您现在的位置是:首页 >学无止境 >计算机视觉——day88 读论文:基于驾驶员注意视野的交通目标检测与识别网站首页学无止境
计算机视觉——day88 读论文:基于驾驶员注意视野的交通目标检测与识别
基于驾驶员注意视野的交通目标检测与识别
该方法使用由前视立体成像系统和非接触式三维凝视跟踪器联合交叉校准获得的注视点的驱动器三维绝对坐标。在检测阶段,结合了多尺度HOG-SVM和Faster r - cnn模型。识别阶段通过ResNet-101网络来验证生成的假设集。我们将这种方法应用于城市环境中驾驶过程中收集到的真实数据。
II. RELATED WORKS
A. 通用对象检测
通用目标检测算法可分为传统的和基于深度学习的两大类。
基于深度学习的目标检测方法主要有两大类:基于区域的方法和基于回归的方法。
B. 交通标志检测与识别
符号检测方法一般分为基于颜色的方法、基于形状的方法和混合方法。
1、颜色阈值分割是基于颜色的方法中最常用的方法,它通过忽略非目标区域来减少搜索区域。
2、交通标志也有特定的形状,可以通过基于形状的方法搜索。由于它对光照变化和图像噪声具有较强的鲁棒性,霍夫变换是最常用的基于形状的方法之一。
3、混合方法利用了标识的颜色和形状的优点,分类阶段主要采用模板匹配、SVM、遗传算法(Genetic Algorithm, GA)、人工神经网络(Artificial Neural Network, ANN)、AdaBoost和基于深度学习的方法。
卷积神经网络(Convolutional Neural Networks, cnn)是深度神经网络模型的一个子集,能够从原始数据中学习鲁棒的和有区别的特征。有各种各样的CNN被用来识别交通标志。
C. 车辆检测
许多传统的车辆检测方法包括假设生成(HG)步骤和假设验证(HV)步骤。现在还是用深度学习的多。
D.行人检测
使用深度学习的行人检测方法可以分为单阶段技术和两阶段技术。
E. 交通灯检测
颜色分割是交通场景图像中常用的一种减少搜索空间的方法。
III. PROPOSED METHOD
在本节中,我们描述了我们提出的基于驾驶员注意视野的交通目标检测和识别方法。首先,介绍了本研究中使用的数据集。在此基础上,我们描述了在前向立体成像系统中寻找驾驶员注意力凝视区域的方法。接下来,在目标检测阶段,我们训练的模型和用于丰富我们的数据集的方法被描述。然后讨论了我们使用的利益区域(Region of interest, roi)积分方法。最后,给出了目标识别阶段。图1说明了我们提出的框架。
我主要想看的是第一和第三小节,第二小节留给感兴趣的读者自己去挖掘啦。
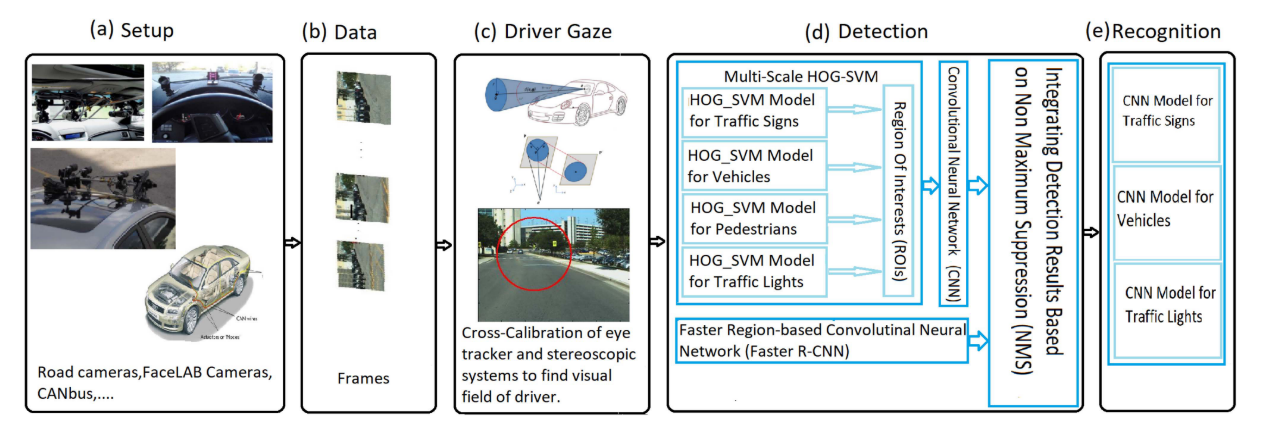
图1。框架概述。我们的框架检测并识别驾驶员视野内的交通目标。从左至右:
a)前向立体视觉和眼球追踪系统的RoadLAB车辆。
b) RoadLAB实验车辆创建的数据集。
c)计算驾驶员视野半径作为注意力注视锥,定位驾驶员视野重新投影的2D椭圆。
d)我们在框架的检测阶段使用了两种不同的模型类型;模型A包括多尺度HOG-SVM,然后应用CNN两个步骤,模型B是基于Faster region的CNN。检测结果通过一种基于网管的算法进行集成。
e)识别阶段,我们分别对交通标志、车辆、交通灯三个独立的模型进行训练。
A. The RoadLAB Dataset
基于深度学习的目标检测系统的一个基本元素是大量样本图像的可用性。在本节中,我们将从RoadLAB实验数据序列中展示我们自己的对象数据集
## 此处参考文献名:
1、A probabilistic model for visual driver gaze approximation from head pose estimation;2、Portable andscalable vision-based vehicular instrumentation for the analysis of driver
intentionality;
3、Multi-depth cross-calibration of remote eye gaze trackers and stereoscopic scene systems)。
我们的数据集包含背景类样本图像3,225张,交通标志、车辆、行人和交通灯对象类样本图像分别为5,172、1,984、1,290和1,875张。车辆类别包括3种不同的类别,包括轿车、公共汽车和卡车。交通灯等级分为红、黄、绿、不清4个等级。最后,交通标志类包括19种不同类型的交通标志。此外,一些交通标志类别包括多个标志类型,如“最高速度限制”、“建筑”、“停车”等。
B. 驾驶员注视定位
圆通常以二维椭圆的形式投射到立体传感器的成像平面上
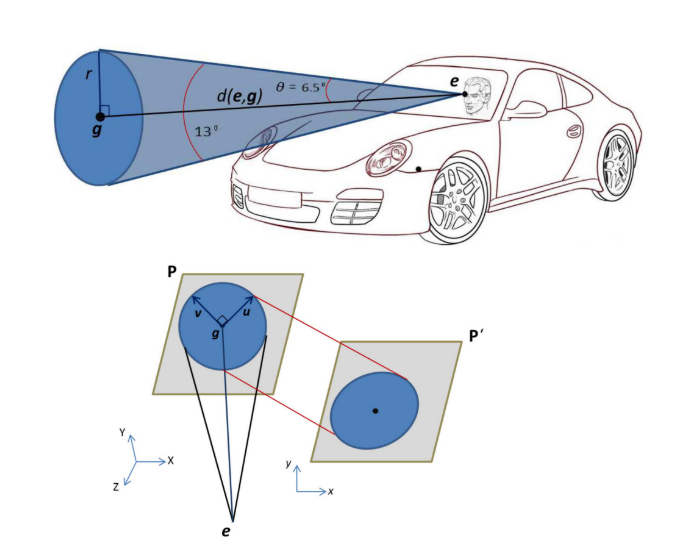
图二。(上):驾驶员注意力注视锥的描绘。(下):将三维注意圆在正向立体场景系统的图像平面上重新投影成相应的二维椭圆。
C. 目标检测阶段
为了检测驾驶员注意域内外感兴趣的交通对象,我们采用了一个由两种不同模型类型组成的框架,并对其进行描述:
模型A
第一个模型包括两个步骤,包括多尺度HOG-SVM,然后使用ResNet-101网络。多尺度HOG-SVM描述符计算图像区域中梯度方向出现的次数,然后使用块归一化算法,该算法对边缘对比度和阴影具有更好的不变性。由于感兴趣区域(Region of Interest, RoI)包含大小不同的目标,我们使用了一种多尺度方法来解决目标检测问题。我们将从每一层的每个滑动窗口提取的hog特征作为独立的样本,然后将它们输入svm分类器。
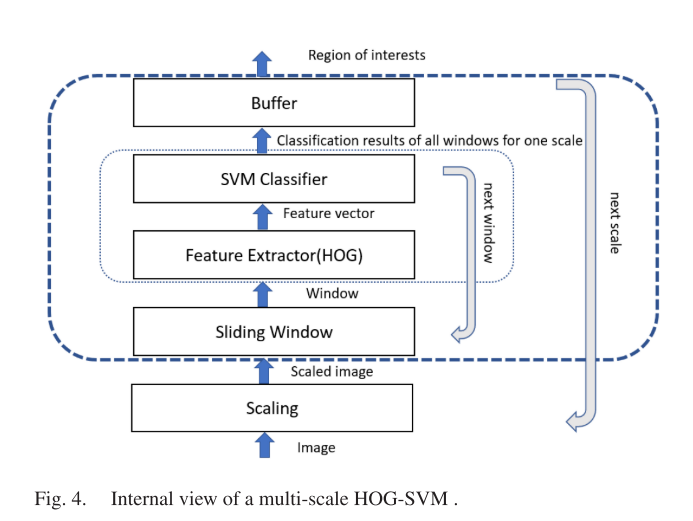
图4为多尺度HOG-SVM的内部视图。其余来自HOG-SVM分类器的roi被分为5类:背景、交通标志、车辆、行人和交通灯。
第二阶段,我们使用了ResNet-101[38],这是一个流行的CNN,已经训练了超过100万张来自ImageNet数据库的图像。

图5显示了使用该模型得到的样本结果。
 然而,在我们的实证试验中,我们注意到多尺度HOG-SVM很难定位占据图像大部分的车辆(图6说明了这个问题)。因此,我们也使用Faster R-CNN模型来检测车辆。
然而,在我们的实证试验中,我们注意到多尺度HOG-SVM很难定位占据图像大部分的车辆(图6说明了这个问题)。因此,我们也使用Faster R-CNN模型来检测车辆。
模型B
我们在数据集上训练了一个Faster R-CNN模型来定位车辆。在我们的实证试验中,我们观察到模型B能够正确地检测出占用较大图像区域的车辆,或者是非常接近被仪器检测车辆的车辆相反,根据我们的经验实验以及对文献的调查,我们发现Faster R-CNN难以处理分辨率低或尺寸小的物体。因此,为了检测不同大小的物体,我们综合了模型a和模型B的结果,以充分利用这两个模型。这一阶段生成的假设将直接转移到整合阶段,在整合阶段对检测结果进行合并。

图7为模型B获得的车辆检测结果。
D.数据扩充
E.综合检测结果
在完成对测试图像的检测阶段后,为了提高检测性能,我们消除了冗余的检测,并将剩余的检测合并成一组完整的结果。为此,我们使用了一种基于非最大抑制(NMS)的方法,当多个边界盒重叠时,NMS保留得分最高的边界盒,并消除重叠比例超过预设阈值的其他边界盒。我们用Pascal重叠分值来求它们之间的重叠比a0。得到的比值为:

F.物体识别阶段
 图8显示了四类交通对象的结果样本。更准确地说,交通灯识别器可以将交通灯假设分为5类,车辆识别器可以将车辆假设分为4类,交通标志识别器可以将交通标志假设分为20类。
图8显示了四类交通对象的结果样本。更准确地说,交通灯识别器可以将交通灯假设分为5类,车辆识别器可以将车辆假设分为4类,交通标志识别器可以将交通标志假设分为20类。
IV. 实验结果
A. 参数
为了获得每个分类器模型的微调参数,我们在我们的训练数据集上使用交叉验证实验。我们将训练数据分为基本训练集和验证集。然后,使用基本训练集来训练分类器,然后,使用验证集来评估模型。通过探索调优参数的各种范围,我们选择了能够获得最大验证精度的参数设置。然后,使用调整后的参数对完整的训练集重新训练分类器。我们的模型在训练集和验证集上的性能分别达到了95.1%和94.2%。最后,我们在由一组随机选择的样本组成的预先分离的不可见数据上测试模型。
B. 对象检测阶段的结果
表1,数据扩充的描述

表2,检测结果描述,为不同交通对象的f1得分。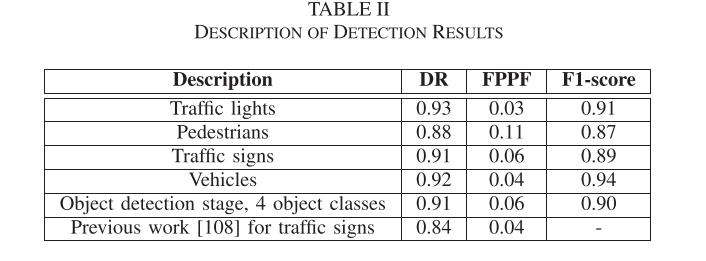
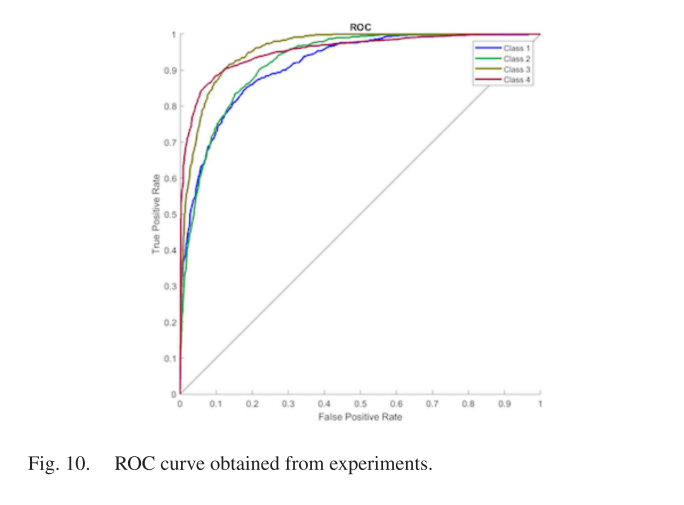
图10显示了我们使用受试者工作特征(ROC)曲线计算的检测器的性能,标记了真阳性率(TPR)与假阳性率(FPR)。图中class1、class2、class3和class4分别代表行人、交通标志、交通灯和车辆。
C. 可信度
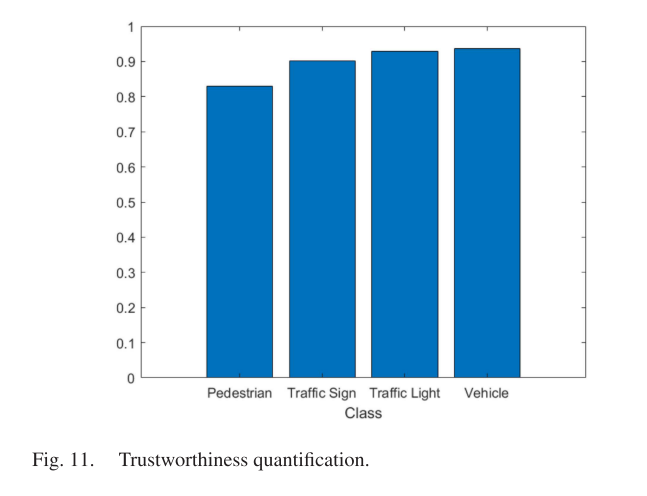
图11中的信任谱显示了行人、交通标志、交通灯、车辆四类的总体信任。可以看出,车辆等级的信任度最高,行人等级的可靠性最低。
D.物体识别阶段的结果
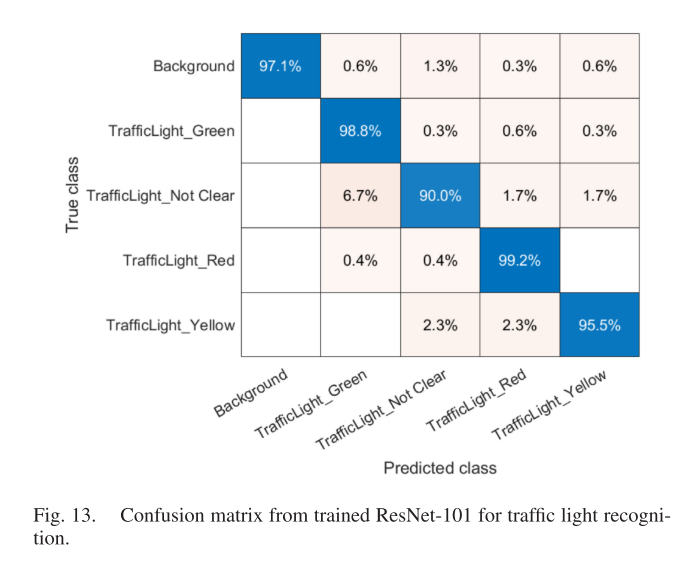
图13给出了用于交通灯识别的混淆矩阵。结果表明,该模型的总体正确率达到96.2%。
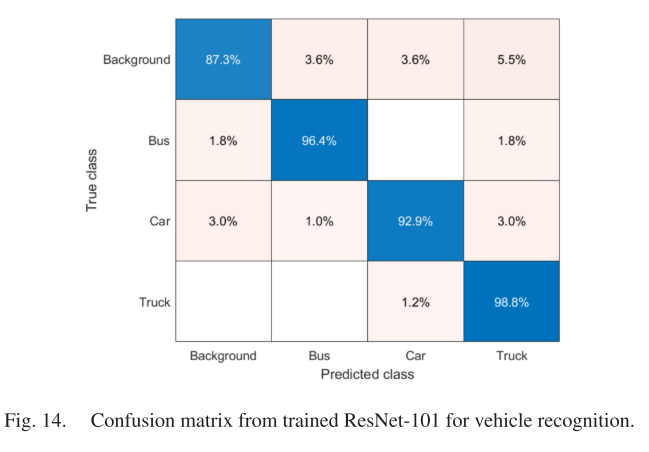
如图14所示的结果表明,车辆识别器模型的总体分类正确率为94.8%。这个混淆矩阵表明,该模型能够识别车辆对象(即车辆、公交车和卡车),而误标记错误的概率小于3%。背景类的准确率最低,为87.3%。
V. 结论
我们对交通标志、车辆、行人和交通灯四类重要交通目标的检测与识别方法进行了文献综述。一般来说,在学习过程中,适当和充分的训练数据的可用性是一个至关重要的因素,以实现一个有区别的模型。在这项工作中,我们从属于RoadLAB计划[3]的序列中收集了超过10,000个物体样本图像。我们还使用增强和HEM策略丰富了我们的训练数据。将驾驶员的注意视觉区域定位在前向立体系统的成像平面上,设计了驾驶员注意视野内外交通目标的检测与识别框架。我们分别考虑了3、4和19种不同类型的车辆、交通灯和交通标志。目标检测阶段将传统模型和基于深度学习的模型相结合,对不同尺度的目标进行检测。最后,在识别阶段,通过经过训练的ResNet-101网络,我们的框架对交通标志、交通灯和车辆的分类正确率分别达到96.1%、96.2%和94.8%。






站长推荐
- QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结