您现在的位置是:首页 >学无止境 >Ubuntu上跑通PaddleOCR网站首页学无止境
Ubuntu上跑通PaddleOCR
书接上文。刚才说到我已经在NUC8里灌上了Windows Server 2019。接下来也顺利的启用了Hyper-V角色并装好了一台Ubuntu 22.04 LTS 的虚机。由于自从上回在树莓派上跑通了Paddle-Lite-Demo之后想再研究一下PaddleOCR但进展不顺,因此决定先不折腾了,还是从x64平台上做起,至少先能跑通体验一下。
进入Ubuntu,先做常规更新工作:
sudo apt update
sudo apt upgrade
安装一些远程工具。建议ssh装上:
sudo apt install xrdp ssh
其它实用工具,建议smbclient装上:
sudo apt install git smbclient
给$PATH添加一条路径,推荐这会儿先做掉:
cd
sudo nano ./.bashrc
最后添加一行:
export PATH=/home/ki/.local/bin:$PATH
sudo reboot
至此准备工作完毕,接下来开始安装PaddleOCR相关的软件:
sudo apt install cmake libopencv-dev python3-pip
python3 -m pip install paddlepaddle==2.4.2 -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 -m pip install paddleocr -i https://pypi.tuna.tsinghua.edu.cn/simple期间可能有个报错,版本依赖有问题,暂时可以忽略。
至此就算安装完毕可以测试了。
我的测试用例有一个图片和一个pdf。我是在Ubuntu上用smbclient命令访问Windows上共享目录得到的。在Windows上运行WinSCP也是个可行的办法。
先看看图片的识别效果:
命令行为:paddleocr --image_dir 图片文件名 --lang ch。lang参数指出用什么语言去解读。ch是指中英文。第一次运行时会下载一些必要的模型。
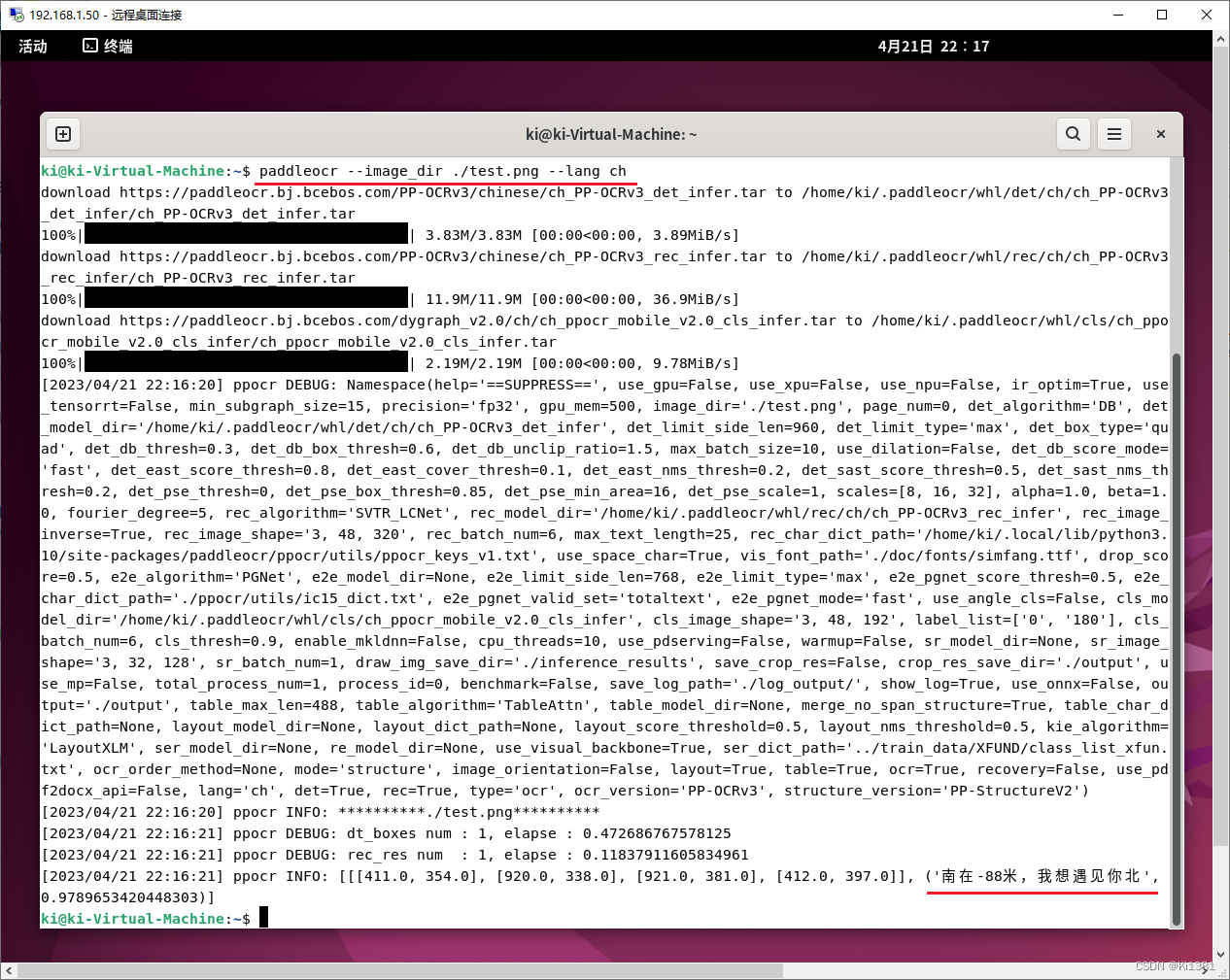
识别正确。
PDF识别稍微有点小问题,要改一下源代码。命令行和识别图片几乎一致,PDF的文件名也是通过 --image_dir 参数提供。另外也可以加 --page_num 参数用于指定识别的页码,不写的话识别全部文档。

但会报错。解决办法也很简单粗暴,根据提示直接改就是了。后面还有一处同性质的错误,懒得贴图,这里直接一并给出了。一共两处。
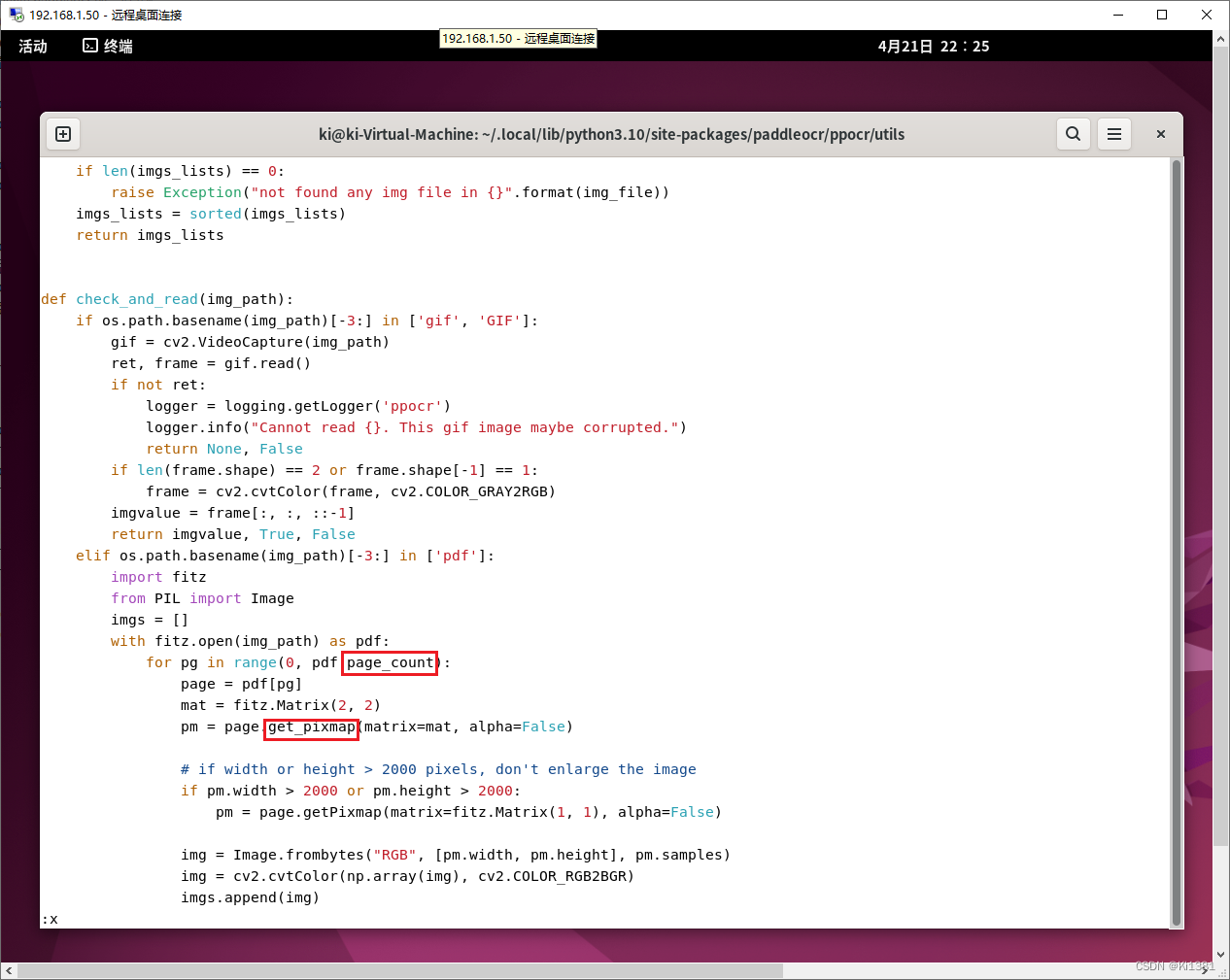
之后就可以运行了。不妨对比下原始pdf和识别出的效果:

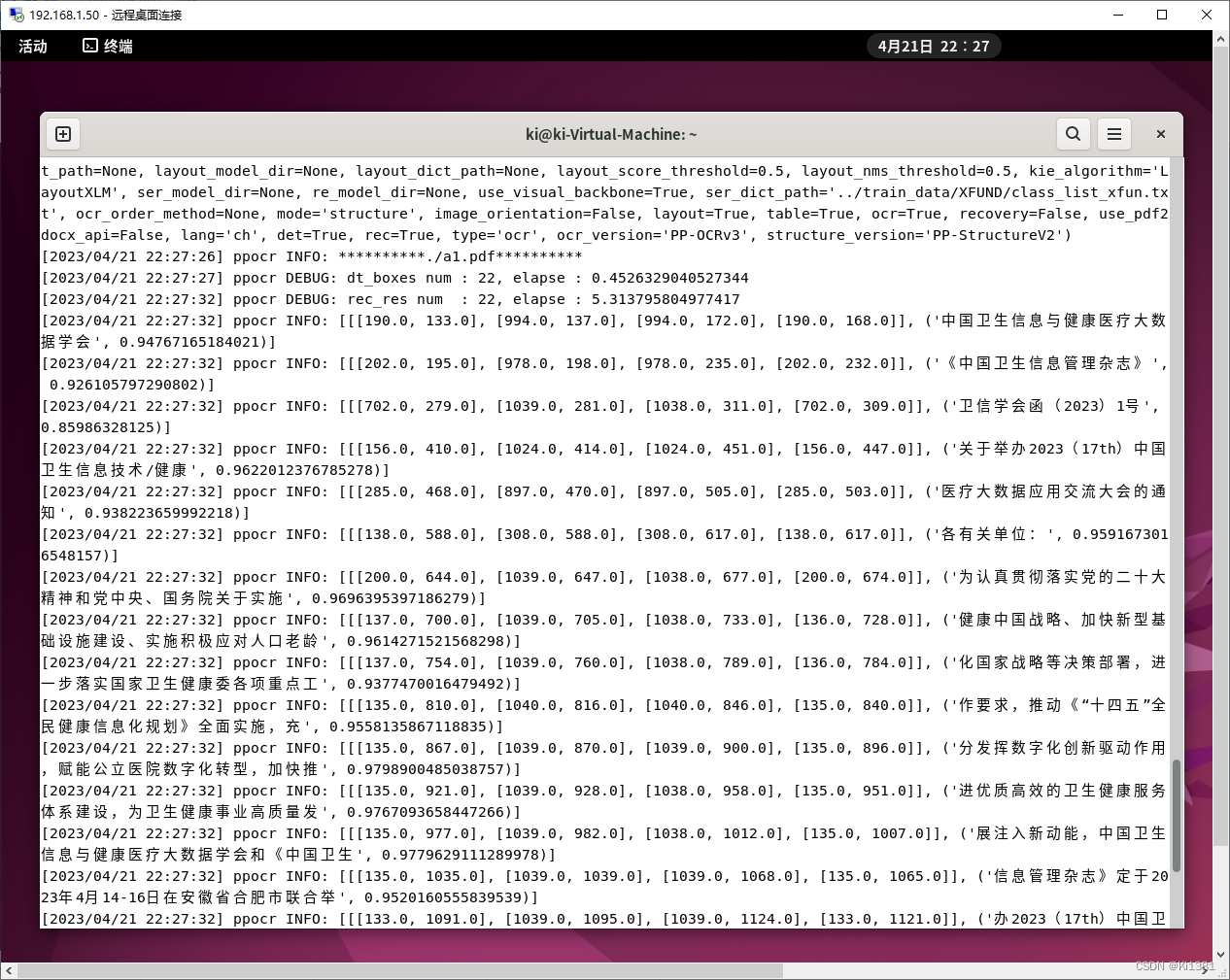
识别率满意。
最后,如果实在介意那个版本依赖造成的错,有人说可以这么操作算是打个补丁:
pip uninstall onnx
python3 -m pip install protobuf==3.20.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
python3 -m pip install onnx==1.12.0 -i https://pypi.tuna.tsinghua.edu.cn/simple尚未亲测,仅供参考。
====^^^^====
测过了,没用,但似乎也没影响。






站长推荐
- U8W/U8W-Mini使用与常见问题解决
 U8W/U8W-Mini使用与常见问题解决
U8W/U8W-Mini使用与常见问题解决 - QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。
 QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。...
QT多线程的5种用法,通过使用线程解决UI主界面的耗时操作代码,防止界面卡死。... - stm32使用HAL库配置串口中断收发数据(保姆级教程)
 stm32使用HAL库配置串口中断收发数据(保姆级教程)
stm32使用HAL库配置串口中断收发数据(保姆级教程) - 分享几个国内免费的ChatGPT镜像网址(亲测有效)
 分享几个国内免费的ChatGPT镜像网址(亲测有效)
分享几个国内免费的ChatGPT镜像网址(亲测有效) - Allegro16.6差分等长设置及走线总结
 Allegro16.6差分等长设置及走线总结
Allegro16.6差分等长设置及走线总结