您现在的位置是:首页 >技术交流 >Transformer通俗讲解网站首页技术交流
Transformer通俗讲解
-
视频链接:Transformer 李宏毅
Transformer
Transformer是一个编码器-解码器网络架构的模型,最早的编码器解码器网络架构时Seq2Seq模型,用于机器翻译等任务,后来逐渐在计算机视觉领域中流行。
Transformer主体框架

Transformer是第一个完全依靠自注意力计算输入和输出表示的传导模型,无需使用RNN或卷积等其他结构。如图所示是Transformer的整体架构,Transformer是一个典型的编码器-解码器结构,其中编码器组由六个编码器构成,解码器组也由六个解码器构成。编码器由多头自注意力机制和全连接前馈网络两个子层构成,每个子层周围采用残差连接, 然后进行层归一化处理。输出为 L a y e r N o r m ( x + S u b l a y e r ( x ) ) LayerNorm(x+Sublayer(x)) LayerNorm(x+Sublayer(x))。解码器除了有上述的两个子层还具有一个多头注意力机制,对编码器信息进行融合。我们还修改解码器堆栈中的自注意力子层,以防止在训练过程中关注到后续位置。在训练过程中,我们将所有的真值都输入到解码器中,这种掩码机制保证了对位置i的预测只能依赖于小于i位置的已知输出,不会用到后续真值。在验证过程中,只能得到小于i位置的输出,因此不需要掩码机制。由于自注意力机制无法获取位置信息,因此在输入的时候我们需要加入一个位置编码信息,在Transformer这篇论文中,我们采用的是正余弦编码。
基本术语
注意力机制
可以描述为将一组查询和一组键、值映射到一组输出的方法。其中查询、键、值和输出都是向量。输出计算为值的加权和,其中分配给每个值的权重由查询与相应键的点乘计算。通俗来说注意力机制指的是对一组输入序列,我们分别乘上矩阵 W Q 、 W K 、 W V W^Q、W^K、W^V WQ、WK、WV,得到 q , k , v q,k,v q,k,v三个向量,序列中每个token的 q q q要与其余token的 k k k相乘,采用 d k sqrt{d_k} dk 进行缩放。再经过softmax操作,得到的数值与 v v v进行相乘,得到一个新的特征向量,其中 k , v k,v k,v来自于编码器,而 q q q来自于解码器。在实践中,我们同时计算一组查询的注意力函数,并将其打包成矩阵 Q Q Q,键、值也打包成矩阵 K , V K,V K,V则此时矩阵的输出为 A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(frac{QK^T}{sqrt{d_k} } )V Attention(Q,K,V)=softmax(dkQKT)V
自注意力机制
又是也称为帧内注意力,是一种将单个序列的不同位置联系起来,以计算序列的表示的注意力机制。注意力机制中 k , v k,v k,v来自于编码器,而 q q q来自于解码器。而自注意力机制的 q , k , v q,k,v q,k,v都来自于编码器或者解码器本身,因此它称作是自注意力机制。
多头注意力机制
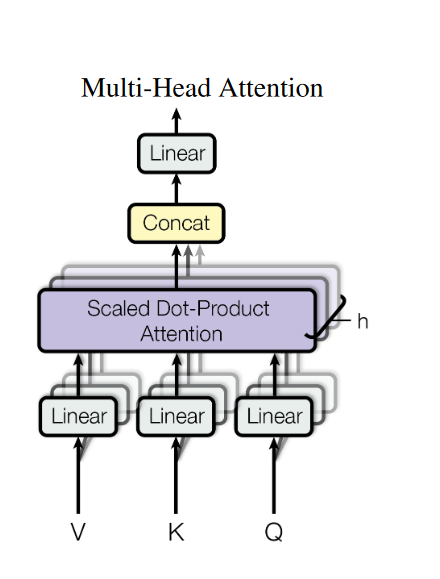
注意力机制中,对于输入矩阵(一组序列,序列中的每一个token都是一个向量),我们只采用一组
W
Q
、
W
K
、
W
V
W^Q、W^K、W^V
WQ、WK、WV,得到
Q
,
K
,
V
Q,K,V
Q,K,V三个矩阵。而多头注意力机制中采用多组
W
Q
、
W
K
、
W
V
W^Q、W^K、W^V
WQ、WK、WV,得到多组
Q
,
K
,
V
Q,K,V
Q,K,V矩阵,然后每组分别计算得到一个Z矩阵,将得到的多个Z矩阵进行拼接。在Transformer中我们采用了8组不同的
W
Q
、
W
K
、
W
V
W^Q、W^K、W^V
WQ、WK、WV。
全连接前馈网络
F
F
N
(
x
)
=
m
a
x
(
0
,
x
W
1
+
b
1
)
W
2
+
b
2
FFN(x)=max(0,xW_1+b_1)W_2+b_2
FFN(x)=max(0,xW1+b1)W2+b2
该全连接层由两个线性变化和一个ReLu激活函数组成,其中max就是我们所说的ReLu激活函数,x是经过多头(自)注意力机制的输出。这两层网络目的是将输入的Z映射到更加高维的空间中,然后经过非线性函数ReLu进行筛选,筛选完在变回到原来的维度。我们也可以将其看作两个核大小为1de卷积,其中输入输出的维度是512,内层的维度是2048。
层归一化
在神经网络进行训练之前,都需要对输入数据进行归一化处理,可以加快训练的速度,并且提高训练的稳定性。
层归一化是在同一个样本中不同神经元之间进行归一化,而BN是指在同一个batch中的不同样本之间的同一位置的神经元进行归一化。
Seq2Seq模型
对于输入输出都是序列且输出序列长度不确定的情况下我们采用Seq2Seq模型。Seq2Seq模型本身是一个Encoder-Decoder结构的网络。输出序列的长度是由模型本身来进行决定的
应用:语音辨识,机器翻译,语音翻译,分类任务,目标检测等。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结