时:不可变借用计数减1―每次调用borrow_mut可变借用计数加1 - 任何一个
RefMut<T>的值离开作用域被释放时:可变借用计数减
以此技术来维护借用检查规则:
任何一个给定时间里,只允许拥有多个不可变借用或一个可变借用
结合 Rc 和 RefCell 来拥有多个可变数据所有者
这个例子我认为圣经上写的很好了,解释也很到位,所以大家直接看吧
RefCell<T> 的一个常见用法是与 Rc<T> 结合。回忆一下 Rc<T> 允许对相同数据有多个所有者,不过只能提供数据的不可变访问。如果有一个储存了 RefCell<T> 的 Rc<T> 的话,就可以得到有多个所有者 并且 可以修改的值了!
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {:?}", a);
println!("b after = {:?}", b);
println!("c after = {:?}", c);
}
我们可以看到List的Cons是Rc<RefCell<i32>>, Rc<List>这样我们传入一个通过使用Rc::new出来的RefCell,而真实的值类型是i32所以再通过RefCell::new 一下,这样我们可以修改这个传入的i32的值






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结